The success story of Yandex.Mail with PostgreSQL

Vladimir Borodin (on dev1ant Habré), the system administrator for the storage management group at Yandex.Mail, introduces the difficulties of migrating a large project from Oracle Database to PostgreSQL. This is a transcript of the report from the HighLoad ++ 2016 conference.
Hello! My name is Vova, today I will talk about the Yandex.Mail database.
')
First a few facts that will matter in the future. Yandex.Mail is a rather old service: it was launched in 2000, and therefore we have accumulated a lot of legacy. We have - as is customary and fashionable to say - quite a highload-service itself, more than 10 million users per day, some hundreds of millions in total. More than 200 thousand requests per second at the peak arrive to us in the backend. We add more than 150 million emails per day that have passed checks for spam and viruses. The total volume of letters for all 16 years is more than 20 petabytes.
What are we talking about? How we transferred metadata from Oracle to PostgreSQL. The metadata there is not petabytes - there are a little more than three hundred terabytes. More than 250 thousand requests per second fly into the bases. It should be borne in mind that these are small OLTP requests, mostly reading (80%).
This is not our first attempt to get rid of Oracle. At the beginning of zero was an attempt to move to MySQL, it failed. In 2007 or 2008 there was an attempt to write something of their own, it also failed. In both cases, there was a failure not so much for technical reasons, as for organizational reasons.
What is metadata? Here they are highlighted with arrows. These are folders, which are some kind of hierarchy with counters, tags (also, in fact, lists with counters), collectors, threads and, of course, letters.
We do not store the letters themselves in metabase, the body of the letters are in a separate repository. In meta database we store envelopes. Envelopes are some of the email headers: from whom, to whom, the subject of the letter, the date and the like. We store information about attachments and conversations.

Back to 2012
This was all in Oracle. We had a lot of logic in the database itself. Oraklovye bases were the most efficient hardware for recycling: we put a lot of data on the shard, more than 10 terabytes. Relatively speaking, with 30 cores, we have a normal working load average of 100. This is not when everything is bad, but under normal operation.
Baz was not enough, so much was done by hand, without automation. There were a lot of manual operations. To save money, we divided the bases into “warm” (75%) and “cold” (25%). “Warm” is for active users, they are with SSD. “Cold” - for inactive users, with SATA.
Sharding and resiliency is an important topic in Yandex. Sharding is because you don’t cram everything into one shard, but fault tolerance is because we regularly take and turn off one of our data centers to see that everything works.
How was this implemented? We have an internal BlackBox service (black box). When one request arrives on one of our backends, the backend exchanges authentication data - login, password, cookie, token or something like that. He goes with this in BlackBox, which, if successful, returns him the user ID and the name of the shard.
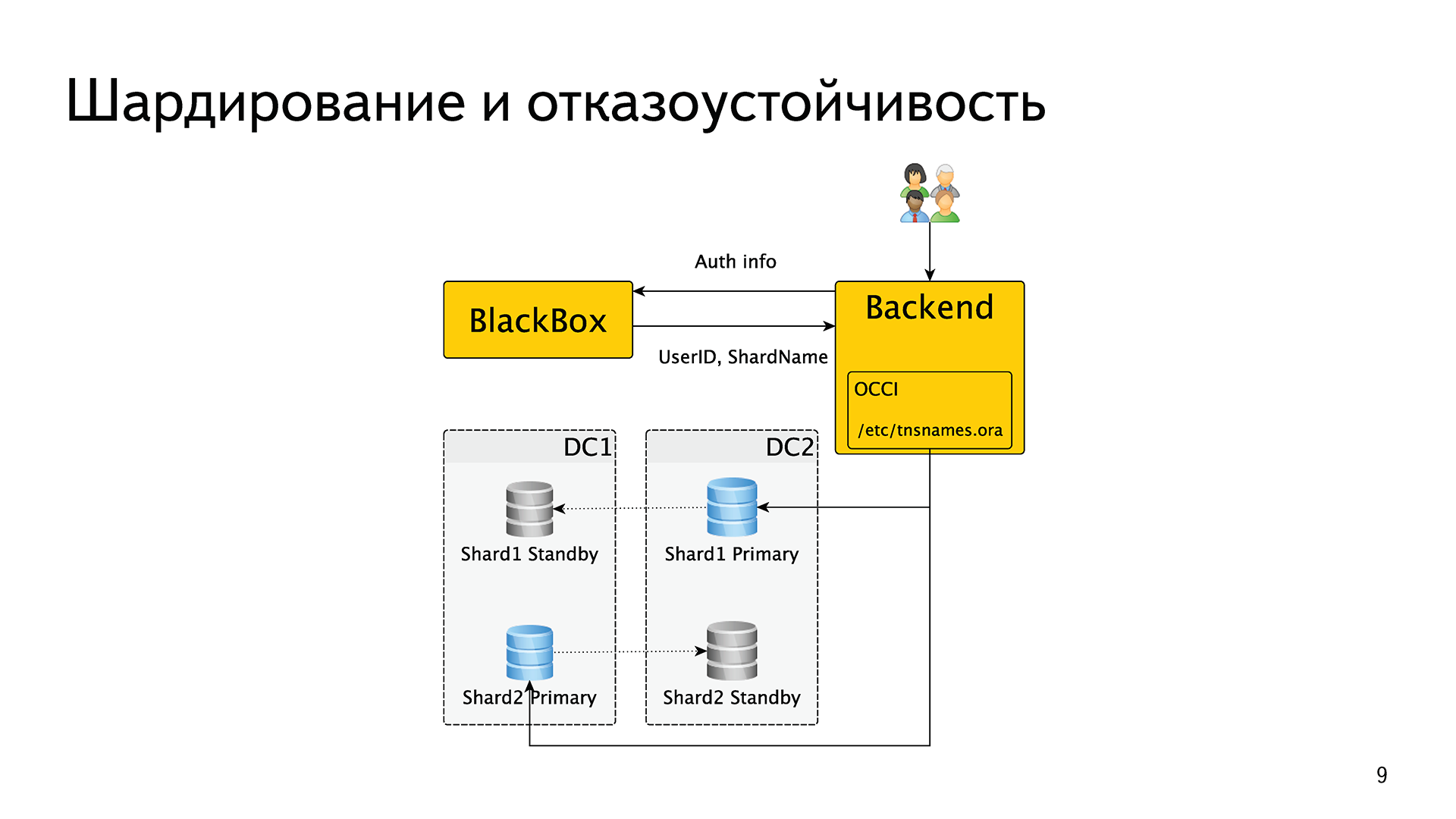
Then the backend fed this shard name to the OCCI driver, further inside this driver all the fault tolerance logic was implemented. That is, roughly speaking, in a special file /etc/tnsnames.ora a shardname and a list of hosts that enter this shard are stored, it is served. Oracle itself decided which master was one of them, who made a replica, who was alive, who was dead, etc. So, the sharding was implemented by means of an external service, and fault tolerance by means of an Oracle driver.
