Making your Skype with real-time speech translation, only better
 Not so long ago, Skype announced a real-time translation during a video call with an interlocutor. This topic has long given no rest to humanity: many people remember the film “The Hitchhiker's Guide to the Galaxy” and Babel fish. We decided to figure out how to make this creature on Voximplant. Description and demo - under the cut.
Not so long ago, Skype announced a real-time translation during a video call with an interlocutor. This topic has long given no rest to humanity: many people remember the film “The Hitchhiker's Guide to the Galaxy” and Babel fish. We decided to figure out how to make this creature on Voximplant. Description and demo - under the cut. Service Description
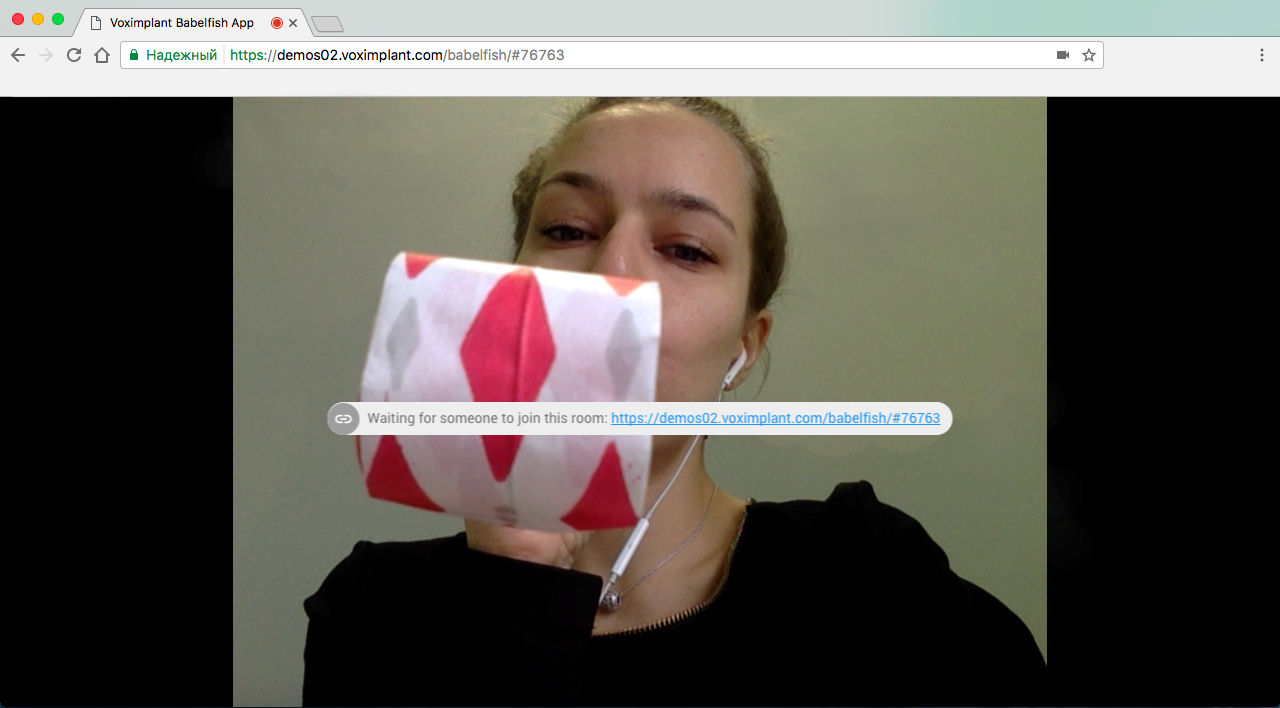
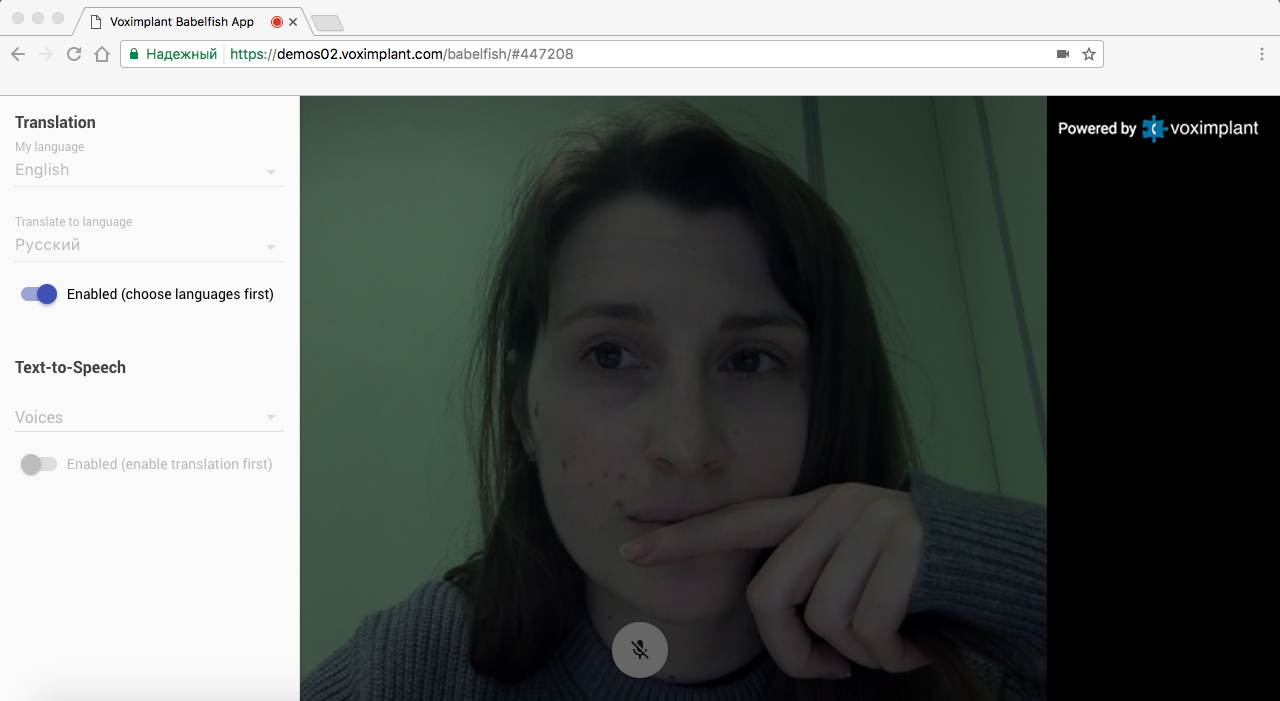
Let's start with the fact that you need to decide on functionality. The idea of the service is quite simple: there is a certain URL, passing through which the user creates a room where he can invite the interlocutor. As soon as the interlocutor connects to the room, a video session is established between the user and the interlocutor and you can begin to