Comparison of solutions for balancing high-load systems
Once again, we publish transcripts of speeches from the HighLoad ++ conference, which was held in Skolkovo near Moscow on November 7—8, 2016. Today, Evgeny Piven introduces us to balancing solutions in the clouds.

My name is Zhenya, I work for IPONWEB. Today we will talk about the development of our solutions in balancing high-load systems.
')
First, I will go over the concepts with which I will operate. Let's start with what we do: RTB, Real Time Bidding - the display of advertising with the auction in real time. A very simplified diagram of what happens when you visit the site:

In order to show advertisements, a request is sent to the RTB server, which requests their bids from the ad servers and then decides which ad to show you.
We have all the infrastructure in the clouds. We are very active in using Amazon and GCE, we have several thousand servers. The main reason why we live completely in the clouds is scalability, that is, we really often need to add / remove instances, sometimes a lot.
We have millions of requests per second, all these HTTP requests. This may not be fully applicable to other protocols. We have very short answers. Maybe not, I think, on average, from one to several kilobytes of responses. We do not operate with any large volumes of information, just a very large number of them.
For us, caching is not relevant. We do not support CDN. If our clients need CDN, then they themselves are engaged in these solutions. We have very strong daily and event fluctuations. They manifest themselves during holidays, sporting events, some seasonal discounts, etc. Daily allowances can be seen well on this schedule:
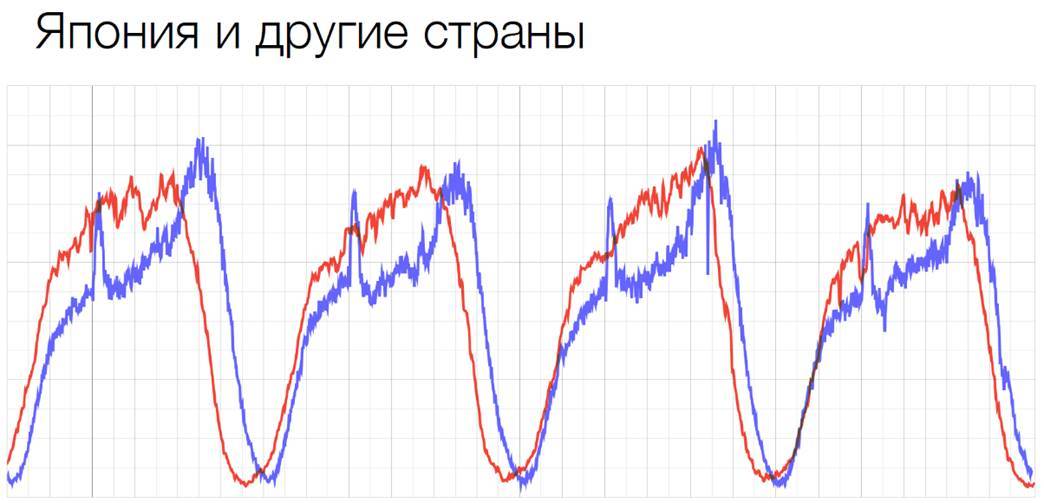
The red graph is the usual standard graph in a European country, and the blue graph is Japan. On this graph, we see that every day at about twelve we have a sharp jump, and at about an hour the traffic drops sharply. This is due to the fact that people go to lunch, and as very decent Japanese citizens, they use the Internet actively most at lunch. This is very well seen on this graph.
We have a wide range of users around the world. This is the second big reason why we use clouds. It is very important for us to respond quickly, and if the servers are located in some other regions from users, then this is often unacceptable for RTB realities.
And we have a clear distinction between server and user traffic. Let us return to the scheme that I showed on the first slide. For simplicity, all that comes from the user to the primary RTB server is user traffic, all that happens behind it is server traffic.

The two main reasons are the scalability and availability of services .
Scalability is when we add new servers, when we are from one server that can no longer cope, we grow to at least two, and between them we must somehow scatter requests. Availability is when we are afraid that something will happen to this one server. Again, you need to add a second one in order to somehow balance all of this and distribute requests only to those servers that can answer them.
What else is often required from balancers? These functions, of course, for the purposes of each application may be different. For us, SSL Offload is most relevant. How it works is shown here.
