There are two functions
There are two boolean functions.
If you do not know how to solve a similar problem, welcome under cat. There I will talk about quantum algorithms and show you how to emulate them in the most popular language - in Python.
I've come to talk with you again
Let's formulate the problem of two functions a little more formally. Let a Boolean function be given.

Example:
')
balanced:
0 0 0 0 one one one 0 one one one 0 constant:
0 0 one 0 one one one 0 one one one one neither balanced nor constant:
0 0 0 0 one 0 one 0 0 one one one
The task is, of course, artificial and it is unlikely that someone will ever meet in practice, but it is a classic guide to the brave new world of quantum computing, and I don’t dare break traditions.
Classic deterministic solution

Let's first solve the problem in the classical model of computation. To do this, in the worst case, you need to call the function on
Algorithm in Python:
from itertools import product, starmap, tee def pairwise(xs): a, b = tee(xs) next(b, None) return zip(a, b) def is_constant(f, n): m = 2 ** (n - 1) for i, (x, y) in enumerate(pairwise(starmap(f, product({0, 1}, repeat=n)))): if i > m: break if x != y: return False return True Classic probabilistic solution

But what if, instead of half the arguments, we check a smaller number of them and make a verdict? Exact answer will not be, but with what probability we make a mistake? Let's say we calculated a function on
Reverse function:
With fixed
Algorithm in Python:
import random from itertools import product, starmap, tee def pairwise(xs): a, b = tee(xs) next(b, None) return zip(a, b) def is_constant(f, n, k=14): xs = list(product({0, 1}, repeat=n)) random.shuffle(xs) xs = xs[:k] for x, y in pairwise(starmap(f, xs)): if x != y: return False return True And if I tell you that there is a constant deterministic solution with complexity
However, before you consider it, you will have to digress ...
Because a vision softly creeping
Myths
Before starting, I would like to discuss a few common myths associated with quantum computing:
- Quantum algorithms are hard.

Yes, they are difficult to synthesize, because it requires for this mathematical imagination and insight. They are difficult to implement on real quantum computers: for this you need to know the physics perfectly and stay up late every day in the laboratory at the department. But what exactly does not require any special knowledge and an incredible amount of zeal is their understanding. I argue that everyone can understand quantum algorithms : they rely on extremely simple mathematics, accessible to any freshman. All that is required of you - just a little time to study. - There are already quantum computers on thousands of qubits from D-Wave
No, these are not real quantum computers. - There is not a single real quantum computer.
No, there are. In the laboratory, and they have only a few qubits. - Quantum computers will allow to solve problems that were previously unavailable.
No, the set of problems computable in the classical and quantum models coincide. Quantum computing only reduces the complexity of a small subset of these problems. - On the Crysis quantum computer at max speeds will fly

With the exception of a certain subset of problems that the quantum model of computation is capable of speeding up, the rest can be solved only by emulating a classical computer. Which, as you understand, is very slow. Crysis is likely to lag. - A quantum computer is a black box with input and output, looking into which you can ruin everything.

If you are 12 years old, this analogy will fit. In any other case, it, like all other analogies with boxes, cats, loops and electrons “bound” by threads, so actively promoted in all popular science sources, only confuses, creates the illusion of false understanding and is more harmful than useful. Discard these analogies.
What for?
Why should an applied mathematics (programmer) be able to understand quantum algorithms at the application level? Everything is simple, I am ready to offer you two reasons:
- For self-development. Why not?
- They are already coming. They are quantum computers. They are already near. You will not have time to blink, as a couple will appear in the server of your company, and in a few more years in the form of a coprocessor in your laptop. And there will be nowhere to run. We'll have to program for them, call quantum coroutines. And without understanding it is difficult to do, agree.
I was sleeping
The most basic component of quantum computing is a quantum system. A quantum system is a physical system, all of whose actions are comparable in magnitude with the Planck constant. This definition and the fact that quantum systems obey the laws of matrix mechanics - all the knowledge that we need from physics. Next - only math.