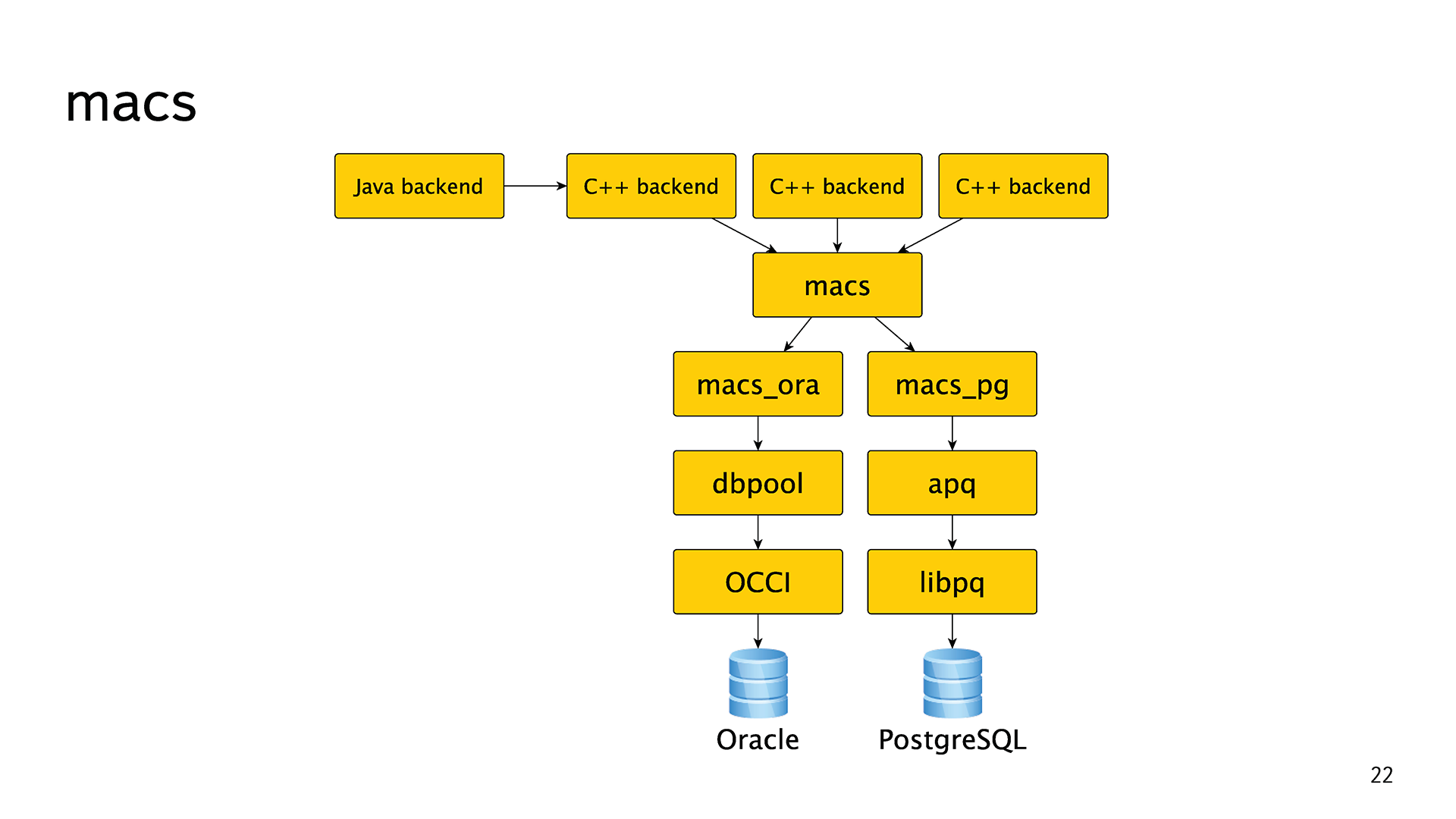
Most of the backends were written in C ++. In order not to produce “bicycles”, for a long time they had a common abstraction macs meta access. This is just an abstraction for going to the base. Almost all the time she had one macs_ora implementation for circulation directly in Oracle. At the very bottom, of course, is OCCI. There was also a small dbpool layer that implemented the connection pool.
