“The worst practices” of working with backup products on the example of Veeam Backup & Replication
Many have heard about the “best practices” - these are recommendations that should be followed when deploying a system for optimal performance. However, today I want to talk about the “worst practices” or the common mistakes of administrators in the field of backup tasks. Since the users of the products do not always have enough time to read many articles with “best practitioners”, as well as resources to implement them all, I decided to summarize information about what exactly should be avoided when working with backup products. For “bad advice” welcome under cat.

Lack of backup planning and evaluation of backup storage performance is the most common “worst practice”. Many users install a backup product with standard settings by simply pressing the Next button in the product wizards. Moreover, many leave the default settings for backup jobs, not taking into account the infrastructure, the removal policies of old copies and other important aspects. As a result, errors occur when starting and executing tasks, premature filling of the repository and, as a result, pleasant, but time-consuming communication with the technical support service.
What is the right way then? Using the example of Veeam products: in order to avoid such scenarios, it is recommended to use, for example, Veeam ONE - a tool for monitoring and creating reports about infrastructure work before installing Veeam Backup & Replication. So, by opening the VM Configuration Assessment report, you will see if your virtual machines are ready for backup, and if not, for whatever reason. The VM Change Rate Estimation report (estimate of VM change frequency) is based on statistics on changes in virtual machine blocks and allows you to correctly calculate the required repository size.
')

More information about useful for planning reports can be read, for example, here .
Another tool from Veeam — an online recovery point size calculator — will also help when planning your backup environment.
Do you want to fill up all backup tasks due to an error in one of them? Then, rather, combine them into chains of dependent tasks, so that when one task is completed, another begins at once. In this case, you are guaranteed to get an increase in backup windows, delayed start of tasks and other unpleasant consequences.
What is the right way then? In fact, tasks should be merged only in certain cases. For example, if you do not want to backup two applications at the same time, then you can configure the start of the backup of one of them only after the completion of the backup of another application. In the case of Veeam, you better trust the product to plan the resources for you. Veeam Backup & Replication scheduler can run several tasks at the same time to optimize backup windows, using “smart algorithms” to distribute the load on infrastructure components, choosing the optimal data transfer mode and working within the established limits of the channel bandwidth to the repository.
Life experience shows that companies often “save” on backup testing. This may be due to both insufficient awareness of possible problems during the recovery phase, as well as economic factors, since a complete testing process of restoring a system from a backup, if done manually, is a very time-consuming operation. This situation is fraught with negative consequences, because in the event of a failure, critical data may not be restored at a given time or, even worse, may be partially or completely lost.
What happened in 1998 in the real Pixar studio case, when all the working materials of the cartoon “Toy Story 2” were almost lost, you can read in our post “ Pixar Case or again about the importance of backup testing ”.
What is the right way then? Backup recovery testing should be performed regularly. It is necessary to distinguish between testing the integrity of the backup itself and testing the restoration from the backup . In the first case, you only check the integrity of the copy of the checksums of the data blocks. In the second, you are testing to reflect one or another simulated scenario of a single failure or a full-scale “catastrophe” of the productive network. It is extremely important to do not only the first, but also the second, because ultimately you are interested in real data recovery in the event of a failure, and even if the integrity of the backup itself is not compromised, the recovery may fail.
There can be a lot of probable reasons for the unsuccessful recovery, I will give only some of them:
How can these problems be solved? For example, the Veeam SureBackup technology allows you to automatically test virtual machines from backups and ensure that they can be restored. The SureBackup task (see the post “SureBackup - automatically checking the possibility of restoring data from a backup” ) automatically starts all machines, taking into account their dependencies (for example, first a domain controller and only then an Exchange server), in an isolated virtual laboratory, it checks their performance ( including using scripts written by the user) and sends the corresponding reports by email.
And finally, the worst advice on today's topic is specifically on Veeam: start a virtual machine using Instant VM recovery and forget about it. Forget it completely. In this case, you are guaranteed a whole ton of problems. Running the machine directly from the repository will result in locking the recovery point, so other tasks (for example, SureBackup or BackupCopy) simply won't start. This happens due to the fact that the machine is started directly from the backup file in read mode, that is, without writing any changes to the file itself. This creates a separate file on the C: drive of the Veeam backup server, which will grow to an incredible size, if you leave the machine running for at least a few days.
