Distributed xargs, or Execution of Heterogeneous Applications on Hadoop Cluster

Hi, Habr! My name is Alexander Krasheninnikov, I lead DataTeam in Badoo. Today I will share with you a simple and elegant utility for distributed execution of commands in the style of xargs, and at the same time I will tell the story of its occurrence.
Our BI department works with data volumes that require the processing of resources from more than one machine. In our ETL processes (Extract Transform Load), distributed Hadoop and Spark systems familiar to the Big Data world are used in conjunction with the Exasol OLAP database. Using these tools allows us to scale horizontally in both disk space and CPU / RAM.
Of course, in our ETL processes there are not only heavy tasks on the cluster, but also simpler machines. A wide range of tasks is solved by single PHP / Python scripts without recourse to gigabytes of RAM and a dozen hard drives. But one fine day we needed to adapt one CPU-bound task for execution in 250 parallel instances. It is time for the little Python script to leave the limits of the native host and rush into a large cluster!
Maneuver options
So, we have the following input conditions of the problem:
- Long-running (about one hour) CPU-bound Python task.
- It is required to perform the task 250 times with various input parameters.
- The result of the execution is obtained synchronously, that is, start something, wait, exit the exit code according to the results.
- Minimum execution time - we believe that we have enough computational resources for parallelization.
Implementation options
One physical host
The fact that running applications are single-threaded and do not use more than 100% of a single CPU core allows us to simply fork-out / exec-actions in the implementation of each task.
Using xargs:
commands.list: /usr/bin/uptime /bin/pwd krash@krash:~$ cat commands.list | xargs -n 1 -P `nproc` bash -c /home/krash 18:40:10 up 14 days, 9:20, 7 users, load average: 0,45, 0,53, 0,59 The approach is simple as a boot and has worked well. But in our case, we reject it, because when we perform our task on a machine with 32 cores, we get the result in ~ eight hours, and this does not correspond to the formulation “minimum execution time”.
Multiple physical hosts
The next tool you can use for this solution is GNU Parallel . In addition to the local mode, similar in functionality to xargs, it has the ability to run programs via SSH on several servers. We select several hosts on which we will execute tasks (“cloud”), divide the list of commands between them and use the parallel to execute tasks.
Create a nodelist file with a list of machines and the number of cores that we can dispose of there:
1/ cloudhost1.domain 1/ cloudhost2.domain Run:
commands.list: /usr/bin/uptime /usr/bin/uptime krash@krash:~$ parallel --sshloginfile nodelist echo "Run on host \`hostname\`: "\; {} ::: `cat commands.list` Run on host cloudhost1.domain: 15:54 up 358 days 19:50, 3 users, load average: 25,18, 21,35, 20,48 Run on host cloudhost2.domain: 15:54 up 358 days 15:37, 2 users, load average: 24,11, 21,35, 21,46 However, we also reject this option due to operational features: we do not have information about the current load and availability of cluster hosts, and it is possible to get into a situation where parallelization will only cause harm, since one of the target hosts will be overloaded.
Hadoop-based solutions
We have a proven BI tool that we know and can use, a bunch of Hadoop + Spark. To cram our code into a cluster framework, there are two solutions:
Spark Python API (PySpark)
Since the original task is written in Python, and Spark has the corresponding API for this language, you can try to port the code to the map / reduce paradigm. But we also had to reject this option, since the cost of adaptation was unacceptable within the framework of this task.
Hadoop streaming
The Hadoop Map / reduce framework allows you to perform tasks written not only in JVM-compatible programming languages. In our particular case, the task is called map-only — there is no reduce-stage, since the execution results are not subjected to any subsequent aggregation. The task launch looks like this:
hadoop jar $path_to_hadoop_install_dir/lib/hadoop-streaming-2.7.1.jar \ -D mapreduce.job.reduces=0 \ -D mapred.map.tasks=$number_of_jobs_to_run \ -input hdfs:///path_for_list_of_jobs/ \ -output hdfs:///path_for_saving_results \ -mapper "my_python_job.py" \ -file "my_python_job.py" This mechanism works as follows:
- We request resources from the Hadoop cluster ( YARN ) to perform the task.
- YARN allocates a number of physical JVMs (YARN containers) on different cluster hosts.
- The contents of the files (a) located in the hdfs: // path_for_list_of_jobs folder are divided between containers.
- Each of the containers, having received its own list of strings from a file, runs the my_python_job.py script and sends it to STDIN successively, interpreting the contents of STDOUT as a return value.
