Openstack. Detective story or where the connection is lost? Part one
This story is about OpenStack + KVM. It all started when everything worked fine. The “old” platform satisfied everyone. She was raised without us, and she was a little outdated. It was Juno. At the same time she worked.
In principle, it was a test, until one day it became a combat one. We know they did not know the problems they encountered later. The bosses, joyfully rubbing their hands, decided to upgrade their fleet of systems. Including the OpenStack test platform.
We decided to deploy manually, because at that moment there were no fuel solutions for the Mitaka version. Therefore, they deployed all the recipes from the official site. Of course, they added a little and from themselves, for example, replaced Memcached with Couchbase, and took percona in a cluster mode as a database. And everything went well. Until a certain point.
We have lost our packages. At first we thought the switch was to blame. Junos was on it is a rather old version - 11, which has known bugs. And on the console she really had messages confirming our guess. We replaced this hardware with another, with the new, 15th Junos firmware.
')
Meanwhile, the problem did not disappear, but only slowly began to expand. The general symptom looks like this - pings are suddenly lost. Constantly disconnected.
Frustratingly for us and customers.
We have one client, consumes a lot of traffic. And generates in response too much. He has broadcasts from webcams coming. He began to complain: the connection is lost and that's it.
Here is what we saw on monitoring:
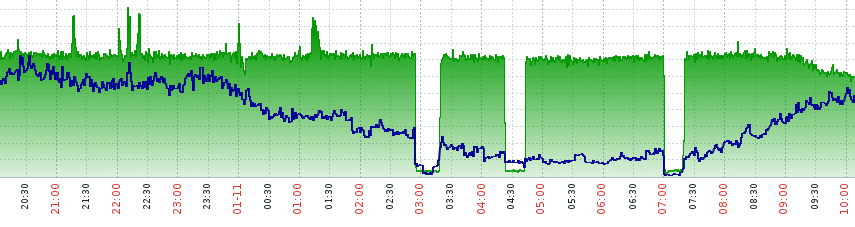
Indeed - the client is right, something is wrong. But where??? At one of those moments, we found the reason - the wrong ARP was glowing on the network. Where is the culprit? The guilty address was found on the issuing firewall. There was a line entered by the admin in error:
Thank God, they found - was the first thought. But it was not there. The loss of packets, no matter what tcp, icmp, udp - continued.
We continued to search, and it became clear that the problem was somewhere inside OpenStack. When I started pinging a test virtual machine, I almost fell off my chair:

This meant that for some reason some of the packets were not broadcast, and fell out with gray addresses! Naturally, these packages never reached anyone.
We will share what we could dig, but later. I would like to see the opinion of a respected public, what we did wrong and where it was necessary to look
In principle, it was a test, until one day it became a combat one. We know they did not know the problems they encountered later. The bosses, joyfully rubbing their hands, decided to upgrade their fleet of systems. Including the OpenStack test platform.
We decided to deploy manually, because at that moment there were no fuel solutions for the Mitaka version. Therefore, they deployed all the recipes from the official site. Of course, they added a little and from themselves, for example, replaced Memcached with Couchbase, and took percona in a cluster mode as a database. And everything went well. Until a certain point.
We have lost our packages. At first we thought the switch was to blame. Junos was on it is a rather old version - 11, which has known bugs. And on the console she really had messages confirming our guess. We replaced this hardware with another, with the new, 15th Junos firmware.
')
Meanwhile, the problem did not disappear, but only slowly began to expand. The general symptom looks like this - pings are suddenly lost. Constantly disconnected.
Frustratingly for us and customers.
We have one client, consumes a lot of traffic. And generates in response too much. He has broadcasts from webcams coming. He began to complain: the connection is lost and that's it.
Here is what we saw on monitoring:
Indeed - the client is right, something is wrong. But where??? At one of those moments, we found the reason - the wrong ARP was glowing on the network. Where is the culprit? The guilty address was found on the issuing firewall. There was a line entered by the admin in error:
set security nat proxy-arp interface xxxx address yy.zz.tt.cc/32 Thank God, they found - was the first thought. But it was not there. The loss of packets, no matter what tcp, icmp, udp - continued.
We continued to search, and it became clear that the problem was somewhere inside OpenStack. When I started pinging a test virtual machine, I almost fell off my chair:
This meant that for some reason some of the packets were not broadcast, and fell out with gray addresses! Naturally, these packages never reached anyone.
We will share what we could dig, but later. I would like to see the opinion of a respected public, what we did wrong and where it was necessary to look
Source: https://habr.com/ru/post/321442/
All Articles