Content, metadata and context of open data
The result of the publication of data in free and free access depends on their composition and quality. The more complete and correct the public data will be, the higher the efficiency of their use will be, and the more users will prefer to work with them.

With regard to any transmitted data, especially public, it is always necessary to evaluate three of their key aspects: composition (content), description (metadata) and environment (context).
This publication continues the theme of open, shared and delegated data and applies to all these three categories.
The first important aspect of public data is related to its content and its internal organization.
')
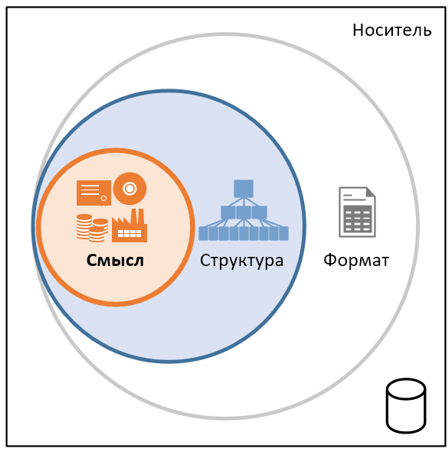
Any good data has some useful meaning. Nonsense information in any form is unsuitable for further processing and analysis in any kind of activity using any tools.
The digital data referred to in this publication, being primary or even secondary, in one way or another reflect the result of a certain collection of information. The ongoing collection of information allows you to record some qualitative and quantitative values of the properties of objects, processes, events, events, etc. Structured logged information is stored as digital data on the appropriate media. It is obvious that the data thus obtained directly (primary) or indirectly (secondary) determine a certain objective meaning.
Taking into account the fact that the human factor has a direct and inseparable effect on data, one can always say that they describe not an objective reality, but a certain understanding by the person of that objective reality about which he collects information in a targeted way. In other words, data always contain a certain amount of subjectivity in its content or structure and describe the perceived model from a given subject area.
It is the fact that the data in varying degrees describe some sense of the target model, their subsequent analysis and identification of important attributes of such a model is possible.
The meaning that the data contains determines the necessity and importance of their publication. For example, government statistics have a special social and economic meaning - hence, the obvious task of publishing them both in the form of digital datasets and special processed collections. If the data does not carry any important meaning for users or in general constitute a meaningless registration of the flow of events and events, then they will not be claimed. This statement suggests a certain idea that it is worth publishing digital sets with a well-formalized meaning.
The meaning of data is influenced by their level of redistribution.
The most valuable from this point of view and possessing undistorted meaning are the collected primary data. The more processing was done with the data, the more the meaning is distorted and modified. Hence the need to clearly indicate the quantity and quality of data redistribution.
The meaning contained in the data leaves its imprint on their structure.
Some indivisible minimal integral units can always be distinguished in the data.
Moreover, such indivisible integral units always have a meaning greater than direct ones. For example, a symbol (in its simplest form) does not carry any additional meaning, except that it represents a certain letter of the alphabet, a number, or a special designation in the text. On the other hand, the word, besides representing a certain set of the same symbols, has a semantic conceptual meaning and defines an object (noun), an attribute (adjective), an action (verb), etc. Therefore, the division of the word into symbols — the division of the minimum integral unit — results in the loss of its conceptual meaning.
But that's not all.
The choice of the minimum integral and indivisible unit is a subjective concept within the framework of a given subject and user goals.
For example, for some purposes, it can be established that an indivisible unit is not a single word, but an entire sentence. At the same time, even some formats can specify the features of the construction of minimum data units. For example, in the framework of spreadsheets, it is quite simple and convenient to take the contents of a single cell as the minimum data unit. However, in many respects, the choice of an integral unit of data is determined by a set of criteria of the data domain and the way they are recorded.
After the concept of the minimum indivisible data unit is given, the concept of the structure of the entire set of target data arises. So for a spreadsheet, data units form data sets in the form of rows or columns, and subsequently are grouped into tables (sheets) and sets of tables (books).
It is convenient to distinguish two levels of grouping complete data units:
The given data structure is based on some additional definition of their characteristics, therefore, directly or indirectly, the presence of metadata.
The structure of the data must be in order to make any meaningful processing.
Data operations are performed directly with indivisible whole units or with their groups. Moreover, it is even possible to process indivisible complete units in one way or another by creating new ones from them. For example, this allows you to do spreadsheet functionality: to process the contents of a single cell and divide it into certain constituent elements, but the main focus in such an application is still on processing cells as the simplest processed elementary units.