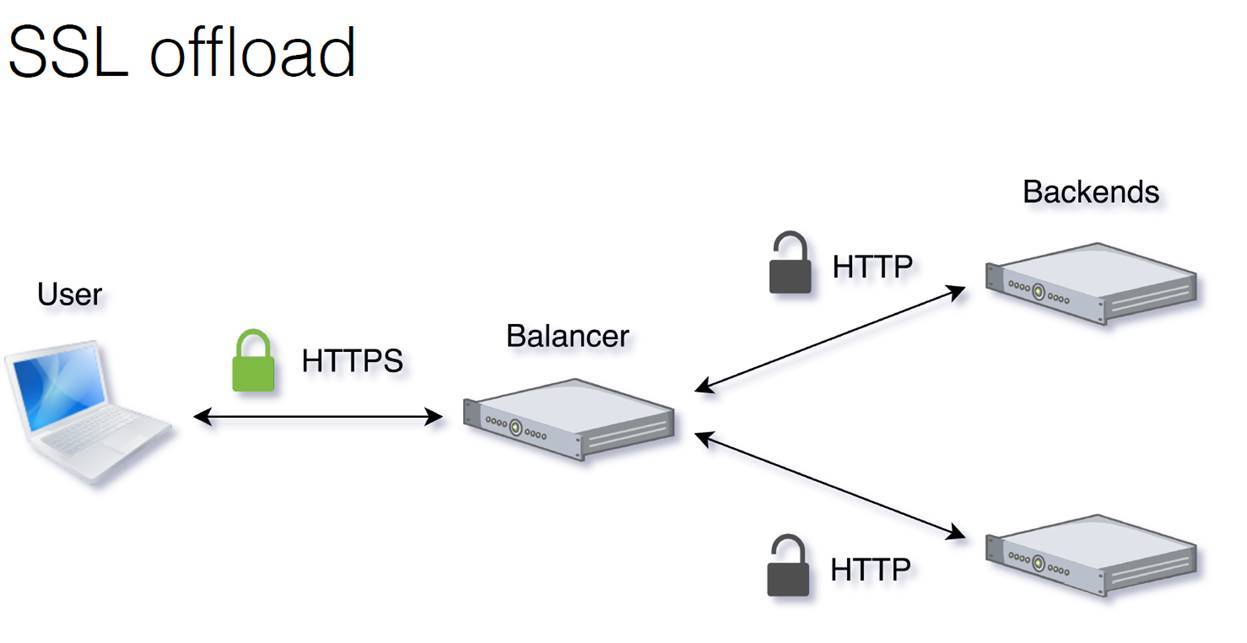
From the user to the balancer, there is traffic that is encrypted. The balancer decrypts it, scatters already decrypted HTTP traffic on the backends. Then the balancer back encrypts it and sends it back to the user in encrypted form.
Such a thing as Sticky balancing, which is often called session affinity, is also very important to us.

Why is this important for us? When we see several advertising slots on a page, we want all requests to come immediately to one backend when opening this page. Why is it important? There is a feature like roadblock. It means that if we showed a banner in one of the slots, for example, Pepsi, then in the other we cannot show the banner of the same Pepsi or Coca-Cola, because these are conflicting banners.
We need to understand which banners we are currently showing to the user. When balancing, we need to make sure that the user has come to one backend. On this backend we create a kind of session, and we understand exactly what advertisements can be shown to this user.
We also have Fallback. On the example above, a banner is visible, on which it does not work, and on the right - a banner on which it works.
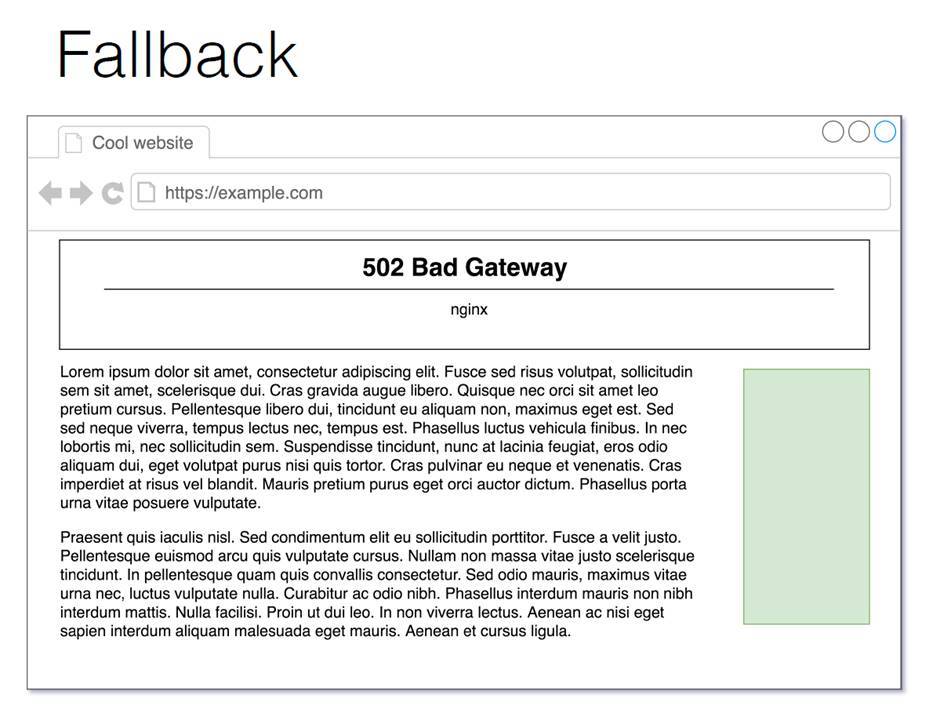
Fallback is a situation where, for some reason, the backend does not cope, and in order not to break a page for a user, we usually give him a completely empty pixel. Here I drew it with a large green rectangle for understanding, but in fact it’s usually just a little gif, two hundredth HTTP Response and the right set of headers so that we don’t have anything in the layout to break.
So we have a normal balancing.

