Machine search for anomalies in the behavior of online stores and buyers

Some time ago we connected a machine learning module to a system that protects payments and transfers in Yandex.Money from fraud. Now she understands when something suspicious happens, even without explicit instructions in the settings.
In the article I will talk about the techniques and difficulties of finding anomalies in the behavior of customers and stores, as well as how to use machine learning models to make it all take off.
Why payments another check
Regardless of the type of authorization, any payment operation through Yandex.Money is tested by the antifraud system. This procedure allows you to protect all participants in the transaction:
the buyer - from direct losses due to the actions of fraudsters;
the seller and his acquiring bank - from making unauthorized payment, after which the funds will have to be returned;
- Yandex.Money - from fines and user dissatisfaction.
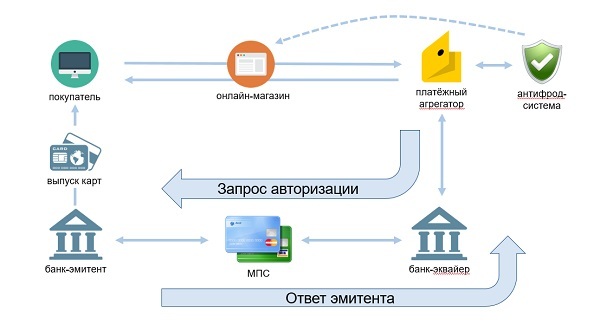
The general scheme of the payment process for the online store.
Antifraud is installed in the core of the Yandex.Money payment infrastructure, and any payment or transfer transactions come to the test for verification. If there are any suspicions, the anti-fraud may recommend additional authentication or mark the risk as high.
Initially, antifraud worked only on the basis of static rules (a transaction with some parameters is good, and with others it is bad), but static rules alone do not allow maintaining a consistently low level of false positives. They are difficult to take into account, for example, sudden sales surges or organic changes in user behavior. That is why a machine learning module was connected to the antifogue, which works in conjunction with static rules for more accurate risk assessment.
How robots make decisions
To work with machine learning methods, Yandex.Money uses one of the popular analysis systems in which machine learning models are built - let's call it ML. Let us take an example of how it all works.
In principle, the process is divided into two phases:
Training. During the training, the model parameters and significant features are identified;
- Application of the results, that is, the classification of new operations. In this phase, the class to which each new transaction belongs is determined - risky, fraudulent or secure.
When working out static rules, the anti-fraud algorithm sends a request with certain transaction attributes to the machine learning module for classification. The machine learning model analyzes them and gives a verdict with the likelihood that the fraudster is conducting the operation. Here the most subtle point is to select and form such attributes, but more on that later.

This is a diagram of the machine learning process in ML.
Let’s say, on behalf of Innocent’s user, a game currency is purchased for World of Tanks on Friday evening:
transaction amount - 15,000 rubles;
purchases are made from Australia;
the user works with the Safari browser on MacOS;
on the clock 15:23;
- another ten attributes.
Separately, these attributes do not cause any suspicion, because no one bothers Russians to travel and play games, as well as to use systems other than Windows.
But we have already met with Innocent before and we know that in the past months he bought mostly small household appliances and clothes in Russia with an average check of 7,000 rubles. Only this morning, he replenished the travel card in Moscow, so there should be no fundamental changes in his behavior.
Of course, some conclusions can be drawn already on the basis of a simple comparison of attributes from two neighboring operations. It is unlikely that our hero invented a way to get from Moscow to Australia faster than an airplane. Such a significant difference in geography in itself attracts attention.
But a simple comparison with a neighboring transaction in the case of amounts will already be ineffective. In principle, nothing prevents you from purchasing something larger after purchasing a travel card. And here the following approach is applied. Based on the available history data, a forecast is generated for each of the attributes of a new transaction with an indication of the range of possible values. If several attributes suddenly go beyond these boundaries, there is an anomaly that needs to be closely considered.
In addition, sometimes not specific values of any attributes are interesting, but some quality characteristics based on them. Therefore, in addition to using the data already in the transaction, the system can generate additional attributes of the operation. For example, such an attribute may be a sign “Amount greater than N rubles” instead of just a numeric value of the amount, or the difference between the actual value of some basic attribute and its prediction - this issue will be discussed in more detail later.
The result of the work of machine learning is not necessarily decisive - in the rules of antifraud there are many static criteria by which a decision is made. However, the results of this additional test can significantly improve the accuracy of fraud detection.
If in many ways the reality is too different from the forecast, this is a reason for suspicion and, for example, additional verification.
Anomaly search area
When buying from an online store, the greatest risk, as a rule, is assumed by the store, which in case of problems will have to work with protest and returns. Therefore, the most attention is paid to the search for anomalies in user behavior in antifraud systems.
But the behavior of the store can also be abnormal, which, like ordinary users, can also become the object of a scam attack or go to the side of evil. Therefore, it is important to detect in time when something is wrong with the store. You can notice such changes with the help of the same change in the nature of operations and the attributes associated with them.