An example of running a child process:
#!/usr/bin/python import sys import subprocess def main(argv): command = sys.stdin.readline() subprocess.call(command.split()) if __name__ == "__main__": main(sys.argv) And an option with a "controller" that runs the business logic:
#!/usr/bin/python import sys def main(argv): line = sys.stdin.readline() args = line.split() MyJob(args).run() if __name__ == "__main__": main(sys.argv) This approach most fully corresponds to our task, but has several disadvantages:
- We lose the STDOUT flow of the task being performed (it is used as a communication channel), and we would like to be able to see logs after the task is completed.
- If in the future we want to run some more tasks on the cluster, we will have to do a wrapper for them.
As a result of analyzing the above implementation options, we decided to create our own bicycle product.
Hadoop xargs
Requirements for the developed system:
- Perform a task list with optimal use of Hadoop cluster resources.
- The condition for successful completion is “all subtasks worked successfully, otherwise fail.”
- The ability to save subtasks for further analysis.
- Optional restart of the task with an exit code other than zero.
We chose Apache Spark as a platform for implementation - we are well acquainted with it and know how to “prepare” it.
Work algorithm:
- Get a list of tasks from STDIN.
- Make it Spark RDD (distributed array).
- Request containers for execution from the cluster.
- Distribute an array of tasks in containers.
- For each container, start a map function that accepts the text of an external program as input and produces fork-exec.
The code of the entire application is obscenely simple, and the function code itself is of immediate interest:
package com.badoo.bi.hadoop.xargs; import lombok.extern.log4j.Log4j; import org.apache.commons.exec.CommandLine; import org.apache.commons.lang.NullArgumentException; import org.apache.log4j.PropertyConfigurator; import org.apache.spark.api.java.function.VoidFunction; import java.io.IOException; import java.util.Arrays; /** * Executor of one command * Created by krash on 01.02.17. */ @Log4j public class JobExecutor implements VoidFunction<String> { @Override public void call(String command) throws Exception { if (null == command || command.isEmpty()) { throw new NullArgumentException("Command can not be empty"); } log.info("Going to launch '" + command + "'"); Process process = null; try { CommandLine line = CommandLine.parse(command); ProcessBuilder builder = getProcessBuilder(); // quotes removal in bash-style in order to pass correctly to execve() String[] mapped = Arrays.stream(line.toStrings()).map(s -> s.replace("\'", "")).toArray(String[]::new); builder.command(mapped); process = builder.start(); int exitCode = process.waitFor(); log.info("Process " + command + " finished with code " + exitCode); if (0 != exitCode) { throw new InstantiationException("Process " + command + " exited with non-zero exit code (" + exitCode + ")"); } } catch (InterruptedException err) { if (process.isAlive()) { process.destroyForcibly(); } } catch (IOException err) { throw new InstantiationException(err.getMessage()); } } ProcessBuilder getProcessBuilder() { return new ProcessBuilder().inheritIO(); } } Assembly
The assembly of the application is made by the standard for Java-world tool - Maven. The only difference is in the environment in which the application will run. If you do not use Spark for your cluster, then the assembly looks like this:
mvn clean install In this case, the resulting JAR file will contain Spark's source code. If the client code Spark is installed on the machine with which the application is launched, it should be excluded from the assembly:
mvn clean install -Dwork.scope=provided As a result of such a build, the application file will be significantly smaller (15 Kb against 80 Mb).
