Load balancing and fault tolerance in Odnoklassniki
 We continue posts with transcripts of speeches at the HighLoad ++ conference, which was held in Skolkovo, Moscow Region, on November 7—8, 2016.
We continue posts with transcripts of speeches at the HighLoad ++ conference, which was held in Skolkovo, Moscow Region, on November 7—8, 2016.Hello, my name is Nikita Dukhovny, and I work as the lead system administrator in the Odnoklassniki project.
At the moment, the Odnoklassniki infrastructure is located on more than 11 thousand physical servers. They are located in 3 main data centers in Moscow. We also have CDN presence points. According to the latest data at rush hour, we give our users more than 1 terabit of traffic per second.
')
In the system administration department, we develop and develop automation systems. We are engaged in many research tasks. We help developers launch new projects.
Today we will talk about load balancing and fault tolerance on the example of our social network.
At the dawn of the project, Odnoklassniki was faced with the task of making load balancing between many frontends. The project lived explosive growth, and therefore the decision was made as follows. The user went to
www.odnoklassniki.ru , in response received a redirect to a specific server name, for example, wg13.odnoklassniki.ru . This name was tightly bound to a physical server.This approach has obvious drawbacks. First, in case of problems with the server, the user received an error in the browser. Secondly, if we wanted to take the server out of rotation, we were faced with the fact that many users bookmarked the name of this server. Something needed to be changed.
Then we decided to put into operation load balancers. We had enough to use Layer 4 balancing. What does it mean? This means that the balancer is aware of the IP address and port. That is, the user, coming to virtual IP, port 80, will be sent to port 80 of the real server, coming to port 443, will be sent to port 443.
We considered different options. At that time, the choice was between proprietary solutions — both software and hardware and software — and the open source LVS project (Linux Virtual Server). According to the test results, we did not find any reason to dwell on proprietary solutions.
How we organized the LVS work scheme
The user request goes to the network equipment, it sends a request to LVS. LVS, in turn, sends a request to one of the front-end servers. Moreover, on LVS we use the persistence settings, that is, the next user request will be sent to the same front-end server.
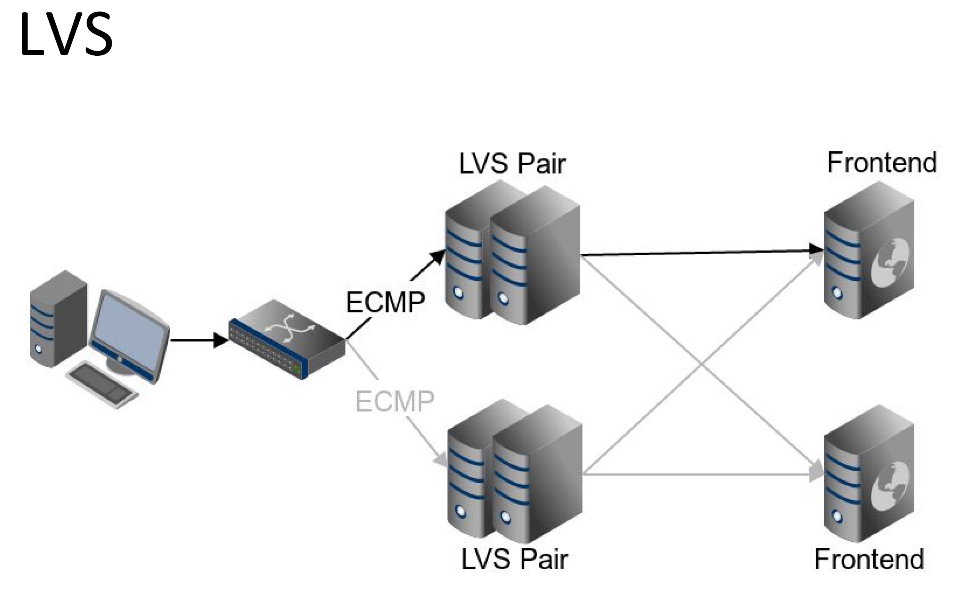
We wanted our LVS cluster to be fault tolerant, so we organized master / standby pairs. Between master / standby pairs, sessions are constantly synchronized. What is it for? So that when the master server is sent out, the user, upon entering the standby server, is sent to the same frontend.
VRRP is also running between the servers using the tools of the well-known keepalive daemon. This is to ensure that the IP address of the LVS server itself is moved to standby. We have a lot of such master / standby pairs. Between them we balance using ECMP protocol. Moreover, our network equipment is also aware of the settings of persistence, and thus the whole chain works. A user request will be sent to the same LVS pair, and the LVS pair, in turn, will send to the same frontend.
It was necessary to somehow manage the balance sheet. At that time, we chose the popular ldirector solution. The ldirecor daemon adds real servers to the balancing table based on its config. It also checks real servers. And if any of the real servers starts to return an error, ldirector adjusts the balance table, and this server is taken out of rotation.
Everything looked good, but the number of servers increased. At the moment, in each of our data centers, we have two hundred web-based frontends — these are the servers that process requests from
www.odnoklassniki.ru .The fact is that ldirector performs its checks in single-threaded mode. In case of problems, when the servers start responding longer than the timeout, the following happens: the request arrives at the first server, waits for the timeout time (for example, 5 seconds), and only after that the test starts the second server. Thus, with a large-scale problem, for example, when half of the servers are affected, the output of this half takes more than 8 minutes. It was unacceptable.
To solve this problem, we wrote our own solution: ok-lvs-monitor. It has two main advantages.
- Performs multi-threaded checks . This means that with the above problem, the servers will be taken out of rotation at the same time.
- Integrates with our portal configuration system . If earlier to change the table we needed to edit configs on the servers, now it is enough to edit the configuration in the same system where we manage the settings of our applications.
During the operation of the LVS, we are faced with a number of technical problems.
- We stumbled upon the fact that when synchronizing sessions there is a rather large discrepancy between master and standby.
- The synchronization process worked only on the first processor core.
- On a standby server, it consumed over 50% of this kernel.
- Different things were also noticed. For example, the ipvsadm balance table management utility did not distinguish between Active / InActive sessions in the case of our configuration.
We reported the bugs to the LVS project developer, helped with testing, and all these problems were fixed.
Persistence settings
Earlier, I mentioned that we use the settings for persistence. What is it for us?
The fact is that each front-end server stores in its memory information about the user session. And if the user comes to another frontend, this frontend must follow the user login procedure. For the user, this is transparent, but nevertheless it is a rather expensive technical operation.
LVS can do persistence based on client IP address. And here we are faced with the following problem. Mobile Internet gained popularity, and many operators, first of all, the largest operator in Armenia, hid their users for just a few IP addresses. This led to the fact that our mobile-web servers were very unevenly loaded, and many of them were overloaded.
We decided to ensure the persistence of the cookie that we put to the user. When it comes to a cookie, unfortunately, it is impossible to limit ourselves to Layer 4 balancing, because we are already talking about Layer 7, about the application level. We reviewed various solutions, and at that time HAProxy was the best. Popular today nginx then did not have the proper mechanisms of balancing.

