The history of the development of TWIME - the new high-speed interface of the Moscow Exchange
In this hub, we will tell you about our unique experience in developing a high-speed TWIME interface for the Moscow Exchange, explain why low latency (response time) is so important to us and how to shorten it. We hope that in conclusion you will understand a little more clearly why the Moscow Exchange is more technological in some areas than, for example, such high-load giants as Nginx, VK or MailRu.
To explain what a high-speed TWIME interface is, you have to start from afar. What is traded on the stock exchange is called a trading instrument - it has a price and can be bought or sold. A trading instrument can be, for example, a barrel of oil, a Sberbank share, or a pair of currencies. Derivatives market is a segment of the Moscow Stock Exchange, in which they trade derivatives (derivatives) - futures and options.
The main function of the exchange is to take orders for the purchase / sale of trading instruments, to reduce orders to a transaction under strict rules and to issue information about the transactions made.
Accordingly, exchanges have several types of interfaces. Trading interfaces allow you to make transactions and receive operational information about the transactions. It is the exchange trading interfaces that are most critical to the response time. The TWIME protocol implementing gateway is a new, fastest, trading interface to the derivatives market.
Before answering the question of how we managed to speed up access to the stock exchange, we will explain why this was necessary.
')
Once upon a time applications of the exchange were taken by phone. Bidding occurred in manual mode. Latency from issuing to the notice of applications in the transaction was calculated in seconds, or even minutes.
At present, the Exchange accepts applications via the optical channels of communication of the best Russian data centers, and the reduction occurs on the best hardware. Accordingly, the bidding time is now tens of microseconds. Agree, the trend to reduce the time for issuing an application is obvious.
First of all, this need is caused by the competition of exchanges. Customers want to submit an order as quickly as possible in order to get ahead of other customers, and, moreover, get ahead of the rhinestone on all exchanges. This approach allows you to make deals at the best price when the price moves. At the same time, by and large, no matter how long the application is reduced within the system. The main thing is to take a queue before competitors.
It is no secret that the exchange receives income from each transaction that is in the book of active orders. Tariffs, of course, vary and differ in different markets, exchanges, but they are all similar in that the more bandwidth, the more operations are made and money is earned.
Over time, the response is more complicated. The exchange needs a smooth, without bursts, response time. Because otherwise the principle of "Fair Play" is violated. If one user had an application for X μs, and another for 10 μs, and the delay occurred on the exchange side, then there is a threat of lost profit, which greatly distresses the trader. It is impossible to make the response time strictly the same for all, to reduce the latency variance to 0, but you should always strive for such an indicator.
Is the median response time important for the exchange? For clients, the median is only important if it is not different from the median of other clients. Otherwise, it is not significant. One of the latest trends in stock photography is when the exchange slows down itself. Such a trend began with Michael Lewis's well-known book “Flash Boys” and continued in the summer of 2016, when the SEC (Securities and Exchange Commission) decided to make one of such slow exchanges public.
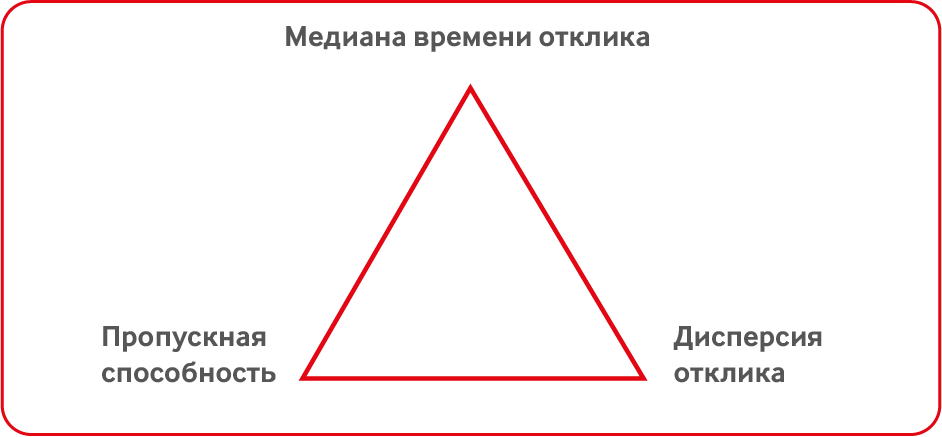
Is the median response time important for the exchange? This question remains open. As a rule, you have to find a compromise between bandwidth, median and latency variance. For example, disabling the Nagle algorithm reduces the median, but also reduces throughput. There are many such examples.
