Neural Network Based Interview Robot
Good day to all! I am a student, for my thesis I chose the topic “Information Neural Networks” (INS). Tasks where it is necessary to work with numbers, were solved rather easily. And I decided to complicate the system by adding word processing. Thus, I set myself the task of developing a “robot interlocutor” who could communicate on any particular topic.
Since the topic of communication with the robot is quite extensive, I do not appreciate the dialogue as a whole (hello to Comrade Turing), only the adequacy of the “interlocutor ”’s response to the person’s comment is considered.
Further, we will call the question a sentence coming in at the INS input, and the answer the sentence received at its output.
Architecture 1. A two-layer direct distribution neural network with one hidden layer
Since neural networks only work with numbers, you need to encode words. For simplicity, punctuation marks are excluded from consideration, only proper names are written with a capital letter.
Each word is encoded with two integers, starting from one (zero is responsible for the absence of a word) - the category number and the word number in this category. It was assumed in the "category" to store words that are similar in meaning or type (colors, names, for example).
Table 1
| Category 1 | Category 2 | Category 3 | Category 4 | |
| one 2 3 four five 6 7 | you your you yours you you I | OK perfectly wonderful excellent good good good ones | badly horrible disgusting bad the bad | Hello Hello welcome hello healthy |
For a neural network, data is normalized, reduced to a range $ inline $ [0, 1] $ inline $ . Category number and words - to the maximum value. $ inline $ M $ inline $ category numbers or words in all categories. The sentence is translated into a real vector of fixed length, the missing elements are filled with zeros.
Each sentence (question and answer) can consist of a maximum of ten words. Thus, a network with 20 inputs and 20 outputs is obtained.
The required number of links in the network to remember N examples was calculated by the formula
$$ display $$ L_W = (m + n + 1) (m + N) + m, $$ display $$
where m is the number of inputs, n is the number of outputs, N is the number of examples.
The number of connections in the network with one hidden layer consisting of H neurons
$$ display $$ L_W = 20H + 20H = 40H, $$ display $$
where does the required number of hidden neurons come from
$$ display $$ H = L_W / 40 $$ display $$
For $ inline $ n = 20 $ inline $ , $ inline $ m = 20 $ inline $ it turns out a match
$$ display $$ L_W (N) = 41N + 480 $$ display $$
As a result, we obtain the dependence of the number of hidden neurons on the number of examples:
$$ display $$ H (N) = \ frac {41} {40} H + 21 $$ display $$
The structure of the learning network is shown in Figure 1.
Figure 1. The simplest INS for memorizing sentences
Implemented network in MATLAB, training is the method of back propagation of an error. The training sample contains 32 sentences ...
More and did not take ...
The INS could not remember more than 15 sentences, as the following graph shows (Figure 2). The error is calculated as the modulus of the difference between the current output of the NA and the required one.
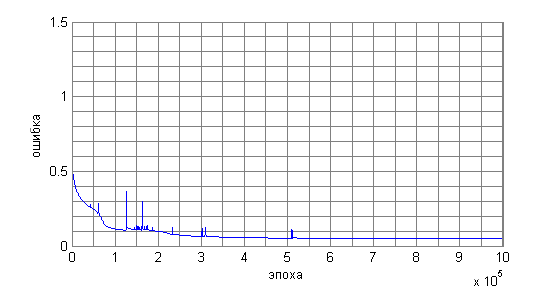
Figure 2. NA error when learning 32 examples
Dialogue example (all questions from the training set):
|
|
As a result of testing for various numbers of examples, it became clear that even the training sample of the INS remembers with great difficulty (as can be seen from Figure 2). Even for a million epochs, the error could not be reduced to the required value.
Architecture 2. A two-layer neural network of direct distribution
The next way to encode words for ANN is one-hot encoding [4] . Its essence is as follows: let the dictionary have $ inline $ D $ inline $ alphabetically arranged words. Each word of such a dictionary is encoded by a length vector. $ inline $ D $ inline $ containing a unit in place corresponding to the number of the word in the dictionary and zeros in other places.
For experiments, a dictionary was created from $ inline $ D = 468 $ inline $ words and a training set of 95 sentences. Six words were delivered to the input of the National Assembly and the answer was also considered from six words.
The number of neurons in the hidden layer was determined by the dependence of the number of connections on the number of examples that the network can learn without errors.
|
|
The results show that now the system can memorize more words. Almost a victory ... but another problem arises - the definition of synonyms and similar words [4] .
Architecture 3. Two-layer direct distribution neural network
with one hidden layer and word2vec encoding
To solve the problem of the similarity of words and synonyms, I decided to try word2vec [4] , which allows you to encode words as necessary.
For experiments on the network used a dictionary of word2vec length vectors $ inline $ D = 50 $ inline $ trained at the neural network training base.
Six words (the vector of length 300) are given to the input of the neural network and it is proposed to receive an answer, also consisting of six words. In the case of reverse coding, the sentence vector is divided into six word vectors, for each of which in the dictionary the maximum possible match is found for the cosine of the angle between the vectors $ inline $ A $ inline $ and $ inline $ b $ inline $ :
$$ display $$ cos [A, B] = \ frac {\ sum_ {d = 1} ^ {D} {(A_d B_d)}} {\ sqrt {\ sum_ {d = 1} ^ {D} {A_d ^ 2}} \ sqrt {\ sum_ {d = 1} ^ {D} {B_d ^ 2}}} $$ display $$
But even with this implementation, word2vec does not make the necessary connections between words from the point of view of the Russian language. To create a dictionary in which exactly the synonyms will be located as close as possible, a training building with grouped synonyms was formed, as far as possible combined in meaning with each other:
| TO ME MY ME MY MY YOU YOU YOU YOUR YOUR YOUR YOUR YOU NO ON ON WITH S AND YES TO ABOUT WHAT ALSO EVEN ONLY THIS WHO IS WHAT BORN BORN ROBOT ROBOT ROBOT ROBOT |
As a result of such a presentation, there is no need to memorize many synonyms that can be given the same answer (like “hello”, “hello”, “greet”). For example, only “hello - hello” participated in the training sample, the remaining answers were received due to the large cosine proximity of “hello”, “hello” and “greet”.
|
|
However, at the same time, because of the close proximity of the synonyms in the answer (conversation = conversation = talked = ..., I = me = mine = me = ...), they are often confused when they slightly reformulate the question ("How do you study?" Instead of "How do you learn from a person? ”).
Misadventure
As you can see, when I tried to use the INS to communicate with a person, I had “two blondes”: one cannot remember more than 15 sentences, and the second knows a lot, but does not understand anything.
Judging by the descriptions both on Habrahabr and on other sites, not everyone faces such a problem. Therefore, the question arises: where is the dog buried? What approach should be used to get an INS that can memorize and understand at least 100 - 200 phrases?
Who faced similar questions, I ask for your advice and suggestions.
Bibliography
- How to understand LSTM networks
- Development: Chatbot on neural networks
- Development: Google TensorFlow machine learning library - first impressions and comparison with its own implementation
- Development: Classification of proposals using neural networks without pre-processing
- Development: Russian Neural Network Chatbot
')
Source: https://habr.com/ru/post/321996/
All Articles