The best architecture based on Docker and Kubernetes - myth or reality?
How has the software world changed in the era of Docker and Kubernetes? Is it possible to build an architecture once and for all based on these technologies? Is it possible to unify the development and integration processes when everything is “packed” into containers? What are the requirements for such solutions? What restrictions do they carry with them? Will they make life easier for simple developers or will it make it harder?
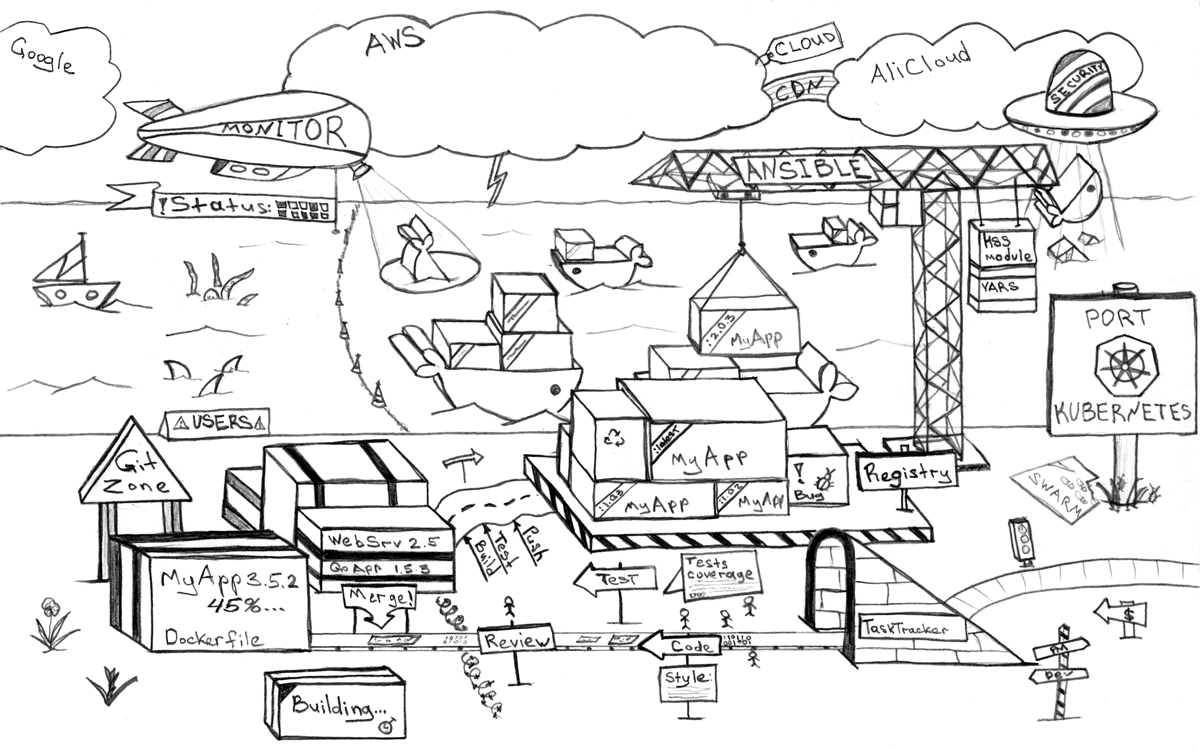
It's time to answer all these and not only these questions! (In the text and original illustrations)
This article will lead you in a circle from real life to development processes and through architecture will bring you back to real life, answering the most important questions in each of these sectors. I will also try to identify a number of components and principles that should become part of the architecture, without going into specific implementations, but only giving examples of possible available solutions.
The final conclusion about the question from the headline of the article can upset you, just as much to please other readers - everything will depend on your experience, how you take the following story from three chapters and, quite likely, the mood on this day, so do not hesitate to healthy discussions and questions after reading!
Table of contents
- From real life to development processes
- From processes to architecture
- Essential components and ecosystem solutions
- Identity service
- Automated server provisioning
- Git repository and task tracker
- Docker registry
- CI / CD service and service delivery system
- Log collection and processing system
- Tracing System
- Monitoring and alerting
- API Gateway and Single Sign-on
- Event Bus and Event Integration / Service Bus
- Databases and other stateful services
- Dependency mirrors
- From architecture to real life
From real life to development processes
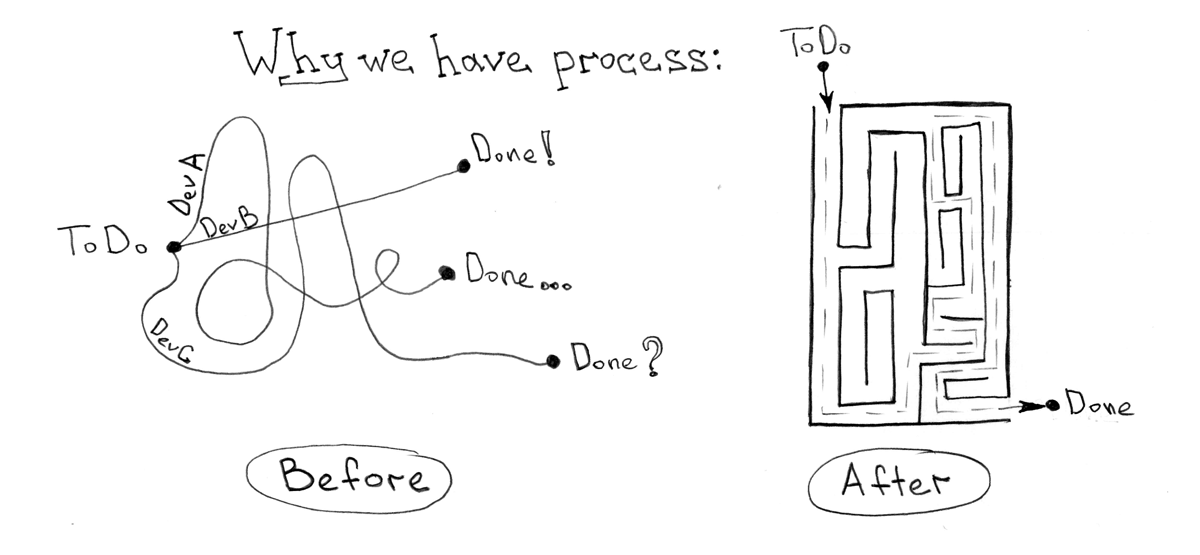
For the most part, all the development processes that I have ever seen or been given to install / configure serve, in fact, one simple goal - to reduce the time between the birth of an idea and its delivery to the “combat” environment with a given, generally case of constant, the value of the quality code.
But a bad idea or a good one is completely irrelevant. Bad ideas are usually accelerated in order to check and then give up and, possibly, quickly disintegrate. What is important to say here is that the process of rolling back to the previous version (without this “crazy” idea) also falls on the shoulders of the robot, which automated your processes.