What trading interfaces does the derivatives market have? We wrote about this in our blog earlier, so we will only repeat in general terms.
Previously, the fastest interface was CGate API - a set of libraries with a single API. CGate communicates with the exchange through a closed internal exchange protocol. Although this interface is the fastest, but since its protocol is closed and linking to the library is required, there are natural limitations on the supported languages and platforms, and there is no possibility to use FPGA, which many of our customers would like.
Another trading interface is FIX. It is quite convenient for customers, since the FIX protocol is an old, time-tested standard for bidding. Under it created a huge number of libraries and FPGA-solutions. Unfortunately, on the derivatives market, this interface is somewhat slower than CGate.
And most customers naturally preferred CGate. Now we have developed a new interface, it is faster than CGate, does not require linking, is suitable for FPGA, while the most advanced industry standards are used in its development - and its name is TWIME (Trading Wire Interface for Moscow Exchange).
We conducted a painstaking analysis of available stock exchange interfaces. Work continued throughout the summer of 2015. By the fall, we had a finished prototype that showed latency at 10 µs towards the core. It was an order of magnitude faster than the fastest interface at that time. By December, we launched a public test, and in April, began full operation.
In developing the fastest interface, we focused on three aspects:
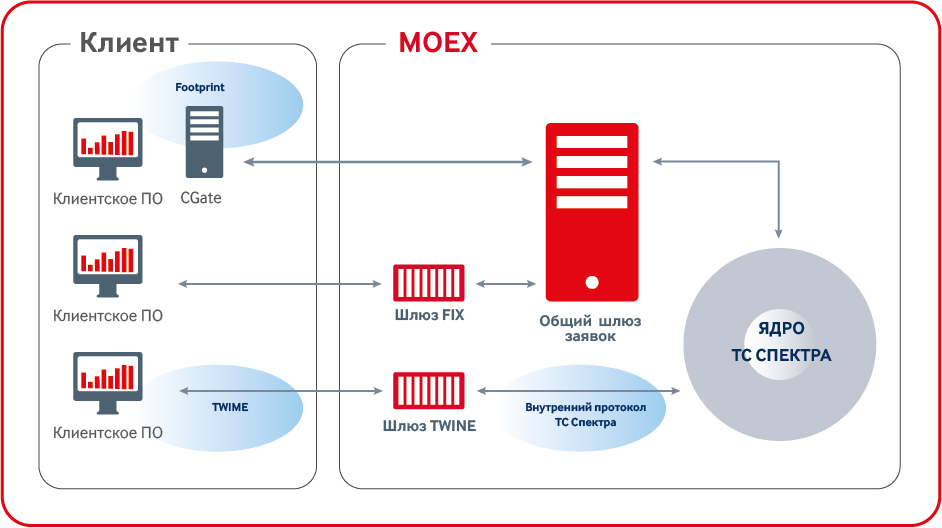
We cut corners in architecture. The largest angle is the common gateway of requests, through which all messages to the core, including insensitive to the response time, the so-called non-trading orders, passed earlier. This gateway performs the functions of monitoring, authentication and flood control. As a result, we implemented the necessary functionality within our TWIME gateway, and threw out the extra. Thus, it was possible to avoid unnecessary hop in the network, since usually the common gateway and the core were located on different boxes.
We prohibit connecting to the exchange through the TWIME gateway (send TCP SYN) more than once a second from one address. This reduced the damage from incorrectly written client applications and the attempts of malicious damage.
In the new gateway, we use bidding by a numeric identifier, which makes it a little difficult for our customers to get the correct tool identifier, but it allows us to reduce our messages.
In developing the new trading protocol, we used the recommendations of the Fix Community, a community of organizations interested in unifying access to various trading platforms.
We took FIXP as the basis for our session level, we use SBE at the presentation level, and on the one hand, for the efficiency, it is as close as possible to the internal message format of the trading system core, and on the other hand, it uses the FIX semantics. The result was a very simple protocol for implementing clients. We received positive feedback from manufacturers of FPGA-based trading solutions.
There are a lot of exchanges, there are hundreds of them, and it turns out to the bidders that it is expensive to support the zoo from the protocols. The simplicity and uniformity of our protocol allows us to hope that TWIME clients will be able to use more advanced hardware and waste developers' time on optimization, rather than on the implementation of non-standard protocols.