communicate. If it is necessary to activate the translation in real time, then pressing a special button brings up a dialogue, selects languages (from which and to which translation will be made), after which the function can be activated. Optionally, you can silence the original sound and force the system to voice the translated phrases using text-to-speech.
Service implementation
As you probably guessed, for the implementation of this service, we need speech recognition, streaming and an interpreter with an API. Speech recognition from Google is already connected to our platform, which supports about 80 languages, streaming from the browser to the platform is done using the Web SDK (which, in turn, uses the WebRTC / ORTC), and we will do the translation using the Google Translate API . The solution scheme will look something like this:
')
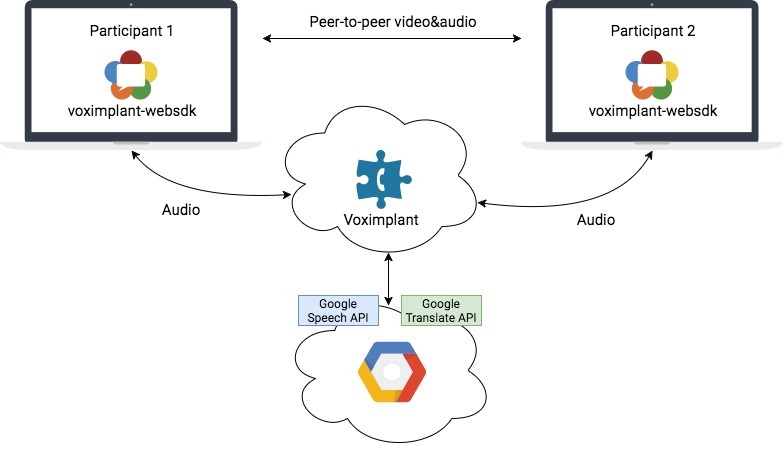
On the Voximplant cloud side, we have a JavaScript script (more precisely, several scenarios) that will be responsible for the service’s logic, including interaction with the Google Translate API via HTTP (integration with the Speech API is already built into the platform and provided through the ASR module ).