Continuous integration and delivery usually seem like a lifeline in the design world. What would seem easier? There is an idea, there is a code - let's go! All is good, if not for one big "BUT". As my experience shows, the process of integration and delivery is rather difficult to formalize in isolation from the technologies and business processes that take place in the company.
In spite of all the seeming complexity of the task, the world is constantly throwing up great ideas and technologies that bring us (well, me personally for sure ...) to the utopian and ideal mechanism that would fit in almost any occasion. The next step towards this is Docker and Kubernetes. The level of abstraction and the ideological approach give me the right to say that 80% of the problems can now be solved by practically the same methods.
20% nowhere, of course, do not share. But this is exactly the area where it is interesting to work and create, and not to engage in the same routine problems of architecture and processes. Therefore, having concentrated once on the “architectural framework”, we can forget (without prejudice to the cause) about the need to return to these 80% of the problems solved.
What does all this mean, and how does Docker solve the problems of our development processes?
Let's take a simple development process, which I also propose to consider as being quite sufficient in most cases:
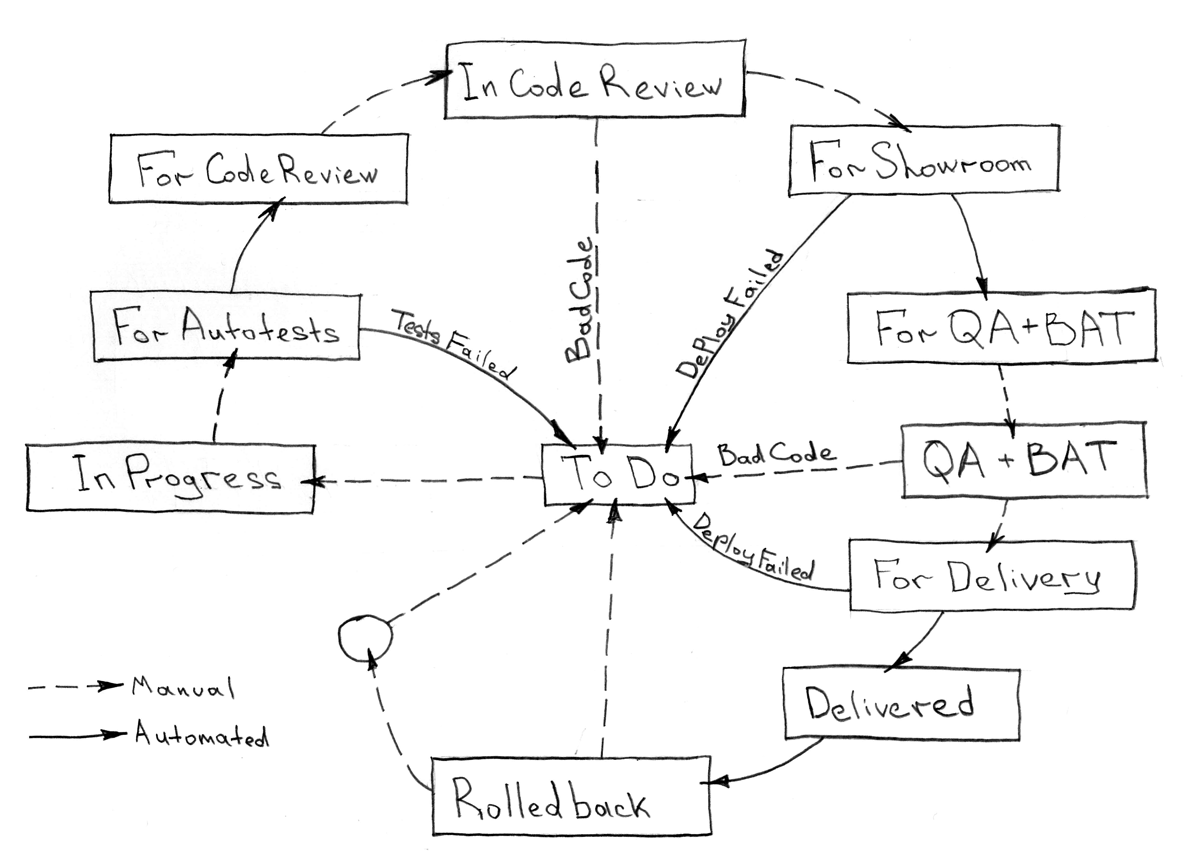
Everything that should be automated from a given sequence of stages of any task can be completely unified to itself and not require changes with the proper approach over time.
Installing a Developer Environment
Any project must contain docker-compose.yml . It will easily save the developer from having to think about how and what he needs to do in order to run your application / service on the local machine. A simple docker-compose up should include this application with all dependencies, populate the database with fixtures, connect the local code to the inside of the container, spy on the code for compilation on the fly, and ultimately respond to the expected port.
If we are talking about creating a new service, then the developer also should not be asked questions about how to start, where to commit or what frameworks to choose. All this should be described in advance in the instructions-standards and dictated by service templates for different cases: frontend , backend , worker and other types.
Automated Testing
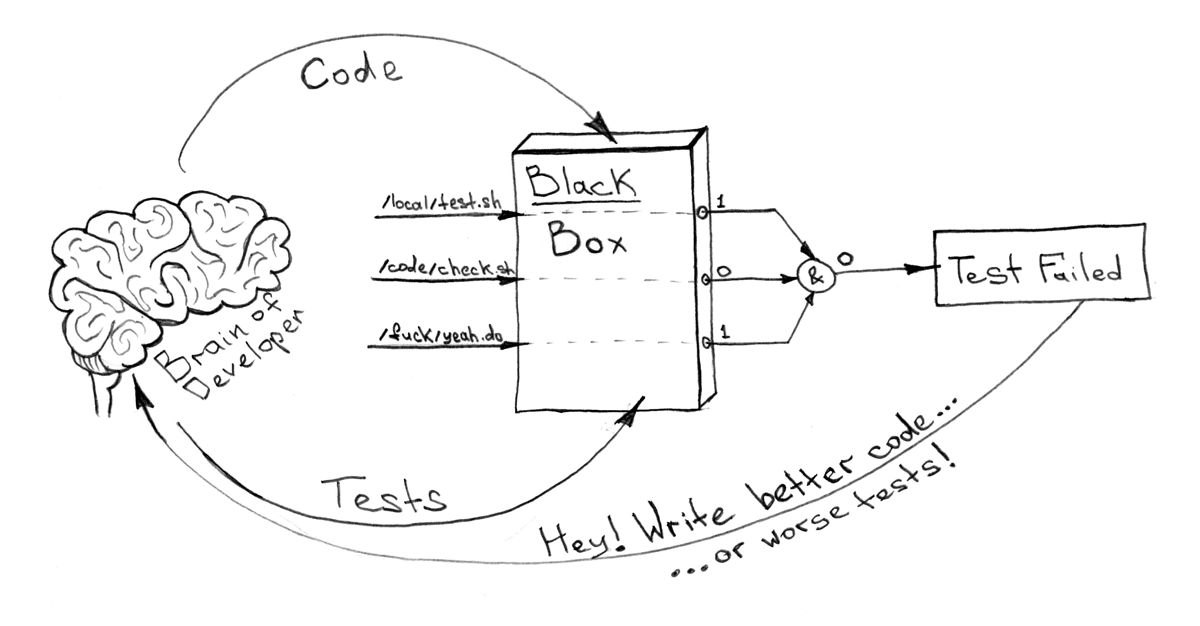
All that I want to know about the "black box" ( why I will tell the container a little later ) is the fact that everything is okay inside it. Yes or no. 1 or 0. If you have a finite number of commands that need to be executed inside the container, and docker-compose.yml , which describes dependencies, this can be easily automated and unified especially without immersing yourself in the implementation details.