Like any other physical system, a quantum system can be in a certain state. All possible states of a quantum system form a Hilbert space
- Linear (vector) space - a set of elements
with the operations of addition of elements introduced on it
and multiplications
on field item
(in our case, the field of complex numbers). These operations must be closed (the result must belong to the set
- In metric space
distance determined
which satisfies the requirements (the axioms of metric
spaces):, wherein
then and only if
and
match up;
;
- triangle inequality.
- In normalized space
there is a real number
, called its norm and satisfying, again, three axioms:
, if
then
- zero element;
;
.
In the resulting space we introduce the scalar product that satisfies the usual requirements of the scalar product, we introduce the norm as shown above and obtain the Hilbert space.
Let us also discuss the concept of conjugate space . Space conjugate to
Where
For historical reasons, Dirac is used in quantum informatics. They may seem unreasonably cumbersome and fanciful, but they are a standard worth adhering to. In these notation, an element of our Hilbert space that describes the state of the system is called a ket vector and is denoted by
Sconce vector is an element of the conjugate space
such that
That is, it is a linear operator, the application of which to our state vector is similar to the scalar product on the corresponding element of the “original” Hilbert space. For convenience of writing, when applying the bra-vector to the ket vector, the two vertical lines merge into one, as shown in the expression above.
It is important that the vectors differing only by multiplying by some non-zero constant correspond to the same physical state, therefore, not all possible states are often considered, but only the normalized ones, that is, such a subset
- the norm of each element is equal to one. All such vectors live on a single hypersphere.
If we isolate in our Hilbert state space some basis
in this case, the matrix mechanics tells us that the squares of the modules of the coefficients of the decomposition
Here it is - the first and main property of quantum systems , which is so often gnawed in popular articles: if you measure the system in some basis, it will go into one of the basic states, lose information and will not be able to go back. It’s only when reading it that one gets the feeling that everything happens absolutely randomly and cannot be influenced in any way, whereas in fact the transition probabilities are known in advance and, moreover, depend on the measurement basis. If everything were as random as we are supposed to be, deterministic quantum algorithms would be impossible.
If we can represent an element of the Hilbert space as a vector for some fixed basis, then we can represent the linear operator over this space as a matrix.
Really,
is equivalent to
Where
Let the operator
Matrix elements are complex numbers. Let's take each element and replace it with complex conjugate (complex conjugate to
Such a matrix
The second rule that matrix mechanics dictates to us : only unitary operators can act on a quantum system. Why? Because such transformations are reversible in time and do not lose information. Indeed, if
then you can apply the inverse transform
and get the initial state of the system.
Finally, the most important: tensor product . The tensor product of two Hilbert spaces
- The dimension of the resulting space is equal to the product of the dimensions of the original spaces:
;
- If a
- basis
, but
- basis
then
- generating basis
.
By tensor products of operators
Such a product is also called a Kronecker product: we multiply the second matrix by each element of the first matrix and from the resulting blocks we compose a block matrix. If dimension A was equal
Example:
The third important property of quantum systems : two quantum systems can be in a state of superposition , while the new state space is the tensor product of the original spaces, and the state of the new system will be the tensor product of the states of the original systems. So, the superposition of systems in the states
And the vision
That's all the math that we need. Just in case, summarizing:
- For a fixed basis, the quantum system can be described by a complex vector, and the evolution of this system can be described by a unitary complex matrix;
- A quantum system can be measured in some basis and it will go into one of the basic states according to predetermined probabilities.
It turns out that in order to describe, study, understand and emulate quantum algorithms on a classical computer, you just need to multiply matrices by vectors - it is even simpler than neural networks : there are no nonlinearities here!

