Features of the distributed storage architecture in Dropbox

The readers of “Habrakhabr” are presented with the decoding of the video (at the end of the publication) of the speech of Vyacheslav Bakhmutov on the stage of the HighLoad ++ conference, held in Skolkovo near Moscow on November 7-8 of the past year.
My name is Slava Bakhmutov, I work in Dropbox. I am a Site Reliability Engineer (SRE). I love Go and promote it. With the guys, we are recording the golangshow podcast.
')
What is Dropbox?
This is a cloud storage where users store their files. We have 500 million users, we have more than 200 thousand businesses, as well as a huge amount of data and traffic (more than 1.2 billion new files per day).
Conceptually, architecture is two large pieces. The first piece is the metadata server, it stores information about files, connections between files, information about users, some kind of business logic, and all this is connected to the database. The second big chunk is block storage in which user data is stored. Initially, in 2011, all data was stored in Amazon S3. In 2015, when we managed to transfer all the exabytes to ourselves, we told that we had written our cloud storage.
We called it Magic Pocket. It is written in Go, partly in Rust and quite a lot in Python. Architecture Magic Pocket, it is cross-zone, there are several zones. In America, these are three zones, they are combined in Pocket. There is a Pocket in Europe, it does not intersect with an American one, because Europeans do not want their data to be in America. Zones between themselves replicate data. There are cells inside the zone. There is a Master that controls these cells. There are replications between zones. Each cell has a Volume Manager, which monitors the servers that store this data, there are quite large servers.
On each of the servers, this is all combined into a bucket, the bucket is 1 GB. We operate with buckets when we transfer data somewhere, when we delete something, clean it, defragment it, because the data blocks we save from the user are 4 MB, and it is very difficult to operate with them. All Magic Pocket components are well described in our technical blog, I will not talk about them.
I will talk about architecture in terms of SRE. From this point of view, the availability and security of data is very important. What is it?