For example, like this !
Here, by testing, I mean not only, and not so much a unit, but any other testing, including functional, integration, code testing for code ( code style ) and duplication, checking outdated dependencies, violation of licenses of used packages, and much more. Emphasis should be placed on the fact that all this should be encapsulated inside your Docker image.Shipping Systems
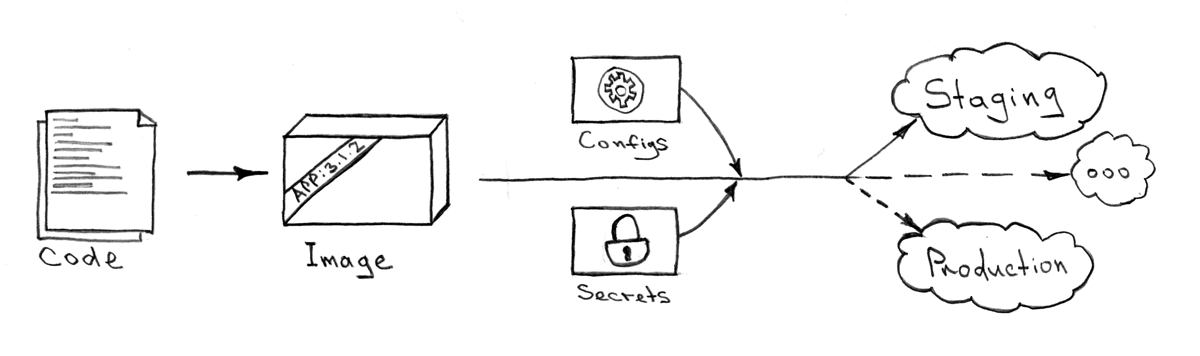
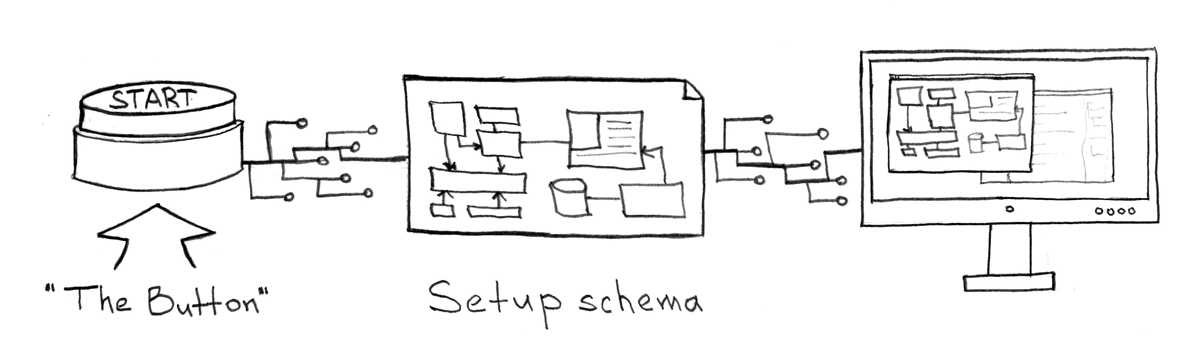
No matter when and where you want to install your child. The result, exactly as the installation process, must always be the same. There is also no difference what part of the whole ecosystem or from which git repository you will do it. Idempotency here is the most important component. The only thing that needs to be set is the installation control variables.
The algorithm, which seems to me the most effective, for solving this problem:
- Collect images from all
Dockerfile(For example, like this ) - With the help of a meta-project, deliver these images to Kubernetes via Kube API . Delivery start usually requires several input parameters:
- Kube API endpoint
- resource of secrets - they usually differ in different contexts (local / showroom / staging / production)
- names of systems for display and Docker tags of images for these systems (obtained in the previous step)
As such a single meta project for all systems and services (a project describing how an ecosystem works and how changes are delivered to it), I prefer to use Ansible playbook and with this module to integrate with KubeAPI. However, sophisticated automators can afford many other options - I will give my own below. The only thing you should not forget is a centralized / unified way to manage architecture. This allows you to conveniently and consistently manage all services / systems and stop any manifestations of the upcoming zoo from technologies and systems performing similar functions on takeoff.Usually setting the environment is required in:
- "ShowRoom" - for some manual checks or debugging of the system
- "Staging" - for near-combat environments and integration with external systems (usually located in the DMZ as opposed to
ShowRoom) - "Production" - the actual environment for the end user
Continuity in integration and delivery

Having a unified way of testing "black boxes" - our Docker images, we must assume that the result obtained by such tests allows us to seamlessly integrate a feature-branch into an upstream or master branch of the git repository with a clear conscience.
The only sticking point with this approach is the sequence in which we have to do the integration and delivery. And in the absence of releases, the question of how to prevent the "race condition" on the same system with multiple parallel feature-branch .
The following process must be launched in the non-competitive mode, otherwise the "race condition" will not give you peace of mind:
- Trying to upgrade
feature-branchtoupstream(git rebase/merge) - We collect images from
Dockerfile- - We test all collected images
- Run and wait for the delivery of the required systems with the images from step 2
- If the previous step fails or due to external factors, we roll back the eco-system to the previous state.
- Merge
feature-branchintoupstreamand send to repository
Any failure and at any step should interrupt the delivery process and return the task to the developer to solve the problem, be it "not passed" tests or problems merging branches.
The same recipe implies the ability to work with more than one repository. For this, the whole process should be carried out for all repositories in order of the steps of the algorithm, rather than repeatedly and iteratively for each repository separately.
In addition, Kubernetes allows you to roll out updates in part for various AB tests and problem analysis. This is achieved by internal means and separation of services (access points) and applications directly. You can always balance the new and old version of the component in the right proportions for analyzing problems and possible rollbacks.
Rollback system
Any deployment must be reversible - it is a mandatory requirement that applies to our architectural framework. This entails a lot of obvious and not very nuances of developing systems.
