How we prepared the redis cluster
In the world of open source there are a huge number of technologies, approaches, patterns, tools and tools that are used by so many companies. How to turn used software or technology into a competitive advantage? I propose to consider the example of Redis Cluster - how we paved our way.
Start
It is worth starting with the fact that Redis is, in fact, a very handy thing . In a nutshell, Redis is a persistent key-value storage in memory, with its blackjack and courtesans. Most often it is compared with the outdated Memcached, which can do almost nothing of what Redis can do.
Redis benefits:
')
- very very fast data access speed. This is a memo.
- mixed data types, hashes. One key (event), we can put a lot of information (user ID, type of event, time, token, session). These can be bytes, kilobytes, megabytes of data.
- generic TTL. We do not need to delete what we put in Redis. The internal mechanism itself will remove the key, the TTL of which has come. It is incredibly convenient.
- unary operations, increments, decrements - all this works out not instantly, but simply incredibly instantly. Accordingly, in Redis it is convenient and easy to implement complex progress bars, events, put custom data that changes from different places of the system.
- persistence and bin-log. It is possible to periodically flush all the data on the disk, ensuring high availability of data, and almost eliminating their loss.
It turns out that Redis is such a “silver bullet”, absolutely for all cases, approaches and practices? Well, it is. More likely no than yes.
For example, problems that very much interfere with living:
- stendelon . In fact, at the moment, the default installation of Redis is a stendelon. This means that if we have a Single point of Failure, then we have an incredibly bad architecture, because in case of Redis crash, the whole system will stop working.
- flush to disk . This is a very expensive operation, with a high load on the IO, on the memory card. And it’s okay even on hardware - but our service is incredibly dull, because Redis has to fix everything he has there, and make a big Flush from fast memory to a slow disk. At this point, the latency on all services increases to seconds.
The conclusion is obvious - Redis speeds up the product, speeds up development, and it definitely needs to be used, but ... there are problems .
Redis cluster
There is also a Redis Cluster! You say, but I would ask not to hurry. In fact, Redis has 2 types of clustering:
- Redis Sentinel - for older versions
- Redis Cluster - for new versions
Redis Sentinel is a very primitive thing that builds a tree structure of your radish stitches, and calls it a cluster. No sharding, balancing, nothing. And even more so, it works for older versions of Redis, if I'm not mistaken, below 3.0.
Redis Cluster is more fun, there is already sharding, replication, fault tolerance, master slaves, various cool stuff and all that. This is definitely similar to a normal cluster, but still it’s not what it is - it will not work.
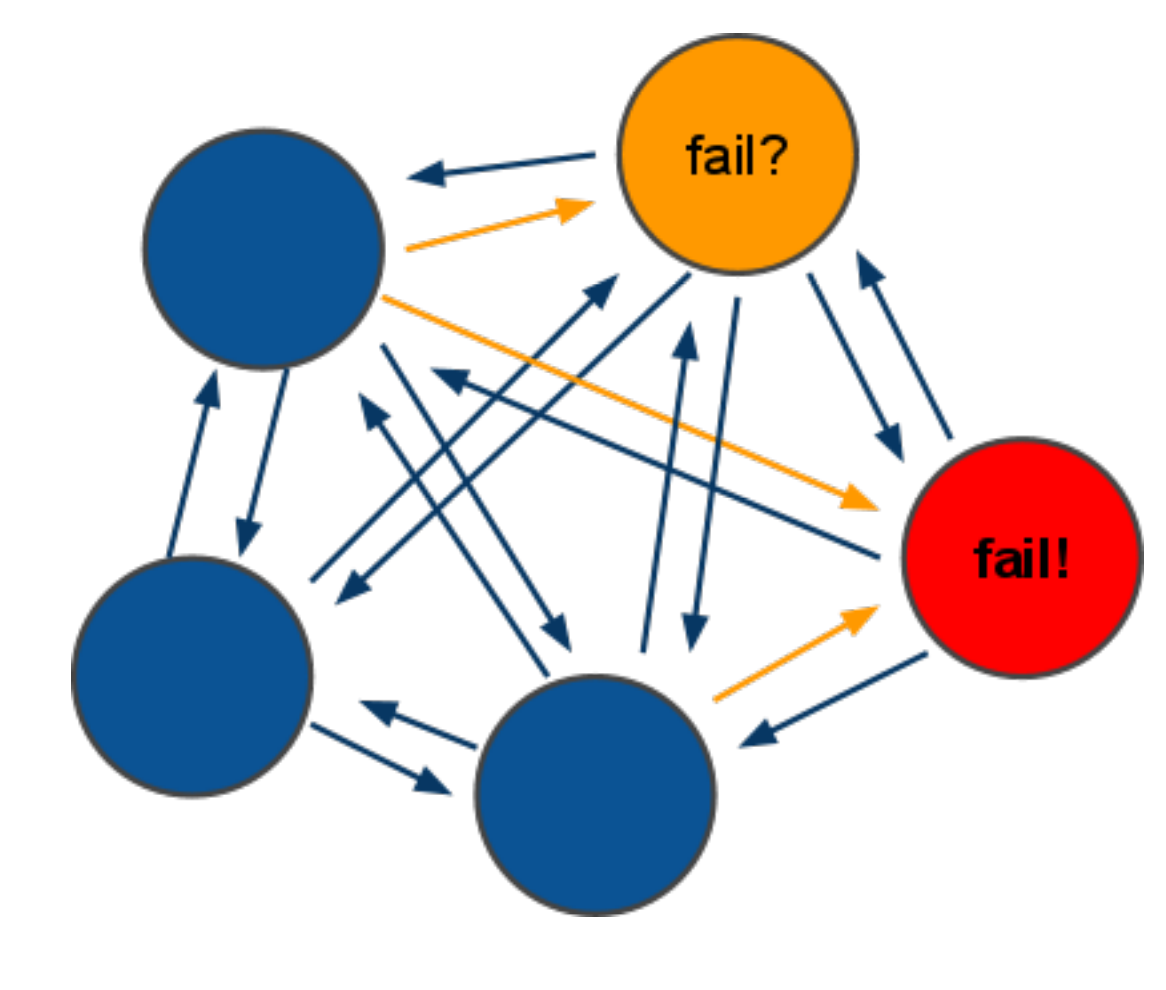
Why it doesn't work
In order to understand why this does not work, you need to understand how it works inside.