Accessibility is a complex concept and is calculated for different services differently, but usually it is the ratio of the number of requests made to the total number of requests, usually described by nines: 999, 9999, 99999. But in fact it is a certain function of the time between disasters or problems by the time for how much you fix it. It doesn't matter how you fix it, in production or just roll back the version.
What is safety?
How do we calculate preservation? You take some data and save it to your hard drive. Then you have to wait until they sync to disk. This is ridiculous, but many people use nosql solutions that simply skip this step.
How is safety calculated?
There is an AFR - this is the annual frequency of disk errors. There are various statistics on how errors occur, how often errors occur in various hard drives. You can view these statistics :
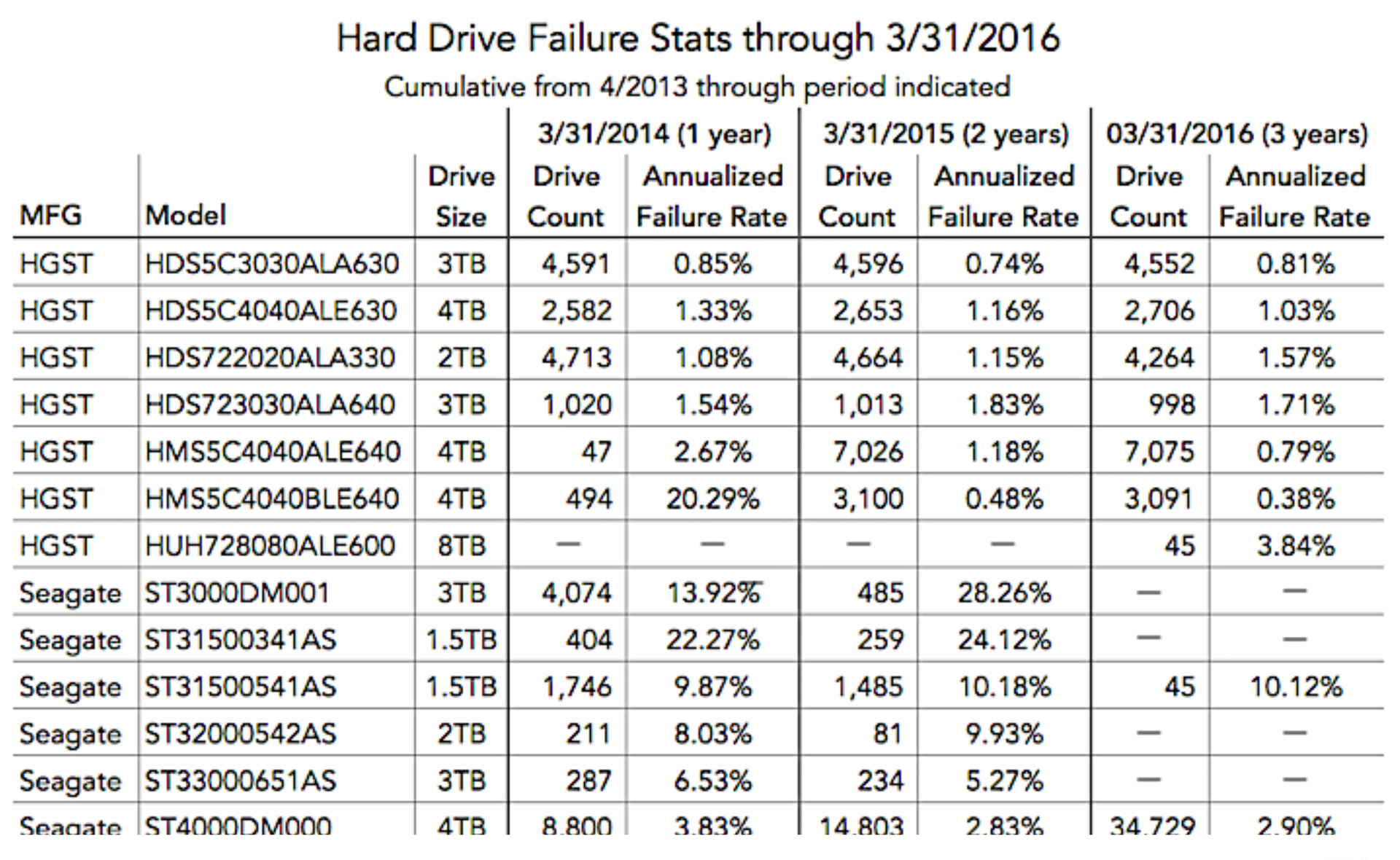
Then you can replicate your data to different hard drives to increase durability. You can use RAID, you can keep replicas on different servers or even in different data centers. And if you count Markov chains, as far as the probability of losing one byte, then you will get something about 27 nines. Even on the scale of Dropbox, where we have exabytes of data, we will not lose a single byte in the near future, almost never. But all this is ephemeral, any operator error, or a logical error in your code - and there is no data.
How do we actually improve the availability and security of data?
I divide it into 4 categories, this is:
- Insulation;
- Protection;
- Control;
- Automation.
Automation is very important.
Isolation is:
- Physical;
- Logical;
- Operational.
Physical isolation. On the scale of Dropbox or a company like Dropbox, it is very important for us to communicate with the data center, we need to know how our services are located inside the data center, how energy is supplied to them, and what network accessibility these services have. We do not want to keep database services in one rack, which we need to constantly back up. Suppose each backup is 400 Mbit / s, and we just do not have enough channel. The deeper you go to this stack, the more expensive your decision and the more difficult it becomes. How low to descend is your decision, but, of course, you should not put all the replicas of your databases in one rack. Because the energy goes out and you have no more databases.
You can look at all this in another dimension, from the point of view of the manufacturer of the equipment. It is very important to use different equipment manufacturers, different firmware, different drivers. Why? Although equipment manufacturers say their solutions are reliable, in fact they lie and this is not true. Well at least do not explode.