Here are some of the most important ones:
- The service should be able to customize its environment exactly as it rolls back changes. For example: database migrations, schema in RabbitMQ, etc.
- If it is impossible to roll back the environment, it must be polymorphic and support both the old and the new version of the code. For example: database migrations should not disrupt the operation of the old version of the service in several generations (usually 2 or 3 generations are enough)
- Backward compatibility of any service update. Usually these are: API compatibility, message formats, etc.
Rolling back states in the Kubernetes cluster is quite simple ( kubectl rollout undo deployment/some-deployment and kubernetes will restore the previous "cast"), but the meta project must contain information about this as well. More complex delivery rollback algorithms are highly discouraged, although sometimes necessary.What can cause the launch of this mechanism:
- High percentage of application errors after release
- Signals from key monitoring points
- Not passed
smoketests - Manual Mode - Human Solution
Information security and audit
It is impossible to isolate a separate process that will “create” one hundred percent safety of your ecosystem from both external and internal threats, but it is worth noting that the architectural framework must be made with an eye to the company's standards and security policies at each level and in all subsystems.
Next, I will consider in more detail all three levels of the proposed solution when I describe monitoring and alert, which are also cross-cutting and have fundamental significance in terms of the integrity of the system.
Kubernetes has a set of very good built-in mechanisms for differentiating access rights , network policies , event auditing and other powerful tools related to information security. With proper perseverance, you will be able to build an excellent perimeter of defense that can stand up and prevent a single attack or data leak from being successful.
From processes to architecture
This hard link between the development processes and the eco-environment that you are trying to build should not give you peace of mind. By adding to the classical requirements for the architecture of information systems (flexibility, scalability, availability, reliability, protection from threats, etc.), a request for good integration with the development and delivery processes, you multiply the value of such an architecture.
The tight integration of development processes and the ecosystem has long given rise to such a thing as DevOps ( Dev elopment Op eration s ), which in fact is a logical step towards total automation and infrastructure optimization. However, if you have a well-thought-out architecture and high-quality subsystems of your platform, DevOps tasks should be kept to a minimum.
Microservice architecture
I suppose there is no need to go into the details of the benefits of the Service Oriented Architecture ( SOA ), but also why these services should be micro. Let me just say that if you decide to use Docker and Kubernetes, you should most likely understand (and accept) that in this world it is very difficult to be a huge monolith and, I would say, ideologically wrong.
Docker, which is designed to run a single process and work with persistence, forces us to think in the framework of DDD (Domain Driven Development) and treats the packaged code as a black box with access ports sticking out.
Essential components and ecosystem solutions
From my practice of designing systems of increased availability and reliability, I would single out several components that are practically necessary for the operation of microservices.
Despite the fact that all the components and their descriptions below are shown in the context of the Kubernetes environment (which is key in terms of approach and architecture in this article), you can refer to this list and as a checklist for any other platform.
If you (like me) come to the conclusion that it would be nice to manage the service services described below as usual Kubernetes services, then the recommendation would be for this to be a stand-alone cluster or a cluster other than "production". For example, you can use a "staging" cluster, which will protect you from a situation where the "combat" environment is not stable, but should still have a source of code, code or monitoring. In other words, this way you solve the problem of "chicken and eggs"
Identity service
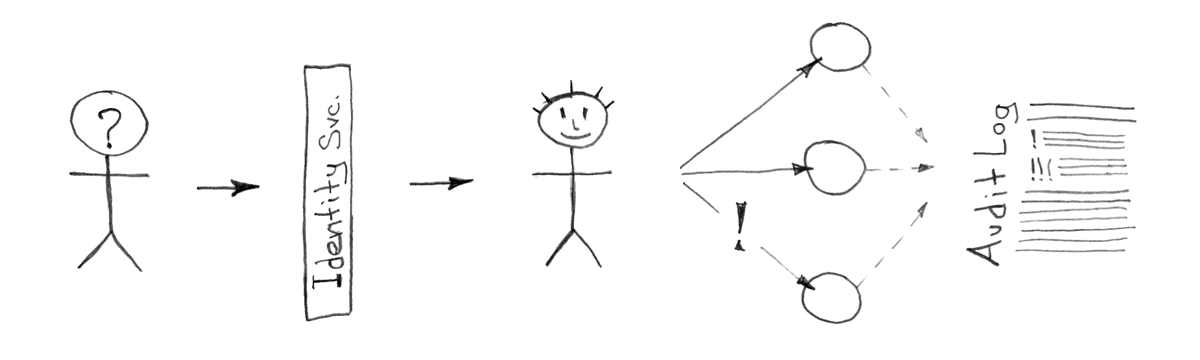
Everything usually begins with access, access to servers, virtual machines, applications, office mail, etc. If you are (or want to become) a client of one of the large corporate platforms (such as IBM, Google or Microsoft), then most likely this problem will be solved for you by the corresponding services of these vendors. But what to do if this is not your way, and you want to have your own solution that is managed only by you and preferably accessible on a budget?
This list should help you decide on the necessary option and understand the labor costs for installation and maintenance. This choice must be unconditionally coordinated with the company's security policy and approved by the (information) security service.
Automated server provisioning
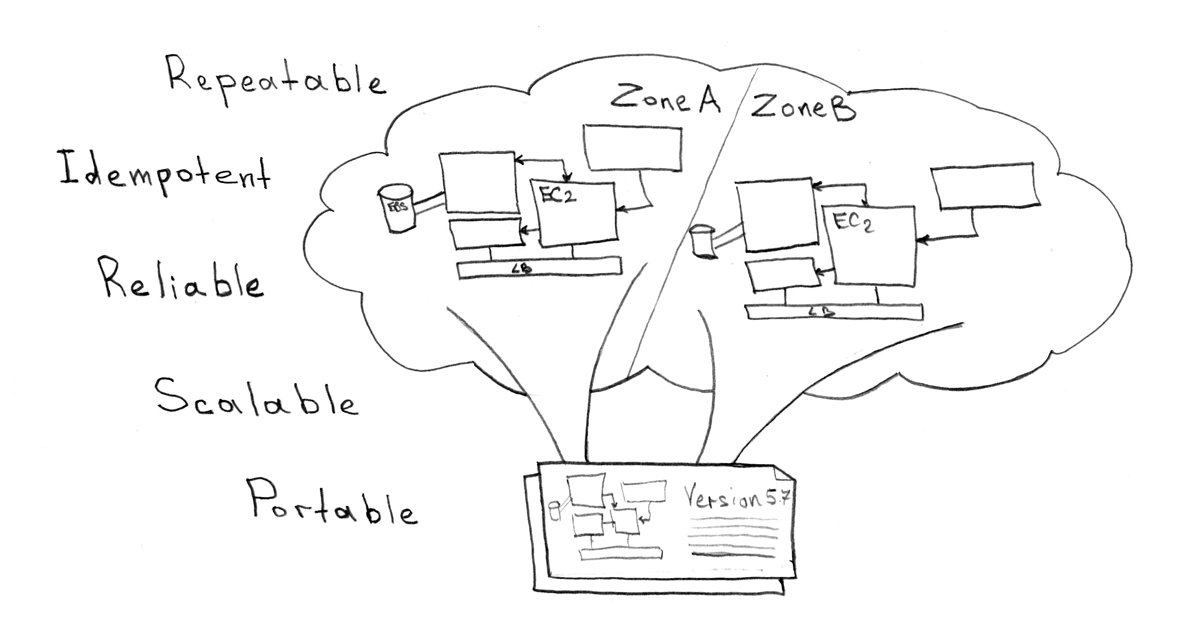
Although Kubernetes requires a very small number of components on physical machines / cloud VMs (docker, kubelet, kube proxy, etcd cluster), you should automate the addition of new machines and cluster management. Several options for mechanisms to make it easy and simple:
- KOPS - the tool allows you to install a cluster on one of two cloud providers - AWS or GCE
- Teraform - as a whole allows to manage the infrastructure for any environment and follows the ideology of IAC ( I nfrastructure a s C ode, infrastructure as a code)
- Ansible is a tool of even wider range of applications and serves for automation of any kind.