The blue bold line is the sum of all requests. These small lines, many, many, are requests for each instance. As we can see, the balancing is quite good here: almost all of them go almost equally, merging into one line.
This is the smoker's balancing. Here something went wrong.
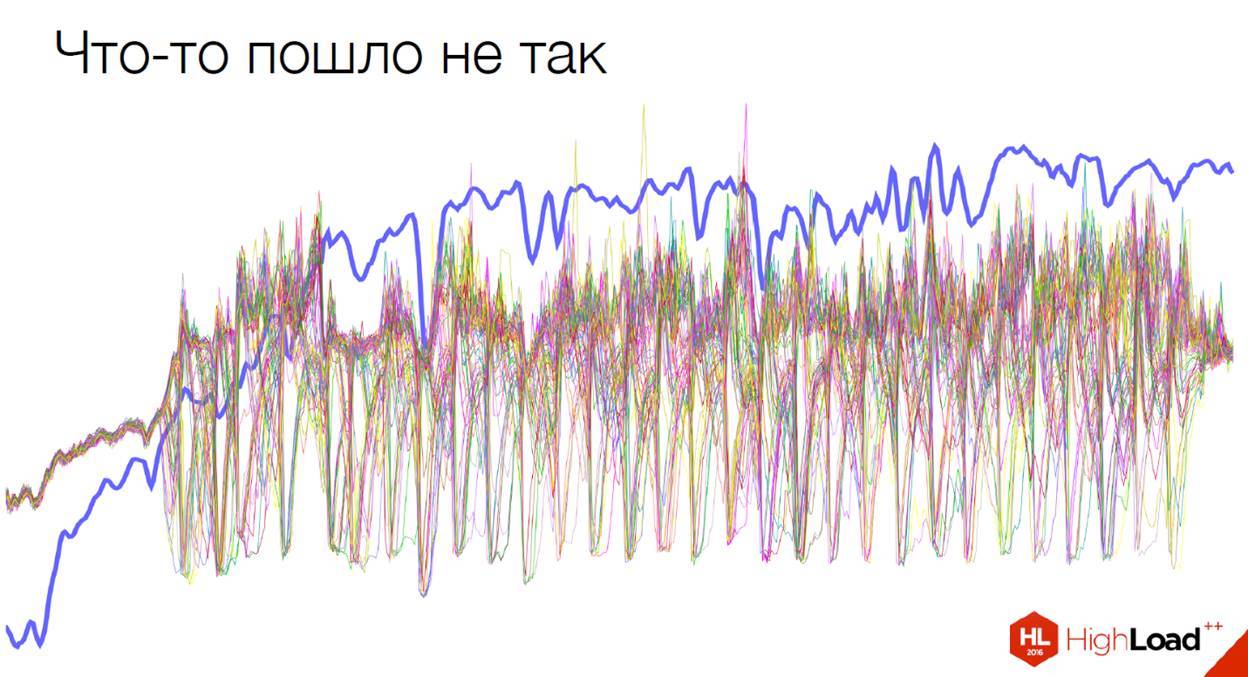
The problem is on the Amazon side. Similar, by the way, happened quite recently, literally two weeks ago. From Amazon balancers traffic began to come in this form.
It is worth saying that metrics are good. Here, Amazon still does not believe us that something bad is happening. They only see this general graph, in which only the sum of requests is visible, but it is not clear how many requests are received by instances. We are still struggling with them, we are trying to prove to them that something is wrong with their balancer.
So, I will tell about balancing on the example of one of our projects. Let's start from the very beginning. The project was young, we are about the beginning of this project.

Most of the traffic in this project is server-side. Feature of working with server traffic: we can easily solve some problems. If we have specificity with one of our clients, then we can somehow agree with him so that they change something at their end, somehow update their systems, do something else so that we can work better with them. You can select them in a separate pool: we can simply take one client who has a problem, tie him to another pool and solve the problem locally. Or, in very difficult cases, you can even ban it.
The first thing we began to use was the usual DNS balancing.

We use Round-robin DNS pools.

Each time a DNS request is made, the pool is rotated and a new IP address is placed on top. Thus balancing works.
Common Round-Robin DNS issues:
Gdnsd comes to the rescue - this is a DNS server that many probably know, which we actively use now.
To keep these records dynamic, we need to maintain a fairly low TTL. This greatly increases the traffic to our DNS servers: quite often clients have to re-request these pools, and therefore DNS servers, respectively, have to have more.
After some period of time, we are faced with the problem of 512 bytes.
Problem 512 bytes is a problem of almost all DNS servers. Initially, when DNS was only designed, the maximum MTU of the modems was 576 bytes. This is 512 bytes + 64 header lengths. DNS packets historically do not send more than 576 bytes over UDP. If we have a pool longer than 512 bytes, then we send only part of the pool, we include the truncated flag in it. Then the client receives a request via TCP, asking us again this pool. And then we send him a full pool, now via TCP.
Only some of our clients had this problem, about 15%. We were able to allocate them separately to the pool and use weighted-pools for them in gdnsd.
Bonus weighted-pools in this case - they can be broken. If we have, say, 100 servers, we divide them into 5 parts. For each request, we give one of these small sub-pools, with a total of 20 servers. And Round-robin passes through these small pools, each time it issues a new pool. Inside the pool itself, Round-Robin is also used: it shuffles these IPs and gives out new ones every time.