Proceeding from all this, it is important to put critical data not only at home somewhere in your infrastructure, but also in the external infrastructure. For example, if you are at the Google cloud, then you put important data in Amazon, and vice versa. Because if your infrastructure goes out, then there will be no backup.
Logical isolation Almost everyone knows about her. Main problems: if one service starts to create some problems, other services also begin to experience problems. If the bug was in the code of one service, then this bug begins to spread to other services. You are starting to receive incorrect data. How to handle it?
Weakly connected! But it very rarely works. There are some systems that are not loosely connected. These are databases, ZooKeeper. If you have a large load went to ZooKeeper, you have a quorum cluster dropped, then it all fell. With databases, about the same. If a large load on the master, then most likely the entire cluster will fall.
What have we done in Dropbox?

This is the high-level diagram of our architecture. We have two zones, and between them we have made a very simple interface. It is practically put and get, it is for storage. It was very difficult for us because we wanted to make everything more difficult. But this is very important, because inside the zones everything is very difficult, there are both ZooKeeper and quorums databases. And all this periodically falls, all straight at once. And so that it does not capture the other zones, there is this simple interface between them. When one zone falls, the second will most likely work.
Operational insulation. No matter how well you spread your code across different servers, no matter how well it is logically isolated, there is always a person who does something wrong. For example, in Odnoklassniki there was a problem: a person rolled out to all Bash shell servers, in which something was not working, and all servers were disconnected. Such problems also occur.
Another joke is that if all programmers and system administrators had gone somewhere to rest, the system would have worked much more stable than when they work. And indeed it is. During friezes, many companies have such a practice of freezing before the New Year holidays, the system works much more stable.
Access control. Release process: you actively test all this, then test for staging, which is used, for example, by your company. Then we lay out the changes in one zone. As soon as we made sure that everything is normal, we decompose into the other two zones. If something is not normal, then we replicate data from them. This is all about storage. We constantly update our food services, once a day.
Protection. How do we need to protect our data?
This is validation of operations. This is the ability to recover this data. This is testing. What is validation operations?
The biggest risk for the system is the operator.
There is a story. Margaret Hamilton, who worked on the Apollo program, at some point during the test, a daughter came to her and turned a lever, and the whole system welled up. This lever cleared the Apollo’s navigation system. Hamilton appealed to NASA and said that there was such a problem, offered to make a defense. If the ship flies, it will not clear the data in this ship. But NASA said the astronauts are professionals, and they will never turn this lever. In the next flight, one of the astronauts inadvertently turned this lever, and everything was cleared. They had a clear description of the problem, and they were able to restore this navigation data.
We had a similar example , we have a tool called JSSH, it’s such a distributed shell that allows you to execute commands on multiple servers.

In fact, we in this team need to run memcache servers that are in the reinstall state, that is, they no longer work, and we need to update them. We need to run the upgrade.sh script. Usually this is all done automatically, but sometimes you need to manually do it.
There is a problem, it was necessary to make all quotes:

Since this was all without quotes, then we have a lifecycle = reinstall argument for all memcachs and they all rebooted. This is not a very good impact on the service. The operator is not guilty, anything can happen.
What have we done?
We changed the command syntax (gsh) to avoid such problems. We have forbidden to perform destructive operations on live services (DB, memcache, storage). That is, we cannot in any way reload the database without stopping it and removing it from production, as well as with memcache. We are trying to automate all such operations.

We added two slashes to this operation at the end and after that we specify our script, such a small fix allowed us to avoid such problems in the future.
The second example. This is SQLAlchemy. This is a Python library for working with databases. And in it for update, insert, delete there is such an argument, which is called whereclause. In it you can specify what you want to delete, what you want to update. But if you pass there not where clause, but where, then sqlalchemy will not say anything, it will simply delete everything without where, this is a very big problem. We have several services, for example, ProxySQL. This is a proxy for MySQL, which allows you to disable many destructive operations (DROP TABLE, ALTER, updates without where, etc.). Also in this ProxySQL, you can do throttling and for those requests that we do not know, limit their number so that a smart request does not put the master to us by chance.