I want to note that from the proposed list, as mentioned above - in the section on system delivery, I prefer the latter option (with a small module for integration with Kubernetes ), since it allows the most flexibility to work with servers, and with k8s objects, and generally implement any kind of automation. However, nothing prevents you from using, for example, Teraform and its module for Kubernetes . KOPS is not fully applicable to work on bare metal, however, in my opinion, the ideal tool for working with AWS / GCE!
Git repository and task tracker
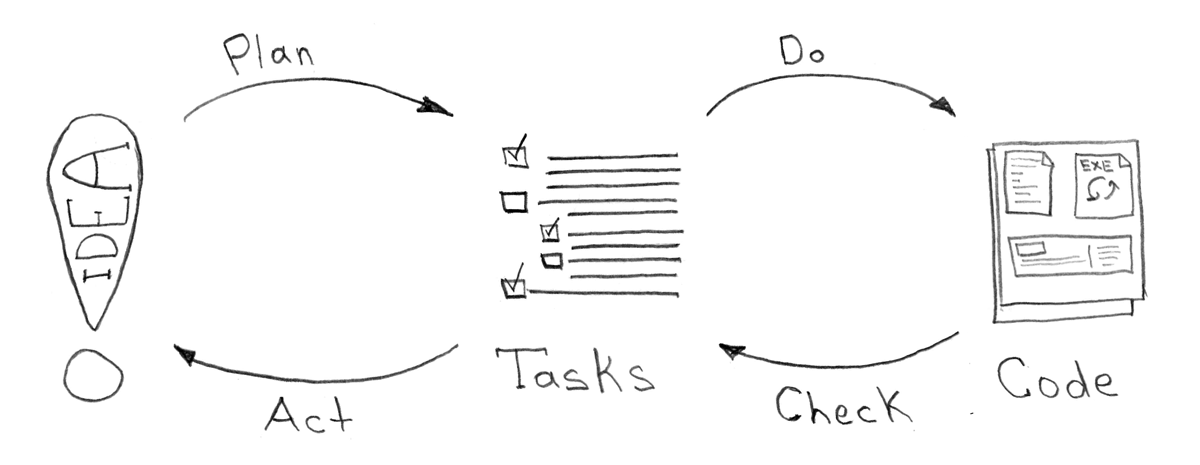
Needless to say, for the full-fledged work of developers and other related roles, it is necessary to have a place for collaboration, discussions of storing code. It is difficult to answer the question about the best service for this, I can only mention that for me as a task tracker classically is a free redmine or paid Jira and a free old-school gerrit or paid bitbucket
It is worth paying attention to the two most consistent, but commercial, stacks for collaborative corporate work: Atlassian and Jetbrains . You can use one of them completely or combine different components in your solution.
To ensure the greatest effect of using the tracker and repository, you should keep in mind the strategies for working and integrating these two entities. For example, a couple of tips to ensure the integrity of the code and related tasks (of course you can choose your strategies):
- The ability to "push" to a remote repository should only be in the branch with the task number (
TASK-1/feature-34) - Any branch should be blocked and not available for updates if the corresponding task is not in the "In Progress" status or similar.
- The branch should be available for merging only after a certain number of positive review codes.
- Any steps intended for automation should not be available to developers directly.
masterbranch should be available for direct modification only by privileged developers - everything else is available only to the “automaton” robot.- The branch should not be available for merging if the corresponding task is in a status other than "For Delivery" or the like.
Docker registry
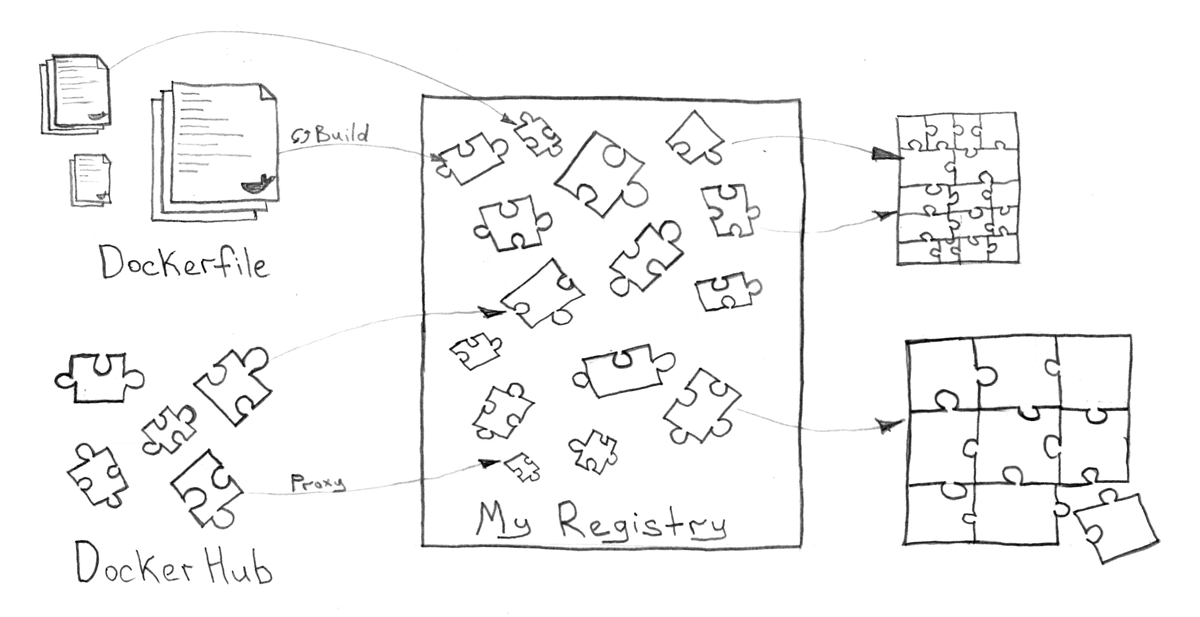
The function of managing Docker images must be separately identified, as it is of great importance for the storage and delivery of services. In addition to this, such a system should support work with users, groups and access, be able to delete old and unnecessary images, provide a GUI and a restful API.