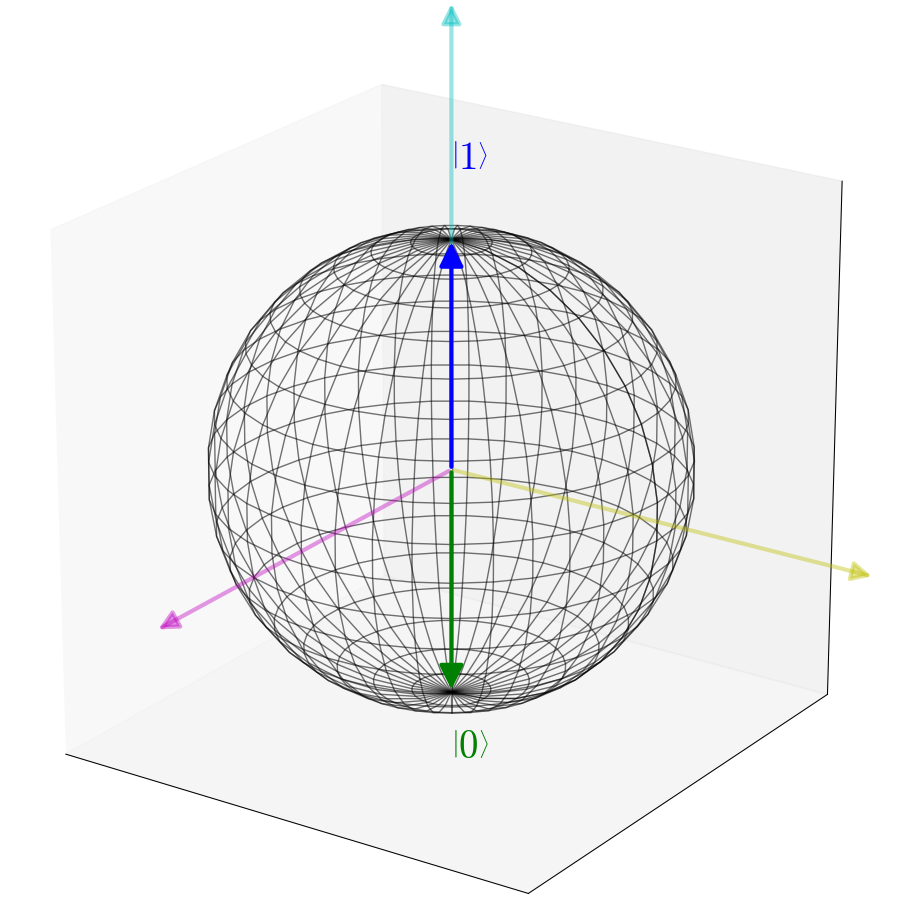
Qubit
Let's look at some quantum system described by a two-dimensional Hilbert space
and arbitrary vector
Where
Register
A single qubit, like a single bit, is too boring, so we immediately consider the superposition of several qubits. Such a superposition is called a quantum register ( quantum register , qregister ) of
Accordingly, any state of such a register
Where
Further similar. Quantum register of
import numpy as np class QRegister: def __init__(self, n_qbits, init): self._n = n_qbits assert len(init) == self._n self._data = np.zeros((2 ** self._n), dtype=np.complex64) self._data[int('0b' + init, 2)] = 1 3 lines of code to create a quantum register is not at all difficult, agree. You can use this way:
a = QRegister(1, '0') # |0> b = QRegister(1, '1') # |1> c = QRegister(3, '010') # |010> The quantum algorithm includes:
- Initialization of the quantum register;
- A set of unitary transformations over it;
- Measurement result.
Measurement
We figured out the first item and learned how to emulate it, now let's learn how to emulate the last one: measurement. As you remember, the squares of the state vector coefficients physically mean the probabilities of transition to this state. In accordance with this, we are implementing a new method in the QRegister class:
def measure(self): probs = np.real(self._data) ** 2 + np.imag(self._data) ** 2 states = np.arange(2 ** self._n) mstate = np.random.choice(states, size=1, p=probs)[0] return f'{mstate:>0{self._n}b}' We generate probabilities of
probs choosing one of states and randomly select it using np.random.choice . It remains only to return the binary string with the corresponding number of padding zeros. It is obvious that for basic states the answer will always be the same and equal to this state itself. Check: >>> QRegister(1, '0').measure() '0' >>> QRegister(2, '10').measure() '10' >>> QRegister(8, '01001101').measure() '01001101' Almost everything is ready to solve our problem! It remains only to learn how to influence the quantum registers. We already know that this can be done by unitary transformations.In quantum informatics, the unitary transformation is called a gate ( quantum gate , qgate , gate ).