Has anyone used google protobuf? On some tests, SBE shows acceleration tenfold compared to GPB. SBE is like C language structures that are sent to the network “as is” by passing a pointer to the structure and sizeof structure to the send system call. Accordingly, serialization and deserialization is simply a C-style cast at compile time. In fact, everything is a little more complicated, but I think that the advantages and disadvantages of this approach are clear.
Each message in TWIME has a fixed size. The first field in each message is the size of the message without a header, and the second is the identifier of the message type — the structure. By the type of message, you can definitely get the length, but it would be an extra switch, which is long. Two more fields in the header are the schema identifier and the schema version. This is all the standard SBE header. Next come the business logic fields: price, tool, client account.
The protocol is more efficient than FIX, because we use binary coding. For example, in FIX, the time to within milliseconds is 19 bytes, in TWIME the time to within nanoseconds is 8 bytes. This is the number of nanoseconds from the unix era.
It is also more efficient than the internal exchange protocol (Plaza2), the size of messages is 4 times less on average due to the absence of internal core fields.
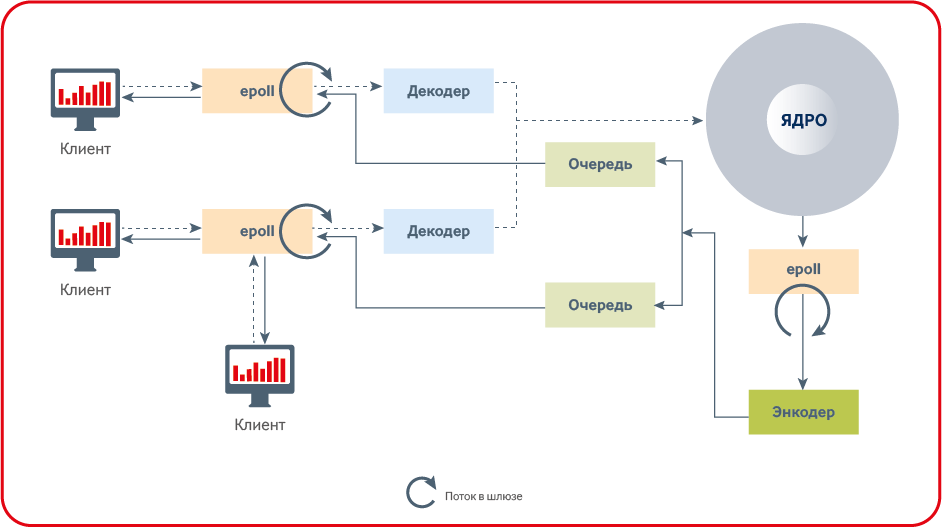
The main secret of low latency is the absence of locks on the critical path.
Mutexes cannot be used in low-latency applications on a critical path, since the time of one slice of time (the minimum time allocated by the OS to programs) of the OS scheduler is usually longer than the processing time of the application. Memory allocation cannot be performed on a critical path as it uses a mutex.
The number of context switches must be minimized using affinity and realtime scheduling. Ideally, it is better not to have a context-switch for worker threads at all.
This may seem banal to some, but the lack of mutexes and memory allocations on the critical path, as well as minimizing context switches, is a necessary condition for the success of a low-latency application.

One of the optimizations we have done relates to working with heartbeat. A significant part of our clients constantly send and receive messages throughout the day, in which case it is immediately obvious that the client is active and no heartbeat is needed. We require that the client send heartbeat only in the absence of other messages.
Breaking a session over a missed heartbeat is very important for the clients of the exchange. Since there is an opportunity to ask the exchange in advance to cancel all applications in case of a disconnection.
Therefore, the algorithm that is used in other interfaces requires re-registration of the event by a timer on each message. Which in turn means having to pull out the timer event from the reactor heap and add a new event to the heap (and this is for every new message from the client!).
In the new gateway, we chose a different path. When a new user is connected, we register a timer event at the reactor. For each message from the client is flagged that there was a message. When a timer event triggers, we check the flag and drop it. If the flag was not raised, the client disconnects with an error that heartbeat is missing.
This approach does not allow you to accurately trigger an event exactly at a certain interval after the last message. Therefore, the new gateway disables clients during the interval from one to two intervals after the last message received. This is the compromise we decided to make to speed up the work of the gateway.