Recovery. It is very important not only to create backups, but also to check that these backups will be restored. Facebook recently posted an article where they tell how they are constantly making backups and constantly recovering from these backups. We have essentially the same thing.
Here is an example from our Orchestrator, for some short period of time:

It can be seen that we constantly make clones of databases, because we have up to 32 databases on one server, we move them all the time. Therefore, we are constantly cloning. Constantly promotion goes to the master and to the slave, etc. Also a huge number of backups. We are backing up to ourselves, also in Amazon S3. But we are also constantly recovering. If we do not verify that every database we backed up can recover, then in fact we do not have this backup.
Testing
Everyone knows that both unit testing and integration testing are useful. From the point of view of accessibility, testing is MTTR, time for recovery, it is essentially equal to 0. Because you found this bug not in production, but before production and fixed it. Availability did not bend. This is also very important.
Control
Someone will always screw up: either programmers or operators will do something wrong. It's not a problem. You need to be able to find and fix it all.
We have a huge number of verifiers for storage.
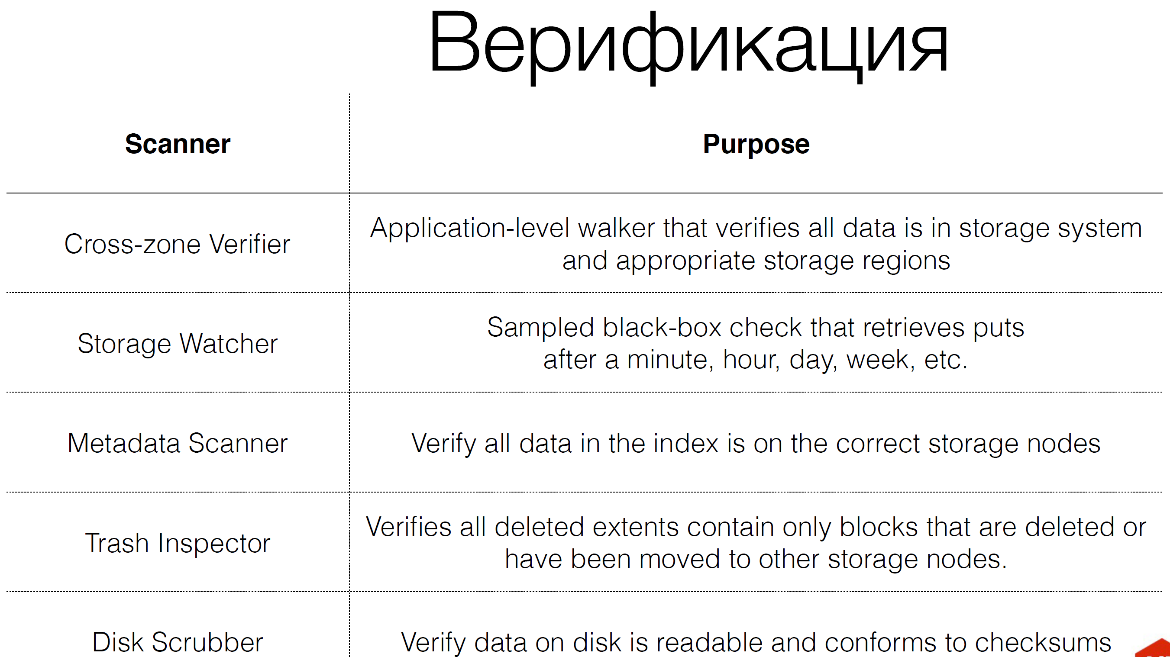
They are actually 8, not 5, as here. We have verification codes more than the storage codes themselves. We have 25% of internal traffic - this is verification. At the lowest level, disk scrubberes work, which simply read blocks from the hard disk and check checksums. Why do we do this? Because hard drives are lying, SMART is lying. It is not profitable for manufacturers to have SMART find errors because they have to return these hard drives. Therefore, it must always be checked. And as soon as we see the problem, we try to recover this data.