Gates
In this article, we consider only a small number of the most basic gates, which will be useful to us. In fact, they are much more.
Unit
A single gate is the easiest one to look at. Its matrix is as follows:
It does not change the qubit on which it acts:
However, you should not consider it useless - we will need it more than once.
Gate Hadamard
It is easy to verify that the matrix is unitary:
Consider the effect of Hadamard gate on basic qubits:
Or in general terms [1]:
As you can see, Hadamard's gate translates any baseline state into equally probable - when measuring with equal probability, you can get any result.
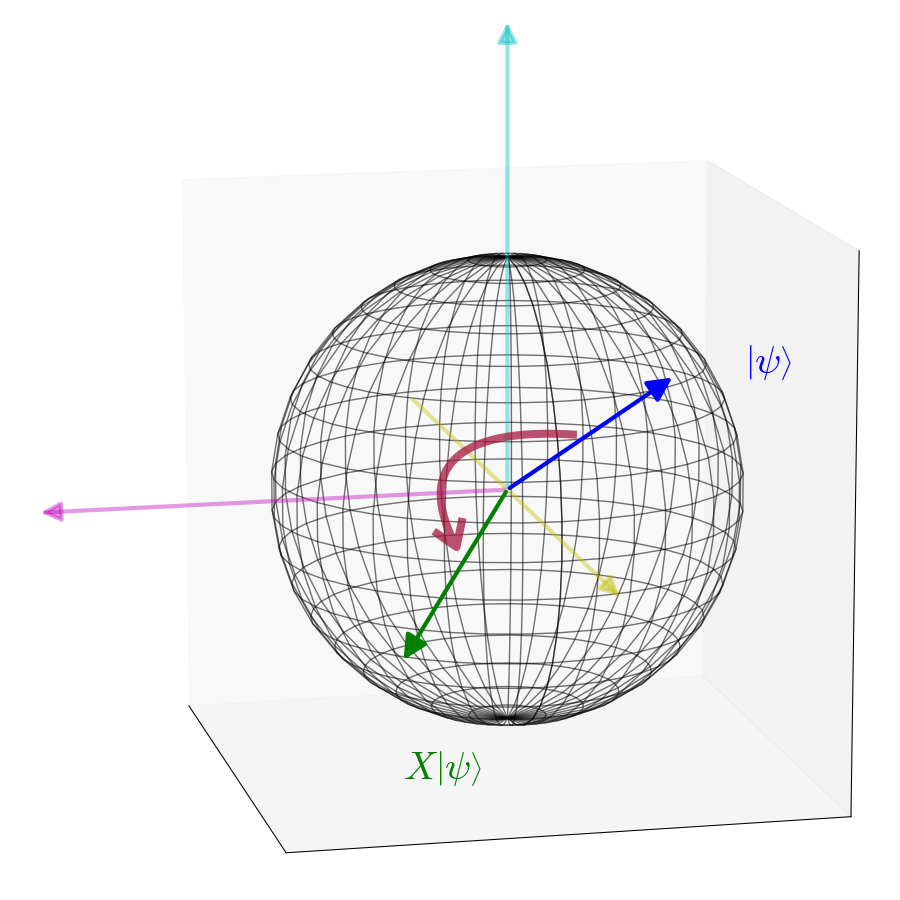
Gates of Pauli
Three extremely important gates to which the matrices introduced by Wolfgang Pauli correspond:
Gate is
and its geometrical use is equivalent to a rotation on the Bloch sphere by
Gates
There is a theorem according to which with the help of gates
where you can see that Hadamard gate geometrically means rotation on
We implement all the considered gates in Python. To do this, create another class:
class QGate: def __init__(self, matrix): self._data = np.array(matrix, dtype=np.complex64) assert len(self._data.shape) == 2 assert self._data.shape[0] == self._data.shape[1] self._n = np.log2(self._data.shape[0]) assert self._n.is_integer() self._n = int(self._n) And in the class
QRegisterwe add the operation of applying the gate: def apply(self, gate): assert isinstance(gate, QGate) assert self._n == gate._n self._data = gate._data @ self._data And create already known to us gates:
I = QGate([[1, 0], [0, 1]]) H = QGate(np.array([[1, 1], [1, -1]]) / np.sqrt(2)) X = QGate([[0, 1], [1, 0]]) Y = QGate([[0, -1j], [1j, 0]]) Z = QGate([[1, 0], [0, -1]]) Heads or tails?

