Andrew Un's draft of The Thirst for Machine Learning, Chapters 1-7
Last December, in a correspondence with American colleagues in data science, a wave of discussion of the long-awaited draft of the new book of machine learning guru Andrew Ng ( Andrew Ng ) “Thirst for machine learning: strategies for engineers in the era of deep learning” swept. The long-awaited, because the book was announced in the summer of 2016, and now, finally, several chapters appeared.

I present to the Habra community the translation of the first seven chapters of the currently available fourteen chapters. I note that this is not the final version of the book, but a draft. There are a number of inaccuracies. Andrew Eun offers to write your comments and comments here . The author begins with things that seem obvious. Further more complex concepts are expected.
Machine learning (ML) is the foundation of an infinite number of important products and services, including Internet search, anti-spam, speech recognition, recommendation systems, and so on. I assume that you and your team are working on products with machine learning algorithms, and you want to make rapid progress in development. This book will help you with this.
Let's say you are creating a startup that will provide a continuous stream of photos of cats for cat lovers. You use a neural network to create a computer vision system to detect cats in a photo taken with smartphones.
')

But, unfortunately, the accuracy of your algorithm is not high enough. You are under tremendous pressure, you have to improve the “cat detector”. What to do?
Your team has lots of ideas, for example:
• Collect more data: take more images of cats.
• Collect a more diverse training set: for example, cats in unusual poses, cats of rare color, photos taken with different camera settings, ...
• Teach the model longer, use more iterations of the gradient descent.
• Try a larger neural network: more layers / connections / parameters.
• Experiment with a smaller network.
• Add regularization, for example, L2.
• Change network architecture: activation function, number of hidden layers, etc.
•…
If the choice among possible alternatives is successful, then you will be able to create a leading system for finding photos of cats, and this will lead the company to success. If the choice is unsuccessful, then lose months. How to act in such a situation?
This book will tell you how. Most machine learning tasks leave key clues that say it is useful to try and what not. The ability to see such tips can save months and years of development time.
After reading this book, you will know how to set design directions in a project with machine learning algorithms. However, your colleagues may not understand why you have chosen this or that direction. You might want your team to define a quality metric as a single numerical parameter, but colleagues disagree on using only one indicator. How to convince them? That is why I made the chapters in this book short: just print and let your colleagues read 1-2 pages of key information they need to know.
Minor changes in the priority of tasks can have a huge effect on team performance. I hope you can become a superhero if you help your team make such changes.
If you studied the course “Machine Learning” on a Coursera or have experience in applying learning algorithms with a teacher (supervised learning), then this is enough to understand the text of the book. I assume that you are familiar with the teaching methods with the teacher: finding a function that, by the values of x, allows you to get y for all x, having a marked training set for some (x, y). These types of algorithms include, for example, linear regression, logistic regression, and neural networks. There are many areas of machine learning, but most of the practical results are achieved with the help of learning algorithms with a teacher.
I will often talk about neural networks (NN) and deep learning. You only need a general understanding of their concepts. If you are not familiar with the concepts mentioned above, then first watch the lecture video of the “Machine Learning” course on Coursera.
Many in-depth learning / neural network ideas have been in the air for many years. Why we started using them right now? The greatest contribution to the progress of recent years has been given by two factors:
• Data availability: now people are constantly using digital devices (laptops, smartphones, etc.), their digital activity generates huge amounts of data that we can “feed” to our algorithms.
• Computational power: only a few years ago it became possible to massively train large enough neural networks to experience the benefits of the huge data sets that are available now.
Usually, the quality score of “old” algorithms, such as logistic regression, goes to a constant level, even if you have accumulated more training data, i.e. from a certain limit, the quality of the algorithm performance ceases to improve with an increase in the training sample. If you train a small neural network on the same task, you can get a little better result. Here, under the “small” neural network, I mean a network with a small number of hidden layers, connections and parameters. After all, if you are teaching a larger and larger network, then you can get better results.
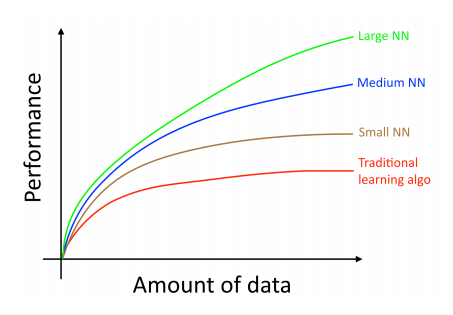
Author's note: This graph shows that NN works better than traditional ML algorithms, even in the case of a small amount of data for training. This is less correct than for a huge amount of data. For small samples, traditional algorithms may be better or worse, depending on the characteristics that are manually constructed. For example, if you have only 20 samples / use cases for training, then it doesn’t matter if you use logistic regression or a neural network, the feature set will have a significantly greater effect compared with the choice of algorithm. But if you have a million samples to learn, then I prefer to use a neural network.
