Virtualized Data Center Design

Introduction
From the user's point of view, the information system is well defined in GOST RV 51987 - “an automated system, the result of the operation of which is the presentation of output information for later use”. If we consider the internal structure, then in fact any IP is a system of interrelated algorithms implemented in the code. In the broad sense of the Turing-Church thesis, the algorithm (and, in fact, the IC) transforms a set of input data into a set of output data.
You can even say that the transformation of input data is the meaning of the existence of an information system. Accordingly, the value of IP and the entire complex of IP is determined by the value of the input and output data.
Based on this, design should begin and take data as the basis, adjusting the architecture and methods to the structure and significance of the data.
')
Stored data
The key step in preparing for design is to obtain the characteristics of all data sets planned for processing and storage. These features include:
- Data volume;
- Information on the life cycle of data (growth of new data, lifetime, processing obsolete data);
- Classification of data from tz. the impact on the company's main business (triad confidentiality, integrity, availability) along with financial indicators (for example, the cost of data loss in the last hour);
- Geography of data processing (physical location of processing systems);
- Requirements of regulators for each data class (for example, FZ-152, PCI DSS).
Information Systems
Data is not only stored, but also processed (transformed) by information systems. The next step after obtaining the characteristics of the data is the most complete inventory of information systems, their architectural features, interdependencies and infrastructure requirements in arbitrary units for the four types of resources:
- Processor computing power;
- The amount of RAM;
- Requirements for the volume and performance of the storage system;
- Requirements for data network (external channels, channels between the components of the IC).
The requirements for this should be for each service / microservice in the composition of the IP.
Separately, it is necessary to note the obligatory for correct design availability of data on the impact of IP on the company's main business in the form of IP downtime (rubles per hour).
Threat model
A mandatory model of threats against which it is planned to protect data / services should be mandatory. However, the threat model includes not only confidentiality aspects, but also integrity and availability. Those. eg:
- Failure of a physical server;
- Failure of the top-of-the-rack switch;
- The rupture of the optical communication channel between the data center;
- Failure of operational DSS entirely.
In some cases, threat models are written not only for infrastructure components, but also for specific information systems or their components, such as the failure of a DBMS with logical destruction of the data structure.
All solutions within the framework of a project to protect against an undescribed threat are redundant.
Regulator requirements
If the processed data falls under the special rules established by the regulators, information on data sets and processing / storage rules are required.
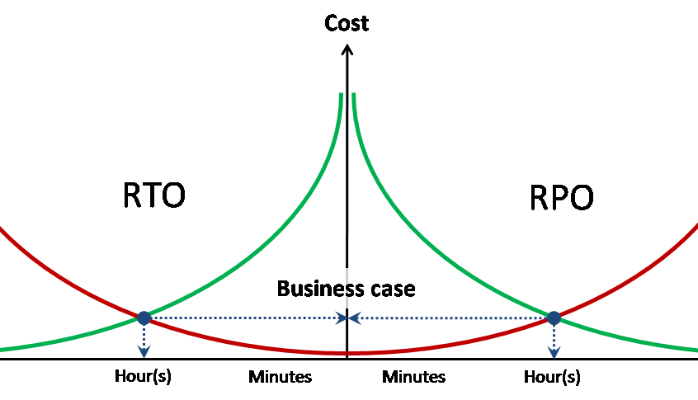
RPO / RTO targets
Designing any type of protection requires indicators of targeted data loss and target service recovery time for each of the described threats.
At the same time, ideally, RPO and RTO should have associated data loss and idle costs per unit time.
Resource Pooling
After collecting all the initial background information, the first step is to group the data sets and IP into pools, based on threat models and regulator requirements. The type of separation of different pools is determined programmatically at the level of system software or physically.
Examples:
- The contour processing personal data is completely physically separated from other systems;
- Backups are stored on a separate storage system.
In this case, pools can be with incomplete independence, for example, two pools of computing resources (processor power + RAM) are defined, which use a single storage pool and a single pool of data transfer resources.
Processor power