Let us consider, for example, the simplest quantum algorithm: it will generate a random bit - zero or one, eagle or tails. It will be the most honest coin in the universe - the result will be known only when measuring, and the nature of randomness is sewn into the very foundation of the universe and cannot be influenced by it in any way.
For the algorithm we need only one qubit. Let it be in the initial moment of time
Now apply the Hadamard gate to it
If we now measure the resulting system, with probability
Let's check the algorithm by emulating it on our classic computer:
from quantum import QRegister, H def quantum_randbit(): a = QRegister(1, '0') a.apply(H) return a.measure() for i in range(32): print(quantum_randbit(), end='') print() Results:
➜ python example-randbit.py 11110011101010111010011100000111 ➜ python example-randbit.py 01110000111100011000101010100011 ➜ python example-randbit.py 11111110011000001101010000100000 All the above algorithm can be written with a pair of formulas:
However, it is not very convenient to work with such a record: the structure of the list is a sequence of actions that is well suited for classical algorithms, is not applicable in the quantum case: here we have neither cycles nor conditions, only state flow forward (and sometimes back) in time . Therefore, quantum schemes are widely used to describe algorithms in quantum computer science. Here is a diagram of the above algorithm:
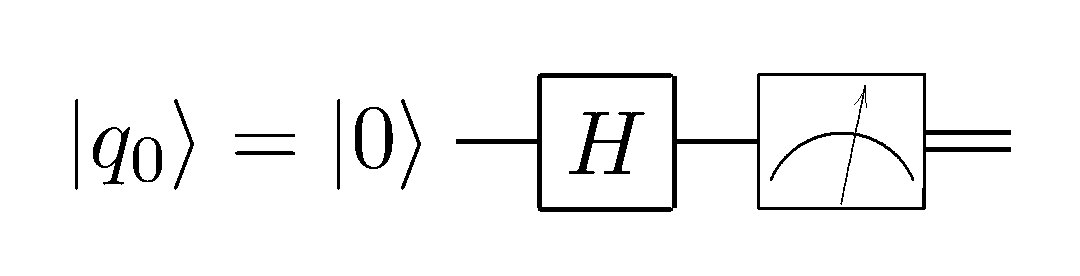
On the left is always indicated the initial state of the system. Unitary transformations performed on this state are indicated in the rectangles, and at the end a measuring instrument icon is placed on all or on several qubits - a measurement operation. There is also a “syntactic sugar” for some multi-qubit transformations in the form of points, ramifications, and circles. And that's all. If you can distinguish a square from a triangle and a circle, you will easily understand any scheme of the quantum algorithm.