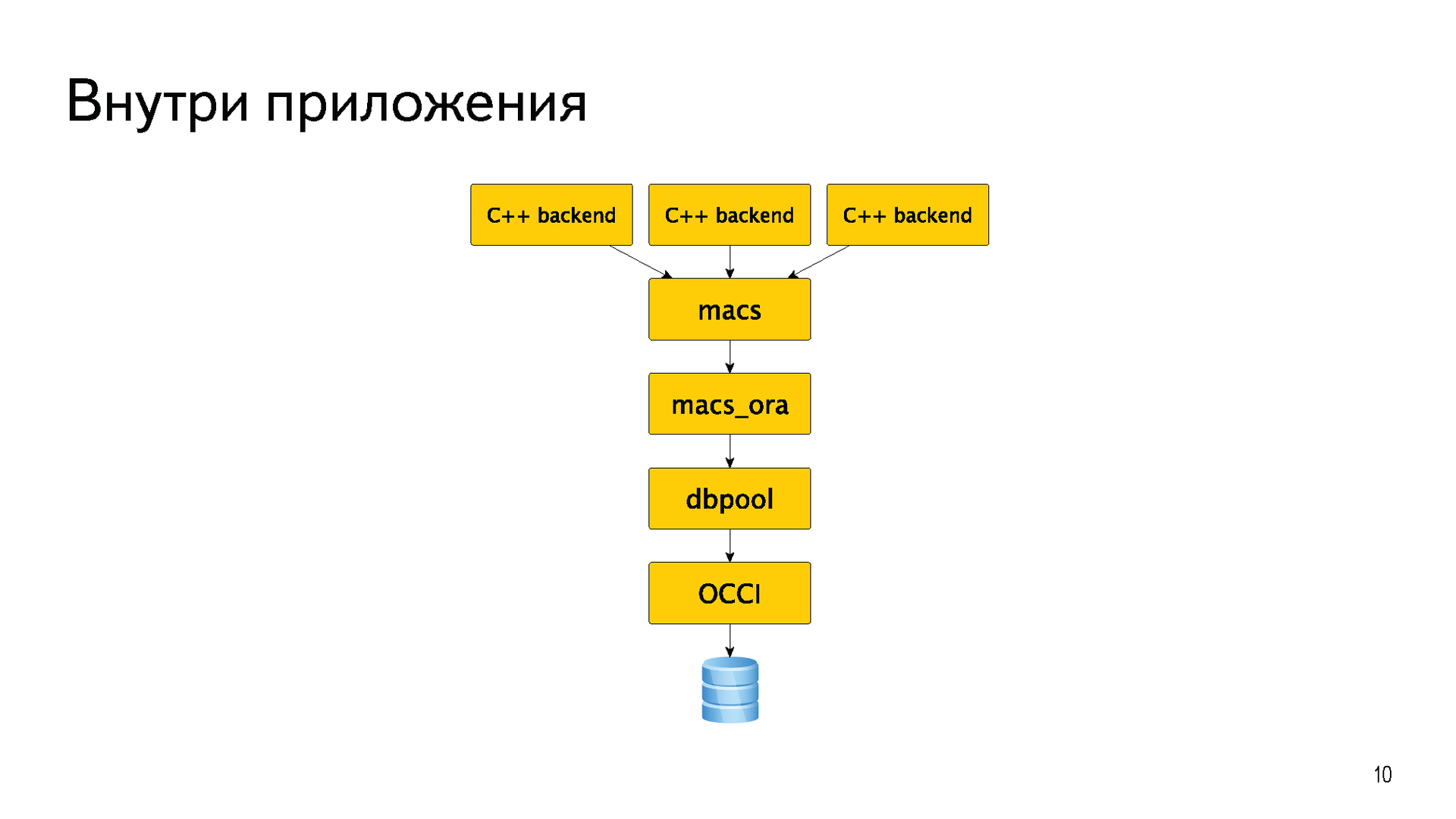
This is how it was once long conceived, designed and implemented. Over time, abstractions have leaked, backends have begun to use methods from the macs_ora implementation, and even worse from dbpool. There were Java and any other backends that could not use this library. All this noodles then had to painfully rake.
Oracle is a great database, but there were problems with it. For example, laying out PL / SQL code is a pain, because there is a library cache. If the database is under load, then you cannot simply take and update the function code that is currently being used by some sessions.
The remaining problems are associated not so much with Oracle, as with the approach we used. Again: a lot of manual operations. Switching masters, pouring in new databases, launching user migrations - everything was done by hand, because there were few bases.
From the development point of view, there is a disadvantage that the [C ++] plus driver has only a synchronous interface. That is, a normal asynchronous backend cannot be written on top. This caused some pain in the design. The second pain in the development was caused by the fact that raising the test base is problematic. First, because with hands, and second, because it is money.
No matter what anyone says, Oracle has support. Although support for enterprise-companies is often far from ideal. But the main reason for the transition is money. Oracle is expensive.
Chronology
In October 2012, more than 4 years ago, it was decided that we should get rid of Oracle. There were no words PostgreSQL, did not sound any technical details - it was a purely political decision: to get rid of, period of 3 years.
After six months, we began the first experiments. What have been spent these six months, I can tell you a little later. These six months have been important.
In April 2013, we experimented with PostgreSQL. Then there was a very fashionable trend for all sorts of NoSQL solutions, and we tried many different things. We remembered that we have all the metadata already stored in the search backend by mail, and maybe you can use it. This solution was also tried.
The first successful experiment was with collectors, I talked about it at a meeting in Yandex at 2014 .
We took a small piece (2 terabytes) of fairly loaded (40 thousand queries per second) mail metadata and took them from Oracle to PostgreSQL. That piece which is not so connected with the main metadata. We did it and we liked it. We decided that PostgreSQL is our choice.