We have a trash inspector. When we delete something, or we move it, or we do something destructive with the data, we first put this data in a basket and then check this data if we really wanted to remove it. They are stored there for two weeks, for example. We have capacity for this two-week time of deleted data, this is very important, so we spend money on it. We are also constantly part of the traffic that comes in storage, save these operations in Kafka. Then we repeat these operations on storage. We turn to storage as a blackbox, to see if there really is traffic data that came to us, and those that signed up, we can pick them up.
We constantly check that the data is replicated from one storage to another, that is, they correspond to each other. If the data is in one storage, they must be in another storage.
Verifiers are very important if you want to achieve high and high-quality durability.
It is also very important to know that verifiers that you have not tested, they essentially do not verify anything. You cannot say that they really do what you want.
Therefore, it is very important to conduct Disaster Recovery Testing (DRT). What it is? This is when you, for example, completely disable some kind of internal service on which other services depend, and see if you were able to determine that something is not working for you, or if you think that everything is fine. Could you respond to it quickly, fix it, restore it all. This is very important because we catch problems in production. Production differs from staging in that there is a completely different traffic. You just have a different infrastructure. For example, you may have the same number of services in a staging on the same rack, and they are different, for example, a web service, database, storage. And in production it may be completely different.
We had such a problem due to the fact that we had a database with web services, we could not save it in time. For this, too, need to follow.
It is very important to prove our judgments. That is, if something fell, and we know how to restore it, we wrote this script, we have to prove that if something falls, then it will really happen. Because the code is changing, the infrastructure is changing, everything can change. Also, this is a plus and peace for those on duty, because they are not sleeping. They do not like to wake up at night, then they may have problems. This is a fact, psychologists have studied this.
If the attendants know that there will be some problem, then they are ready for this. They know how to recover it in case of a real problem. This should be done regularly in production.
Automation
The most important thing. When your number of servers grows linearly or exponentially, then the number of people is not born linearly. They are born, learn, but with some frequency. And you cannot increase the number of people equivalent to the number of your servers.
So you need an automation system that will do the work for these people.
What is automation?
In automation, it is very important to collect metrics from your infrastructure. I almost did not say anything about metrics in my report, because metrics are the core of your service and you don’t need to mention it, because it is the most important part of your service. If you do not have metrics, you do not know whether your service is working or not. Therefore, it is very important to collect metrics quickly. If, for example, your metrics are collected once a minute, and you have a problem in a minute, then you will not know about it. It is also very important to respond quickly. If a person reacts, for example, our minute has passed, when something happened, something is laid on the fact that the bug was in the metric, you receive an alert. We have a policy for 5 minutes. You have to start doing something, respond to the alert at this time. You begin to do something, you begin to understand, in fact, your problem is solved on average 10-15 minutes, depending on the problem. Automation allows you to speed up, but not solve, in the sense that it gives information about this problem before you start solving this problem.
We have such a tool Naoru - paranoid automation.

Automation consists of several components.
It consists of some alerts that come. This may be a simple Python script that connects to the server and checks that it is available. This can come from Nagios or Zabbix, no matter what you use. The main thing is that it comes quickly. Next we need to understand what to do with it, we need to diagnose. For example, if the server is unavailable, we should try to connect via SSH, connect via IPMI, see if there is no answer, it hangs or something else, you prescribe some kind of treatment.
Further, when you write automation, everything has to go through the operator. We have a policy that we are any kind of automation, for about 3-6 months, it is solved through the operator.