You can use both cloud solutions (for example, hub.docker.com ), and any private service that can be installed even within the Kubernetes cluster itself. Vmware Harbor , which is positioned as a corporate solution for the Docker Registry, can become a rather interesting service for this. At the worst, you can do the usual Docker Registry if you don’t really need a complex system and just want to store images.
CI / CD service and service delivery system
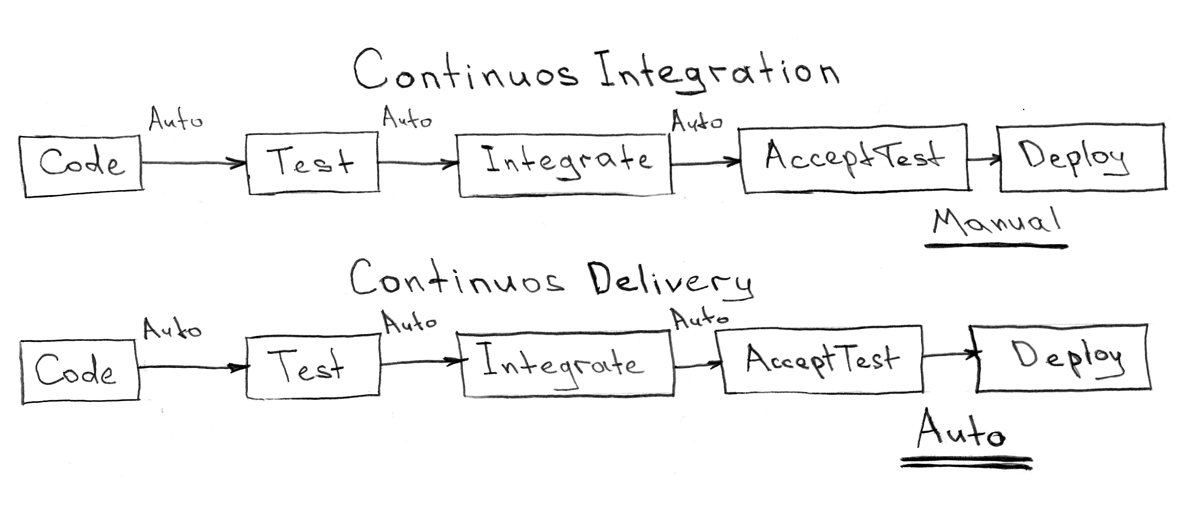
All the components we talked about before (git repository, task tracker, meta-project with Ansible Playbooks, external dependencies) cannot exist separately suspended in a vacuum. To fill this vacuum should be just the service of continuous integration and delivery.
CI - Continuous Integration - Continuous Integration
CD - Continuous Delivery - Continuous Delivery
The service should be fairly simple and have no logic related to the delivery methods or system configuration. All that the CI / CD service has to do is respond to events from the outside world (change in the git repository, transition of the task to the task tracker), and start some actions described in the meta project. It is also a place that is the point of control of all repositories and a tool for managing them (merging branches, updates from upstream/master )
I am historically used to using quite a powerful and at the same time very simple tool from Jetbrains - TeamCity , but I don’t see any problems if you decide to use, for example, free Jenkins .
Based on the foregoing, in essence, in the whole scheme, there are only four main and one auxiliary process that the integration service should launch:
- Automatic testing of services - usually for a single repository, by changing the state of the branch or upon the occurrence of the status "Awaiting Autotests" (or similar)
- Service delivery - usually from a meta-project for a number of services (and therefore repositories), upon the occurrence of the "Awaiting Showroom" and "Awaiting Delivery" statuses for deploying the QA and "production" environments, respectively
- Rollback - usually from a meta-project for a specific part of a single service or a whole service upon the occurrence of an external event or trigger from a failed delivery process
- Deletion of services - required to completely remove the entire ecosystem from a single test environment (
showroom), after the status ofIn QA, when the environment is no longer needed - Assembling images (auxiliary process) - can be used either in the process for delivering services or independently, if you just need to assemble
Dockerimages and send them to the Docker Registry, often used for some widely used images (DB, shared services, not frequently changing services)
Log collection and processing system

The only way for any Docker container to make its own logs accessible is to write them in STDOUT or STDERR of the root process running in this container itself. In fact, for the developer of the service, it does not matter what happens next with this data, the main thing is that they are available when needed and preferably to a predictable point in the past. All responsibility here for fulfilling these expectations lies with the Kubernetes and those people who support the ecosystem.
In the official documentation, you can find a description of the basic, and generally not bad, strategy of working with logs, which will help you choose the necessary service for the aggregation and storage of a huge number of text data.
, fluentd , , Elasticsearch . , , , .
Elasticsearch , Docker .
Tracing

, "" " , ?!". , , , -, — , .
Opentracing Zipkin . , , , .
, "Trace Id" , , .., , .