The second key feature of the selection in the digital data of individual integral units and their subsequent grouping is the possibility of identification .
The assignment of a unique absolute or relative name both for the indivisible part of the data and for the ordered data set significantly expands the processing functionality. Addressing, summarization, recursion, classification, and many additional simple or complex operations apply to named or identified data elements with subsequent returns to the original source (link history).
Another useful and important feature of the data structure, as derived from identification, is to link individual data elements according to certain criteria or tasks. Linking actually leads to the emergence of such functional as secondary structuring, nonlinear ordering, hyperlinks, alternative workarounds, etc. If you accompany the connection with some additional attributes, you can even select a special class of descriptor objects and build complex dependent structures of previously unimaginable forms and combinations. It is due to the binding appears some dynamics in the data.
Structuring data makes a significant contribution to the possibilities of not only digital processing, but also semantic analytics.
Modeling correct and effective digital data structures is a rather complicated and responsible competence that can give a good result only when combining the knowledge of information technology and the subject area. A well-defined structure allows you to conveniently and efficiently work with data both on a person and a machine. In other words, the right choice of structure allows you to quickly recognize ordered data directly by a person or by created algorithms.
The data structure, as already mentioned, may depend on the format of recording and storing data, but this is not the format itself. So it can be transformed. And it means that different structures can be defined within the same format. In the overwhelming cases in practice, for considerable simplification and for greater efficiency, the structure is closely interrelated with the format.
In the context of this publication, “format” is a method of storing data in a physical separate unit (file, record, table, stream) on a given medium.
The format defines the ability to read and accept data for processing by both human and algorithm. If the structure specifies a meaningful organization of the data, then the format is the technical side of their recording and storage.
Taking into account the fact that digital data is inseparable from machine media, the format is implemented on three machine-dependent layers, by choosing the appropriate formatting method on each of the layers:
The higher the layer, the more it is subject-oriented and depends on the meaning of the data. On the 3rd layer - the data scheme - the format is almost completely mixed with the subject area of the target data.
The character encoding is quite understandable and part of the settlement, which as a whole has come to relative theoretical and practical stability. Nevertheless, even in this matter, the practice of application leaves much to be desired. What to say about the notation and data schema, especially when applied to public data. Many factors and conflicting interests involved in free standards and paid powerful tools.
The key factor in the choice of data notation, as one of the formatting levels, is directly in the data structure.
For example, if the structuring of data is reduced to a table, then it is obvious that it will be convenient to format it, rather, as CSV, than as HTML. On the other hand, the task can be set so that the choice will be made in favor of XML. It seems quite exotic, but it is possible to notify the data table and as a sequence of INSERT (SQL) commands for each of the rows.
For public data, simple, free and common formats are preferred. A priority, for example, for open state data is a bunch: [Unicode + CSV | XML + custom_scheme]. Moreover, the custom data schema is often described in the “open data passport”.
Of course, it is possible and necessary to develop the formats of data transmitted and published. But to a large extent, new items from this area will be perceived at the private level or with secure data transfer. For public data, those formats that are widely distributed and for work, with which there are many both paid and free tools that analysts are accustomed to using, will remain more understandable and relevant.
The question of data reuse may be incorrectly attributed to the peculiarities of their formatting, but it is rather a question of their proper structuring. It is at the level of the structure of digital data that it becomes possible to link and organize links. The format only defines the actual rules for recording and link resolution. Including the format, it can set or support “inter-format” reference rules so that the user has the opportunity to refer in one set or data element to another.
The second aspect of public data is its effective description, which ultimately turns into metadata . If this aspect can be missed for some time for internal or protected data transmission, for data that is placed on the network openly and free of charge, this is very important for their effective use.
For a holistic transfer of public data, the best way is to keep the metadata “inside” the data itself. That is, it is possible to record original digital data in such a way that they are accompanied in parallel by some attributes, and the recording structure allows the algorithms to extract the metadata contained in it.
What can be done quite well, for example, within the framework of XML notation: where the markup already defines the type of element (node, attribute, document), and the use of attributes and space names opens up possibilities for embedding metadata. However, reading data combined with their description requires, at a minimum, mastering more complex competences and tools. It is much clearer and more obvious for most users to receive clean data with the name and headers. But this in turn causes its problems in reading and understanding data. Until the development of uniform and understandable standards in this direction is far.