Weights gdnsd can be used besides this for, for example, staging servers. If you have a weaker instance, you can initially send much less traffic to it and check that something has broken there, only on it, by sending a fairly small set of traffic to it. Or if you have different types of instances, or you use different servers. (I often say “instances” because we have everything in the clouds, but for your particular case it may not be so.) That is, you can use different types of servers and send more or less traffic to them using gdnsd.
Here we also have a problem - DNS caching. Often, when there is a request for this pool, we give only a small pool, and this pool is cached. With this pool, we continue to live some kind of client, without asking again our DNS. This happens when the DNS client behaves badly, does not adhere to TTL, and works only with a small limited set of IP addresses, without updating it. If he initially received a complete TCP sheet, this is normal. But if he got only a small pool that weighted, then this could be a problem.
After some time, we are faced with a new problem.
Those remaining 85% of server traffic still use regular multifopules, as it is called in gdnsd. Problems begin with some of them.
We realized that the problem occurs only in the Amazon DNS. That is, those of our clients who are hosted by Amazon themselves, when resolving a pool in which there are more than 253 hosts, simply receive an NXDOMAIN error, and they do not completely resolve this whole pool.
This happened when we added about 20 hosts, and we had 270 of them. We localized the number to 253, we realized that this number becomes problematic. Now this problem has already been fixed. But at that moment we realized that we were marking time, and we need to somehow solve this problem further.
Since we are in the clouds, the first thing we thought about was to try vertical scaling. It worked, respectively, we reduced the number of instances. But again, this is a temporary solution.
We decided to try something else, then the choice fell on ELB .
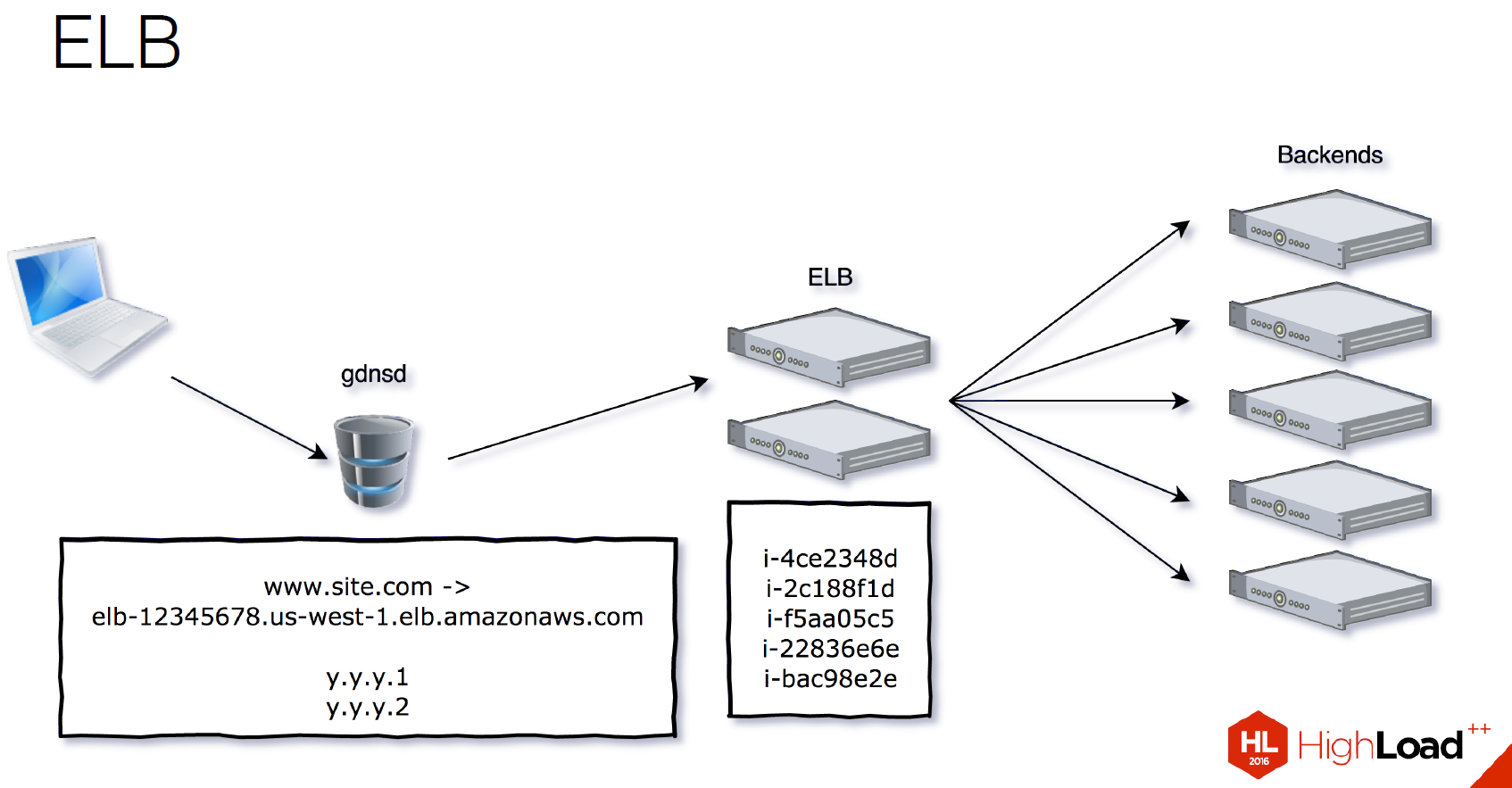
ELB is Elastic Load Balancing, a solution from Amazon that balances traffic. How it works?