Each message that the client sends to the exchange, in fact, is an official document that must be saved and processed. At what point is the message considered to be on the exchange? A message is considered technically to come to the exchange if it has been confirmed by TCP ACK.
It turns out that in the case of excessive load on the stock exchange there are several ways that you can do with messages. They cannot be ignored, they cannot be rejected without a good reason either, they can be accumulated in memory, for example, put in a queue in RAM. So the general gateway of applications behaved. Not the most effective way to work with messages, may require a lot of memory and unnecessary copying messages.
In the new gateway, we chose a different path; we read from socket buffers only those messages that we can process. If the gateway is heavily loaded, the TCP buffer will be blocked on the server side and TCP ACK messages will stop coming to clients. Thus, the client will get an EAGAIN error with clogged buffers and asynchronous sockets and will be able to decide for itself whether it is worthwhile in the situation of excessive load on the stock exchange to continue trading as before or change the strategy.

One of the most interesting algorithms in our gateway is the priority packet size algorithm.
Suppose one of the clients, using super-fast iron and a brilliant code, learned to send messages to the stock exchange faster than the stock manages to process them: does this mean that in this situation the stock exchange will be forced to serve only one client? Definitely not, because it would be unfair to less fast bidders.
Solving the problem that was used before assumed tracking the number of messages from each client and the distribution of gateway time between clients. In the new gate, we found a simpler solution. At each iteration of polling sockets, we read no more than a predetermined N-th number of bytes. Thus, if one of the clients sent 100 messages in one TCP segment, the second sent 15 messages, the third 5 messages, and the priority packet size is 10 messages, then on the first iteration only the messages from the third client will be fully processed. Messages from the first client will take 10 iterations of the reactor poling, and the second two iterations.
Another optimization we have done in the new gateway is the use of a static scheme instead of the dynamic one as it was before.
A schema is a set of messages and fields in them. In the case when the message fields are not known at compile time, this is a dynamic scheme, and if the fields are known at the compilation stage, then we get the static scheme. Both approaches have their positive and negative sides. In the first case, the same code can work with different schemes; in the second, changing the schema requires recompiling the code. The static scheme allows the compiler to make many additional optimizations, for example, when writing messages to the log. The code for writing messages from the static scheme to the log is most likely to be inline with the compiler, due to the fact that the number and types of fields are known at the compilation stage.
The material was prepared by Nikolai Viskov - an engineer at the Moscow Exchange.
To explain what a high-speed TWIME interface is, you have to start from afar. What is traded on the stock exchange is called a trading instrument - it has a price and can be bought or sold. A trading instrument can be, for example, a barrel of oil, a Sberbank share, or a pair of currencies. Derivatives market is a segment of the Moscow Stock Exchange, in which they trade derivatives (derivatives) - futures and options.
The main function of the exchange is to take orders for the purchase / sale of trading instruments, to reduce orders to a transaction under strict rules and to issue information about the transactions made.
Accordingly, exchanges have several types of interfaces. Trading interfaces allow you to make transactions and receive operational information about the transactions. It is the exchange trading interfaces that are most critical to the response time. The TWIME protocol implementing gateway is a new, fastest, trading interface to the derivatives market.
Before answering the question of how we managed to speed up access to the stock exchange, we will explain why this was necessary.
')
Once upon a time applications of the exchange were taken by phone. Bidding occurred in manual mode. Latency from issuing to the notice of applications in the transaction was calculated in seconds, or even minutes.
At present, the Exchange accepts applications via the optical channels of communication of the best Russian data centers, and the reduction occurs on the best hardware. Accordingly, the bidding time is now tens of microseconds. Agree, the trend to reduce the time for issuing an application is obvious.
First of all, this need is caused by the competition of exchanges. Customers want to submit an order as quickly as possible in order to get ahead of other customers, and, moreover, get ahead of the rhinestone on all exchanges. This approach allows you to make deals at the best price when the price moves. At the same time, by and large, no matter how long the application is reduced within the system. The main thing is to take a queue before competitors.
Why does the exchange need low latency?
It is no secret that the exchange receives income from each transaction that is in the book of active orders. Tariffs, of course, vary and differ in different markets, exchanges, but they are all similar in that the more bandwidth, the more operations are made and money is earned.