Metadata should include:
The more complete and complete the metadata accompanying the package of digital data, the more powerful will be their subsequent use to extract useful knowledge and the more effective will be the reverse effect of new knowledge on the system, which is described by the source data.
At a minimum, the user should designate the composition and purpose of the data, as well as give an indication of the machine format for recording and storing them. It is also good if the metadata includes an assessment of the quality of the data.
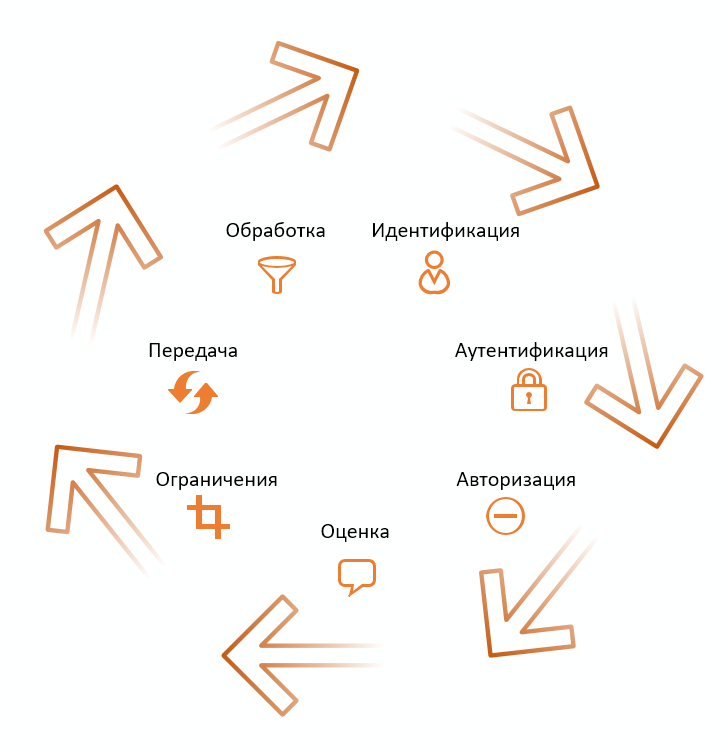
To understand what should be included in the metadata, you can consider the operations in which they are actually used or required for use. Here are the most important seven of them in terms of two directly interacting roles within the public data transfer scheme:
1. Data identification
2. Data authentication
3. Data Authorization
4. Data evaluation
5. Data limitations
6. Data transfer
7. Data processing
The quality of public data begins with the quality of their metadata.
A special role in certain situations begins to play the third aspect of public data - the environment.
This is the most complex of the three considered (the other two - content and metadata) - but it is the most valuable for the strategic and thematic development of analytics and the search for knowledge, especially with related issues.
In the public data space - the context for a given set will be all other data with which analysts can correctly link them for one reason or another.
You can correctly specify the context only if the subject data and their purpose are correctly set for the master data.
Contextual data is associated with master data in several ways:
From any point of view, any data can be considered a context in relation to the main one. This is the subjective aspect of analytics. The whole question lies in the tasks and expediency.
Permanent disaggregation of the analyzed data array by searching for and connecting to it an additional environment cannot be considered the norm if it is an end in itself. Therefore, a rational approach can be called a thorough work on the careful planning of data research in the framework of which designate and adhere to a limited set. The question “what kind of data is still needed?” Should be asked at key stages of the analysis in cases when it is really necessary to expand the semantic front of research.
The context is rarely taken into account when data is published or used, or it is taken for granted as an obvious increase in the data set. However, it is the unlimited possibility of extending the framework to the context and the numerous options for combining data that allow one to take advantage of the public use of data over the closed one . In this regard, the priority is the development of repositories of publicly available and generally significant digital data, which constitute the context for any data in a given subject area. For example, when working with economic data, it may be extremely useful to have generally accessible reference books, classifiers, catalogs (for example, OKVED, KLADR, BIK, Unified Statements, etc.)
For the same purpose, thematic “portals” and “hubs” of open data are extremely useful and created.
With regard to any transmitted data, especially public, it is always necessary to evaluate three of their key aspects: composition (content), description (metadata) and environment (context).
This publication continues the theme of open, shared and delegated data and applies to all these three categories.