We have collected all the information about the problem, and this information is thrown out to the operator, such and such a server is unavailable for such a reason, and it indicates what needs to be done, and the operator is asked to confirm. The operator has very important knowledge. He knows that now there is some problem with the service. He, for example, knows that this server cannot be rebooted, because something else is running on it. Therefore, it cannot simply be restarted. Therefore, each time an operator encounters a problem, he introduces some improvements in this automation script, and each time it becomes better.
There is a big problem here, this is laziness of operators. They begin to automate automation. They automatically insert yes here:

Therefore, for some time we did not write yes / no, but: “Yes, I really want this and that.” In different case, randomly checked that this is really the console. It is very important.
It is also important to have hooks. Because not everything can always be checked. Hooks can be very simple, for example, if ZooKeeper is running on the server, then we need to check that all members of the group are working (script with errors), in fact, we just check something:

These hooks are located around the flow, there are hooks everywhere, in the diagnostic plugin, etc. You can create your hook for your service.
Next is the solution to the problem:

It can be very simple. For example, restart this server. Run puppet, chef, etc.
This is Naoru. This is reactive remediation. Which allows us to react to the event very quickly and repair them very quickly.
There is also an open-source solution. The most popular is StackStorm from Russian guys. They have a very good solution, quite popular. You can also do this with your own solutions like riemann or OpsGenie, etc.
There are proprietary solutions. From Facebook this is FBAR (facebook auto-remediation). Nurse from Linkedin'a. They are closed, but they constantly talk about these decisions. For example, Facebook recently made a report on the problem of moving the entire rack through its tool.