They give you CNAME, in this case it’s this scary line under
ELB can SSL Offload, you can attach a certificate to it. He also knows HTTP status checks to understand how live instances we have.
We almost immediately began to encounter problems with ELB. There is a so-called warming up of ELB balancers. This is necessary when you want to allow more than 20-30 thousand requests per second. Before you transfer all your traffic to ELB, you need to write a letter to Amazon, say that we want to send a lot of traffic. You are sent a letter with a bunch of scary questions about the characteristics of your traffic, how much, when, how long you are going to keep it all up. Then they add new instances to their pool and are ready for the influx of traffic.
And even with the preliminary heating, we are faced with a problem. When we asked them for 40 thousand requests per second, about 30 thousand of them broke. We had to quickly roll back the whole thing.
They also have speed balancing responses. This is the algorithm of the Amazon balancer. He looks at how quickly your backends respond. If he sees that quickly, he sends more traffic there.
The problem here is what? If your backend is desperately pyatisotit [gives the HTTP 5XX status code, which indicates a server error] and fails, the balancer thinks that the backend responds very quickly and starts sending more traffic to it, bending your backend even more. In our realities, this is even more problematic, because, as I have already said, we usually send out the 200th answer, even if everything is bad. The user should not see the error - just send an empty pixel. That is, for us this problem is even more difficult to solve.
At the last Amazon conference, they said that if something bad happens to you, then in exception, wrap up any timeouts of 100-200 ms, artificially slowing down the 500th responses, so that the Amazon balancer understands that your backend cannot cope . But in general, in an amicable way, it is necessary to do the correct status checks. Then your backend would understand that there are problems, and would give the status checks to the problem, and it would simply be thrown out of the pool.
Now Amazon has a new solution: Application Load Balancer (ALB) . This is a rather interesting decision, but it is not very relevant to us, because it does not solve anything for us and most likely will cost much more. Their host system has become more complicated.
But ALB supports Path-based routing: this means that if you, for example, have a user come to
There is support for WebSocket, HTTP / 2 and containers. If you have a Docker inside one instance, then it can distribute between them.
At Google, we use GLB . This is quite an interesting decision. Compared to Amazon, it has many advantages.
First, we only have 1 IP. When you create a balancer in Google, you are given the only IP address that you can link to your site. This means that you can even bind it to a “bare” domain. CNAME can also be tied to a second-level domain.
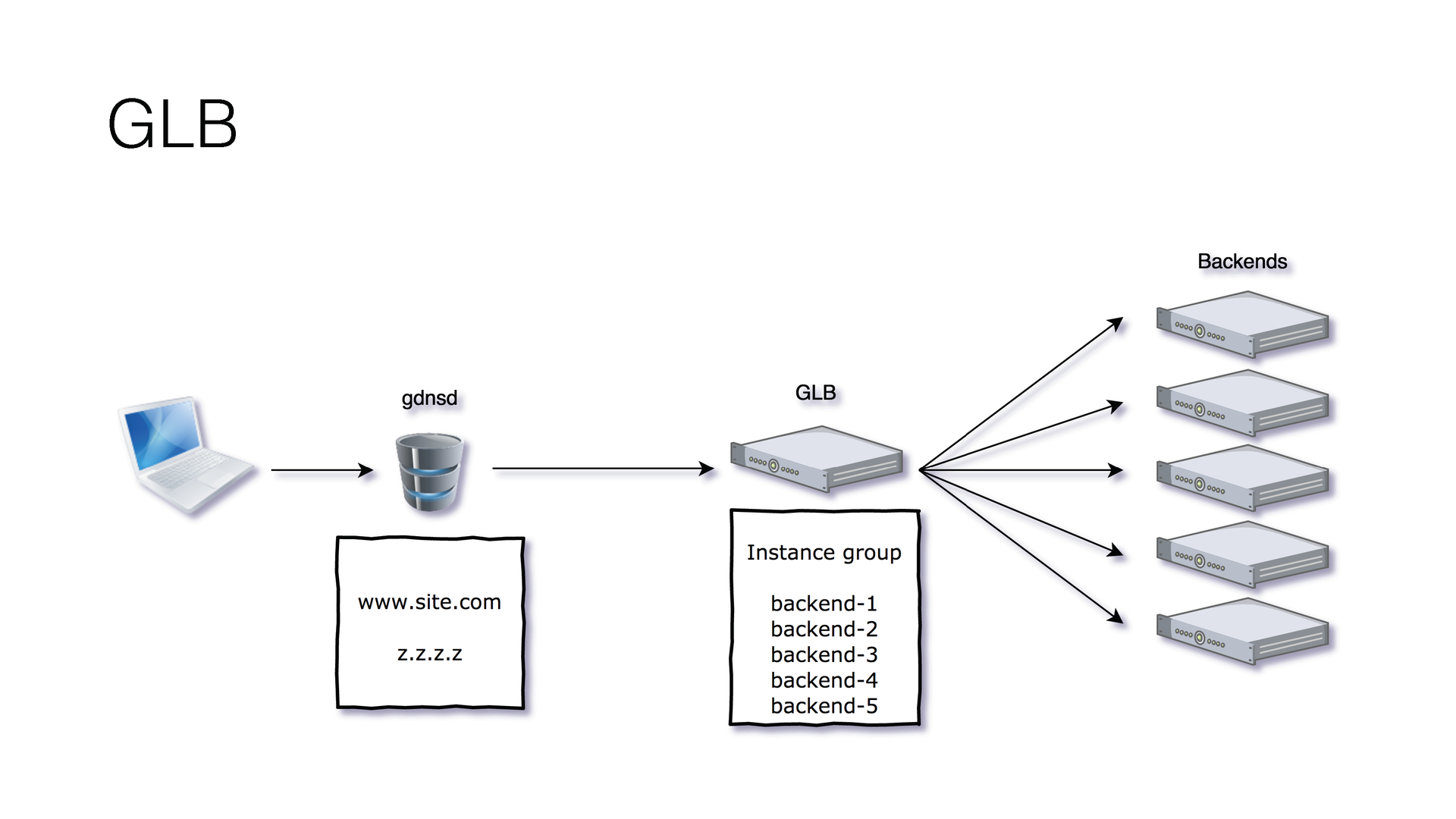
You need to create only one balancer in all regions. That is, in Amazon, we need to create a balancer in each region in order to balance between instances within that region, and in Google only one balancer, just one IP, and it balances between all your instances across different regions.
The Google Balancer is able to stick by both IP and cookie. I told you why Sticky is needed - we need to send one user to one backend. Amazon balancers can only cookie, that is, they themselves at the level of the balancer issue a cookie. Then it is checked, and if it is clear that the user has a cookie corresponding to one of the instances, it is sent to the same one. Google can IP, which is much better for us, although it does not always solve all problems.