Links to previous articles, which dealt with some of the concepts used in this article
Data organization
The first important aspect of public data is related to its content and its internal organization.
')
Meaning
Any good data has some useful meaning. Nonsense information in any form is unsuitable for further processing and analysis in any kind of activity using any tools.
The digital data referred to in this publication, being primary or even secondary, in one way or another reflect the result of a certain collection of information. The ongoing collection of information allows you to record some qualitative and quantitative values of the properties of objects, processes, events, events, etc. Structured logged information is stored as digital data on the appropriate media. It is obvious that the data thus obtained directly (primary) or indirectly (secondary) determine a certain objective meaning.
Taking into account the fact that the human factor has a direct and inseparable effect on data, one can always say that they describe not an objective reality, but a certain understanding by the person of that objective reality about which he collects information in a targeted way. In other words, data always contain a certain amount of subjectivity in its content or structure and describe the perceived model from a given subject area.
It is the fact that the data in varying degrees describe some sense of the target model, their subsequent analysis and identification of important attributes of such a model is possible.
The meaning that the data contains determines the necessity and importance of their publication. For example, government statistics have a special social and economic meaning - hence, the obvious task of publishing them both in the form of digital datasets and special processed collections. If the data does not carry any important meaning for users or in general constitute a meaningless registration of the flow of events and events, then they will not be claimed. This statement suggests a certain idea that it is worth publishing digital sets with a well-formalized meaning.
The meaning of data is influenced by their level of redistribution.
The most valuable from this point of view and possessing undistorted meaning are the collected primary data. The more processing was done with the data, the more the meaning is distorted and modified. Hence the need to clearly indicate the quantity and quality of data redistribution.
The meaning contained in the data leaves its imprint on their structure.
Structure
Some indivisible minimal integral units can always be distinguished in the data.
Moreover, such indivisible integral units always have a meaning greater than direct ones. For example, a symbol (in its simplest form) does not carry any additional meaning, except that it represents a certain letter of the alphabet, a number, or a special designation in the text. On the other hand, the word, besides representing a certain set of the same symbols, has a semantic conceptual meaning and defines an object (noun), an attribute (adjective), an action (verb), etc. Therefore, the division of the word into symbols — the division of the minimum integral unit — results in the loss of its conceptual meaning.
But that's not all.
The choice of the minimum integral and indivisible unit is a subjective concept within the framework of a given subject and user goals.
For example, for some purposes, it can be established that an indivisible unit is not a single word, but an entire sentence. At the same time, even some formats can specify the features of the construction of minimum data units. For example, in the framework of spreadsheets, it is quite simple and convenient to take the contents of a single cell as the minimum data unit. However, in many respects, the choice of an integral unit of data is determined by a set of criteria of the data domain and the way they are recorded.
After the concept of the minimum indivisible data unit is given, the concept of the structure of the entire set of target data arises. So for a spreadsheet, data units form data sets in the form of rows or columns, and subsequently are grouped into tables (sheets) and sets of tables (books).
It is convenient to distinguish two levels of grouping complete data units:
- primary - grouping (merging, ordering) directly elementary indivisible integral data units;
- secondary - grouping (merging, ordering) of primary and secondary grouped data units.
The given data structure is based on some additional definition of their characteristics, therefore, directly or indirectly, the presence of metadata.
The structure of the data must be in order to make any meaningful processing.
Data operations are performed directly with indivisible whole units or with their groups. Moreover, it is even possible to process indivisible complete units in one way or another by creating new ones from them. For example, this allows you to do spreadsheet functionality: to process the contents of a single cell and divide it into certain constituent elements, but the main focus in such an application is still on processing cells as the simplest processed elementary units.
The second key feature of the selection in the digital data of individual integral units and their subsequent grouping is the possibility of identification .
The assignment of a unique absolute or relative name both for the indivisible part of the data and for the ordered data set significantly expands the processing functionality. Addressing, summarization, recursion, classification, and many additional simple or complex operations apply to named or identified data elements with subsequent returns to the original source (link history).
Another useful and important feature of the data structure, as derived from identification, is to link individual data elements according to certain criteria or tasks. Linking actually leads to the emergence of such functional as secondary structuring, nonlinear ordering, hyperlinks, alternative workarounds, etc. If you accompany the connection with some additional attributes, you can even select a special class of descriptor objects and build complex dependent structures of previously unimaginable forms and combinations. It is due to the binding appears some dynamics in the data.
