Development of transactional microservices using aggregates, Event Sourcing and CQRS (Part 1)

We bring to your attention a translation of the first part of a useful article on how to develop transactional business applications using a microservice architecture.
Microservice architecture is becoming increasingly popular. This is a modular approach in which the application is functionally divided into separate services. As a result, developers of large and complex applications can quickly produce high-quality software. With this approach, it is easier for them to master new technologies, as it becomes possible to implement each individual service using the most appropriate and modern technology stack. Microservice architecture also improves the scalability of applications due to the ability to deploy each individual service on the equipment that is optimal for it.
However, microservices are not so simple and universal solution. In particular, domain models, transactions, and queries are remarkably resistant to separation along a functional basis. As a result, the development of transactional business applications using the microservice architecture is quite a challenge. In this article, we will look at how to develop microservices, in which these problems are solved using a domain-based design pattern (Domain Driven Design), Event Sourcing, and CQRS.
Key points:
')
- Microservice architecture functionally divides the application into separate services, each of which corresponds to a specific business object or business process.
- One of the key problems in the development of microservice-oriented applications is that transactions, domain models (Domain models) and requests "resist" the division into separate services.
- A domain model can be decomposed into aggregates (Aggregates) within the framework of the Domain Driven Design design pattern.
- Each service is a domain model consisting of one or more DDD aggregates.
- As part of the service, each transaction creates or updates a single aggregate.
- Events are used to maintain consistency between the aggregates (and services).
Let's first look at the problems that developers face when creating microservices.
Problems of development of microservices
Modularity is important when developing large and complex applications.
Most modern applications are too large to be created by one developer. In addition, they are too complex to be fully understood by one person. The application should be divided into modules that are developed by a whole team of developers. In a monolithic application, modularity is determined by the constructs of the programming language used, for example, Java packages. Such an approach, as a rule, does not work well in practice. Long-lived monolithic applications usually degenerate into what is known as the Big balls of mud anti-pattern .
Microservice architecture uses service as a unit of modularity. Each service is a separate business process or business object that does something to produce a specific result. For example, an online store using this architecture could consist of such microservices as the Order Service, Customer Service, Catalog Service, etc.
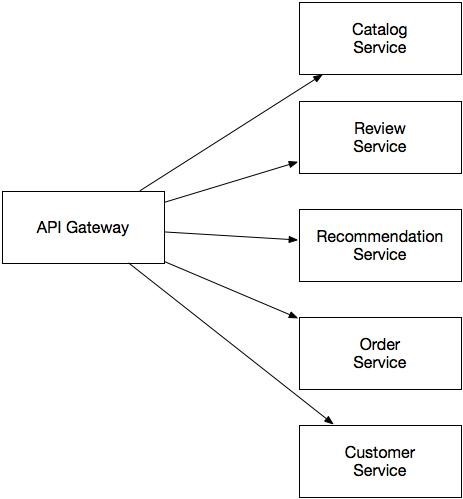
Each service has clear boundaries, due to which it is much easier to maintain the modularity of the application for a long time. Microservice architecture has other advantages, including the ability to deploy and scale services independently.
Unfortunately, dividing the application into services is not as easy as it seems. As mentioned earlier, several different aspects of the applications — domain models, transactions, and queries — are difficult to break down. Let's look at the causes of these difficulties.
Problem number 1: The separation of the domain model
The domain model pattern ( Domain model ) is a good way to implement complex business logic. The domain model for the online store will include classes such as Order , Order Item , Customer , Product . In the microservice architecture, the Order and Order Position classes are part of the Order service, the Client class is part of the Client service, and the Goods class belongs to the Catalog service.