The Google balancer has Instant warm-up: you don’t need to warm it up, you can immediately send up to a million requests to it. A million requests - this is what they promise themselves for sure, and what I myself checked. I think, then they grow somehow themselves inside.
But at the same time they have a problem with a sharp change in the number of backends. At some point, we added about 100 new hosts. At this stage, Google balancer bent. When we started talking with an engineer from Google, they said: add one per minute, then you will be happy.
Also recently, in their HTTP balancer, ports that you can use when creating a balancer have been clipped. Previously, there was a usual input field, now you can only choose between 80 and 8080 ports. For some, this can be a problem.
None of these cloud balancers have SNI support. If you need to support multiple domains and multiple certificates, then you need to create a separate balancer for each certificate and bind to it. This is a solvable problem, but this situation can be inconvenient.
My name is Zhenya, I work for IPONWEB. Today we will talk about the development of our solutions in balancing high-load systems.
')
First, I will go over the concepts with which I will operate. Let's start with what we do: RTB, Real Time Bidding - the display of advertising with the auction in real time. A very simplified diagram of what happens when you visit the site:
In order to show advertisements, a request is sent to the RTB server, which requests their bids from the ad servers and then decides which ad to show you.
IPONWEB Features
We have all the infrastructure in the clouds. We are very active in using Amazon and GCE, we have several thousand servers. The main reason why we live completely in the clouds is scalability, that is, we really often need to add / remove instances, sometimes a lot.
We have millions of requests per second, all these HTTP requests. This may not be fully applicable to other protocols. We have very short answers. Maybe not, I think, on average, from one to several kilobytes of responses. We do not operate with any large volumes of information, just a very large number of them.
For us, caching is not relevant. We do not support CDN. If our clients need CDN, then they themselves are engaged in these solutions. We have very strong daily and event fluctuations. They manifest themselves during holidays, sporting events, some seasonal discounts, etc. Daily allowances can be seen well on this schedule:
The red graph is the usual standard graph in a European country, and the blue graph is Japan. On this graph, we see that every day at about twelve we have a sharp jump, and at about an hour the traffic drops sharply. This is due to the fact that people go to lunch, and as very decent Japanese citizens, they use the Internet actively most at lunch. This is very well seen on this graph.
We have a wide range of users around the world. This is the second big reason why we use clouds. It is very important for us to respond quickly, and if the servers are located in some other regions from users, then this is often unacceptable for RTB realities.
And we have a clear distinction between server and user traffic. Let us return to the scheme that I showed on the first slide. For simplicity, all that comes from the user to the primary RTB server is user traffic, all that happens behind it is server traffic.
Why balance?
The two main reasons are the scalability and availability of services .
Scalability is when we add new servers, when we are from one server that can no longer cope, we grow to at least two, and between them we must somehow scatter requests. Availability is when we are afraid that something will happen to this one server. Again, you need to add a second one in order to somehow balance all of this and distribute requests only to those servers that can answer them.