Thus, the best results are achieved:
1. when a very large neural network is being trained (so as to be on the green curve in the figure);
2. when a huge amount of data is used for training.
There are also many other details, such as the network architecture, where many innovations constantly appear. Nevertheless, one of the most reliable ways to improve the quality of the algorithm remains (1) to train a large NN and (2) to use more data for training. In practice, following points (1) and (2) is extremely difficult. This book discusses the details of this process. We begin with general approaches that are useful for both traditional ML algorithms and NN, then select the most effective strategies for building depth learning systems.
Translator's note: Andrew Un uses the term “development set” to refer to the sample on which the model parameters are tuned. Currently, this sample is more commonly called the “validation set” - validation sample. Indeed, the term “validation” does not correspond to the variety of tasks for which this sample is applied, and the name “development set” more corresponds to the status quo. However, I was not able to find a good translation for the “development set”, so I am writing a “development sample” or a “development work sample”. It may be reasonable to call this sample “tuning” (thanks to kfmn ).
Let's go back to the example with photos of cats. So, you are developing a mobile application, users download various photos into your application, which automatically finds among them photos of cats. Your team has created a large data set by uploading photos of cats (positive samples) and non-cats (negative samples) from the websites. Then this data set was divided into training (70%) and test (30%) samples. Using the sample data, a “cat detector” was created that worked well for objects from test and training samples. But when this classifier was implemented in a mobile application, you found that the quality of its work is really low! What happened?
You found out that the photos that users upload to your application look different than the images from the websites that make up the training sample: users upload photos taken by smartphones, these images have a different resolution, less clear, and the scene is not perfectly lit. Since the training and test samples were compiled from images from web sites, your algorithm does not generalize to the actual distribution of the data for which the algorithm is being developed, i.e. Does not summarize photos from smartphones.
Before the “big data” era, the general rule in machine learning was to randomly break a 70% / 30% data set into a training and test set. This approach may work, but it is a bad idea for more and more tasks, where the distribution of data in the training set is different from the distribution of data, for which, ultimately, the problem is solved.
Usually we define three samples:
• training, which runs the learning algorithm;
• For development (development set), which is used to adjust parameters, select features and make other decisions regarding the learning algorithm, sometimes such a sample is called held for cross-validation (hold-out cross validation set);
• Test, which assess the quality of the algorithm, but based on it do not make any decisions about which learning algorithm or parameters to use.
As soon as you make a test sample and sample for development, your team will begin to try many ideas, for example, the various parameters of the learning algorithm to see what works best. These samples allow you to quickly assess how well the model works. In other words, the goal of test and work (development) samples is to direct your team towards the most important changes in the development of machine learning systems. Thus, you should do the following: create a working and test sample so that they correspond to the data you expect to receive in the future, and on which your system should work well. In other words, your test sample should not just include 30% of the available data, especially if in the future you expect data (photos from smartphones) that differ from the data in the training sample (images from websites).
If you have not yet begun to distribute your mobile application, then as long as you do not have users, and it is not possible to collect exactly the data that you expect in the future. But you can try to approximate them. For example, ask your friends and acquaintances to take photos with mobile phones and send them to you. As soon as you publish the mobile application, you will be able to update the developmental and test sample with real user data.
If there is no possibility of obtaining data that approximates what is expected in the future, then perhaps you can start working with images from web sites. But you must clearly understand that it is a risk to create a system that has a low generalizing ability for a given task.
It is necessary to estimate how much time and effort you are willing to invest in creating two powerful samples: for development and test. Do not make blind assumptions that the distribution of data in the training sample is exactly the same as in the test sample. Try to choose test examples that reflect what should work well in the end, and not any data that you are lucky enough to have for training.
The feline mobile app photos are segmented into four regions that correspond to the largest application markets: USA, China, India and the rest of the world. You can create a working sample from the data of two randomly selected segments, and put the data of the two remaining ones into the test sample. Right? No, mistake! Once you determine these two samples, the team will focus on improving the quality of the working sample. Consequently, this sample should reflect the whole task that you are solving, and not part of it: you need to work well in all markets, not just in two.