Next, we wrote down a prototype of the mail scheme for PostgreSQL and began to add the entire stream of letters to it. We did it asynchronously: we folded all 150 million letters a day in PostgreSQL. If the laying failed, then we would not care. It was a pure experiment, he did not touch the production.
This allowed us to test the initial hypotheses with the scheme. When there is data that is not a pity to throw out - it is very convenient. I made some kind of scheme, stuffed letters into it, saw that it was not working, dropped everything and started anew. Excellent data that can be dropped, we love these.
Also, thanks to this, it turned out to some extent to carry out load testing right under the live load, and not by some kind of synthetics, not on individual stands. So it turned out to make an initial estimate of the iron, which is needed for PostgreSQL. And of course, experience. The main goal of the previous experiment and prototype is experience.
Then the main work began. Development took about a year of calendar time. Long before it ended, we moved our mailboxes from Oracle to PostgreSQL. We always understood that there would never be such a thing that we would show everyone for one night “sorry, technical work”, transfer 300 terabytes and start working on PostgreSQL. It does not happen. We would definitely break down, roll back, and everything would be bad. We understood that there would be a rather long period of time when some of the boxes would live in Oracle, and some in PostgreSQL, there would be a slow migration.
In the summer of 2015, we moved our boxes. The “Mail” team, which writes it, tests it, admins, and so on, transferred its boxes. This has greatly accelerated development. The abstract Vasya suffers, or you suffer, but you can correct it - these are two different things.
Even before we added and implemented all the features, we began to carry inactive users. We call inactive such a user, to whom the mail arrives, we fold the letters, but he does not read them: neither the web, nor the mobile, nor IMAP - they are not interested in him. There are such users, unfortunately. We began to carry such inactive users when, for example, IMAP was not yet fully implemented, or half the pens in the mobile application did not work.
But this is not because we are so bold and decided to break all the boxes, but because we had a plan B in the form of a reverse transfer, and it helped us a lot. There was even automation. If we moved a user, and he suddenly tried, for example, to log in to the web interface, he woke up and became active - we transferred him back to Oracle, so as not to break any features for him. This allowed us to fix a bunch of bugs in the transfer code.
Then followed the migration. Here are some interesting facts. We spent 10 man-years in order to rewrite all our noodles, which we have accumulated over 12-15 years.
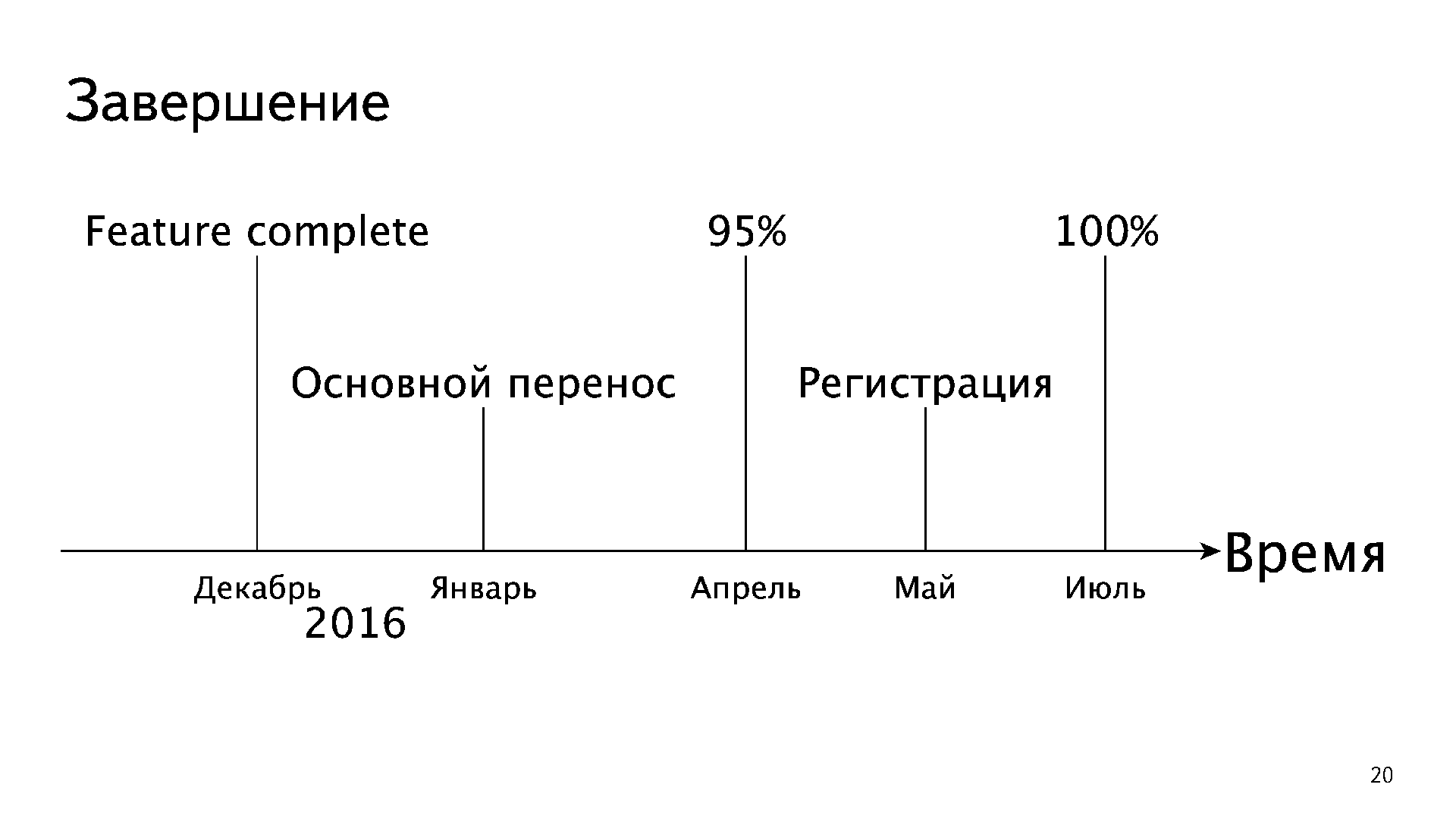
The migration itself took place very quickly. This is a 4 month schedule. Each line is the percentage of the load that the service renders from PostgreSQL. Split into services: IMAP, web, POP3, tab, mobile and so on.