Over time, the response is more complicated. The exchange needs a smooth, without bursts, response time. Because otherwise the principle of "Fair Play" is violated. If one user had an application for X μs, and another for 10 μs, and the delay occurred on the exchange side, then there is a threat of lost profit, which greatly distresses the trader. It is impossible to make the response time strictly the same for all, to reduce the latency variance to 0, but you should always strive for such an indicator.
Is the median response time important for the exchange? For clients, the median is only important if it is not different from the median of other clients. Otherwise, it is not significant. One of the latest trends in stock photography is when the exchange slows down itself. Such a trend began with Michael Lewis's well-known book “Flash Boys” and continued in the summer of 2016, when the SEC (Securities and Exchange Commission) decided to make one of such slow exchanges public.
Is the median response time important for the exchange? This question remains open. As a rule, you have to find a compromise between bandwidth, median and latency variance. For example, disabling the Nagle algorithm reduces the median, but also reduces throughput. There are many such examples.
What trading interfaces does the derivatives market have? We wrote about this in our blog earlier, so we will only repeat in general terms.
Previously, the fastest interface was CGate API - a set of libraries with a single API. CGate communicates with the exchange through a closed internal exchange protocol. Although this interface is the fastest, but since its protocol is closed and linking to the library is required, there are natural limitations on the supported languages and platforms, and there is no possibility to use FPGA, which many of our customers would like.
Another trading interface is FIX. It is quite convenient for customers, since the FIX protocol is an old, time-tested standard for bidding. Under it created a huge number of libraries and FPGA-solutions. Unfortunately, on the derivatives market, this interface is somewhat slower than CGate.
And most customers naturally preferred CGate. Now we have developed a new interface, it is faster than CGate, does not require linking, is suitable for FPGA, while the most advanced industry standards are used in its development - and its name is TWIME (Trading Wire Interface for Moscow Exchange).
How did we manage to reduce the response time?
We conducted a painstaking analysis of available stock exchange interfaces. Work continued throughout the summer of 2015. By the fall, we had a finished prototype that showed latency at 10 µs towards the core. It was an order of magnitude faster than the fastest interface at that time. By December, we launched a public test, and in April, began full operation.
In developing the fastest interface, we focused on three aspects:
- System architecture, conceptual changes in interfaces.
- The new protocol, which took the best from its predecessors.
- Algorithms - private improvements in the implementation of the gateway logic.
We cut corners in architecture. The largest angle is the common gateway of requests, through which all messages to the core, including insensitive to the response time, the so-called non-trading orders, passed earlier. This gateway performs the functions of monitoring, authentication and flood control. As a result, we implemented the necessary functionality within our TWIME gateway, and threw out the extra. Thus, it was possible to avoid unnecessary hop in the network, since usually the common gateway and the core were located on different boxes.
We prohibit connecting to the exchange through the TWIME gateway (send TCP SYN) more than once a second from one address. This reduced the damage from incorrectly written client applications and the attempts of malicious damage.
In the new gateway, we use bidding by a numeric identifier, which makes it a little difficult for our customers to get the correct tool identifier, but it allows us to reduce our messages.
In developing the new trading protocol, we used the recommendations of the Fix Community, a community of organizations interested in unifying access to various trading platforms.
We took FIXP as the basis for our session level, we use SBE at the presentation level, and on the one hand, for the efficiency, it is as close as possible to the internal message format of the trading system core, and on the other hand, it uses the FIX semantics. The result was a very simple protocol for implementing clients. We received positive feedback from manufacturers of FPGA-based trading solutions.
There are a lot of exchanges, there are hundreds of them, and it turns out to the bidders that it is expensive to support the zoo from the protocols. The simplicity and uniformity of our protocol allows us to hope that TWIME clients will be able to use more advanced hardware and waste developers' time on optimization, rather than on the implementation of non-standard protocols.
Has anyone used google protobuf? On some tests, SBE shows acceleration tenfold compared to GPB. SBE is like C language structures that are sent to the network “as is” by passing a pointer to the structure and sizeof structure to the send system call. Accordingly, serialization and deserialization is simply a C-style cast at compile time. In fact, everything is a little more complicated, but I think that the advantages and disadvantages of this approach are clear.
Each message in TWIME has a fixed size. The first field in each message is the size of the message without a header, and the second is the identifier of the message type — the structure. By the type of message, you can definitely get the length, but it would be an extra switch, which is long. Two more fields in the header are the schema identifier and the schema version. This is all the standard SBE header. Next come the business logic fields: price, tool, client account.