There is another problem in the inconsistency of the data distribution in the working and test samples: there is a chance that your team will create something well working on the sample for development, and then make sure that it does not work well on the test sample. As a result, there will be a lot of frustration and wasted effort. Avoid this.
Suppose your team has developed a system that works well on a sample for development, but not on a test one. If both samples were obtained from the same source / distribution, then there is a fairly clear diagnosis of what went wrong: you have overtrained on the working sample. The obvious cure: increase the amount of data in the work sample. But if these two samples do not match, then there are a lot of things that could “go wrong.” In general, it is quite difficult to work on applications with machine learning algorithms. The discrepancy between the working and test samples introduces additional uncertainty in the question: will the improvement in the work on the working sample lead to improvements in the test sample? Having such a discrepancy, it is difficult to understand what is not working, it is difficult to prioritize: what should have been tried first.
If you are working on a task, when a sample is provided by a third-party company / organization, then the working and test sample may have different distributions, and you cannot influence this situation. In this case, luck, not skill, will have a greater impact on the quality of the model. Learning a model on data that has one distribution, for processing data (also with a high generalizing ability) that has a different distribution, is an important research problem. But if your goal is to get a practical result, not a study, then I recommend using data from the same source and equally distributed for the working and test samples.
The working sample should be large enough to detect the difference between the algorithms that you are trying. For example, if classifier A gives an accuracy of 90.0%, and classifier B has an accuracy of 90.1%, then a working sample of 100 samples will not allow to see a change of 0.1%. In general, a working sample of 100 samples is too small. Common practices are samples from 1,000 to 10,000 samples. With 10,000 samples, you have a chance to see a 0.1% improvement.
Author's note: it is theoretically possible to conduct statistical tests in order to determine whether changes in the algorithm led to significant changes in the working sample, but in practice most teams do not bother with this (unless they write a scientific article), I also do not find such tests useful for assessing interim progress.
For developed and important systems, such as advertising, search, recommendation systems, I saw teams that were striving to achieve improvements even at 0.01%, as this directly affected the profits of their companies. In this case, the working sample must be well over 10,000 to be able to determine the slightest change.
What can be said about the size of the test sample? It should be large enough to evaluate with high confidence the quality of the system. One popular heuristic was to use 30% of the available data for a test sample. This works quite well when you have a small amount of data, say, from 100 to 10,000 samples. But in the era of “big data”, when there are tasks with more than a million samples for training, the proportion of data in the working and test sample is reduced, even when the absolute size of these samples is growing. There is no need to have working and test samples much larger than the volume that allows you to evaluate the quality of your algorithms.
I present to the Habra community the translation of the first seven chapters of the currently available fourteen chapters. I note that this is not the final version of the book, but a draft. There are a number of inaccuracies. Andrew Eun offers to write your comments and comments here . The author begins with things that seem obvious. Further more complex concepts are expected.
1. Why are machine learning strategies?
Machine learning (ML) is the foundation of an infinite number of important products and services, including Internet search, anti-spam, speech recognition, recommendation systems, and so on. I assume that you and your team are working on products with machine learning algorithms, and you want to make rapid progress in development. This book will help you with this.
Let's say you are creating a startup that will provide a continuous stream of photos of cats for cat lovers. You use a neural network to create a computer vision system to detect cats in a photo taken with smartphones.
')
But, unfortunately, the accuracy of your algorithm is not high enough. You are under tremendous pressure, you have to improve the “cat detector”. What to do?
Your team has lots of ideas, for example:
• Collect more data: take more images of cats.
• Collect a more diverse training set: for example, cats in unusual poses, cats of rare color, photos taken with different camera settings, ...
• Teach the model longer, use more iterations of the gradient descent.
• Try a larger neural network: more layers / connections / parameters.
• Experiment with a smaller network.
• Add regularization, for example, L2.
• Change network architecture: activation function, number of hidden layers, etc.
•…
If the choice among possible alternatives is successful, then you will be able to create a leading system for finding photos of cats, and this will lead the company to success. If the choice is unsuccessful, then lose months. How to act in such a situation?
This book will tell you how. Most machine learning tasks leave key clues that say it is useful to try and what not. The ability to see such tips can save months and years of development time.
2. How to use this book to help your team?
After reading this book, you will know how to set design directions in a project with machine learning algorithms. However, your colleagues may not understand why you have chosen this or that direction. You might want your team to define a quality metric as a single numerical parameter, but colleagues disagree on using only one indicator. How to convince them? That is why I made the chapters in this book short: just print and let your colleagues read 1-2 pages of key information they need to know.