Unfortunately, the abyss can not be jumped by 95%. We could not move all of them by April, because the registration remained at Oracle, this is a rather complicated mechanism. It turned out that we registered new users in Oracle and immediately transferred them to PostgreSQL at night. In May, we filed the registration, and in July, we had already extinguished all the Oracle databases.
Major changes
In our abstraction, another macs_pg implementation appeared, and we unraveled all the noodles. All those leaked abstractions had to be carefully rewritten. At the bottom of her libpq, we made a small layer apq, where the connection pool, timeouts, error handling are implemented, and everything is asynchronous.
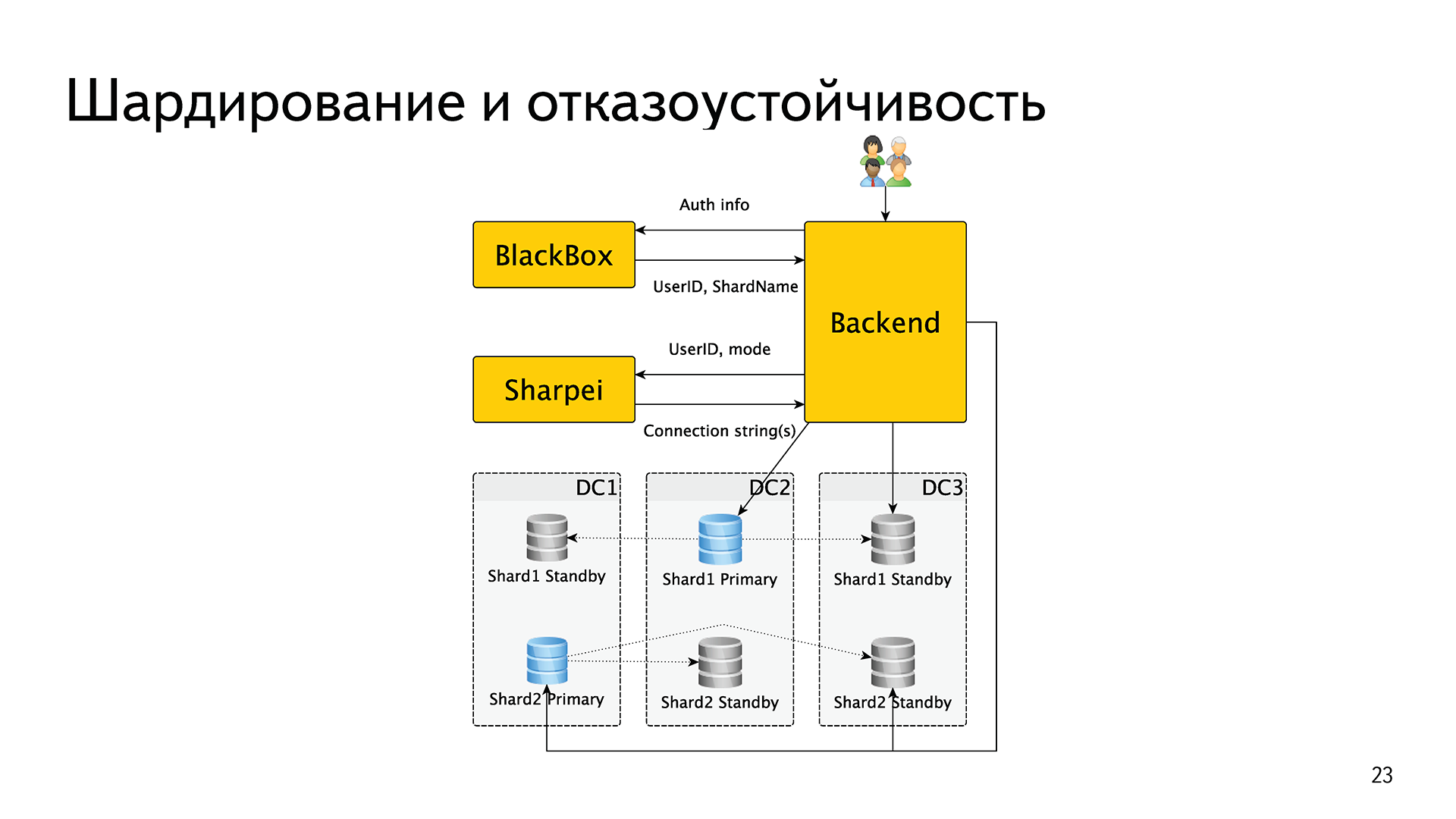
Sharding and fault tolerance are all the same. The backend receives authentication data from the user, exchanges them in BlackBox for a user ID and shard name. If the name of the shard has the letter pg, then it makes another request to the new service, which we call Sharpei. The backend transmits there the identifier of this user and the mode in which he wants to get the base. For example, “I want a master”, “I want a synchronous replica” or “I want the nearest host”. Sharpei returns him connection strings. Next, the backend opens the connection, holds it and uses it.