But automation is not only reactive (here and now), but also automation that needs to be done over a long period of time. For example, we need to update 10 thousand servers by restarting them. For example, you need to update the driver, kernel, and something else to do. This can take a long time: month, year, etc. In the reactive system it is impossible to constantly monitor
Therefore, we still have such a system Wheelhouse.
There is a scheme of how it works . Now I will tell you what is there.

Basically, we have a database cluster that has one master. A and there are two slave. We need to replace this master, for example, we want to update the kernel. To replace it, we need to block the slave, depromoute that master, remove it. We have a requirement in Dropbox, we should always have two slaves in the cluster for this configuration. We have a certain state of this cluster. HostA is in production, he is master, he is not released yet, we have two slave numbers, but we need three for this operation.
We have a certain state machine that does all this.
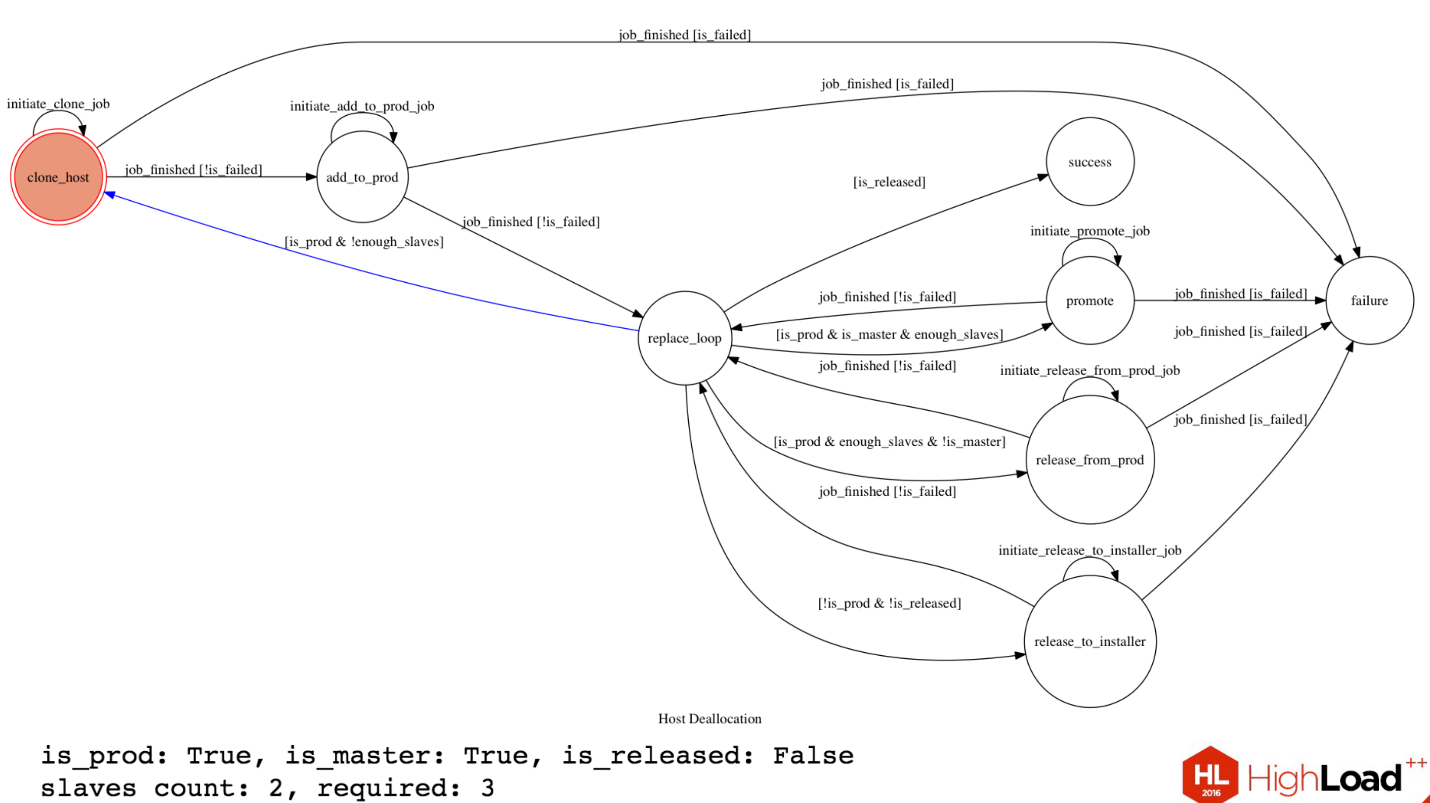
From replace_loop (blue arrow) we see that our server is in production, and we do not have enough slave'ov, and we move to the state to allocate more slave. We come to this state, we initiate work to create a new clone with the master'a new slave. It runs somewhere in Orchestrator, we are waiting. If the work is completed, and everything is fine, then we proceed to the next step. If it was fail, then go to the state of failure. Next we add a new slave in production to this host, also initiate this work in Orchestrator, wait and return to replace_loop.
We now have about this scheme:

One host is master, there are three slaves. We satisfy the condition that we have enough slaves. After that we pass into the state of promote.