Minor changes in the priority of tasks can have a huge effect on team performance. I hope you can become a superhero if you help your team make such changes.
3. What should you know?
If you studied the course “Machine Learning” on a Coursera or have experience in applying learning algorithms with a teacher (supervised learning), then this is enough to understand the text of the book. I assume that you are familiar with the teaching methods with the teacher: finding a function that, by the values of x, allows you to get y for all x, having a marked training set for some (x, y). These types of algorithms include, for example, linear regression, logistic regression, and neural networks. There are many areas of machine learning, but most of the practical results are achieved with the help of learning algorithms with a teacher.
I will often talk about neural networks (NN) and deep learning. You only need a general understanding of their concepts. If you are not familiar with the concepts mentioned above, then first watch the lecture video of the “Machine Learning” course on Coursera.
4. What large-scale changes contribute to progress in machine learning?
Many in-depth learning / neural network ideas have been in the air for many years. Why we started using them right now? The greatest contribution to the progress of recent years has been given by two factors:
• Data availability: now people are constantly using digital devices (laptops, smartphones, etc.), their digital activity generates huge amounts of data that we can “feed” to our algorithms.
• Computational power: only a few years ago it became possible to massively train large enough neural networks to experience the benefits of the huge data sets that are available now.
Usually, the quality score of “old” algorithms, such as logistic regression, goes to a constant level, even if you have accumulated more training data, i.e. from a certain limit, the quality of the algorithm performance ceases to improve with an increase in the training sample. If you train a small neural network on the same task, you can get a little better result. Here, under the “small” neural network, I mean a network with a small number of hidden layers, connections and parameters. After all, if you are teaching a larger and larger network, then you can get better results.
Author's note: This graph shows that NN works better than traditional ML algorithms, even in the case of a small amount of data for training. This is less correct than for a huge amount of data. For small samples, traditional algorithms may be better or worse, depending on the characteristics that are manually constructed. For example, if you have only 20 samples / use cases for training, then it doesn’t matter if you use logistic regression or a neural network, the feature set will have a significantly greater effect compared with the choice of algorithm. But if you have a million samples to learn, then I prefer to use a neural network.
Thus, the best results are achieved:
1. when a very large neural network is being trained (so as to be on the green curve in the figure);
2. when a huge amount of data is used for training.
There are also many other details, such as the network architecture, where many innovations constantly appear. Nevertheless, one of the most reliable ways to improve the quality of the algorithm remains (1) to train a large NN and (2) to use more data for training. In practice, following points (1) and (2) is extremely difficult. This book discusses the details of this process. We begin with general approaches that are useful for both traditional ML algorithms and NN, then select the most effective strategies for building depth learning systems.
5. What should be the sample?
Translator's note: Andrew Un uses the term “development set” to refer to the sample on which the model parameters are tuned. Currently, this sample is more commonly called the “validation set” - validation sample. Indeed, the term “validation” does not correspond to the variety of tasks for which this sample is applied, and the name “development set” more corresponds to the status quo. However, I was not able to find a good translation for the “development set”, so I am writing a “development sample” or a “development work sample”. It may be reasonable to call this sample “tuning” (thanks to kfmn ).
Let's go back to the example with photos of cats. So, you are developing a mobile application, users download various photos into your application, which automatically finds among them photos of cats. Your team has created a large data set by uploading photos of cats (positive samples) and non-cats (negative samples) from the websites. Then this data set was divided into training (70%) and test (30%) samples. Using the sample data, a “cat detector” was created that worked well for objects from test and training samples. But when this classifier was implemented in a mobile application, you found that the quality of its work is really low! What happened?
You found out that the photos that users upload to your application look different than the images from the websites that make up the training sample: users upload photos taken by smartphones, these images have a different resolution, less clear, and the scene is not perfectly lit. Since the training and test samples were compiled from images from web sites, your algorithm does not generalize to the actual distribution of the data for which the algorithm is being developed, i.e. Does not summarize photos from smartphones.
Before the “big data” era, the general rule in machine learning was to randomly break a 70% / 30% data set into a training and test set. This approach may work, but it is a bad idea for more and more tasks, where the distribution of data in the training set is different from the distribution of data, for which, ultimately, the problem is solved.
Usually we define three samples:
• training, which runs the learning algorithm;
• For development (development set), which is used to adjust parameters, select features and make other decisions regarding the learning algorithm, sometimes such a sample is called held for cross-validation (hold-out cross validation set);
• Test, which assess the quality of the algorithm, but based on it do not make any decisions about which learning algorithm or parameters to use.