To know the information, who is the master, who is the replica, who is alive, who is dead, who is behind, who is not, Sharpei goes to the final bases once a second and asks for their statuses. At this point, a component appeared that took on both functions: sharding and fault tolerance.
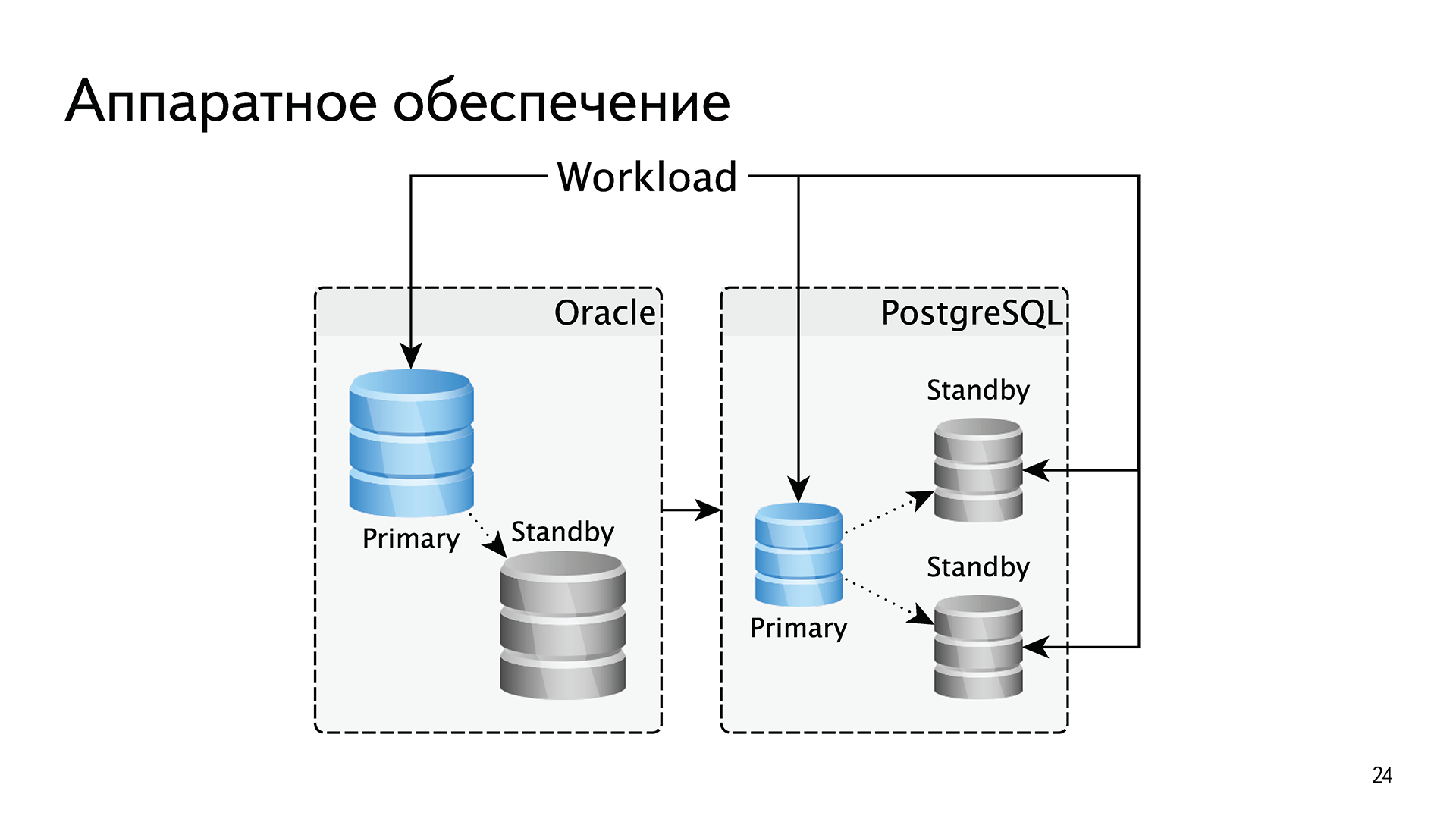
In terms of iron, we made a few changes. Because Oracle is licensed by processor cores, we had to scale vertically. On one processor core, we crammed a lot of memory, a lot of SSD-drives. There was a small number of databases with a small number of processor cores, but with huge arrays of memory and disks. We have always had strictly one replica for resiliency, because all subsequent ones are money.
In PostgreSQL, we changed the approach. We began to make smaller bases and two replicas in each shard. This allowed us to wrap up reading loads on replicas. That is, in Oracle everything was serviced from the wizard, and in PostgreSQL - three machines instead of two smaller ones, and we wrapped the reading in PostgreSQL. In the case of Oracle, we scaled vertically; in the case of PostgreSQL, we scaled horizontally.
In addition to the “warm” and “cold” bases, there appeared also “hot” ones. Why? Because we suddenly discovered that 2% of active users create 50% of the load. There are some bad users who are raping us. We made separate bases for them. They are not much different from warm ones, there are also SSDs there, but they are smaller by one processor core, because the processor is more actively used there.
Of course, we wrote down the automation of the transfer of users between shards. For example, if a user is inactive, now lives in a satashnoy [with SATA drive] base and suddenly started using IMAP, we will transfer it to the “warm” base. Or if he doesn't move in a warm base for half a year, then we will transfer him to the “cold” one.
Moving old emails of active users from SSD to SATA is what we really want to do, but we cannot yet. If you are an active user, you live on an SSD and you have 10 million emails, they are all on an SSD, which is not very efficient. But so far in PostgreSQL there is no normal partitioning.