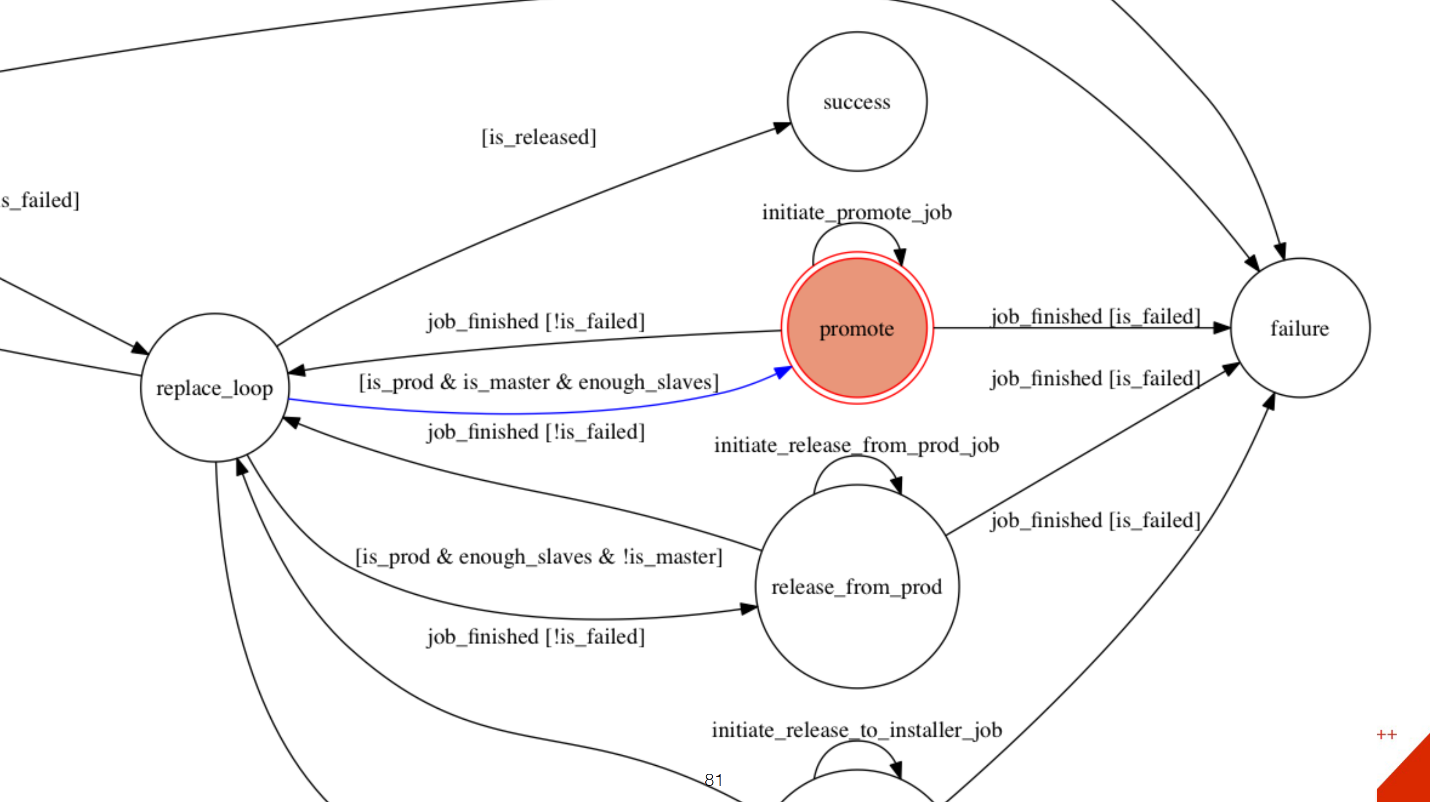
Actually it is depromote. Because we need to make master slave'om, and some slave master'om. It's all the same here. The work is added to the Orchestrator, the condition is checked, and so on, the remaining steps are about the same. We then remove master from production, remove traffic from it. We delete master in the installer, so that people who work on this server can update something on it.
This block is very small, but it participates in more complex blocks. For example, if we need to move an entire rack to another rack, because the drivers on the switches change, and we just need to disable the entire rack to reset the switch. We have described a lot of such state diagrams for different services, how to extinguish them, how to raise them. It all works. Even mathematically, you can prove that your system will always be in working condition. Why is this done through STM and not in procedure mode? Because if this is a long process, for example, cloning can take an hour or so, then something else may happen and the state of your system will change. In the case of a state machine, you always know which state and how to react to it.
We now use it in other projects. These 4 methods you can use to increase the availability and security of your data. I did not talk about specific solutions, because in any large company they write all the solutions themselves. Of course, we use some kind of stable blocks, for example, we use MySQL for databases, but above we have built our graph storage. We used semi sync for replication, but now we have our own replication, something like Apache BookKeeper, we also use proxdb. But in general, we have all our decisions, so I did not mention them, because they most likely do not look like yours. But you can use these methods with any of your solutions, with open source or not. To improve your availability.
That's all, thanks!
Source: https://habr.com/ru/post/321274/
All Articles