A user request, getting on the network equipment, is balanced by the same ECMP protocol, so far nothing has changed. But then the interesting begins: without any persistence, a pure Round-robin request is sent to any of the HAProxy servers. Each of these servers in its configuration stores the correspondence of the cookie value to a specific front-end server. If the user has arrived for the first time, a cookie will be set for him; if the user has arrived for the second and subsequent times, he will be sent to the same mobile frontend.
Wait, you say, that is, "Classmates" put a cluster of balancers behind a cluster of balancers? It looks somehow complicated.

In fact, let's see. Why not?
In the case of our situation, the percentage of traffic passing through HAProxy is less than 10% of the traffic passing through the entire LVS. That is, for us this is not some expensive solution. But the advantage of this approach is obvious.
Imagine that we are conducting some kind of experimental reconfiguration of the HAProxy server. We want to evaluate the effect. And in this case, we start this HAProxy server in rotation with low weight. First, we can collect all the statistics before making a further decision. Secondly, in the worst case, only a small percentage of our users will notice any problems. After successful application on a small part, we can continue with the entire cluster.
Accidents in the data center
“Classmates” in their history have repeatedly encountered accidents. We had a story when both the main and backup optics to the data center burned down. Data center has become unavailable. We had a story when electrical wiring in a data center melted due to an incorrect design, which led to a fire. We had a very exciting story when a hurricane in Moscow tore off a piece of the roof, and he disabled the cooling system in the data center. We had to decide which servers to shut down and which ones to leave, because overheating had begun.
According to the results of these accidents, we formulated for ourselves the rule: “Classmates” should work in case of failure of any of the data centers.
How did we go towards this goal?
- We prepared our data storage systems. We implemented the functionality that allows our data systems to understand in which data center they are located.
- We use replication factor = 3. Together, these two points lead to the fact that in each of the data centers appears its own replica of the data.
- In our systems we use quorum = 2. This means that when one of the data centers departs, the system will continue its work.
We needed to distribute our frontend servers across three data centers. We did this, taking into account the power reserve, so that the front-ends in the data center could take on all the requests that had previously been made to the data center, which had now refused.

If you make a DNS request on
www.ok.ru , then you will see that you are given 3 IP addresses. Each of these addresses corresponds to a single data center.We handle the situation with the accident in the data center automatically. Here you can see an example of such a check:

It can be seen that in case 10 of the last 20 checks were unsuccessful, the IP address of this data center will cease to be given. 10 is quite a lot, the output of the data center is a difficult operation. We want to make sure that the accident has started. Here you can see that the data center will be automatically rotated in the event of 20 of the 20 successful checks. Yes, the conclusion - this is a difficult operation, but we want to be sure that everything is in order, before we get users.
According to our calculations, with this method, in 5 minutes 80% of the audience will leave the data center. There are assumptions, where did the figure 5 minutes come from?
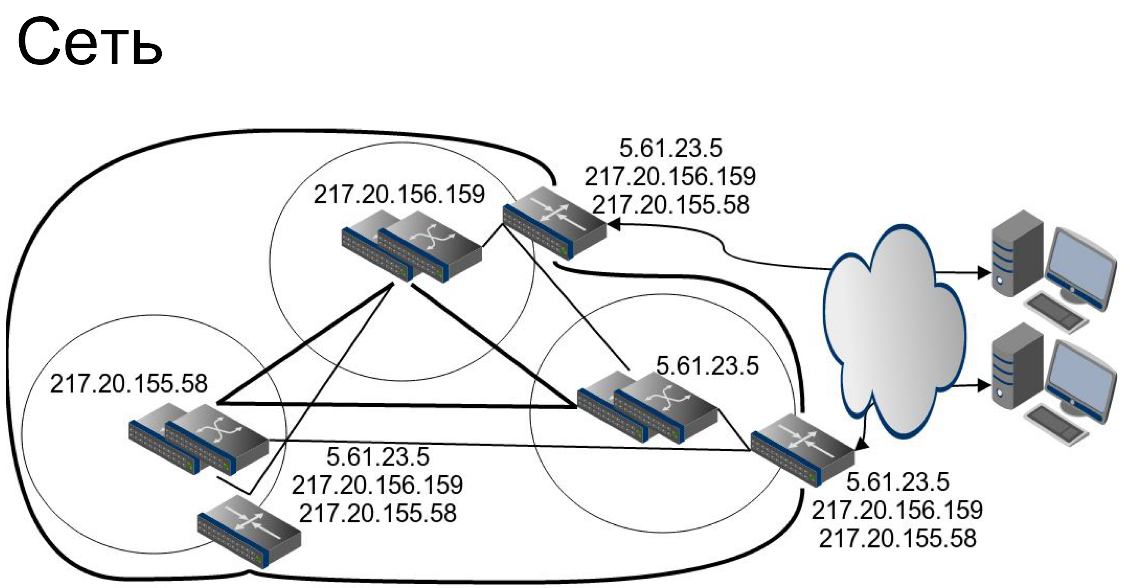
Network. At the network level, we use a rather curious trick. In fact, the border routers of each of the data centers announce all the networks in the world.
Imagine that a user goes to the IP address
217.20.156.159 . The user gets into one of the data centers. Another user, by accessing the same IP address, can actually get into the adjacent data center. What is it for? In case of failure of one of the border routers, users will not notice any effect.There is a subtle point. I just told you about the fact that in each data center we will have our IP address for the service and it seems that I will give you conflicting information. Not really. At the core level of the network, each data center still has its own set of networks, and just border routers, using either a direct connection or a ring, have the opportunity to send a request to the desired data center.
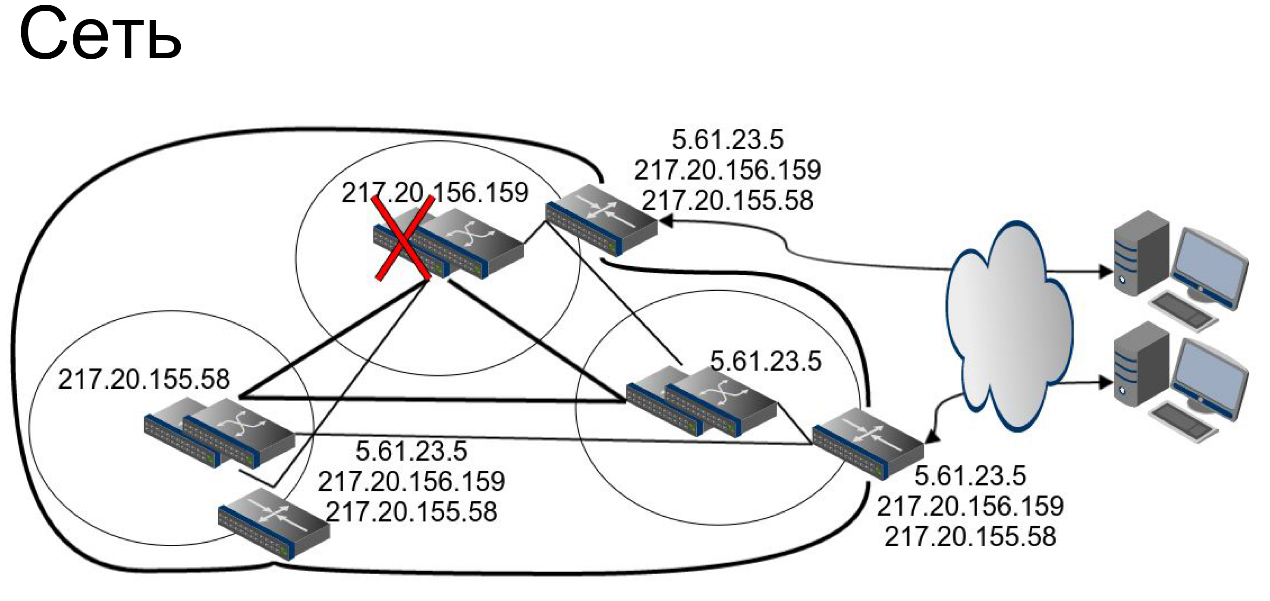
About the core network. All network equipment with us is reserved with such a reserve of power to be able to take on the load of the outgoing neighbor. Only an accident with the entire network core will really lead to a situation where we will have to output traffic from data centers.