More qubits to qubit god
And what if we work not with one qubit, but with their whole register? And, let's say, we want to apply the gate only to one qubit? The properties of the tensor product come to the rescue. By definition, the tensor product of an operator
Where
that is, it doesn't matter if you apply the gate to one qubit, and then connect it with the second one and get a quantum register, or apply the operator to the whole register
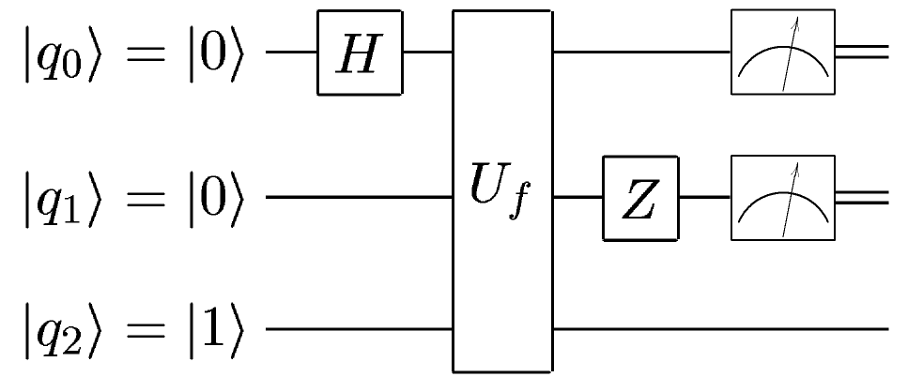
Completely similar to this:
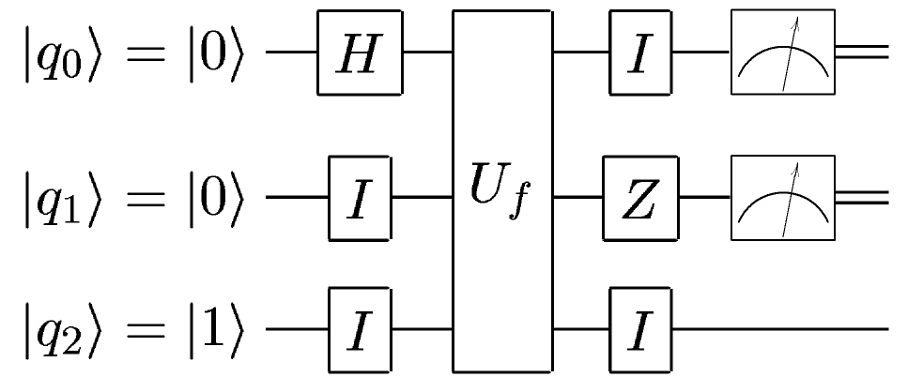
Only single gates are omitted for convenience.
And if we, on the contrary, want to apply the gate to several qubits at once? Again, from the definition of a tensor product, for this we can apply this gate to them, the tensor multiplied by itself the necessary number of times:
means:
Add a tensor product and exponentiation to ours
QGate: def __matmul__(self, other): return QGate(np.kron(self._data, other._data)) def __pow__(self, n, modulo=None): x = self._data.copy() for _ in range(n - 1): x = np.kron(x, self._data) return QGate(x) Quantum oracle
Each binary function
Why is its dimension
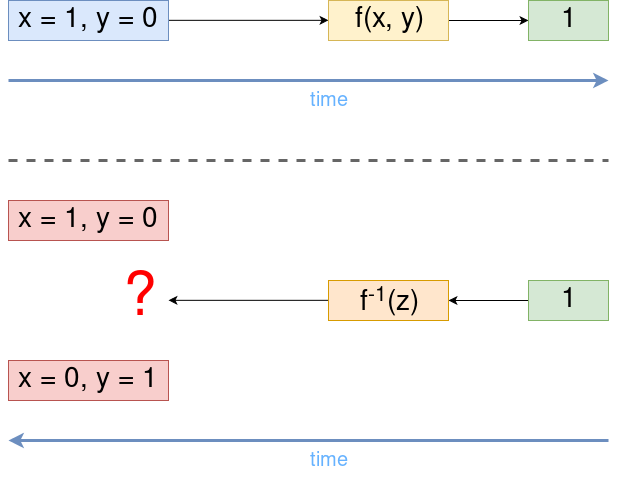
One way to avoid this is to memorize the arguments with which the function was invoked.

