Overview of the architecture and subsystems of deployment and monitoring. How engineers make the system transparent to design

Konstantin Nikiforov ( melazyk )
The report will be about all sorts of secret and not very things that such a large company like Mail.Ru uses in monitoring both for deployment and for configuration management.
My name is Konstantin Nikiforov, I am the head of the system administrators group at Mail.Ru. Our group is engaged in servicing the target.my.com projects, Mail.Ru advertising systems and the top.mail.ru project. All three of our projects are quite specific, because we do not have any user content, we mainly parasitize you as users, and our peculiarity lies in the fact that we have very large PPS on the fronts, which not many projects have. Those. for projects such as Odnoklassniki, like VKontakte, this is understandable, because they are simply huge, for smaller projects there is no such thing. And we are located on all of the above and on all Mail.Ru pages, so our PPS is even larger than those of these projects.
We will talk about how we deploy the code. From the moment when the developers give it to us, until the moment when it appears in production, and the user sees the effect of its change.
')

My report will be divided into three parts: in the first part, we will talk about the deployment, in the second part we will talk about Graphite as a way to implement the project, and in the third part we will talk about how we integrate our Graphite, our deployment system, in this case Puppet, and our monitoring system.

First, about storing Puppet manifests, and why we chose Puppet. We chose Puppet for one reason - because it is practically the corporate standard of Mail.Ru. All departments of all projects use Puppet to maintain the configuration. Any configuration system is useless without version control, because if you cannot see what you have changed in the project, there is no sense in it. Naturally, now a very large number of different version control systems, we use the most popular at the moment, this is GIT.
How is the Puppet process itself organized? how is the Puppet environment organized? We share all of our users on the environment. Those. each user who is brought in by root on the server is the owner of one environment named for him. Well, for me it is “Nikiforov”, for my subordinates - these are their last names. And one environment "Production", which is the current configuration of the production system. Accordingly, all servers must be synchronized with the environment "Production". For testing, for developing new manifestos, for developing modules, for developing and testing some new features or some new approaches, we use only the environment in order not to break the production system.
Another condition that we always fulfill is related to what I will discuss below. All servers in our projects, without exception, are managed by Puppet. 100% of servers. There is not a single calculation that we would do without commit. But in order to properly organize different versions of software on different servers, different test, different experimental versions of the system - for this we use some agreements that allow us to do this most flexibly and most conveniently for us. One of these agreements is the base: module, which we write to cross all servers, i.e. we can not go up the server without this module. It is considered that the default define node is the base: class. What is it done for? Obviously, this rolls in all sorts of core systems, all sorts, bashis, syslogs, configs, and similar things, but the key thing in this base class is: - the base class: it stores the server role.
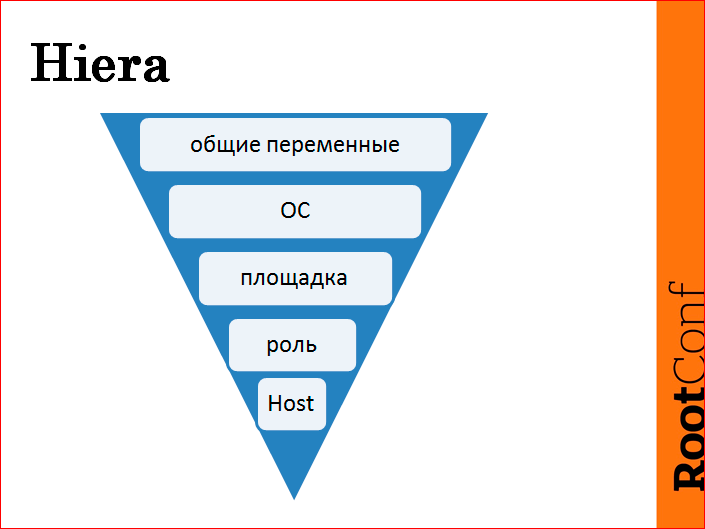
Now you see a triangle that shows the structure of our Hiera, the application of changing our variables. From the top level, the default variables that we use by default, we further rewrite this matter relative to the OS, relative to the site, relative to the role and host.
Of these five things, two things are enough official - OS and playground.
Why OS? It is needed only in order to slightly edit the base: class, because, nevertheless, in the CentOS 7, CentOS 6 software we use, the software is different. And in order to synchronize and level this business, we use this intermediate Hiera, with which we align default values.
The site, for the most part, belongs to that class in order to localize traffic within the site. For example, it is foolish to walk from one site to an LDAP server on another site, this is completely unnecessary for anyone, and in the case of a dump site, it actually leads to destructive actions. Therefore, in this case we use it for more official purposes. We have such a function, called FQDN rotate IP, which does such a thing - we transfer, for example, an LDAP server; we have 12 of them, we push them into one array and say, like, roll these LDAP servers onto all servers. But our FQDN rotate is smart - it takes the whole array, removes servers that are adjacent to this server from it, mixes them up to distribute a bit of workload, puts them at the top of the list to use them priority, the rest mixes up. So there is a small entropy in the mixing inside the site, so the entropy occurs with mixing in the LDAP site. And at different sites it is all rotated.
This helps us not to think about how to prescribe that we need to keep such an order here, we need to keep such an order, and so on. Therefore, we use the platform, as a rule, for Puppet's custom functions, which we write to reduce brain inclusions at the time of the development of new manifestos.
And the key thing - the role is a variable in the base: class. It is clear that the role is shared by the server logically, for example, frontends, MySQL, Tarantool, etc. But why do we include it in base :? Because it allows us to override this role. If you nail, for example, in Hiera any variable, you should always ensure that you will always redefine a role in Hiera. Suppose you wrote to the host: this is the frontend role. You will be obliged to write to each node that this is the “frontend” role. It will not be enough for you to take another server, tell the type, “such is the class” and Enter. No, you will need to go to Hiera and prescribe that he is "frontend". In this case, we can override this base role. Suppose we can put a server, the server will be without a role, then we assign it a role, for example, “MySQL”, and then we reassign it to some other manifesto in another part. This we can do. And this allows us to more flexibly handle these roles.
And the bottom level is the host. Those. in fact, we only get three levels. As I said, the OS and the platform are the service levels that we use insofar as we do not use at the time of the development of the manifests. We use three levels: common variables, role and host. As practice has shown, three levels are quite enough to flexibly configure all the environment variables of the server and hosts as such.
There is, of course, some inconvenience. Suppose we have a role of some kind of “Nginx”, and on 15 Nginx out of 38 we need to roll out a specific version. There will have to be determined in each host, unfortunately, but this software in our projects is not so much. There is only one in which we are actively changing versions, we simply assigned all the rest to roles. Divided, and that was enough for us.