What else is often required from balancers? These functions, of course, for the purposes of each application may be different. For us, SSL Offload is most relevant. How it works is shown here.
From the user to the balancer, there is traffic that is encrypted. The balancer decrypts it, scatters already decrypted HTTP traffic on the backends. Then the balancer back encrypts it and sends it back to the user in encrypted form.
Such a thing as Sticky balancing, which is often called session affinity, is also very important to us.
Why is this important for us? When we see several advertising slots on a page, we want all requests to come immediately to one backend when opening this page. Why is it important? There is a feature like roadblock. It means that if we showed a banner in one of the slots, for example, Pepsi, then in the other we cannot show the banner of the same Pepsi or Coca-Cola, because these are conflicting banners.
We need to understand which banners we are currently showing to the user. When balancing, we need to make sure that the user has come to one backend. On this backend we create a kind of session, and we understand exactly what advertisements can be shown to this user.
We also have Fallback. On the example above, a banner is visible, on which it does not work, and on the right - a banner on which it works.
Fallback is a situation where, for some reason, the backend does not cope, and in order not to break a page for a user, we usually give him a completely empty pixel. Here I drew it with a large green rectangle for understanding, but in fact it’s usually just a little gif, two hundredth HTTP Response and the right set of headers so that we don’t have anything in the layout to break.
So we have a normal balancing.
The blue bold line is the sum of all requests. These small lines, many, many, are requests for each instance. As we can see, the balancing is quite good here: almost all of them go almost equally, merging into one line.
This is the smoker's balancing. Here something went wrong.
The problem is on the Amazon side. Similar, by the way, happened quite recently, literally two weeks ago. From Amazon balancers traffic began to come in this form.
It is worth saying that metrics are good. Here, Amazon still does not believe us that something bad is happening. They only see this general graph, in which only the sum of requests is visible, but it is not clear how many requests are received by instances. We are still struggling with them, we are trying to prove to them that something is wrong with their balancer.
DNS balancing
So, I will tell about balancing on the example of one of our projects. Let's start from the very beginning. The project was young, we are about the beginning of this project.
Most of the traffic in this project is server-side. Feature of working with server traffic: we can easily solve some problems. If we have specificity with one of our clients, then we can somehow agree with him so that they change something at their end, somehow update their systems, do something else so that we can work better with them. You can select them in a separate pool: we can simply take one client who has a problem, tie him to another pool and solve the problem locally. Or, in very difficult cases, you can even ban it.
The first thing we began to use was the usual DNS balancing.
We use Round-robin DNS pools.
Each time a DNS request is made, the pool is rotated and a new IP address is placed on top. Thus balancing works.
Common Round-Robin DNS issues:
- He has no status checks. We cannot understand that something was wrong with the backend, and stop sending requests to it.
- We have no understanding of customer geolocation.
- When requests come from a fairly small number of IPs, which is important for server traffic, balancing may not be very ideal.
Balancing gdnsd
Gdnsd comes to the rescue - this is a DNS server that many probably know, which we actively use now.
- The main feature of gdnsd, which we use, is DYNA-records . These are such records that are issued for each request, using a certain plugin, dynamically either one A-record or a set of A-records. They can use Round-robin inside.
- gdnsd can support geoIP databases.
- He has a status check . It can send some requests via TCP to the host, via HTTP, watch Response and throw out from the pool those servers that are not used, which currently have some kind of problem.
To keep these records dynamic, we need to maintain a fairly low TTL. This greatly increases the traffic to our DNS servers: quite often clients have to re-request these pools, and therefore DNS servers, respectively, have to have more.
After some period of time, we are faced with the problem of 512 bytes.
Problem 512 bytes is a problem of almost all DNS servers. Initially, when DNS was only designed, the maximum MTU of the modems was 576 bytes. This is 512 bytes + 64 header lengths. DNS packets historically do not send more than 576 bytes over UDP. If we have a pool longer than 512 bytes, then we send only part of the pool, we include the truncated flag in it. Then the client receives a request via TCP, asking us again this pool. And then we send him a full pool, now via TCP.
Only some of our clients had this problem, about 15%. We were able to allocate them separately to the pool and use weighted-pools for them in gdnsd.
Bonus weighted-pools in this case - they can be broken. If we have, say, 100 servers, we divide them into 5 parts. For each request, we give one of these small sub-pools, with a total of 20 servers. And Round-robin passes through these small pools, each time it issues a new pool. Inside the pool itself, Round-Robin is also used: it shuffles these IPs and gives out new ones every time.
Weights gdnsd can be used besides this for, for example, staging servers. If you have a weaker instance, you can initially send much less traffic to it and check that something has broken there, only on it, by sending a fairly small set of traffic to it. Or if you have different types of instances, or you use different servers. (I often say “instances” because we have everything in the clouds, but for your particular case it may not be so.) That is, you can use different types of servers and send more or less traffic to them using gdnsd.
Here we also have a problem - DNS caching. Often, when there is a request for this pool, we give only a small pool, and this pool is cached. With this pool, we continue to live some kind of client, without asking again our DNS. This happens when the DNS client behaves badly, does not adhere to TTL, and works only with a small limited set of IP addresses, without updating it. If he initially received a complete TCP sheet, this is normal. But if he got only a small pool that weighted, then this could be a problem.