The abstract CPU requirements of a virtualized data center are measured in terms of the number of virtual processors (vCPU) and their consolidation ratio on physical processors (pCPU). In this particular case, 1 pCPU = 1 physical core of the processor (without Hyper-Threading). The number of vCPUs is summed over all defined resource pools (each of which may have its own consolidation factor).
The coefficient of consolidation for loaded systems is obtained empirically, based on the already existing infrastructure, or with a pilot plant and load testing. For non-loaded systems, “best practice” is applied. In particular, VMware calls the average ratio of 8: 1.
RAM
The total need for RAM is obtained by simple summation. Using oversubscription for RAM is not recommended.
Storage resources
Storage requirements are obtained by simply summing all pools by volume and performance.
Performance requirements are expressed in IOPS in combination with an average read / write ratio and, if necessary, a maximum response delay.
Separately, QoS requirements for specific pools or systems should be specified.
Data Network Resources
Data network requirements are obtained by simply summing up all bandwidth pools.
Separately, the requirements for quality of service (QoS) and delays (RTT) for specific pools or systems should be specified.
As part of the requirements for data network resources, there are also requirements for isolation and / or encryption of network traffic and preferred mechanisms (802.1q, IPSec, etc.)
Choice of architecture
In this guide, there’s no other option than the x86 architecture and 100% server virtualization. Therefore, the choice of computing subsystem architecture is reduced to the choice of server virtualization platform, server form factor and general server configuration requirements.
The key point of choice is certainty in the use of the classical approach with separation of the functions of processing, storage and transmission of data or convergent.
The classical architecture implies the use of intelligent external storage and data transfer subsystems, while the servers bring only processor power and RAM to the common pool of physical resources. In the extreme case, servers become completely anonymous, not having not only their own disks, but even a system identifier. In this case, the OS or hypervisor boot from embedded flash media or from an external storage system (boot from SAN) is used.
In the framework of the classical architecture, the choice between blades (blade) and rack (rack) is carried out primarily from the following principles:
- Economic efficiency (on average, rack servers are cheaper);
- Computational density (higher in blades);
- Power consumption and heat dissipation (at the blades the unit per unit is higher);
- Scalability and controllability (the blade as a whole requires less effort with large installations);
- Use of expansion cards (for blades a very limited choice).
Convergent architecture (also known as hyperconvergent ) involves combining data processing and storage functions, which leads to the use of local server disks and, as a result, the rejection of the form factor of classical blades. For converged systems, either rack servers or cluster systems are used, combining several blade servers and local disks in a single package.
CPU / Memory
To calculate the configuration correctly, you need to understand the type of load for the environment or each of the independent clusters.
CPU bound - an environment limited in performance by processor power. Adding RAM does not change anything in terms of performance (number of VMs per server).
Memory bound - an environment limited by RAM. More RAM on the server allows you to run more VMs on the server.
GB / MHz (GB / pCPU) - the average ratio of consumption of this particular load of RAM and processor power. It can be used to calculate the required amount of memory for a given performance and vice versa.
Calculation of server configuration