Now let's talk about how we write manifestos.
We, since we are not alone, we are several people, these several people must somehow synchronize. We cannot write each module as we want, because then it turns out that we have one user of this module. Or each module will need to write a huge documentation on how to use it. Therefore, we have some agreements that we always adhere to.
The agreements are not very complicated, they fit into three concepts: update, not sleep, tell. This means that we always keep the version in Hiera. Why in Hiera? Because we should be able to redefine it at any time on any server. If we nail these things hardcore, it will be very difficult to support this whole thing, it will be necessary to make a large number of changes. As a result, the version should always be stored in Hiera.
Passwords Passwords, we keep quite clever way. I honestly do not know if anyone uses the same system. The fact is that we are trying to make our system transparent for our development. This is very important because the development is what the project actually lives for, thanks to which the project lives. We are still such a support service that helps all this live. Therefore, the development should provide a large amount of information, and we give all the manifestos, all the modules to the development, because programmers are more capable of programming as such. And hoping that the maintenance service programs better than the development service is stupid. Therefore, we give all our manifestos, but we cannot give passwords, what to do with it? There is a very simple solution that we came up with - we separate all the passwords into a separate PP file, which we store outside our repository. Inside the repository, we make a symlink to this file, this file is backed up independently and independently we monitor versions and versioning. To be honest, it's just RCS, really. But this allows us to separate the entire project code from the passwords.
Thus, we can give all our modules to all departments in the company. Of course, we can not put them in open source, for the simple reason that the structure, architecture of the project will be visible, which in itself is quite sensitive information. But, nevertheless, we can give it to all our colleagues who can use our experience, and can correct our mistakes. It is very important.
And the third is “tell everyone”. We have a monitoring system, which Sasha asked me not to talk about, because she is a closed source, and we try to talk less about it, but the point is that we have a certain resource, which we can export directly from Puppet ' a role in monitoring. Those. we can, for example, say that we have installed MySQL on this server, rolled up the manifest, and at the same time, we’ve got “we have installed MySQL” in monitoring.
We can define any role, it doesn’t have to be a module, but it’s a good thing - I wrote a module, rolled it onto some server, and we need to know that we’ve rolled this module somewhere, for example, some new software. But such roles, push in our monitoring can be, for example, various configurations of frontends, there can be various shards. For example, we can raise eight Tarantools, which are shards of one entity, one data only, and we can see that we have Tarantool installed. This information gives us, in general, nothing. Well, Tarantool and Tarantool. With the help of this thing we can export shards directly. We have, say, a class that defines sharding, roughly speaking, we know exactly which Tarantool is a shard, and we can launch the same information directly into the host description in monitoring. This helps to quickly find the right entities in our project.