Structuring data makes a significant contribution to the possibilities of not only digital processing, but also semantic analytics.
Modeling correct and effective digital data structures is a rather complicated and responsible competence that can give a good result only when combining the knowledge of information technology and the subject area. A well-defined structure allows you to conveniently and efficiently work with data both on a person and a machine. In other words, the right choice of structure allows you to quickly recognize ordered data directly by a person or by created algorithms.
The data structure, as already mentioned, may depend on the format of recording and storing data, but this is not the format itself. So it can be transformed. And it means that different structures can be defined within the same format. In the overwhelming cases in practice, for considerable simplification and for greater efficiency, the structure is closely interrelated with the format.
Format
In the context of this publication, “format” is a method of storing data in a physical separate unit (file, record, table, stream) on a given medium.
The format defines the ability to read and accept data for processing by both human and algorithm. If the structure specifies a meaningful organization of the data, then the format is the technical side of their recording and storage.
Taking into account the fact that digital data is inseparable from machine media, the format is implemented on three machine-dependent layers, by choosing the appropriate formatting method on each of the layers:
- Data encoding is the chosen method of setting codes for a finite set of symbols or concepts involved and valid for recording data. For example, the character encoding is UTF-8 or ASCII.
- Data notation is the chosen method of formalized recording of ordered data. For example, CSV or XML.
- The data scheme is the chosen method of special organization of different data elements according to predefined metadata. For example, for XML it is the choice of XSD, for CSV it is the choice of table schema (fields and links).
The higher the layer, the more it is subject-oriented and depends on the meaning of the data. On the 3rd layer - the data scheme - the format is almost completely mixed with the subject area of the target data.
The character encoding is quite understandable and part of the settlement, which as a whole has come to relative theoretical and practical stability. Nevertheless, even in this matter, the practice of application leaves much to be desired. What to say about the notation and data schema, especially when applied to public data. Many factors and conflicting interests involved in free standards and paid powerful tools.
The key factor in the choice of data notation, as one of the formatting levels, is directly in the data structure.
For example, if the structuring of data is reduced to a table, then it is obvious that it will be convenient to format it, rather, as CSV, than as HTML. On the other hand, the task can be set so that the choice will be made in favor of XML. It seems quite exotic, but it is possible to notify the data table and as a sequence of INSERT (SQL) commands for each of the rows.
For public data, simple, free and common formats are preferred. A priority, for example, for open state data is a bunch: [Unicode + CSV | XML + custom_scheme]. Moreover, the custom data schema is often described in the “open data passport”.
Of course, it is possible and necessary to develop the formats of data transmitted and published. But to a large extent, new items from this area will be perceived at the private level or with secure data transfer. For public data, those formats that are widely distributed and for work, with which there are many both paid and free tools that analysts are accustomed to using, will remain more understandable and relevant.
The question of data reuse may be incorrectly attributed to the peculiarities of their formatting, but it is rather a question of their proper structuring. It is at the level of the structure of digital data that it becomes possible to link and organize links. The format only defines the actual rules for recording and link resolution. Including the format, it can set or support “inter-format” reference rules so that the user has the opportunity to refer in one set or data element to another.
Certainly machine data reading depends on the format.
At the same time, it is wrong to understand “machine” reading in isolation from the data structure. After all, we are talking about the ability to read digital data on the basis of reading the algorithms of a given digital structure. So in simple scanned images there is no semantic structure of digital data. Yes, a scanned copy is undoubtedly a kind of ordered stream of digital data reproduced by a special program into an image that a person understands at his level. It can even be recognized by the OCR algorithm. But it does not have a given data structure, which, without additional processing, allows us to treat the scanned image solely as a whole as an indivisible unit. Accordingly, the benefits of an unprocessed scanned copy are minimal. Publication of scanned documents in such a case can be aimed solely at viewing by a person, or at using particularly complex and productive tools of “isolating” information from reliable sources.
Scanned documents or other images can be a wonderful proof of the primary data and even the primary source for selective manual verification. If the publicly available scanned images with valuable data are converted into arrays of read and processed data into arrays, then the chain of “gratuity” is unlikely to remain. Still, for now, resources are needed for processing scanned copies. Although technology does not stand still, including technology investment in large-scale projects.
