Data is better than oil, or the sixth set per program by big data
Habr, hello! It's hard to believe, but on March 16 we will launch the 6th set of our program “Big Data Specialist”.

At the moment, we already have about 160 graduates who, with varying degrees of involvement, apply the knowledge and skills acquired in the program. Probably, you can ask yourself whether such a number of frames is needed. There are two answers to this reasonable doubt. First, we keep abreast of and periodically conduct market analysis . Secondly, the market is not a static entity and is growing, and the number of open vacancies is not a sufficient metric to measure this demand.
Two years ago, when we launched the program for the first time, there was no need for so many specialists. But, as it turned out later, most of our students do not change their place of work, but use the acquired skills and knowledge in their companies. And for the most part these vacancies are not published in the public domain, because there are not even such positions yet.
There are more and more companies implementing big data technologies. That is why we have launched a separate program for managers who are now eyeing this topic and are going to conduct a competent implementation of these technologies in the future.
')
If we recall the curve of the spread of innovation and technology in the market, it will become clear that this growth can continue further.
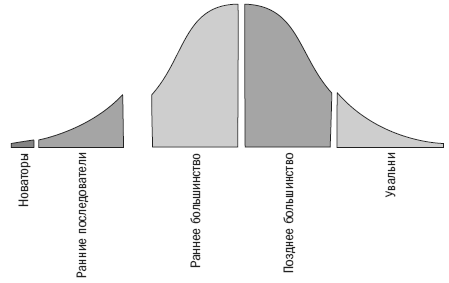
At the moment, the tools for working with big data have most likely introduced the first two classes: innovators and early followers, and representatives of the early majority are just beginning to connect.
As a summary: there is no reason to believe that the need for specialists in big data will decrease. Rather, on the contrary, will grow. The currently popular phrase that data is new oil is not entirely correct. Data is better than oil. Everyone can have access to data if they learn how to collect and process them correctly, which is not the case with oil. So come to us to study.
Despite the fact that this is already 6 launch, we continue to work on the product and decided to add something new to it.
1) Previously, we had 12 labs: one for each week of the program. This time we decided to make 10 labs and 2 "graduation" projects, for which the students will prepare during the whole module. One project will be called “Forecasting the user’s gender and age category using web logs”, and the second “Building a recommender system for online retail”. You will have enough time to work on them and make something of them that you can be proud of and that you can add to your work portfolio.
2) Periodically we were asked to make group tasks in the program. This time part of the laboratory work involves group work. So there will be an occasion to make friends with each other even stronger.
3) At the moment we are optimizing the work of our automatic laboratory checkers so that the test takes minimal time and does not “freak out”. Plus, add a progress indicator on the program. At any time it will be possible to see if there are enough points for a particular certificate or not.
4) Traditionally, on our cluster will be all the most modern and relevant libraries and, of course, the latest version of Apache Spark. Percent 80-90 work in this tool will take place on data frames. During the last launch, we migrated our training materials from RDD to this data structure.
We are waiting for you on the program . It will not be boring!
At the moment, we already have about 160 graduates who, with varying degrees of involvement, apply the knowledge and skills acquired in the program. Probably, you can ask yourself whether such a number of frames is needed. There are two answers to this reasonable doubt. First, we keep abreast of and periodically conduct market analysis . Secondly, the market is not a static entity and is growing, and the number of open vacancies is not a sufficient metric to measure this demand.
Two years ago, when we launched the program for the first time, there was no need for so many specialists. But, as it turned out later, most of our students do not change their place of work, but use the acquired skills and knowledge in their companies. And for the most part these vacancies are not published in the public domain, because there are not even such positions yet.
There are more and more companies implementing big data technologies. That is why we have launched a separate program for managers who are now eyeing this topic and are going to conduct a competent implementation of these technologies in the future.
')
If we recall the curve of the spread of innovation and technology in the market, it will become clear that this growth can continue further.
At the moment, the tools for working with big data have most likely introduced the first two classes: innovators and early followers, and representatives of the early majority are just beginning to connect.
As a summary: there is no reason to believe that the need for specialists in big data will decrease. Rather, on the contrary, will grow. The currently popular phrase that data is new oil is not entirely correct. Data is better than oil. Everyone can have access to data if they learn how to collect and process them correctly, which is not the case with oil. So come to us to study.
Despite the fact that this is already 6 launch, we continue to work on the product and decided to add something new to it.
1) Previously, we had 12 labs: one for each week of the program. This time we decided to make 10 labs and 2 "graduation" projects, for which the students will prepare during the whole module. One project will be called “Forecasting the user’s gender and age category using web logs”, and the second “Building a recommender system for online retail”. You will have enough time to work on them and make something of them that you can be proud of and that you can add to your work portfolio.
2) Periodically we were asked to make group tasks in the program. This time part of the laboratory work involves group work. So there will be an occasion to make friends with each other even stronger.
3) At the moment we are optimizing the work of our automatic laboratory checkers so that the test takes minimal time and does not “freak out”. Plus, add a progress indicator on the program. At any time it will be possible to see if there are enough points for a particular certificate or not.
4) Traditionally, on our cluster will be all the most modern and relevant libraries and, of course, the latest version of Apache Spark. Percent 80-90 work in this tool will take place on data frames. During the last launch, we migrated our training materials from RDD to this data structure.
We are waiting for you on the program . It will not be boring!
Source: https://habr.com/ru/post/321918/
All Articles