Heavy content
By heavy content, I mean music, videos and photos.
The fact is that a significant part of the Odnoklassniki audience cannot boast the same quality of Internet connection as the residents of the capital. First, most of our audience lives outside the Russian Federation. In many countries, the speed of foreign Internet and domestic very different. Secondly, users in remote regions, in principle, often cannot boast of a stable channel. Even if it is stable, it does not mean at all that it is not slow.
We wanted to make it so comfortable for users to work with Odnoklassniki. So we thought about our own CDN solution.
The idea behind CDN is pretty simple. You take the caching servers and put them close to the user. When constructing a CDN, one of two classical approaches is usually used.
IP Anycast . Its essence lies in the fact that each of your sites announces to the world the same network, the same addresses. And what platform your user gets is determined by the current topology of the Internet. The advantages of this approach are obvious: you do not need to implement any logic in order for the user to get to the optimal site.

Cons are also clearly visible. Imagine that you have a CDN in Voronezh, you want to do serious service work with it. To do this, you need to send all users to a specific site, for example, to St. Petersburg. Using IP Anycast in its purest form, you do not have direct mechanisms for how you can do this. In addition, you will need to prepare your application for such a turn of events as an unexpected user transition. In the Internet topology, something has changed, and the user sends the next request to another site.
Another classic technology is based on the use of geolocation and DNS . What is the point?