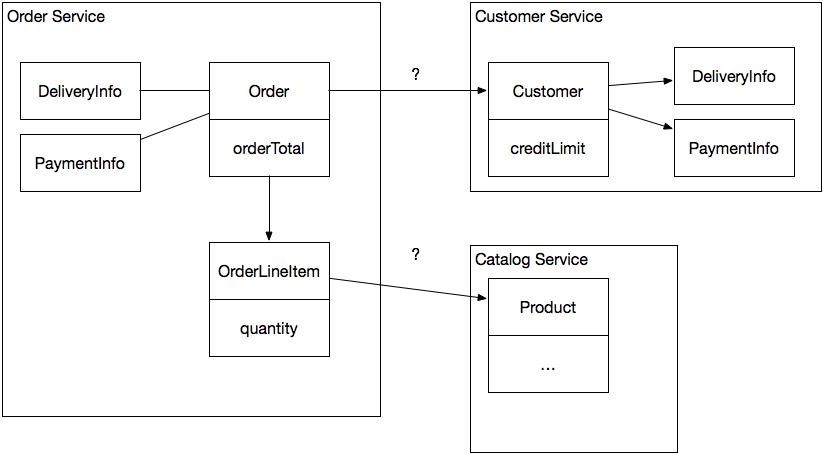
The problem with dividing the domain model into services is that classes often refer to each other. For example, the Order refers to the Client who made it, and the Order Items refer to the Goods . What to do with links that violate the boundaries of services? Later we will see how the concept of aggregate (Aggregate) from DDD ( Domain Driven Design ) solves this problem.
Microservices and databases
A distinctive feature of the microservice architecture is that the data belonging to the service is available only through the API of this service. For example, in the online store, Service Orders has a database that includes the ORDERS table, and Customer Service has its own database, which includes the CUSTOMERS table. Because of this encapsulation, services are loosely coupled, and the developer can change the scheme of his service without having to coordinate with developers working on other services. During application execution, services are isolated from each other. For example, a service will never wait for the end of blocking of a database belonging to another service. On the other hand, the functional separation of the database makes it difficult to maintain the integrity of the data, as well as the implementation of many types of queries.
Problem number 2: Transactions
A traditional monolithic application can rely on transactions to enforce business rules. Imagine, for example, that online store customers have a credit limit, which must be verified before creating a new order. The application must ensure that several simultaneous attempts to place an order do not exceed the client's credit limit. If orders and customers are in the same database, then a trivial solution is to use a transaction (with the appropriate isolation level):
BEGIN TRANSACTION … SELECT ORDER_TOTAL FROM ORDERS WHERE CUSTOMER_ID = ? … SELECT CREDIT_LIMIT FROM CUSTOMERS WHERE CUSTOMER_ID = ? … INSERT INTO ORDERS … … COMMIT TRANSACTION Unfortunately, we cannot use such a simple approach to maintain data consistency with a microservice-oriented approach. The ORDERS and CUSTOMERS tables belong to different services and can only be accessed via the API. They may even be in different databases.
In this case, the traditional solution will be distributed transactions , but for modern applications this is not the appropriate technology. The CAP theorem requires the developer to choose between availability (Availability) and data consistency (Consistency), and availability is usually the preferred choice. In addition, many modern technologies, such as most NoSQL databases, do not even support ordinary transactions, let alone distributed ones. Maintaining integrity is important, so we need another solution. Below we will see that the solution is to use event-oriented (event-driven, message-driven) architecture based on event sourcing.
Problem number 3: Requests to the database
Along with maintaining data integrity, queries to the database are also a problem. In traditional monolithic applications, queries using joins are extremely common. For example, you can easily find newly registered customers and their large orders using the query:
SELECT * FROM CUSTOMER c, ORDER o WHERE c.id = o.ID AND o.ORDER_TOTAL > 100000 AND o.STATE = 'SHIPPED' AND c.CREATION_DATE > ? We cannot use this type of request in a microservice-based online store. As mentioned earlier, the ORDERS and CUSTOMERS tables belong to different services and can only be accessed via the API. Some services may not even use a SQL database. But you can use an approach known as Event Sourcing, which makes finding information even more challenging.
Next, we see that the solution is to preserve materialized views using an approach known as Command Query Responsibility Segregation (CQRS). But first, let's consider the issue of Domain-Driven Design (DDD) when developing microservices.