Thus, even raw images can constitute a separate category of public data. And they are machine-readable anyway. In fact, it is quite difficult to imagine a machine-readable digital stream of bytes. The maximum that can be presented is a violation of data integrity at any of the levels: on the semantic, on the structural or on one of the layers of the format.
Scanned documents or other images can be a wonderful proof of the primary data and even the primary source for selective manual verification. If the publicly available scanned images with valuable data are converted into arrays of read and processed data into arrays, then the chain of “gratuity” is unlikely to remain. Still, for now, resources are needed for processing scanned copies. Although technology does not stand still, including technology investment in large-scale projects.
Thus, even raw images can constitute a separate category of public data. And they are machine-readable anyway. In fact, it is quite difficult to imagine a machine-readable digital stream of bytes. The maximum that can be presented is a violation of data integrity at any of the levels: on the semantic, on the structural or on one of the layers of the format.
Data description
The second aspect of public data is its effective description, which ultimately turns into metadata . If this aspect can be missed for some time for internal or protected data transmission, for data that is placed on the network openly and free of charge, this is very important for their effective use.
For example, open government data is always accompanied by a minimal and mandatory set of metadata.
First, the name of the data set. Secondly, the subject description of dataset is given. Thirdly, there is a passport of the open data set, including including an indication of the format, relevance, size, composition.
For a holistic transfer of public data, the best way is to keep the metadata “inside” the data itself. That is, it is possible to record original digital data in such a way that they are accompanied in parallel by some attributes, and the recording structure allows the algorithms to extract the metadata contained in it.
What can be done quite well, for example, within the framework of XML notation: where the markup already defines the type of element (node, attribute, document), and the use of attributes and space names opens up possibilities for embedding metadata. However, reading data combined with their description requires, at a minimum, mastering more complex competences and tools. It is much clearer and more obvious for most users to receive clean data with the name and headers. But this in turn causes its problems in reading and understanding data. Until the development of uniform and understandable standards in this direction is far.
Metadata should include:
- Description of the data:
- a. name
- b. short description
- c. subject area description
- d. point of view
- e. purpose of data collection and presentation
- f. data processing level
- g. restrictions on use from the point of view of the subject area
- h. illustrative models and schemes for complex data
- i. a thesaurus of data-related concepts (or reference to a valid thesaurus)
- j. references to data sources (primary data) and data collection method
- k. labeling data by time, place, relevance, dependence, significance, etc.
- l. contextual numeric references or other useful information
- m. possible problems with the semantic integrity of data and recommended solutions
- Description of the data structure :
- a. basic structure elements (holistic and indivisible)
- b. principles of grouping and linking elementary and derived data units
- c. priority and secondary valid interdependencies of data structure elements
- d. availability and possible basic types of structure elements
- e. sending or formalizing the principles of building a data structure or its transformation
- f. the permissibility of external references to elements included in the data structure
- g. applicable standards for building structure
- h. data structure restrictions
- i. possible problems with the structural integrity of the data and recommended solutions
- Description of the data format :
- a. applicable data encoding format (reference or description)
- b. used format of data notation (link or description)
- c. applicable data schema format (reference or description)
- d. Recommended tools for working with the data format (algorithms, specifications, protocols, software packages, services, etc.)
- e. features of the data format
- f. possible errors and problems of data format application
- g. justification for the use of data format (if necessary)
- h. foreseen (verified) options for converting to other formats
- i. technical assessment of the quality of data compliance with a given format (especially in cases where the data may contain formatting errors)
- j. Possible problems with data integrity at the format level and recommended solutions
The more complete and complete the metadata accompanying the package of digital data, the more powerful will be their subsequent use to extract useful knowledge and the more effective will be the reverse effect of new knowledge on the system, which is described by the source data.
At a minimum, the user should designate the composition and purpose of the data, as well as give an indication of the machine format for recording and storing them. It is also good if the metadata includes an assessment of the quality of the data.
To understand what should be included in the metadata, you can consider the operations in which they are actually used or required for use. Here are the most important seven of them in terms of two directly interacting roles within the public data transfer scheme:
1. Data identification
- The provider assigns the name and defines the subject area for the data set.
- The recipient restores the name, destination, subject area and system of interacting objects, which is described by the data set
2. Data authentication
- The supplier specifies the factors of possible and valid authentication and quality (including relevance, relevance, adequacy) of the published data set
- The recipient understands a possible way to verify the authenticity and quality (including relevance, relevance, adequacy) of the data set and, if necessary, performs a check.