Complexity of the analysis
From a set of known operation data, a set of attributes is compiled, which is useless without understanding which values are “good” and which are “bad.” That is, it is necessary to draw a line, at the exit of which the parameters of the operation will become suspicious for the antifraud system - these will be abnormal values for each attribute (in some cases, their combinations). This is where one of the biggest difficulties lies.
To build a confidence interval for the values of a bona fide transaction, you need to extrapolate data from the history of a particular user or store. The anomaly will be visible if we compare the current value of the parameters of the operation with the boundaries of the interval. Sometimes you need to compare not absolute, but normalized values. Yandex.Money analysts deal with such issues during the preparation and training of models.
In the learning process, the following methods are used:
probabilistic - building all sorts of distributions for class objects;
metric - calculation of distances between objects;
- Correlation - determination of quantitative relationships between several parameters of the system under study.
In addition, basic attributes such as the product group and the amount of the order is not enough to find patterns. Therefore, from the available data, analysts form additional complex attributes.
Any anomaly is an event out of the general range. It may seem that it is sufficient to simply rationalize data from the history of operations (discarding too low and too high values) in order to get an approximate spread of "good" transactions. But this does not work, as there are daily sales surges, promotions, sales.
Therefore, Yandex.Money uses, for example, the following algorithm for detecting anomalous attribute values:
extrapolation of time series values for each of the signs;
calculation of the difference between the actual value of the feature and the predicted machine;
- if the difference is too large and such anomalous events are united by something in common (IP, BIN card, browser) - most likely, the matter is unclean with a specific transaction.
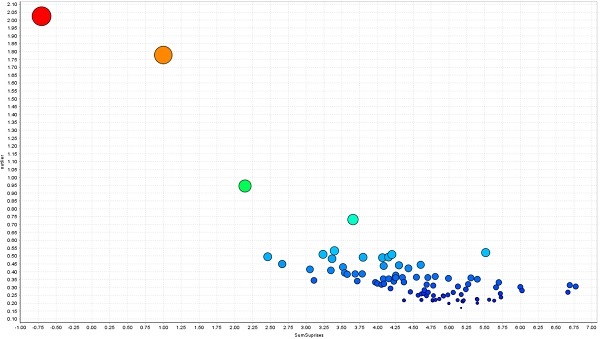
The graph shows the dependence of the event anomaly on a linear combination of signs. Anomaly is determined by the distance between events.
In order not to block the majority of normal payments, it is necessary to choose the right response threshold for a new sign of the anomaly, that is, a deviation from the normal picture, which we will consider essential and at which we will be ready to take action. There is no universal advice on choosing a specific value, because this threshold can be considered the price of a mistake for a business. For someone, a completely normal price will be the rejection of ten good transactions per day, and someone is not ready to lose even one.
The good news is that for each machine learning model you can set your threshold.
In all these technologies and complex math it is important to remember the user.
Users tend to be sympathetic to the inconvenience when it comes to the extra security of their money. For example, the outdated one-time codes on a scratch card can hardly be called convenient, but many users calmly refer to this small evil in exchange for protection from the great evil — fraudulent transactions on its own behalf. It is important to maintain a balance of convenience / speed and reliability, avoiding kinks.
For any modifications in the Yandex.Money "brains", we are especially careful to monitor the change in the processing time of each operation. Even an ideal defense will not find understanding with the user if he has to wait for confirmation for several minutes. Now transactions are executed almost instantly, given the work of the antifraud in real time.
The anti-fraud system has always influenced online payment, evaluating each transaction according to static rules. It is of utmost importance to us that adding risk assessment using machine learning does not increase processing time. It was for this purpose that a mechanism was developed which made it possible to carry out the classification by ML methods simultaneously with static rules.
But here we are faced with a new complexity - sometimes static rules and machine learning can give different answers, and from them you will need to choose the most suitable in a particular situation. For these purposes, a special module was developed that makes the final decision.
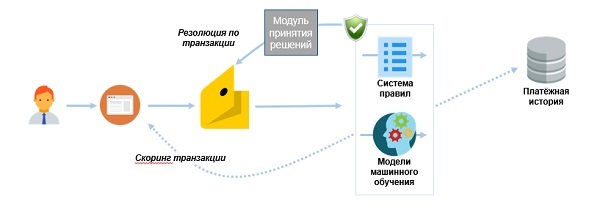
Antifraud connection scheme, in which the test is performed in real time for all operations.
The results of each test under the new scheme are:
synchronous response to the payment component of the system of rules and machine learning models;
- sending a scoring score and transaction data to a historical information base for use in verifying future operations.
Now the antifraud system has the opportunity to further evaluate the danger of a transaction based on statistics, and not to press the "red button" only if it coincides with static rules. For the user, this means an additional level of protection and a more flexible reaction of the system, even in cases where the purchase is knocked out by its attributes from the general mass.
Machine learning technologies involve working with vast amounts of data to make accurate predictions, so their point-of-implementation cannot be called a simple task. In our case, there was an ideal candidate — an antifraud, for whom an additional level of intelligence is crucial, and the volume of data passing through opens up wide possibilities for analysis.
')
Source: https://habr.com/ru/post/321490/
All Articles