As soon as you make a test sample and sample for development, your team will begin to try many ideas, for example, the various parameters of the learning algorithm to see what works best. These samples allow you to quickly assess how well the model works. In other words, the goal of test and work (development) samples is to direct your team towards the most important changes in the development of machine learning systems. Thus, you should do the following: create a working and test sample so that they correspond to the data you expect to receive in the future, and on which your system should work well. In other words, your test sample should not just include 30% of the available data, especially if in the future you expect data (photos from smartphones) that differ from the data in the training sample (images from websites).
If you have not yet begun to distribute your mobile application, then as long as you do not have users, and it is not possible to collect exactly the data that you expect in the future. But you can try to approximate them. For example, ask your friends and acquaintances to take photos with mobile phones and send them to you. As soon as you publish the mobile application, you will be able to update the developmental and test sample with real user data.
If there is no possibility of obtaining data that approximates what is expected in the future, then perhaps you can start working with images from web sites. But you must clearly understand that it is a risk to create a system that has a low generalizing ability for a given task.
It is necessary to estimate how much time and effort you are willing to invest in creating two powerful samples: for development and test. Do not make blind assumptions that the distribution of data in the training sample is exactly the same as in the test sample. Try to choose test examples that reflect what should work well in the end, and not any data that you are lucky enough to have for training.
6. Development and test samples must be from the same source and have the same distribution.
The feline mobile app photos are segmented into four regions that correspond to the largest application markets: USA, China, India and the rest of the world. You can create a working sample from the data of two randomly selected segments, and put the data of the two remaining ones into the test sample. Right? No, mistake! Once you determine these two samples, the team will focus on improving the quality of the working sample. Consequently, this sample should reflect the whole task that you are solving, and not part of it: you need to work well in all markets, not just in two.
There is another problem in the inconsistency of the data distribution in the working and test samples: there is a chance that your team will create something well working on the sample for development, and then make sure that it does not work well on the test sample. As a result, there will be a lot of frustration and wasted effort. Avoid this.
Suppose your team has developed a system that works well on a sample for development, but not on a test one. If both samples were obtained from the same source / distribution, then there is a fairly clear diagnosis of what went wrong: you have overtrained on the working sample. The obvious cure: increase the amount of data in the work sample. But if these two samples do not match, then there are a lot of things that could “go wrong.” In general, it is quite difficult to work on applications with machine learning algorithms. The discrepancy between the working and test samples introduces additional uncertainty in the question: will the improvement in the work on the working sample lead to improvements in the test sample? Having such a discrepancy, it is difficult to understand what is not working, it is difficult to prioritize: what should have been tried first.
If you are working on a task, when a sample is provided by a third-party company / organization, then the working and test sample may have different distributions, and you cannot influence this situation. In this case, luck, not skill, will have a greater impact on the quality of the model. Learning a model on data that has one distribution, for processing data (also with a high generalizing ability) that has a different distribution, is an important research problem. But if your goal is to get a practical result, not a study, then I recommend using data from the same source and equally distributed for the working and test samples.
7. What size should be test and working (development) of the sample?
The working sample should be large enough to detect the difference between the algorithms that you are trying. For example, if classifier A gives an accuracy of 90.0%, and classifier B has an accuracy of 90.1%, then a working sample of 100 samples will not allow to see a change of 0.1%. In general, a working sample of 100 samples is too small. Common practices are samples from 1,000 to 10,000 samples. With 10,000 samples, you have a chance to see a 0.1% improvement.
Author's note: it is theoretically possible to conduct statistical tests in order to determine whether changes in the algorithm led to significant changes in the working sample, but in practice most teams do not bother with this (unless they write a scientific article), I also do not find such tests useful for assessing interim progress.
For developed and important systems, such as advertising, search, recommendation systems, I saw teams that were striving to achieve improvements even at 0.01%, as this directly affected the profits of their companies. In this case, the working sample must be well over 10,000 to be able to determine the slightest change.
What can be said about the size of the test sample? It should be large enough to evaluate with high confidence the quality of the system. One popular heuristic was to use 30% of the available data for a test sample. This works quite well when you have a small amount of data, say, from 100 to 10,000 samples. But in the era of “big data”, when there are tasks with more than a million samples for training, the proportion of data in the working and test sample is reduced, even when the absolute size of these samples is growing. There is no need to have working and test samples much larger than the volume that allows you to evaluate the quality of your algorithms.
Source: https://habr.com/ru/post/321368/
All Articles