Incremental analysis in PVS-Studio: now also on the assembly server

Introduction
When implementing a static analyzer into an existing development process, the team may encounter certain difficulties. For example, it is very useful to check the modified code before it enters the version control system. However, performing static analysis in this case can take quite a long time, especially on projects with a large code base. In this article, we will look at the incremental analysis mode in the PVS-Studio static analyzer, which allows you to check only modified files, which significantly reduces the time required for code analysis. Consequently, developers will be able to use static analysis as often as necessary, and minimize the risk of code containing an error in the version control system. The reason for writing the article was, firstly, the desire to once again tell about such a useful function of our analyzer, and secondly, the fact that we completely rewrote the incremental analysis mechanism and added support for this mode to the version of our analyzer for the command line.
Static Analyzer Usage Scenarios
Any approach to improving software quality implies that defects should be detected as early as possible. In an ideal situation, the code needs to be written without any errors at all, but nowadays this practice has been successfully implemented only in one corporation:

Why is it so important to detect and fix errors as early as possible? I will not speak here about such trivial things as reputational risks that inevitably arise if your users begin to detect defects in your software in large quantities. Let's focus on the economic component of fixing errors in the code. We do not have statistics on the average price of the error. Errors are very different, are detected at different stages of the software life cycle, the software can be applied in different subject areas, both critical to errors and not so much. Therefore, although the industry average cost of correcting a defect depending on the stage of the software life cycle is unknown, it is possible to estimate the change in this cost using the well-known rule “1-10-100”. With regard to software development, this rule states that if the cost of eliminating a defect at the design stage is 1?, Then after transferring this code to testing will be already 10?, And it grows to 100? after the defect code is gone to production:
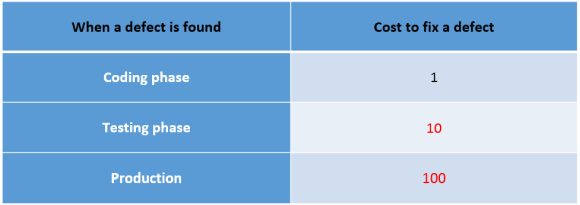
There are many reasons for such a rapid increase in the cost of correcting a defect, for example:
- Changes to one part of the code can affect many other parts of the application.
- Repeating tasks that have already been done: design changes, coding, documentation adjustments, etc.
- Delivery of the revised version to users, the need to convince users to upgrade.
Understanding the importance of eliminating errors at the earliest stages of the software life cycle, we offer our customers to use a two-level code verification scheme with a static analyzer. The first level is the verification of the code on the developer’s computer before the code is incorporated into the version control system. That is, the developer writes some piece of code and immediately inspects it with a static analyzer. For this task, we have a plugin for Microsoft Visual Studio (all versions from 2010 to 2015 are supported). The plugin allows you to check one or more source code files, one or several projects, or the entire solution.
')
The second level of protection is the launch of static analysis during the nightly build of the project. This allows you to make sure that new errors were not added to the version control system, or to take the necessary actions to correct these errors. In order to minimize the risk of errors penetrating into the later stages of the software life cycle, we propose to use both levels of static analysis: locally on the developers' machines and on the centralized server of continuous integration.
This approach, however, is not without flaws and does not guarantee that errors that can be detected by the static analyzer will not get into the version control system or, as a last resort, will be corrected before the build goes into testing. Forcing developers to manually perform static analysis before a commit will most likely encounter strong resistance. First, on projects with a large code base, no one wants to sit and wait until the project is verified. Or, if the developer decides to save time and check only those files in which he has changed the code, he will have to keep records of changed files, which, naturally, no one will do either. If we consider an assembly server, on which, besides nightly assemblies, an assembly is also set up after detecting changes in the version control system, then performing a static analysis of the entire code base during numerous daytime assemblies is also not applicable due to the fact that static analysis will take a long time .
An incremental analysis mode that allows you to check only recently modified files helps to solve these problems. Let us consider in more detail what advantages the incremental analysis mode can bring when used on developers' computers and on an assembly server.
Incremental analysis on the developer's computer - a barrier to bugs in the version control system
If the development team decided to use static code analysis, and the analysis is performed only on the build server, during, for example, nightly builds, sooner or later, the developers will begin to perceive the static analyzer as an enemy. It is not surprising, because all team members will see what mistakes their colleagues make. We strive to ensure that all project participants perceive the static analyzer as a friend and as a useful tool that helps improve the quality of the code. In order for errors that a static analyzer can detect, not to get into the version control system and for everyone to see, static analysis should also be performed on the developers' computers in order to detect possible problems in the code as early as possible.