Let us turn to Deploy. Red button concept. We have such a concept, which in our opinion is the most correct. Many people hang hooks on various version control systems, according to which the code goes to production. We refused this thing, because the company Mail.Ru accepted the agreement that the admin who rolls out the code is responsible for everything. It doesn't matter what they wrote in this code. Therefore, if you rolled out any wrong program, you have to fix it. The developer is not responsible in this case. Of course, he is responsible to you and to his conscience, but, nevertheless, they will come to you, and you will fix this whole thing.
Therefore, we have the concept of the red button deploy.sh. This is a regular Bash script that can do a very simple thing - it can roll out of the GIT wizard into the environment “Production”. Those. all that he does is he takes from the master and puts it in the environment of "Production".
He has some options - this is “roll out the master” for some date, i.e. if we can say: “Roll out at yesterday at 9 in the morning,” he, respectively, will find a commit that was relevant at 9 in the morning, and roll it out. Or directly “pass commit”. An additional option to the whole case is log.
There are cases when something is broken that we don’t know about. In this case, it is not clear what to do, because the etymology of the origin of this problem is not clear. As a rule, in such cases, everyone starts to say: “Let's roll back, that rolled, roll back”. At this point, there is some kind of panic. Whenever a project goes into a non-working state, there is a panic in the heads not only of the administrators, but also of the development, and they begin to influence the whole thing with all possible means and methods. Therefore, such a situation, when one part of the development kicks one admin, the second - the second, and the third starts to tutorize the neighboring department, very often.
At this moment there should be one sole responsible person who should say: “Guys, that's enough!”. As a rule, this “Guys, enough!” Is matched with the rollback of the code. In our case, with the haul manifest. Therefore, we roll back the manifests using the second or third options, and break this warmly. Thus, when the admin comes and tries to roll out something new in production that the developer has advised him and said that now everything will be repaired, he attacks the situation when they say to him: “No, this is the kind of person who fills up, and the more we roll out nothing. " This allows you to make a stop that does not allow to break the project further.
Over the past three years, such functionality has come in handy once, maybe two. I remember one for sure, the second one probably came up with it. And at this moment I did not regret a bit about such a decision. But this, again, is all up to you - someone is very confident in their commit'ah, I'm not sure. I’m not sure of our manifest in any commit, so there must also be a system that ensures that we not only rolled one server group, but did not break another server group. About this and let's talk further.
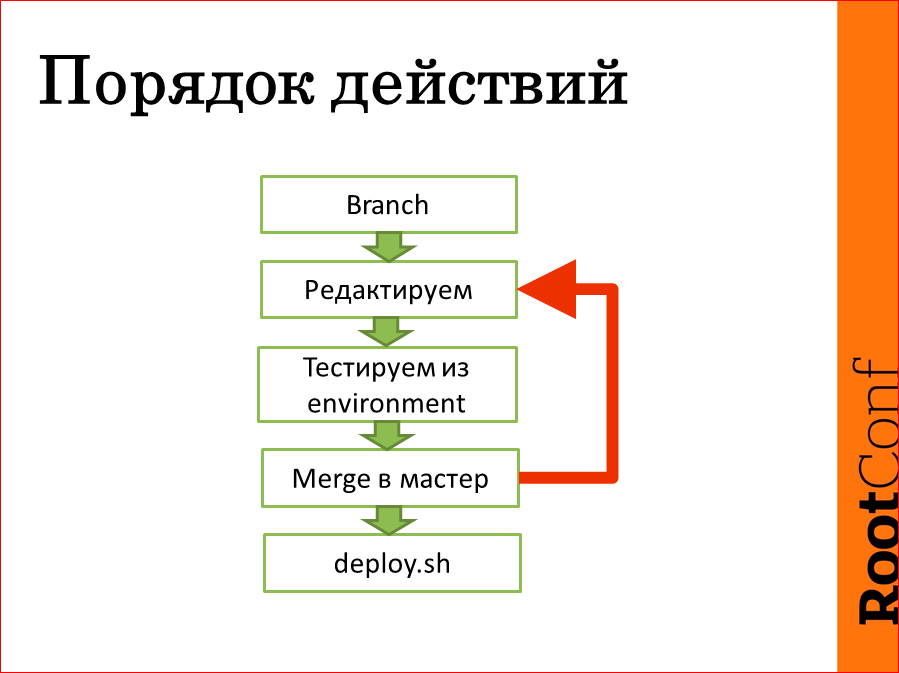
Now we will talk about how we roll out the code in production and, in general, fully and completely cycle.
The full cycle is very simple: we make Branch from the wizard, then we edit our Branch. It may take maybe a day, maybe two, maybe a week, so during the editing of our Branch, we rejoin the master in order to have a chance then, in general, to hold on to it. Then we test everything depending on the host, on the group, etc. in the right positions from their environment and before rolling out in production, merge it into the master, deploy.sh, they drove it all. And if the merge fails, everything returns, loops, and the cycle repeats several times if necessary.