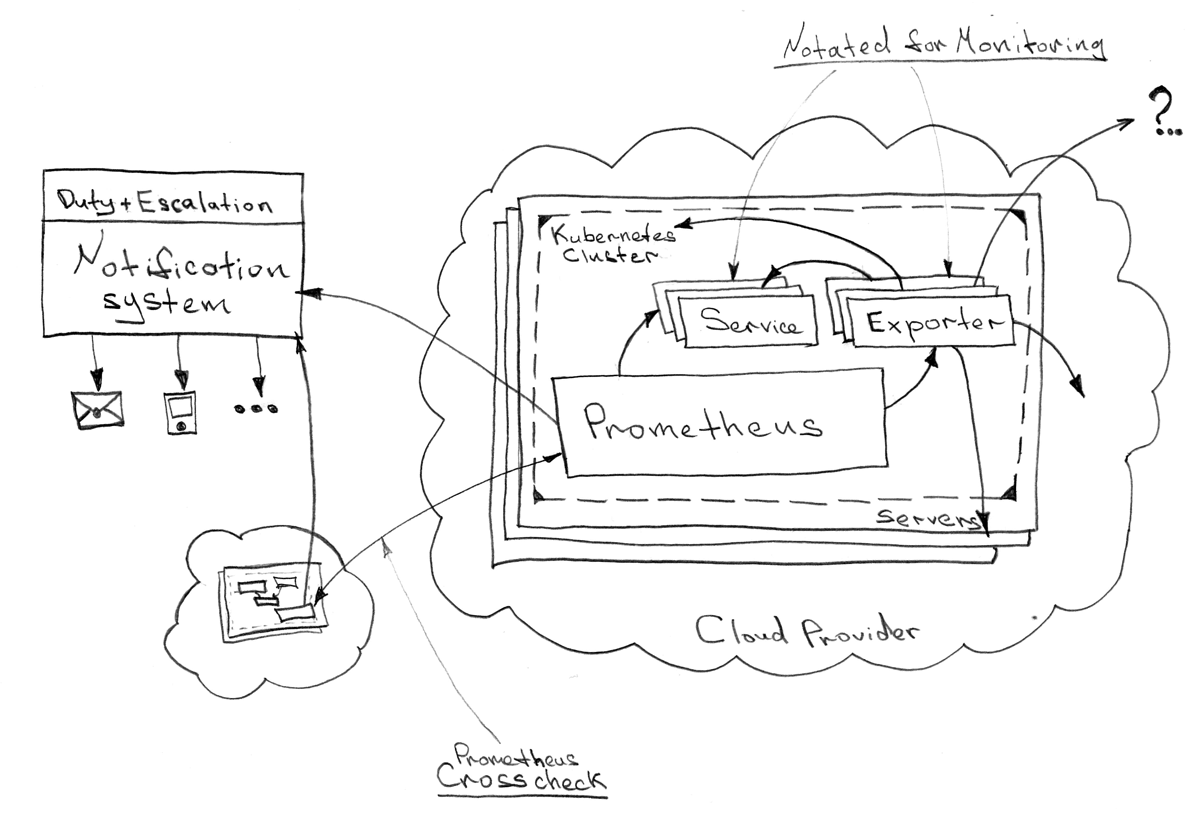
Prometheus - Kubernetes " " . Kubernetes , .
, , , , . ( ) ( "staging" ). "-" .
, , , :
- :
- (i/o, )
- (CPU, RAM, LA)
- :
- (kubelet, kubeAPI, DNS, etcd, ..)
pod-
- :
- API
- HTTP API
worker-- ( , , , ..)
- HTTP
- - ( )
, , email, SMS .
OpsGenie c alertmanager - Prometheus.
OpsGenie , , , . . , /: — Infra+Devops, — Devops, — .
API Single Sign-on
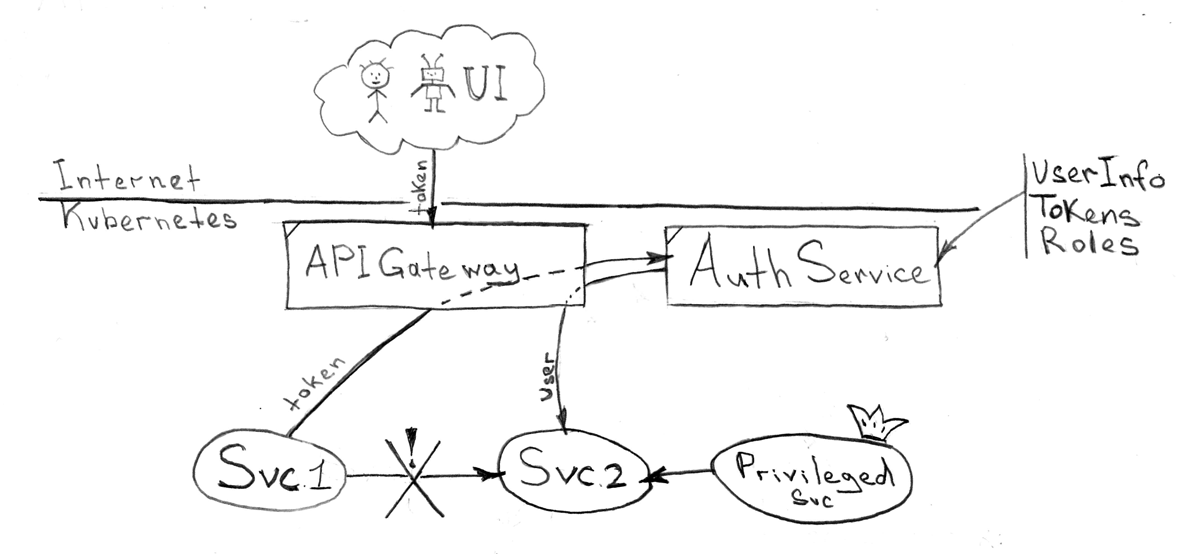
, , (, "Identity ", - ), , , API . , "Identity ", .
, . , . "" , HTTP .
API , - — . : UI , - . ( ), , UI . UI ( TTL) ( TTL)
, API :
- ( )
- c Single Sign-on :
- HTTP (ID, , )
- (/) Single Sign-on
- HTTP
- API (, Swagger json/yaml )
- URI
(Event Bus) (Enterprise Integration/Service Bus)
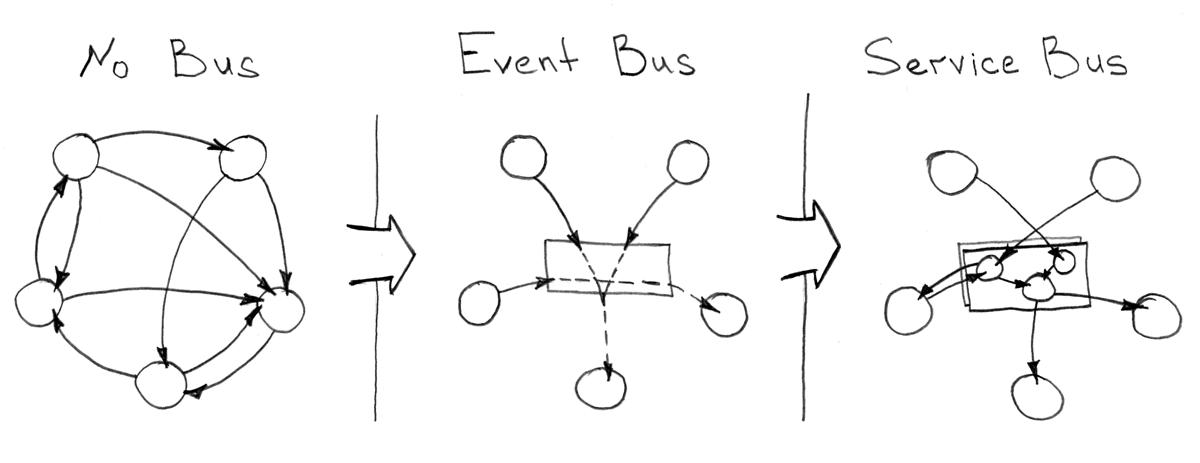
, -, . , , . , , - .