As I already mentioned, manual launch of static analysis on the entire code base can take quite a long time. If the developer is forced to remember which files with the source code he worked on, it will also be very annoying.
Incremental analysis allows you to reduce the time it takes to perform a static analysis, and get rid of the need to manually run the analysis. Incremental analysis starts automatically after building a project or solution. We consider this trigger as the most suitable for launching the analysis. It is logical to check that the project is going, before making changes to the version control system. Thus, the incremental analysis mode allows you to get rid of the annoying actions associated with the need to manually perform static analysis on the developer's computer. Incremental analysis is performed in the background, so the developer can continue to work on the code, without waiting for the end of the test.
You can enable the post-assembly incremental analysis mode in the PVS-Studio / Incremental Analysis After Build (Modified Files Only) menu, this item is activated in PVS-Studio by default:
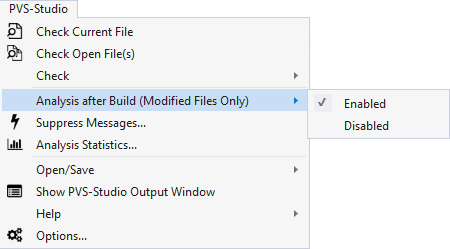
After activating the incremental analysis mode, PVS-Studio will automatically in the background analyze all the affected files immediately after the project has finished building. If PVS-Studio detects such modifications, the incremental analysis will be automatically launched, and the animated PVS-Studio icon will appear in the Windows notification area:
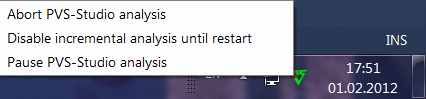
Details related to the use of incremental analysis are discussed in the article PVS-Studio's incremental analysis mode .
Incremental analysis on a continuous integration server - an additional barrier to bugs
The practice of continuous integration means that the project is assembled on the build server after each commit to the version control system. As a rule, besides the project build, the existing set of unit tests is also executed. In addition to unit tests, many teams that use the practice of continuous integration use an assembly server to provide continuous quality control processes. For example, in addition to running modular and integration tests, these processes may include performing static and dynamic analysis, measuring performance, etc.
One of the important requirements for the tasks performed on the continuous integration server is that the project must be built quickly and all additional actions must be completed so that the team can quickly respond to the detected problems. Performing static analysis on a large code base after each commit to a version control system is contrary to this requirement, since this can take a very long time. We did not agree to put up with this restriction, so we looked at our plug-in for Visual Studio, which already has an incremental analysis mode for a long time, and asked ourselves: why don't we implement the same mode in the command line module PVS-Studio_Cmd.exe ?
It is said - done, and in our module for the command line, which is designed to integrate the static analyzer into various building systems, an incremental analysis mode has appeared. This mode works the same way as incremental analysis in a plugin.
Thus, with the addition of support for incremental analysis in PVS-Studio_Cmd.exe, it became possible to use our static analyzer in the continuous integration system during numerous daily builds. Due to the fact that only the modified files will be checked since the last update of the code from the version control system, static analysis will be performed very quickly and the project will not be prolonged much longer.
To activate the incremental analysis mode in the module for the PVS-Studio_Cmd.exe command line, specify the --incremental key and set one of the following modes of operation:
- Scan - analyze all dependencies to determine which files should be used for incremental analysis. The analysis itself will not be performed.
- Analyze - perform incremental analysis. This step must be performed after the Scan step, and can be performed both before and after assembling the solution or project. Static analysis will be performed only for modified files since the last build.
- ScanAndAnalyze — analyze all dependencies to determine on which files the incremental analysis should be performed, and immediately perform an incremental analysis of the modified files with the source code.
For more information about the incremental analysis mode in the PVS-Studio_Cmd.exe command line module, refer to the PVS-Studio incremental analysis mode and Visual C ++ Verification (.vcxproj) and Visual C # (.csproj) projects from the command line using PVS-Studio .
I also want to note that the use of the BlameNotifier utility supplied in the PVS-Studio distribution is perfectly combined with the functionality of the incremental analysis. This utility interacts with popular version control systems (Git, Svn, and Mercurial are currently supported) to get information about which developer has committed code that contains errors and send notifications to these developers.
Thus, we recommend using the following scenario of using a static analyzer on a continuous integration server:
- for multiple daily builds, perform incremental analysis to control the quality of the code of the modified files only;
- for nightly assembly, it is advisable to perform a full analysis of the entire code base in order to have complete information about defects in the code.