DDD units as microservice building blocks
As you can see, there are several problems that need to be solved for the sake of successful application development using microservices. A solution to some of these problems can be found in Eric Evans's “ Domain-Driven Design ”, a must-read book. It describes the approach to the design of complex software, which is very useful in the development of microservices. In particular, Domain-Driven Design allows you to create a modular domain model that can be distributed across services.
What are units?
In Domain-Driven Design, Evans defines several building blocks for domain models. Many of them have become part of the everyday language of developers, including Entity, Value object, Service, Repository, etc. However, one building block — the unit — was largely ignored by the developers, with the exception of DDD-purists. But it turns out that aggregates are the key to the development of microservices.
An aggregate is a cluster of domain objects that can be considered as a whole. It consists of the root entity object (Entity) and, possibly, one or more other related entity objects and value objects (Value Object). For example, the domain model for an online store contains such aggregates as Order and Customer . An Order unit consists of the Order root entity, one or more value objects Order position along with other value objects, such as Cost , Delivery Address, and Billing Details . The Client unit consists of a Client entity and several value objects, such as Delivery Information and Payment Information .
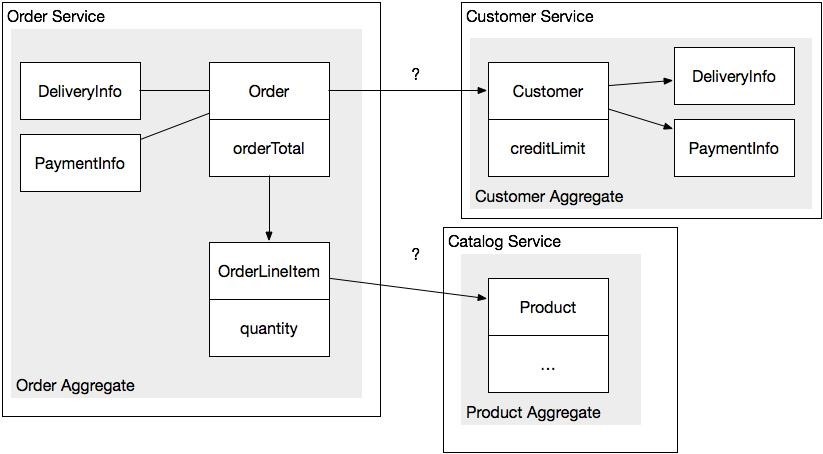
The use of aggregates divides the domain model into pieces that are easier to understand separately. It also defines a set of operations, such as load and delete. An aggregate is usually loaded from the entire database. Removing an aggregate deletes all objects. The advantage of aggregates, however, goes far beyond the limits of the modularity of the domain model, because aggregates must obey certain rules.
Inter-unit communications should use primary keys.
The first rule is that aggregates always refer to each other through a unique identifier (for example, the primary key) instead of direct references to objects. For example, an Order refers to its Customer using the CustomerId, and not a reference to a customer object. Similarly, an Order Item refers to a Product using the ProductID.

This approach is very different from the traditional, in which foreign keys in the domain model are considered bad practice. Using an identifier, rather than an object reference, means that the aggregates are loosely coupled. You can easily place different units in different services. In fact, the business logic of a service consists of a domain model, which is a set of aggregates. For example, OrderService contains the Order aggregate, and CustomerService contains the Customer aggregate.
One transaction creates or updates one aggregate.
The second rule is that a transaction can create or update only one aggregate. When I first read about this rule many years ago, it made no sense! At that time, I was developing traditional monolithic applications based on RDBMS, and therefore transactions could update arbitrary data. Today, this restriction is ideal for microservice architecture. This ensures that the transaction is contained within the service. This restriction also corresponds to the transaction restrictions of most NoSQL databases.
When developing a domain model, the key is to decide how large each specific unit needs to be made. Ideally, the units should be small. This improves modularity by sharing responsibility. This is more efficient since the units are usually loaded completely. In addition, since the update of each unit occurs sequentially, the use of smaller units will increase the number of simultaneous requests that the application can handle, and thereby improve scalability. It also reduces the likelihood that two users will try to upgrade the same unit at the same time.