The same thing happens in the quantum model of computation, only there it is embedded in their very nature - without saving the complete information, it is impossible to build a unitary transformation.
A quantum oracle is
Let's look at an example. Suppose we want to build an oracle for a function of one argument
,
:
. :
def U(f, n): m = n + 1 U = np.zeros((2**m, 2**m), dtype=np.complex64) def bin2int(xs): r = 0 for i, x in enumerate(reversed(xs)): r += x * 2 ** i return r for xs in product({0, 1}, repeat=m): x = xs[:~0] y = xs[~0] z = y ^ f(*x) instate = bin2int(xs) outstate = bin2int(list(x) + [z]) U[instate, outstate] = 1 return QGate(U) Still remains
, , . , , , — . 1985 , 1992 . :
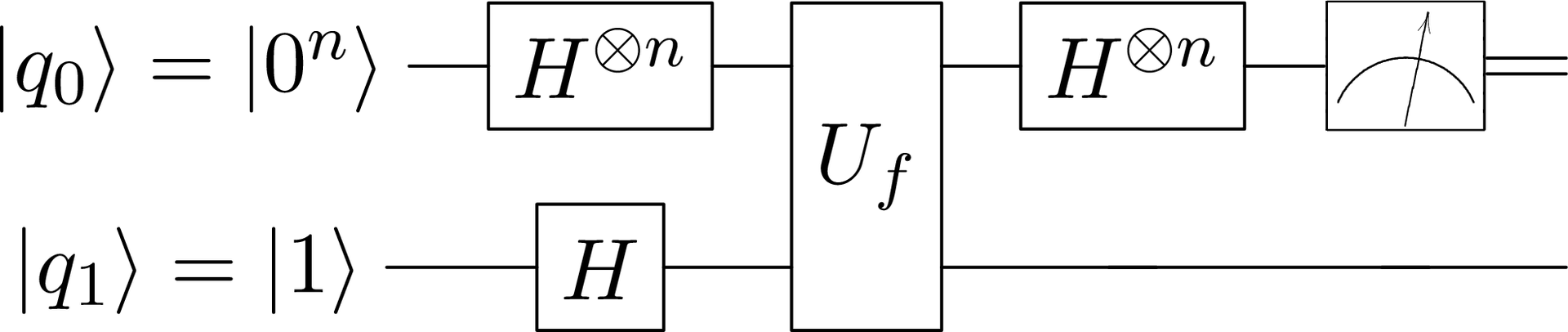
0, , — . :
from quantum import QRegister, H, I, U def is_constant(f, n): q = QRegister(n + 1, '0' * n + '1') q.apply(H ** (n + 1)) q.apply(U(f, n)) q.apply(H ** n @ I) if q.measure()[:~0] == '0' * n: return True else: return False :
def f1(x): return x def f2(x): return 1 def f3(x, y): return x ^ y def f4(x, y, z): return 0 print('f(x) = x is {}'.format('constant' if is_constant(f1, 1) else 'balansed')) print('f(x) = 1 is {}'.format('constant' if is_constant(f2, 1) else 'balansed')) print('f(x, y) = x ^ y is {}'.format('constant' if is_constant(f3, 2) else 'balansed')) print('f(x, y, z) = 0 is {}'.format('constant' if is_constant(f4, 3) else 'balansed')) Result:
f(x) = x is balansed f(x) = 1 is constant f(x, y) = x ^ y is balansed f(x, y, z) = 0 is constant Works. Wonderful. ? .
(by the property of a tensor product)
(applicable to every single qubit)
(we take out -1 for the sign of the tensor product)
(redefine for compactness)
Where
At the initial moment of time the system is in a state
Oracle will
Note that if at some fixed argument the
That's all. , - «» — -. , , :

→ GitHub
Thanks for reading! , , , . .
Literature
- [1] . , « :
» - [2] . . , « »
- [3] MA Nielsen , «Quantum Information Theory»
PS : — . Roman Parpalak upmath.me , .
Source: https://habr.com/ru/post/321292/
All Articles