After some time, we are faced with a new problem.
Those remaining 85% of server traffic still use regular multifopules, as it is called in gdnsd. Problems begin with some of them.
We realized that the problem occurs only in the Amazon DNS. That is, those of our clients who are hosted by Amazon themselves, when resolving a pool in which there are more than 253 hosts, simply receive an NXDOMAIN error, and they do not completely resolve this whole pool.
This happened when we added about 20 hosts, and we had 270 of them. We localized the number to 253, we realized that this number becomes problematic. Now this problem has already been fixed. But at that moment we realized that we were marking time, and we need to somehow solve this problem further.
Since we are in the clouds, the first thing we thought about was to try vertical scaling. It worked, respectively, we reduced the number of instances. But again, this is a temporary solution.
ELB
We decided to try something else, then the choice fell on ELB .
ELB is Elastic Load Balancing, a solution from Amazon that balances traffic. How it works?
They give you CNAME, in this case it’s this scary line under
www.site.com : elb, numbers, region, and so on. And this CNAME resolves to several internal IPs of instances that balance on our backends. In this case, we only need to bind their CNAME once in our DNS to our pool. Then we add servers to the group, on which balancers are thrown.ELB can SSL Offload, you can attach a certificate to it. He also knows HTTP status checks to understand how live instances we have.
We almost immediately began to encounter problems with ELB. There is a so-called warming up of ELB balancers. This is necessary when you want to allow more than 20-30 thousand requests per second. Before you transfer all your traffic to ELB, you need to write a letter to Amazon, say that we want to send a lot of traffic. You are sent a letter with a bunch of scary questions about the characteristics of your traffic, how much, when, how long you are going to keep it all up. Then they add new instances to their pool and are ready for the influx of traffic.
And even with the preliminary heating, we are faced with a problem. When we asked them for 40 thousand requests per second, about 30 thousand of them broke. We had to quickly roll back the whole thing.
They also have speed balancing responses. This is the algorithm of the Amazon balancer. He looks at how quickly your backends respond. If he sees that quickly, he sends more traffic there.
The problem here is what? If your backend is desperately pyatisotit [gives the HTTP 5XX status code, which indicates a server error] and fails, the balancer thinks that the backend responds very quickly and starts sending more traffic to it, bending your backend even more. In our realities, this is even more problematic, because, as I have already said, we usually send out the 200th answer, even if everything is bad. The user should not see the error - just send an empty pixel. That is, for us this problem is even more difficult to solve.
At the last Amazon conference, they said that if something bad happens to you, then in exception, wrap up any timeouts of 100-200 ms, artificially slowing down the 500th responses, so that the Amazon balancer understands that your backend cannot cope . But in general, in an amicable way, it is necessary to do the correct status checks. Then your backend would understand that there are problems, and would give the status checks to the problem, and it would simply be thrown out of the pool.
Now Amazon has a new solution: Application Load Balancer (ALB) . This is a rather interesting decision, but it is not very relevant to us, because it does not solve anything for us and most likely will cost much more. Their host system has become more complicated.
But ALB supports Path-based routing: this means that if you, for example, have a user come to
/video , then you can redirect the request to one set of instances, if to /static , then to another, and so on.There is support for WebSocket, HTTP / 2 and containers. If you have a Docker inside one instance, then it can distribute between them.
GLB
At Google, we use GLB . This is quite an interesting decision. Compared to Amazon, it has many advantages.
First, we only have 1 IP. When you create a balancer in Google, you are given the only IP address that you can link to your site. This means that you can even bind it to a “bare” domain. CNAME can also be tied to a second-level domain.
You need to create only one balancer in all regions. That is, in Amazon, we need to create a balancer in each region in order to balance between instances within that region, and in Google only one balancer, just one IP, and it balances between all your instances across different regions.
The Google Balancer is able to stick by both IP and cookie. I told you why Sticky is needed - we need to send one user to one backend. Amazon balancers can only cookie, that is, they themselves at the level of the balancer issue a cookie. Then it is checked, and if it is clear that the user has a cookie corresponding to one of the instances, it is sent to the same one. Google can IP, which is much better for us, although it does not always solve all problems.
The Google balancer has Instant warm-up: you don’t need to warm it up, you can immediately send up to a million requests to it. A million requests - this is what they promise themselves for sure, and what I myself checked. I think, then they grow somehow themselves inside.
But at the same time they have a problem with a sharp change in the number of backends. At some point, we added about 100 new hosts. At this stage, Google balancer bent. When we started talking with an engineer from Google, they said: add one per minute, then you will be happy.
Also recently, in their HTTP balancer, ports that you can use when creating a balancer have been clipped. Previously, there was a usual input field, now you can only choose between 80 and 8080 ports. For some, this can be a problem.
None of these cloud balancers have SNI support. If you need to support multiple domains and multiple certificates, then you need to create a separate balancer for each certificate and bind to it. This is a solvable problem, but this situation can be inconvenient.
Source: https://habr.com/ru/post/321560/
All Articles