On the other hand, since an aggregate is the business of a transaction, you may need to define an aggregate larger to make a specific update atomic.
For example, the above states that in the domain model of the online store, Order and Customer are separate aggregates. An alternative is to make the Order part of the Customer unit. The advantage of a large aggregate Client is that the application will be able to atomically check the credit limit. The disadvantage of the approach is that it combines the functionality of the Order and the Client in the same service. This reduces scalability, since transactions that update different orders of the same customer cannot be executed in parallel. In addition, two users may come into conflict if they try to edit different orders of the same customer. With an increase in the number of orders, loading the machine will become more and more expensive. Because of these problems, it is better to make the units as small as possible.
Even complying with the requirement to create or update a transaction with only one aggregate, applications still need to maintain consistency between aggregations. For example, the Order service must verify that the new order does not exceed the aggregate credit limit of the customer. There are several different ways to maintain consistency. One option is to trick the application and create / update multiple aggregates in a single transaction. This is possible only when all units belong to the same service and are stored in the same RDBMS. Another more correct option is to maintain consistency between the aggregates using an event-based approach.
Using events to maintain data consistency
In the modern application there are various restrictions on transactions that make it difficult to maintain the consistency of data in services. Each service has its own data, but using distributed transactions is not a viable option. In addition, many applications use NoSQL databases, which do not even support ordinary local transactions, not to mention distributed ones. Therefore, a modern application must use an event-driven transaction model known as Eventually Consistent.
What is an event?
As the Merriam-Webster dictionary (and Captain Obvious) says, an “event” is what happens (happens):

In this article, we define a Domain Event (Domain Event) as what happened to the aggregate. An event is usually a state change. Consider, for example, an Order unit. Events that change its state include Order created , Order canceled , Order sent . Events may constitute attempts to violate business rules, for example, the Client’s credit limit.
Using Event-Driven Architecture
Services use events to ensure consistency between the aggregates as follows: the aggregate publishes an event whenever something noticeable happens. For example, its state is changing, or there is an attempt to violate a business rule. Other aggregates subscribe to an event and respond to it by updating their own state.
The online store checks the client's credit limit when creating an order using the following sequence of steps:
- The Order aggregate, which is created with the NEW status, publishes an OrderCreated event.
- Aggregate The client receives notification of the OrderCreated event, reserves a loan for the order and publishes a CreditReserved event.
- The Order unit receives a CreditReserved event notification and changes its status to APPROVED.
If the credit check fails due to a lack of funds, the client unit posts a CreditLimitExceeded event. This event does not reflect a state change, but is an unsuccessful attempt to violate business rules. The Order unit receives notification of this event and changes its status to CANCELED.
Microservice architecture as a network of event-driven aggregates
In this architecture, the business logic of each service consists of one or more units. Each transaction performed by the service updates or creates a single aggregate. Services maintain consistency of data between aggregates through events.

A distinctive feature of the approach is that the units are loosely connected building blocks. They can be deployed as a monolithic application, and as a set of individual services. At the beginning of the project you could use a monolithic architecture. And later, with the growing size of the application and the development team, you can easily switch to the microservice architecture.
Summary
Microservice architecture functionally divides an application into services, each of which corresponds to a specific business object or business process. One of the main problems in developing microservice business applications is that transactions, domain models and queries oppose the division into services. You can separate the domain model by applying the “aggregate” concept from Domain Driven Design. The business logic of each service is a domain model consisting of one or more DDD aggregates.
Within each service, a transaction creates or updates a single aggregate. Since distributed transactions are not a viable technology for modern applications, events are used to maintain consistency between the aggregates (and services).
In the second part of the article, we will look at how to implement a robust, event-driven architecture using Event Sourcing, as well as how to implement requests in the microservice architecture using CQRS.
Source: https://habr.com/ru/post/321686/
All Articles