Launch
Suppose we have a commands.list file with a list of tasks of the following form:
/bin/sleep 10 /bin/sleep 20 /bin/sleep 30 Run the application:
akrasheninnikov@cloududs1.mlan:~> cat log.log | /local/spark/bin/spark-submit --conf "spark.master=yarn-client" hadoop-xargs-1.0.jar 17/02/10 15:04:26 INFO Application: Starting application 17/02/10 15:04:26 INFO Application: Got 3 jobs: 17/02/10 15:04:26 INFO Application: /bin/sleep 10 17/02/10 15:04:26 INFO Application: /bin/sleep 20 17/02/10 15:04:26 INFO Application: /bin/sleep 30 17/02/10 15:04:26 INFO Application: Application name: com.badoo.bi.hadoop.xargs.Main 17/02/10 15:04:26 INFO Application: Execution environment: yarn-client 17/02/10 15:04:26 INFO Application: Explicit executor count was not specified, making same as job count 17/02/10 15:04:26 INFO Application: Initializing Spark 17/02/10 15:04:40 INFO Application: Initialization completed, starting jobs 17/02/10 15:04:52 INFO Application: Command '/bin/sleep 10' finished on host bihadoop40.mlan 17/02/10 15:05:02 INFO Application: Command '/bin/sleep 20' finished on host bihadoop31.mlan 17/02/10 15:05:12 INFO Application: Command '/bin/sleep 30' finished on host bihadoop18.mlan 17/02/10 15:05:13 INFO Application: All the jobs completed in 0:00:32.258 After completing the work via the YARN GUI, we can get the logs of the applications that were running (example for the uptime ):
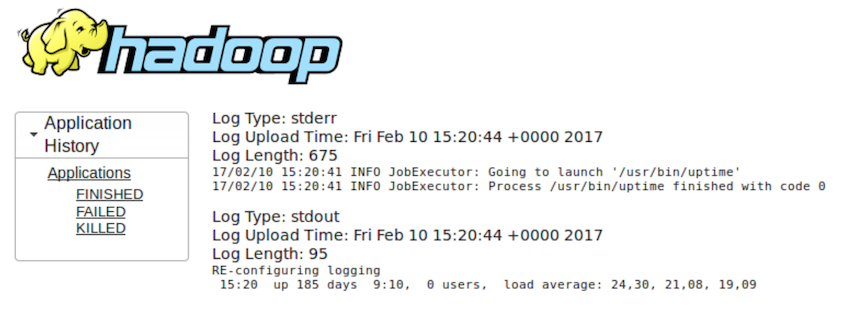
If it is impossible to execute a command, the whole process looks as follows:
akrasheninnikov@cloududs1.mlan:~> echo "/bin/unexistent_command" | /local/spark/bin/spark-submit --conf "spark.master=yarn-client" --conf "spark.yarn.queue=uds.misc" --conf "spark.driver.host=10.10.224.14" hadoop-xargs-1.0.jar 17/02/10 15:12:14 INFO Application: Starting application 17/02/10 15:12:14 INFO Main: Expect commands to be passed to STDIN, one per line 17/02/10 15:12:14 INFO Application: Got 1 jobs: 17/02/10 15:12:14 INFO Application: /bin/unexistent_command 17/02/10 15:12:14 INFO Application: Application name: com.badoo.bi.hadoop.xargs.Main 17/02/10 15:12:14 INFO Application: Execution environment: yarn-client 17/02/10 15:12:14 INFO Application: Explicit executor count was not specified, making same as job count 17/02/10 15:12:14 INFO Application: Initializing Spark 17/02/10 15:12:27 INFO Application: Initialization completed, starting jobs 17/02/10 15:12:29 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 1 times 17/02/10 15:12:29 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 2 times 17/02/10 15:12:30 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 3 times 17/02/10 15:12:30 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 4 times 17/02/10 15:12:30 ERROR Main: FATAL ERROR: Failed to execute all the jobs java.lang.InstantiationException: Cannot run program "/bin/unexistent_command": error=2, No such file or directory at com.badoo.bi.hadoop.xargs.JobExecutor.call(JobExecutor.java:56) at com.badoo.bi.hadoop.xargs.JobExecutor.call(JobExecutor.java:16) at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachAsync$1.apply(JavaRDDLike.scala:690) at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachAsync$1.apply(JavaRDDLike.scala:690) at scala.collection.Iterator$class.foreach(Iterator.scala:727) at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28) at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$15.apply(AsyncRDDActions.scala:118) at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$15.apply(AsyncRDDActions.scala:118) at org.apache.spark.SparkContext$$anonfun$37.apply(SparkContext.scala:1984) at org.apache.spark.SparkContext$$anonfun$37.apply(SparkContext.scala:1984) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66) at org.apache.spark.scheduler.Task.run(Task.scala:88) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Conclusion
The developed solution allowed us to comply with all the conditions of the original problem:
- We get from Hadoop kernel to run our application, according to the requirements (number of cores) - the maximum level of parallelization.
- When issuing resources, the load and availability of the hosts are taken into account (due to the API YARN).
- We save the contents of STDOUT / STDERR of all tasks that we run.
- Did not have to rewrite the original application.
- "Write once, run anywhere" © Sun Microsystems - the developed solution can now be used to run any other tasks.
The joy of the result was so great that we could not share it with you. We published the source code for Hadoop xargs on GitHub .
')
Source: https://habr.com/ru/post/321692/
All Articles