I accidentally stuck this slide here. In fact, the idea was such that I tell you that Puppet is quite a flexible system that can be scaled, and anyone who understood the web project understands that such a scaling system is very simple and can be Puppet. So I think we’ll skip this slide. The only thing I can say is that we use the same DNS name to which we issue the certificate. This DNS name we have is a saneim, so by copying certificates and copying addresses, we can carry along with certificates to any Puppet machines and pick them up at least 200 pieces. And everything else is a standard scalable application.

And now about the alternative - Puppet kick. Remember that I said that we need to know if our system as a whole is relevant when we changed one single piece? In Puppet there was such a thing Puppet kick, which they cut out. She was very scary, to be honest, very uncomfortable and very ugly, but she allowed me to make a calculation on all projects from the master node. Then they changed to Marionette, but with a “microscope for sparrows”, because you can just as easily pull a Puppet agent out of the crown ... or rather a dubious thing, so we made our system, the client, the Puppet server system, an agent, we it was called Puppet kill because of the fact that we have schedulers on the server side and there is a queue of tasks that rolls onto our production; we can regulate simultaneous knurling on a group, i.e. within a group, do not roll more than two servers simultaneously or three. We can regulate knurling on all servers. In general, the standard tasks of the scheduler.
What is the plus? The plus is that this thing can store the name of the node, the status of the last command, the time of the last check, the last update and the time of the last connection, i.e. if our car comes off our Puppet agent, we will find out.
kick, lock - these are service parts, it doesn't matter.
What are the advantages? The advantages are that our scheduler is a web application. Those. production, , . : GIT, , deploy.sh, , «». : , , ?
. , log Puppet'. , – , . , , , , – - , , , , , .. .
Puppet heck, , -t –noop, , , . Those. «» , , . , , , , , , « », « , MySLQ, memcached - ». , , , :
- a) - , ;
- b) , ±4 ;
- c) real time, .. – heck, update .. . , , .

, , Graphite. open source , , – , timestamp, , , , , . : carbon, udp-; whisper ( ceres), ; Graphite-web – .
? , . . , fluxdb. Graphite-web , . , , , .
– carbon, , .

, . , , . , , Graphite TCP-, UDP, , . , target' , , , .., , . , , – 3 , , 4 , , , , , . , , , «» – . , , , , , , , - . – , , .

, , , . , , . – Graphite-nginx-module. Nginx, per location, .. , Nginx rps location', . . Somebody knows?
: log', Logstash Graphite.
, . , log'. , , log', . , log', , , debug', , , log'. log' 1 . . . «» . Good luck!

Graphite , . Graphite : StatsD, StatsD, - event' ( , ), , StatsD, Graphite. , Graphite, UDP, StatsD UDP-, . , .. , , , .
– . - Graphite carbon' , , . , , – carbon'a , . , . , . – carbon. – carbon.
carbon' , :

, carbon . , carbon' , , 15. , , , , «, ». Graphite carbon'.
1-1,2 ., CPU . Totally. , . , , , . - , . , . go-carbon. carbon go. . carbon boost - 3-4. 1.2 . , , carbon, 8 . .

, . . - . -, , , , Puppet, Graphite, , , .
, : Graphite, , , , – , . . , , , . , .
? , . , «-- », . . So what? -? ? , . , – , , . , log' , log' . : timestmp, . , log, errors, info .. . Those. . : « log». log - , .
, , duty , n . , , – SMS .
? , , , , , , , . , , , , , , . , , , - . , :

, , – , ; , – , , Puppet, ; – , , , ; , , , production- – , .
, , – Nginx, go-carbon – open source . , , , , , , , feedbacks, , , .
Contacts
» melazyk
» k.nikiforov@corp.mail.ru
» Mail.Ru
— devops RootConf .
:)
— " - ", , RootConf .
Source: https://habr.com/ru/post/320984/
All Articles