First of all, the very process of creating Redis Cluster from stritelon nodes is wildness and humiliation, as it is now. In our 2017, everybody got used to discovery, provisioning and reporting like “I did everything, there is already a cluster, everything is OK!” - but the reality is that Redis has a script written in rubies that does what it takes as arguments radish instances, and then joins them into a cluster. Do you trust such things? I think yes, they trusted, about 100,500 years ago.
Okay, we have a cluster. Now a bit of theory: there are such things as hash slots inside the cluster. In essence, a slot is a number that implies a set of data for which a particular cluster node is responsible. In total there are 16384 slots, which are evenly divided between all the masters.
By the way, about the masters. By default, Redis Cluster can consist of at least three nodes , and all these will be wizards. Accordingly, they will divide the slots among themselves.
The second nuance of using a cluster is incredible fragility. For example, one node fell off from a cluster with 3 nodes. The logical solution would be to continue working - we also have 66.6% of the data, but this is not at all encouraging. In the default configuration, the response will be 'CLUSTER IS DOWN' at the request of any, even a live key.
If we consider a larger cluster, for example, from 6 nodes (3 masters and 3 slaves) - the situation repeats. While there is an automatic promotion of the slave to the master after the fall, the answer is similar - 'CLUSTER IS DOWN'. And this is seconds, although this delay depends on the amount of data in the cluster.
The third problem is customers. More precisely, the connectors are in aplications. If we take the previous case, when we are promoting the cluster, all clients will fall off with socket error, or connection timeout, or something similar, because they keep connection to all masters in the cluster. This also needs to be completed.
The fourth, and one of the most unpleasant, nuance is a change in the set of commands. Standard teams that work on wildcards do not work, and this is not surprising. It needs to be redone throughout the project, to teach the appli- cation how to work with standtelon and with the cluster. In fact, this is the longest and most expensive part of the implementation of the Redis Cluster.
How to make it work
We are unable to fix the first nuance with provisioning, except to do LWRP for Chef, and it is somehow more normal to do it. In fact, something like this we did.
But the second and third - this is our competence!
Fixing 'CLUSTER IS DOWN' in the absence of some slots is very easy and simple - just add the configuration parameter:
cluster-require-full-coverage no The problem with customers who fall off can be solved by spending a little time. Our project uses 2 languages - PHP and Java, so we had to do the same work two times. The general algorithm is as follows:
- We receive on the client of 'CLUSTER IS DOWN' - during reassembly of a cluster
- Ketchim this error, save the existing non-working slotmap.
- Retraim connection, a certain number of times, and we are waiting for a new slotmap.
- When the slotmap has changed - we read our value and rejoice.
Changing the slotmaps will mean that the cluster has moved to a working state, and our data will already be praised by a slave, and it is ready to work with them.
It will be no secret for anyone if I say that in a cluster with 6+ nodes, there is no point in flashing the data to disk. Accordingly, if you disable the persistence - everything will work very, very quickly.
Result

What was the result?
- We have achieved excellent TTFB performance (as we are no longer afraid to store sessions in Redis).
- We succeeded, probably the best progress loader in the world - there is the most up-to-date information (there is nowhere more relevant!)
- We are not afraid for the data that we put in the Redis Cluster and sleep well.
- SLA and User Experience are much improved due to the rapid responsiveness of many parts of the application.
Here we have such an interesting way.
How do you use publicly available tools?
PS If the information was useful to you, and you want to develop in this direction - subscribe to my personal telegram channel: https://goo.gl/1MnG9v
You can always unsubscribe. What if you like it?
Source: https://habr.com/ru/post/320902/
All Articles