We changed all identifiers. In the case of Oracle, they were all globally unique. We had a separate base where it was written that in this shard such ranges, in this - such. Of course, we had a facac when, by virtue of an error, identifiers crossed, and about half of them were tied to their uniqueness. It was painful.
In the case of PostgreSQL, we decided to switch to a new scheme, when our identifiers are unique within a single user. If earlier the letter identifier was unique to the letter, now the uid mid pair is unique. In all the tablets we have the first field of uid, everything is prefixed to them, it is a part for now.
Besides the fact that it is less space, there is another unobvious plus. Since all these identifiers are taken from sequences, we have less competition for the last page of the index. In Oracle, we used reverse indexes to solve this problem. In the case of PostgreSQL, since the inserts go to different pages of the index, we use the usual B-Tree, and we have range scans, all the data of one user in the index are next to each other. It is very convenient.
We have introduced revisions for all objects. This made it possible to read from the replicas, firstly, the intact data, and secondly, the incremental updates for IMAP, mobile. That is, the answer to the question “what has changed in this folder since such a revision” has been greatly simplified.
In PostgreSQL, everything is fine with arrays, composites. We made a part of the data denormalization. Here is one example:
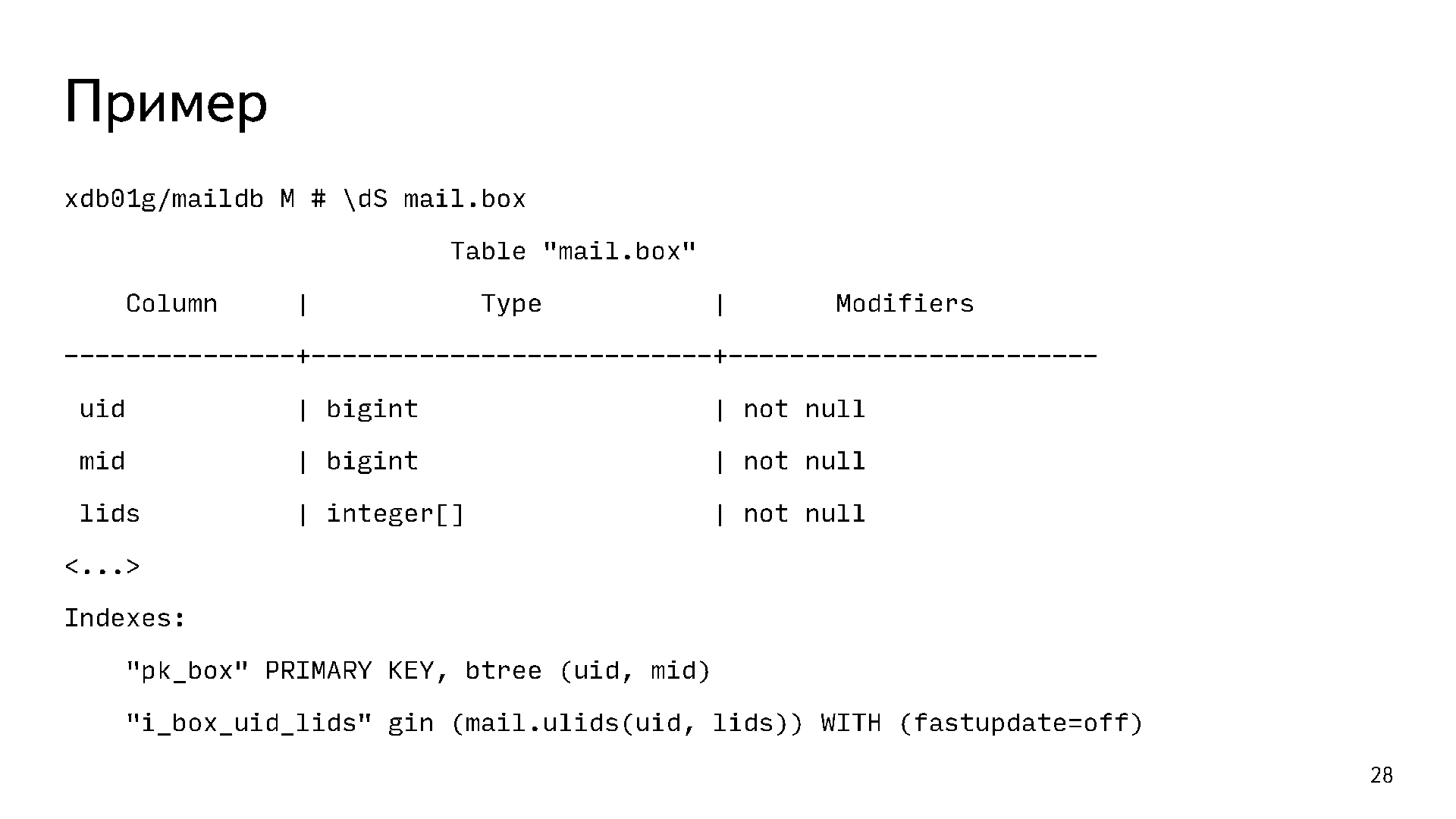
This is our main mail.box sign. It contains a line for each letter. Her primary key is a pair of uid mid. There is also an array of lids tags, because there can be more than one tag on one letter. At the same time, there is a task to answer the question “give me all the letters with such a tag”. Obviously, this requires some kind of index. If we build a B-Tree index by array, then it will not answer such a question. To do this, we use a clever gin functional index across the uid and lids fields. It allows us to answer the question "give me all the letters of such and such a user with such and such labels or with such and such a label."