To begin with, it is necessary to determine all types of load and decide on combining or dividing different computational pools in different clusters.
Further, for each of the specific clusters, the ratio GB / MHz is determined under a known load. If the load is not known in advance, but there is a rough understanding of the level of loading of processor power, you can use the standard vCPU coefficients: pCPU to translate the requirements of pools into physical ones.
For each cluster, the sum of the requirements of the vCPU pools is divided by the coefficient:
vCPU sum / vCPU: pCPU = pCPU sum - the required number of physical. cores
pCPU sum / 1.25 = pCPUht - the number of cores adjusted for Hyper-Threading
Suppose it is necessary to calculate a cluster for 190 cores / 3.5TB RAM. In this case, we take the target 50% of the processor power load and 75% of the RAM.
| pCPU | 190 | CPU util | 50% | |
| Mem | 3500 | Mem util | 75% | |
| Socket | Core | Srv / CPU | Srv mem | Srv / Mem |
| 2 | 6 | 25.3 | 128 | 36.5 |
| 2 | eight | 19.0 | 192 | 24.3 |
| 2 | ten | 15.2 | 256 | 18.2 |
| 2 | 14 | 10.9 | 384 | 12.2 |
| 2 | 18 | 8.4 | 512 | 9.1 |
In this case, always use rounding to the nearest integer up (= ROUNDUP (A1; 0)).
From the table it becomes obvious that several server configurations are balanced under the targets:
- 26 servers 2 * 6c / 192 GB
- 19 servers 2 * 10c / 256 GB
- 10 servers 2 * 18c / 512 GB
The choice of these configurations in the future must be made based on additional factors, such as heat pack and available cooling, servers already used, or cost.
Features of server configuration selection
Wide VM. If it is necessary to locate wide VMs (comparable with 1 NUMA node and more), it is recommended to choose a server with a configuration where possible, allowing such VMs to remain within a NUMA node. With a large number of wide VMs, there is a risk of cluster resource fragmentation, and in this case, servers are selected that allow to place wide VMs as closely as possible.
Size domain single failure.
The choice of server size is also made from the principle of minimizing the domain of a single failure. For example, when choosing between:
- 3 x 4 * 10c / 512 GB
- 6 x 2 * 10c / 256 GB
Other things being equal, it is necessary to choose the second option, since when a single server fails (or serviced), not 33% of the cluster resources, but 17% are lost. Similarly, the number of VMs and ICs affected by the accident is halved.
Calculation of classic performance data storage

Classic storage is always calculated by the worst case scenario, excluding the impact of the operational cache and optimization of operations.
We take mechanical performance from a disk (IOPSdisk) as basic performance indicators:
- 7.2k - 75 IOPS
- 10k - 125 IOPS
- 15k - 175 IOPS
Then the number of disks in the disk pool is calculated using the following formula: = TotalIOPS * (RW + (1 –RW) * RAIDPen) / IOPSdisk . Where:
- TotalIOPS - total required performance in IOPS from a disk pool
- RW - percentage of read operations
- RAIDpen - RAID penalty for selected RAID level
Read more about the device RAID and RAID Penalty is described here - Storage performance. Part one. and storage performance. Part two. and storage performance. Part three
Based on the obtained number of disks, possible options are calculated that meet the requirements for storage capacity, including options with multi-level storage.
Calculation of systems using SSD as a storage level is considered separately.
Features of the calculation systems with Flash Cache
Flash Cache is a common name for all proprietary flash memory technology as a second-level cache. When using a flash cache, the storage is typically calculated to provide a steady load from the magnetic disks, while the peak serves the cache.
At the same time, it is necessary to understand the load profile and the degree of localization of calls to the storage volume blocks. Flash cache technology for loads with high localization of queries, and practically not applicable for uniformly loaded volumes (such as for analytics systems).
Calculation of hybrid systems low-end / mid-range
Hybrid systems of the lower and middle classes use multi-level storage with data movement between levels on a schedule. At the same time, the size of the multi-level storage unit for the best models is 256 MB. These features do not allow us to consider multi-level storage technology as a technology for increasing productivity, as many mistakenly considered. Multi-level storage in the systems of the lower and middle classes is a technology for optimizing the cost of storage for systems with pronounced uneven load.
For tiered storage, the top-level performance is primarily calculated, while the bottom-level storage is considered to only contribute to the missing storage capacity. For a hybrid multilevel system, it is necessary to use the flash cache technology for a multilevel pool in order to compensate for performance drawdown for suddenly heated data from the lower level.
Using SSD in a multi-level disk pool

The use of SSD in a multi-level disk pool has variations, depending on the implementation features of the flash cache algorithms from a given manufacturer.
The general practice of storage policy for a disk pool with an SSD level is SSD first.
Read Only Flash Cache. For a read-only flash cache, the storage level on the SSD appears when the write operations are significantly localized, regardless of the cache.
Read / Write Flash Cache. In the case of a flash cache for writing, the maximum cache volume is first set, and the storage level on the SSD appears only when the cache size is insufficient to serve the entire localized load.
The SSD and cache performance is calculated each time based on the manufacturer's recommendations, but always for the worst case scenario.
Source: https://habr.com/ru/post/321178/
All Articles