, : RabbitMQ , Kafka , ActiveMQ . , CAP - .
, , , " ", , "Dumb pipe — Smart Consumer" , .
"Enterprise Integration/Service Bus" , - . , :
- /
- ,
- ( )
, Apache ServiceMix , .
Stateful
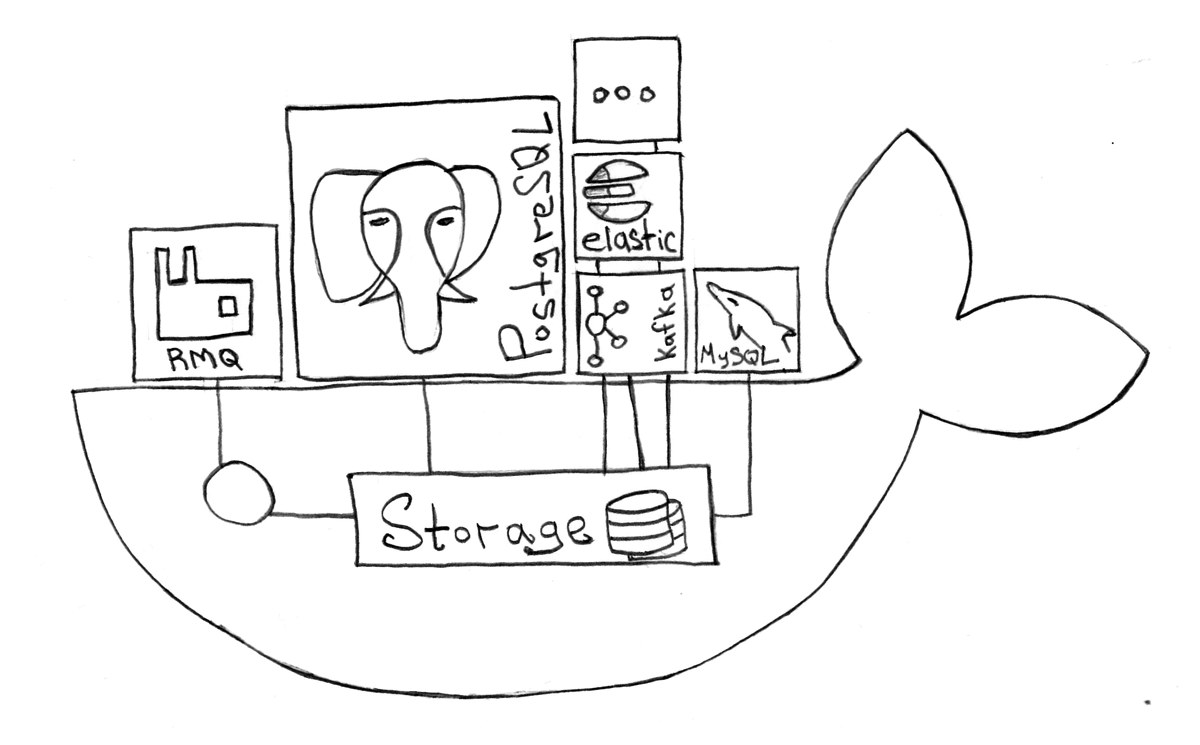
Docker, Kubernetes, , . , "" - … , "" "", , , Docker .
, , Kubernetes .
, Stateful , "":
- — PostDock Postgresql Docker
- / — RabbitMQ ,
cluster_formation - — redis
- — Elasticsearch , ,
- — (ftp, sftp ..)
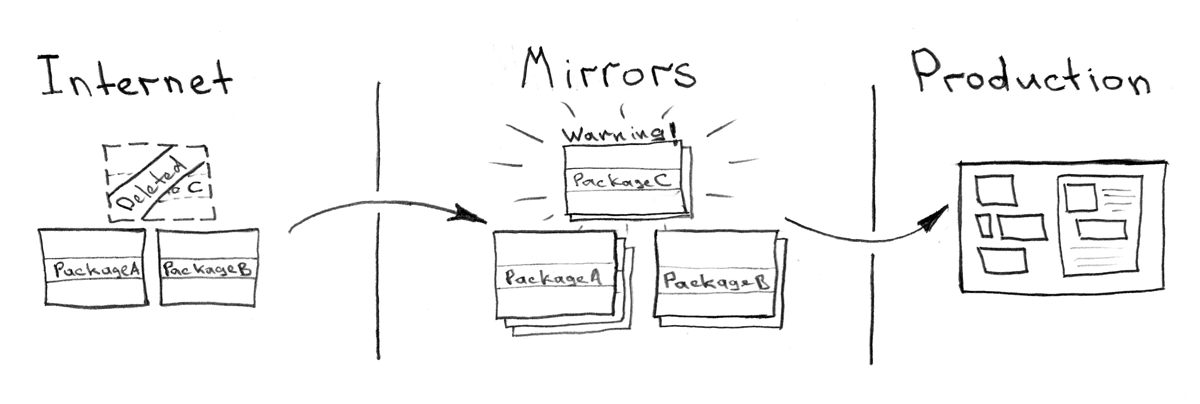
, , . , , — " ". : Docker , rpm , , python/go/js/php .
. , , " private dependency mirror for ... "
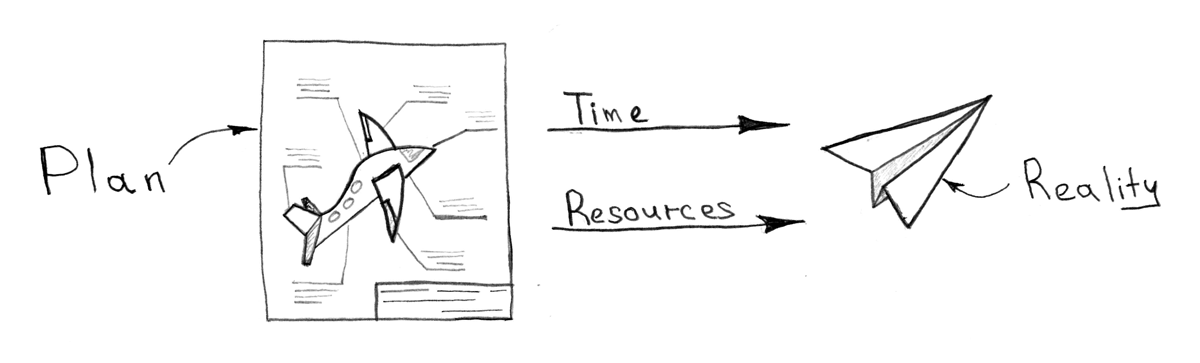
, , . : (1-5 ), — (5-10 ), — (10-20 ), .
, - , , , , , , .
, , . , . .
, . — , , .. , , , ( ), , " ", , !
" ?"…
— , - , , !
')
Source: https://habr.com/ru/post/321810/
All Articles