Stored logic
- Since there was a lot of pain with stored logic from Oracle, we decided that PostgreSQL would not have stored logic at all, no. But in the course of our experiments and prototypes, we realized that PL / pgSQL is very good . It does not suffer from a problem with the library cache, and we did not find other very critical problems.
- At the same time, the amount of logic was greatly reduced , leaving only the one that is needed for the logical integrity of the data. For example, if you put a letter, then increase the counter in the plate with folders.
- Since there is no undo, the cost of the error has become much higher . In undo, we climbed a couple of times after laying out a bad code, about that my colleague Alexander did a separate report on our mitap .
- Due to the lack of library cache it is much easier to deploy . We ride a couple of times a week instead of quarterly, as it was before.
Service approach
- Since we changed the hardware and began to scale horizontally, we changed the approach to serving the bases. Bases we now rule SaltStack . The most important feature of his killer feature for us is the opportunity to see a detailed diff between what is now on the base and what we expect from it. If the observed suits, the person presses the "roll out" button, and it rolls.
- We now change the schema and code through migrations . We had a separate report about it .
- We left the manual service, everything that was possible was automated . Switching masters, transferring users, pouring new shards, and so on - all this is by a button and very simple.
- Since deploying a new database is one button, we have received representative test environments for development. Each developer in the database, two, as he wants - it is very convenient.
Problems
Such things never pass smoothly.
This is a list of threads in the community with problems that we could not solve ourselves.
- Problem with ExclusiveLock on inserts
- Checkpoint distribution
- Shared_buffers
- Hanging startup process on the replica after vacuuming on master
- Replication slots and isolation levels
- Segfault in BackendIdGetTransactions
That is, we went to the community, and they helped us. It was a test of what to do when you do not have enterprise support: there is a community, and it works. And this is very cool. Of course, much more problems we decided on our own.
For example, we had a very popular joke: “The autovacuum is to blame for any incomprehensible situation”. We also solved these problems.
We really lacked a way to diagnose PostgreSQL. The guys from Postgres Pro filed us a wait-interface. I already told about it on PG Day in 2015 to St. Petersburg . There you can read how it works. With the help of the guys from Postgres Pro and EnterpriseDB, it was included in kernel 9.6. Not all, but some of these developments were included in 9.6. Further this functionality will be improved. In 9.6 columns appeared that allow much better understand what is happening in the database.
Surprise. We encountered a problem with backups. We have a recovery window of 7 days, that is, we should be able to recover at any time in the past for the last 7 days. In Oracle, the size of the space for all backups and archivogs was about the size of the database. Base 15 terabytes - and its backup for 7 days takes 15 terabytes.
In PostgreSQL, we use barman, and in it, for backups, you need space at least 5 times larger than the size of the base. Because WAL is compressed, but there are no backups, there are File-level increments that don’t really work, in general everything is single-threaded and very slow. If we were backing up as is these 300 terabytes of meta-data, we would need about 2 petabytes of backups. Let me remind you, the entire repository of "Mail" - 20 petabytes. That is, 10% we would have to cut off just under the backups of meta-databases for the last 7 days, which is a pretty bad plan.
We didn’t think of anything better and patched the barman, here’s a pull request . Almost a year has passed, as we ask them to file this killer feature, and they are asking for money from us to keep it up. Very arrogant guys. My colleague Eugene, who wrote down all this, talked about this on PGday in 2016 . It really shakes backups much better, speeds them up, there are honest increments.
According to the experience of the experiment, the prototype, and other databases that appeared on PostgreSQL by then, we expected a bunch of rakes during the transfer. And they were not there. There were many problems, but they were not related to PostgreSQL, which was surprising to us. It was full of problems with the data, because in 10 years a lot of legacy has accumulated. Suddenly, it was discovered that in some databases the data is encoded in KOI8-R, or other strange things. Of course, there were errors in the transfer logic, so the data also had to be repaired.
Completion
There are things that we really miss in PostgreSQL.
For example, partitioning to move old data from SSD to SATA. We lack a good built-in recovery manager to not use the batman fork, because it probably will never reach the core barman. We are already tired: we have been kicking them for almost a year, but they are not in a hurry. It seems that this should be not aside from PostgreSQL, but in the kernel.
We will develop the wait-interface . I think in the 10th version a quourum commit will happen, there is a patch in good condition. We also really want a normal work with the disk . In terms of disk I / O, PostgreSQL strongly loses Oracle.
What is the result? If you take into account the raid replicas, then we have more than 1 petabyte in PostgreSQL. Recently, I thought there were a little over 500 billion lines. There flies 250 thousand requests per second. In total, it took us 3 calendar years, but we spent more than 10 man-years. That is the effort of the whole team is quite impressive.
What did we get? It has become faster deployed, despite the fact that the databases have become much larger, and the number of DBA has decreased. The DBA for this project is now smaller than when Oracle was.
Whether we wanted to or not, we had to refactor all the backend code. All that legacy, which accumulated over the years, was cut out. Our code is cleaner now, and this is very good.
There is no tar without spoons. We now have 3 times more hardware for PostgreSQL, but this is nothing compared to the cost of Oracle. So far we have not had major fakapov.
A quick note from me. In the "Mail" we use a lot of open source libraries, projects and ready-made solutions. To the three chairs on which we sat tight, which we have almost everywhere - Linux, nginx, postfix - was added PostgreSQL. Now we use it for many bases in other projects. We liked him. Fourth - a good, reliable chair. I think this is a success story.
That's all I wanted to say. Thank!
Vladimir Borodin - The success story of Yandex.Mail with PostgreSQL
Source: https://habr.com/ru/post/321756/
All Articles