The protocol is more efficient than FIX, because we use binary coding. For example, in FIX, the time to within milliseconds is 19 bytes, in TWIME the time to within nanoseconds is 8 bytes. This is the number of nanoseconds from the unix era.
It is also more efficient than the internal exchange protocol (Plaza2), the size of messages is 4 times less on average due to the absence of internal core fields.
The main secret of low latency is the absence of locks on the critical path.
Mutexes cannot be used in low-latency applications on a critical path, since the time of one slice of time (the minimum time allocated by the OS to programs) of the OS scheduler is usually longer than the processing time of the application. Memory allocation cannot be performed on a critical path as it uses a mutex.
The number of context switches must be minimized using affinity and realtime scheduling. Ideally, it is better not to have a context-switch for worker threads at all.
This may seem banal to some, but the lack of mutexes and memory allocations on the critical path, as well as minimizing context switches, is a necessary condition for the success of a low-latency application.
One of the optimizations we have done relates to working with heartbeat. A significant part of our clients constantly send and receive messages throughout the day, in which case it is immediately obvious that the client is active and no heartbeat is needed. We require that the client send heartbeat only in the absence of other messages.
Breaking a session over a missed heartbeat is very important for the clients of the exchange. Since there is an opportunity to ask the exchange in advance to cancel all applications in case of a disconnection.
Therefore, the algorithm that is used in other interfaces requires re-registration of the event by a timer on each message. Which in turn means having to pull out the timer event from the reactor heap and add a new event to the heap (and this is for every new message from the client!).
In the new gateway, we chose a different path. When a new user is connected, we register a timer event at the reactor. For each message from the client is flagged that there was a message. When a timer event triggers, we check the flag and drop it. If the flag was not raised, the client disconnects with an error that heartbeat is missing.
This approach does not allow you to accurately trigger an event exactly at a certain interval after the last message. Therefore, the new gateway disables clients during the interval from one to two intervals after the last message received. This is the compromise we decided to make to speed up the work of the gateway.
Each message that the client sends to the exchange, in fact, is an official document that must be saved and processed. At what point is the message considered to be on the exchange? A message is considered technically to come to the exchange if it has been confirmed by TCP ACK.
It turns out that in the case of excessive load on the stock exchange there are several ways that you can do with messages. They cannot be ignored, they cannot be rejected without a good reason either, they can be accumulated in memory, for example, put in a queue in RAM. So the general gateway of applications behaved. Not the most effective way to work with messages, may require a lot of memory and unnecessary copying messages.
In the new gateway, we chose a different path; we read from socket buffers only those messages that we can process. If the gateway is heavily loaded, the TCP buffer will be blocked on the server side and TCP ACK messages will stop coming to clients. Thus, the client will get an EAGAIN error with clogged buffers and asynchronous sockets and will be able to decide for itself whether it is worthwhile in the situation of excessive load on the stock exchange to continue trading as before or change the strategy.
One of the most interesting algorithms in our gateway is the priority packet size algorithm.
Suppose one of the clients, using super-fast iron and a brilliant code, learned to send messages to the stock exchange faster than the stock manages to process them: does this mean that in this situation the stock exchange will be forced to serve only one client? Definitely not, because it would be unfair to less fast bidders.
Solving the problem that was used before assumed tracking the number of messages from each client and the distribution of gateway time between clients. In the new gate, we found a simpler solution. At each iteration of polling sockets, we read no more than a predetermined N-th number of bytes. Thus, if one of the clients sent 100 messages in one TCP segment, the second sent 15 messages, the third 5 messages, and the priority packet size is 10 messages, then on the first iteration only the messages from the third client will be fully processed. Messages from the first client will take 10 iterations of the reactor poling, and the second two iterations.
Another optimization we have done in the new gateway is the use of a static scheme instead of the dynamic one as it was before.
A schema is a set of messages and fields in them. In the case when the message fields are not known at compile time, this is a dynamic scheme, and if the fields are known at the compilation stage, then we get the static scheme. Both approaches have their positive and negative sides. In the first case, the same code can work with different schemes; in the second, changing the schema requires recompiling the code. The static scheme allows the compiler to make many additional optimizations, for example, when writing messages to the log. The code for writing messages from the static scheme to the log is most likely to be inline with the compiler, due to the fact that the number and types of fields are known at the compilation stage.
The material was prepared by Nikolai Viskov - an engineer at the Moscow Exchange.
Source: https://habr.com/ru/post/321280/
All Articles