VoxEngine scripts and client application
We compiled the client application based on React, TypeScript and Voximplant WebSDK. The code is a bit much, so there’s no point in telling him about it. We give only short excerpts that are associated with the scenario spinning in the cloud. Client logic is as follows:
1. Authorization - we create a user on the fly through the HTTP API and then log in via the SDK .
2. Generate the room code (it is the conference code on the Voximplant side).
3. After authorization we call to the conference (call to the server).
4. Konfa sends clients a list of connected users, using the mechanism for sending messages within a call.
5. Make a P2P call between two participants (by analogy with this tutorial ).
You can read more about speech recognition in one of our previous articles .
Voice of the translation result
If you want the interlocutor not to hear your voice, you can activate text-to-speech - the sound from the microphone in the P2P call will be turned off on your part, and the script will begin to voice the result of the transfer through the server call. Speech synthesis is available in more than 20 languages .
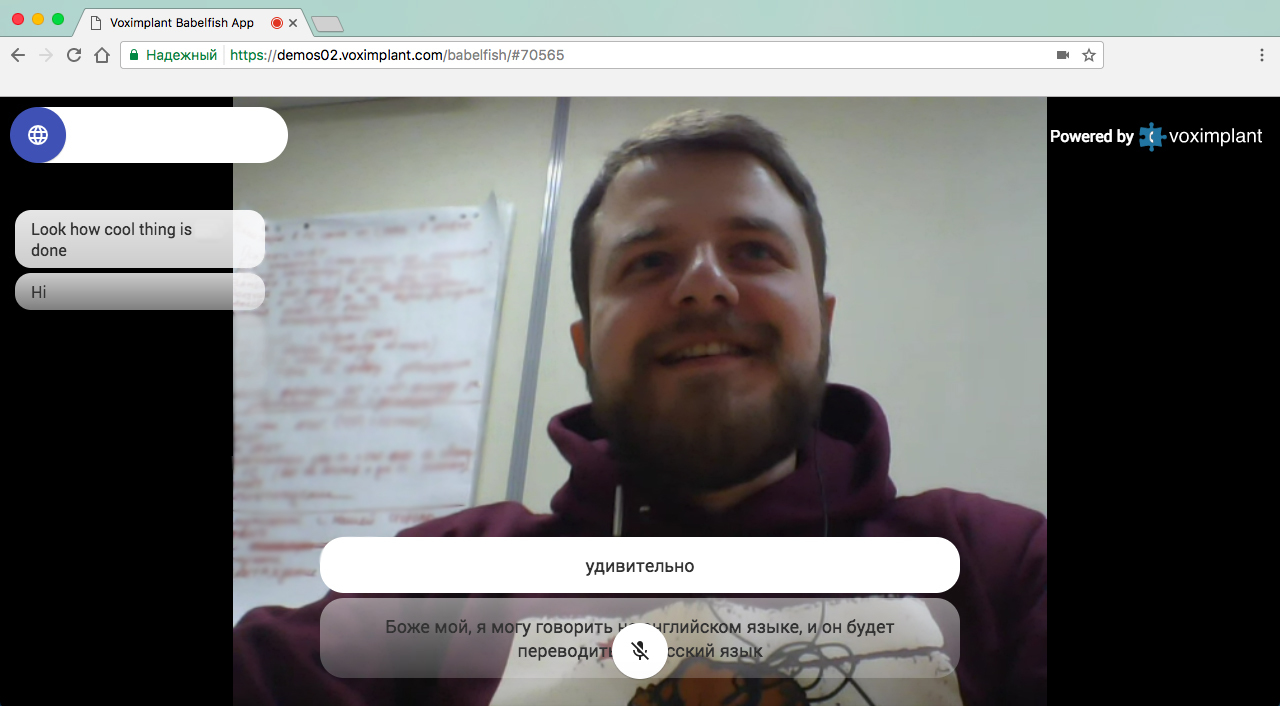
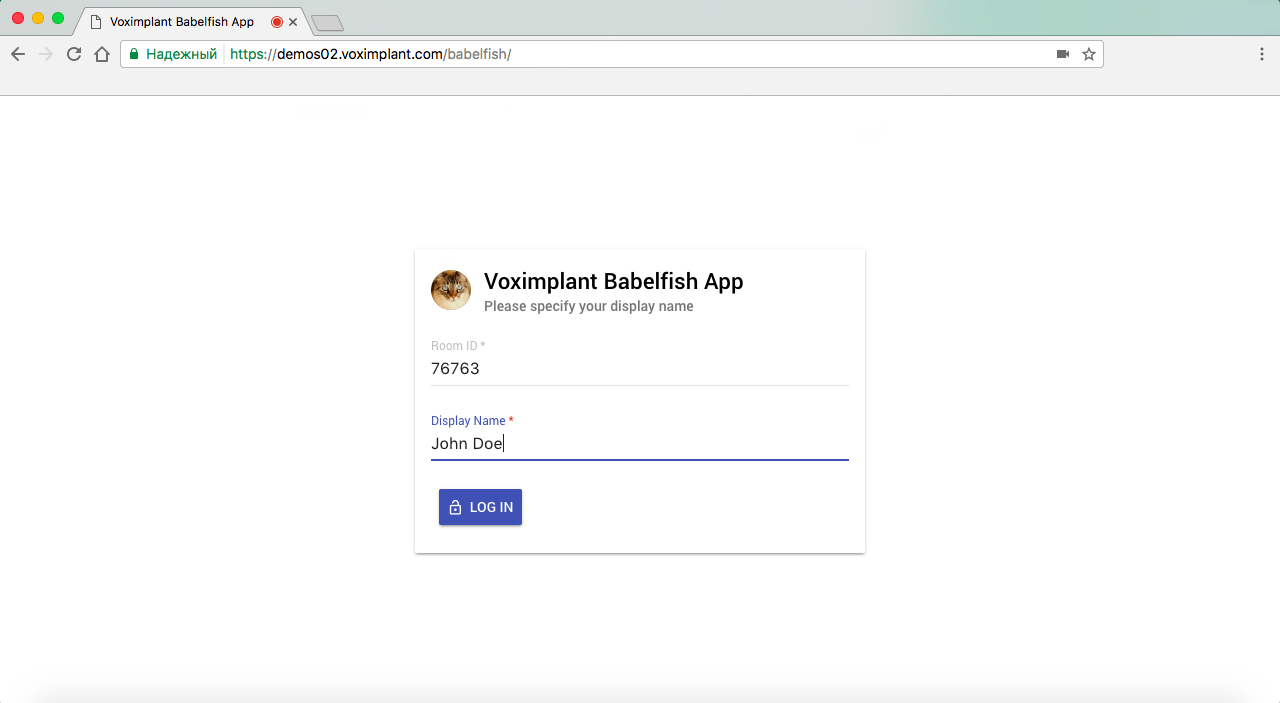
Demo
You can try the service by following the link demos02.voximplant.com/babelfish .
We strongly recommend that you do not try it on the same computer, since the echo cancellation of WebRTC will reduce the recognition quality to the baseboard. There is, however, one workaround - to jam the microphone in one of the application instances (or better in both).
PS Works in browsers Chrome, Firefox, Microsoft Edge. We are pleased to answer any of your questions in the comments.
Source: https://habr.com/ru/post/320828/
All Articles