Features of the implementation of the incremental analysis mode in PVS-Studio
As I have already noted, the mode of incremental analysis in the PVS-Studio plugin for Visual Studio has existed for a long time. In the plugin, the definition of modified files for which incremental analysis should be performed was implemented using Visual Studio COM wrappers. This approach is absolutely inapplicable to the implementation of the mode of incremental analysis in the version of our analyzer for the command line, since it is completely independent of the internal infrastructure of Visual Studio. Support for different implementations that perform the same function in different components is not a good idea, so we immediately decided that the plugin for Visual Studio and the command line utility PVS-Studio_Cmd.exe would use a common code base.
Theoretically, the task of detecting modified files since the last build of the project is not particularly difficult. To solve this problem, we need to obtain the modification time of the target binary file and the modification time of all the files that participated in the construction of the target binary file. Those source code files that were modified later than the target file should be added to the list of files for incremental analysis. The real world, however, is much more complicated. In particular, for projects implemented in C or C ++, it is very difficult to identify all the files that participated in the construction of the target file, for example, those header files that were directly connected in the code and are not in the project file. Here I want to note that under Windows and our plug-in for Visual Studio (which is obvious), the command-line version PVS-Studio_Cmd.exe only supports the analysis of MSBuild projects. This fact greatly simplified our task. It is also worth mentioning that in Linux version of PVS-Studio it is also possible to use incremental analysis - there it works out of the box: when using compilation monitoring, only the collected files will be analyzed. Accordingly, with incremental build, incremental analysis will start; with direct integration into the build system (for example, in make files), the situation will be similar.
MSBuild has a file tracking mechanism ( File Tracking ). For an incremental build of projects implemented in C and C ++, correspondences between source files (for example, cpp files, header files) and target files are recorded in * .tlog files. For example, for a CL task, the paths to all source files read by the compiler will be written to the CL.read. {ID} .tlog file, and the paths to the target files will be stored in the CL.write. {ID} .tlog file.
So, in the CL. *. Tlog files we already have all the information about the source files that were compiled and the target files. The task is gradually simplified. However, it still remains the task to bypass all the source and target files and compare the dates of their modification. Is it possible to simplify more? Of course! In the Microsoft.Build.Utilities namespace , we find the classes CanonicalTrackedInputFiles and CanonicalTrackedOutputFiles , which are responsible for working with the CL.read. *. Tlog and CL.write. *. Tlog files, respectively. Creating instances of these classes and using the method CanonicalTrackedInputFiles.ComputeSourcesNeedingCompilation , we obtain a list of source files that need to be compiled, based on the analysis of the target files and the dependency graph of the source files.
Here is an example of code that allows you to get a list of files on which to perform an incremental analysis, using the chosen approach. In this example, sourceFiles is a collection of full normalized paths to all project source files, tlogDirectoryPath is the path to the directory where * .tlog files are located:
var sourceFileTaskItems = new ITaskItem[sourceFiles.Count]; for (var index = 0; index < sourceFiles.Count; index++) sourceFileTaskItems[index] = new TaskItem(sourceFiles[index]); var tLogWriteFiles = GetTaskItemsFromPath("CL.write.*", tlogDirectoryPath); var tLogReadFiles = GetTaskItemsFromPath("CL.read.*", tlogDirectoryPath); var trackedOutputFiles = new CanonicalTrackedOutputFiles(tLogWriteFiles); var trackedInputFiles = new CanonicalTrackedInputFiles(tLogReadFiles, sourceFileTaskItems, trackedOutputFiles, false, false); ITaskItem[] sourcesForIncrementalBuild = trackedInputFiles.ComputeSourcesNeedingCompilation(true); Thus, using standard MSBuild tools, we achieved that the mechanism for determining files for incremental analysis is identical to the internal mechanism for MSBuild for incremental assembly, which ensures a very high reliability of this approach.
Conclusion
In this article, we looked at the benefits of using incremental analysis on developers' computers and on the build server. We also looked under the hood and learned how, using the capabilities of MSBuild, to determine which files to perform incremental analysis for. I suggest everyone who is interested in the capabilities of our product, download the trial version of the PVS-Studio analyzer and see what can be found in your projects. All quality code!

If you want to share this article with an English-speaking audience, then please use the link to the translation: Pavel Kuznetsov. Incremental analysis in PVS-Studio: now on the build server
Read the article and have a question?
Often our articles are asked the same questions. We collected answers to them here: Answers to questions from readers of articles about PVS-Studio, version 2015 . Please review the list.
Source: https://habr.com/ru/post/321702/
All Articles