3. Data Authorization
- The supplier determines and formalizes who the author, owner and publisher is in relation to the data set, and also determines who publishes the published data, under what conditions and for what
- The recipient checks and evaluates who created, owns and supplies the data set, as well as being tested for the possibility and feasibility of their use.
4. Data evaluation
- The vendor measures the amount of data (within the chosen structure and format) and gives an estimate of the quality of the data.
- The recipient examines the established data volumes (within the specified structure and format) and checks the data quality assessment issued for possible use.
5. Data limitations
- The supplier sets various restrictions (by meaning, structure and format) for the published data set and publishes data in accordance with the restrictions.
- The recipient finds out what limitations (in meaning, structure and format) are imposed on the data set and works with the data with their account
6. Data transfer
- The supplier assembles the data into a complete set and, within the established conditions (data transfer contract), sends them directly or makes them available
- The recipient accepts directly or downloads from the open access a complete, complete set of data according to the established conditions
7. Data processing
- The supplier preliminarily (before publication) processes the data into a set in accordance with the existing task of publication.
- The recipient processes the received data for its own purposes within the framework of the publication circumstances known to it
To illustrate the importance of metadata, it is worth noting that subject data analysts spend most of their time and effort on working not with the digital data sets themselves, but with metadata.
They determine the format of the set, the particular application of the format, the data scheme, the coding, the organizing structure, the purpose and characteristics of the composition, the subject area and the applicability of the data to a particular thematic task, check the quality of the data and its relevance and do many more similar things. For example, even SQL query texts can be made with only a table schema and without directly having data from these tables.
The quality of public data begins with the quality of their metadata.
Data environment
A special role in certain situations begins to play the third aspect of public data - the environment.
This is the most complex of the three considered (the other two - content and metadata) - but it is the most valuable for the strategic and thematic development of analytics and the search for knowledge, especially with related issues.
In the public data space - the context for a given set will be all other data with which analysts can correctly link them for one reason or another.
You can correctly specify the context only if the subject data and their purpose are correctly set for the master data.
Contextual data is associated with master data in several ways:
- Direct linking - by specifying direct links to third-party data sets that are published by the same publisher or published by other people in the public domain. The context serves in this key as the official data extension. Obviously, the direct linking of public data with closed or paid data is an example of a not entirely bona fide publisher.
- Indirect subject binding - through the definition for the basic data of the name, subject, purpose, relevance and relevance. The user independently studies a given subject area and searches for data that constitutes the context of interest. In addition to the obvious examples of objective linking, it is worth mentioning the following mathematical linking options: by distribution, frequency, or other indicators. As well as binding options for similar attributes or identical bases.
- Linking implementation - through the inclusion in the main data of other data fragments as a result of which there is a non-obvious reference or subject relationship. If the recipient clearly understands the “introduction” of the context into the base, then he also clearly understands the essence of the context data. Quite often, this kind of linking is based on the inclusion of unique or conditionally unique identifiers of context data in the main data. Unlike direct referencing, binding by implementation does not include the inclusion of explicit addressing to contextual data elements and does not categorically provide any references to context sets. And unlike indirect object binding, implementation still provides for the indication of certain identifying fragments of the context in the basis.
From any point of view, any data can be considered a context in relation to the main one. This is the subjective aspect of analytics. The whole question lies in the tasks and expediency.
Permanent disaggregation of the analyzed data array by searching for and connecting to it an additional environment cannot be considered the norm if it is an end in itself. Therefore, a rational approach can be called a thorough work on the careful planning of data research in the framework of which designate and adhere to a limited set. The question “what kind of data is still needed?” Should be asked at key stages of the analysis in cases when it is really necessary to expand the semantic front of research.
The context is rarely taken into account when data is published or used, or it is taken for granted as an obvious increase in the data set. However, it is the unlimited possibility of extending the framework to the context and the numerous options for combining data that allow one to take advantage of the public use of data over the closed one . In this regard, the priority is the development of repositories of publicly available and generally significant digital data, which constitute the context for any data in a given subject area. For example, when working with economic data, it may be extremely useful to have generally accessible reference books, classifiers, catalogs (for example, OKVED, KLADR, BIK, Unified Statements, etc.)
For the same purpose, thematic “portals” and “hubs” of open data are extremely useful and created.
Source: https://habr.com/ru/post/321010/
All Articles