A Muscovite, making a request for static content, for a service name that gives static content to the DNS, will receive in return a Moscow IP address and will be sent to the site in Moscow. A resident of Novosibirsk, making a similar request, will receive the IP address of the site in Novosibirsk and will be sent there.
The advantages of this approach are a high degree of control. The above task to send a resident of Voronezh to the site of your choice becomes quite simple. You just need to edit your base. But there are also disadvantages to this approach. First, this approach usually uses a geolocation base like GeoIP, and geographic proximity does not mean the fastest connection to this site. Secondly, this approach does not take into account the change in the topology on the Internet.
Odnoklassniki had one more task: we wanted to launch projects like “traffic to“ Odnoklassniki ”for free”. That is, choosing, for example, the mobile connection of our partner, everything that you do through the Odnoklassniki mobile app is not counted as a traffic expense. To accomplish such a task, our CDN should have the functionality that allows you to send only those networks to the site that our partner wants to see there.
Classic solutions for this problem are not suitable. What have we done?

At the CDN site, our BGP server establishes a connection with the provider’s Route Server, receiving from it a list of the networks that the provider wants to see on it. Next, the list of prefixes is transmitted to our GSLB DNS, and then the user, by accessing a DNS request, receives an IP address just in the right area. The site, in turn, of course, takes all the content from the main data centers.

Inside the site between the servers we balance, using a rather trivial approach. Each server has its own IP-address, and both IP-addresses are sent by DNS-request. Thus, users will be distributed between the servers approximately equally. In case of failure of one of the servers by means of the same VRRP protocol, the IP address will be transparently transferred to another node. Users will not notice anything.

Of course, we carry out inspections of all our sites. In case the site ceases to return the status OK, we cease to give its IP address. In this case, the user from Novosibirsk will go to data centers in Moscow. It will be a little slower, but it will work.
On our CDN sites we use internally developed applications for video, music and photos, as well as in addition to this nginx. I would like to mention the main point of optimization, which will be applied in our applications. Imagine that you have several servers that deliver heavy content. The user comes to one server and asks him for this content. Content is not there. Then the server takes this content from the site in Moscow. But what will happen when the next user comes for the same content to the second server? We would not want the server to go again for the same content to Moscow. Therefore, in the first place, he goes to his neighbor server and takes the content from it.
Future
I would like to talk about several projects that we would be very interested in doing and which we would be very interested in implementing.
We would like to see that each of our services, for example,
www.odnoklassniki.ru , still live with one IP address . For what?- In case of failure of the data center in this case, everything would be transparent for users.
- Vy would get rid of the problem with incorrectly leading caching DNS, which continue to give the IP address of the derived site, despite the fact that we don’t give it away.
- Once in TTL time (that is, in our case, once every 5 minutes), the user can still move to another site.
This is not a very technical operation, but nevertheless I would like to get rid of it. This is a very ambitious project, within its framework it is necessary to solve many problems.How to ensure persistence settings? How to carry out service work without being noticed? How to display a data center? In the end, how to prepare our application for this turn of events? All these issues to be solved.
Another interesting topic. These are Layer 4 balancers that work in user space . What is their essence?
In fact, when the balancer uses the Linux network stack, it constantly switches between user space and kernel space. This is quite an expensive operation for a CPU. In addition, network stack Linux is a universal solution. Like any universal solution, it is not ideal for this particular task. User space Layer 4 balancers independently implement the necessary functionality of the network stack that they need. Due to this, according to rumors, everything works very quickly.
I’ll tell you a little secret: in fact, now one of the partners is conducting research and some improvements for us, and we could see for ourselves the huge difference in speed.
These are only two projects from a possible future, which I have just named. In fact, they are much more.And, of course, most of them are connected with other topics, not only with load balancing and fault tolerance.

Let's see where this road will lead us. We always welcome new strong colleagues, please visit our technical site , you will find many interesting publications and videos of my colleagues' speeches on it.
Thanks for attention!
The last nine minutes of the speech, Nikita Dukhovny, answered questions from the audience.
Source: https://habr.com/ru/post/321448/
All Articles