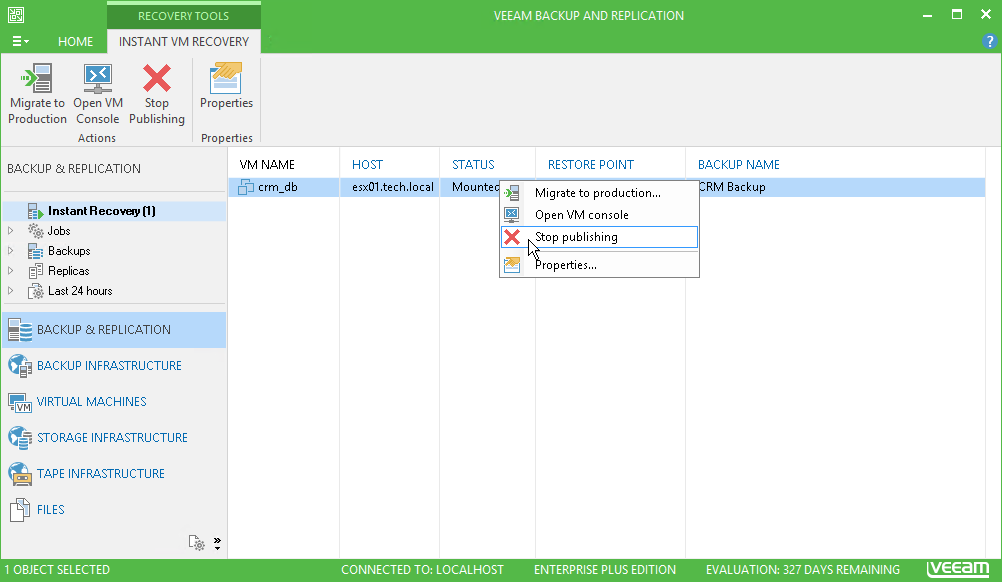
What is the right way then? To avoid this, immediately after the completion of Instant VM recovery, be sure to transfer the machine to the production environment. Learn more about this process in the Veeam User Guide .
I hope this article will help save time, money and get rid of the headaches from the problems described. Have something to add to the list of "worst practices"? Then share it in the comments!
And in conclusion, I provide links to our best posts about best backup practices, whatever product you use:
Run backup tasks with settings that do not take into account a specific configuration
Lack of backup planning and evaluation of backup storage performance is the most common “worst practice”. Many users install a backup product with standard settings by simply pressing the Next button in the product wizards. Moreover, many leave the default settings for backup jobs, not taking into account the infrastructure, the removal policies of old copies and other important aspects. As a result, errors occur when starting and executing tasks, premature filling of the repository and, as a result, pleasant, but time-consuming communication with the technical support service.
What is the right way then? Using the example of Veeam products: in order to avoid such scenarios, it is recommended to use, for example, Veeam ONE - a tool for monitoring and creating reports about infrastructure work before installing Veeam Backup & Replication. So, by opening the VM Configuration Assessment report, you will see if your virtual machines are ready for backup, and if not, for whatever reason. The VM Change Rate Estimation report (estimate of VM change frequency) is based on statistics on changes in virtual machine blocks and allows you to correctly calculate the required repository size.
')
More information about useful for planning reports can be read, for example, here .
Another tool from Veeam — an online recovery point size calculator — will also help when planning your backup environment.
Combine all tasks in chains
Do you want to fill up all backup tasks due to an error in one of them? Then, rather, combine them into chains of dependent tasks, so that when one task is completed, another begins at once. In this case, you are guaranteed to get an increase in backup windows, delayed start of tasks and other unpleasant consequences.
What is the right way then? In fact, tasks should be merged only in certain cases. For example, if you do not want to backup two applications at the same time, then you can configure the start of the backup of one of them only after the completion of the backup of another application. In the case of Veeam, you better trust the product to plan the resources for you. Veeam Backup & Replication scheduler can run several tasks at the same time to optimize backup windows, using “smart algorithms” to distribute the load on infrastructure components, choosing the optimal data transfer mode and working within the established limits of the channel bandwidth to the repository.
Never verify backups
Life experience shows that companies often “save” on backup testing. This may be due to both insufficient awareness of possible problems during the recovery phase, as well as economic factors, since a complete testing process of restoring a system from a backup, if done manually, is a very time-consuming operation. This situation is fraught with negative consequences, because in the event of a failure, critical data may not be restored at a given time or, even worse, may be partially or completely lost.
What happened in 1998 in the real Pixar studio case, when all the working materials of the cartoon “Toy Story 2” were almost lost, you can read in our post “ Pixar Case or again about the importance of backup testing ”.
What is the right way then? Backup recovery testing should be performed regularly. It is necessary to distinguish between testing the integrity of the backup itself and testing the restoration from the backup . In the first case, you only check the integrity of the copy of the checksums of the data blocks. In the second, you are testing to reflect one or another simulated scenario of a single failure or a full-scale “catastrophe” of the productive network. It is extremely important to do not only the first, but also the second, because ultimately you are interested in real data recovery in the event of a failure, and even if the integrity of the backup itself is not compromised, the recovery may fail.
There can be a lot of probable reasons for the unsuccessful recovery, I will give only some of them:
- restoring a system may require additional steps that the backup product does not automatically perform (for example, reconfiguring remote services that interact with the restored system),
- access to the repository of backups from the new laptop of the administrator may be denied (simply because it will be the first attempt of such access - and this will take extra valuable time),
- the low bandwidth of the channel will “hang” the off-site recovery process (when a backup copy needs to be pulled from another office),
- suddenly it turns out that the daily backup for the last six months has constantly increased in size (almost all source systems are constantly growing in size) - and at some point did not fit on the tape, but the error went unnoticed (the above-mentioned Pixar example)
- the old backup may not be restored on the new hardware,
- during recovery, it may turn out that not all files or machines are in the backup job area.
How can these problems be solved? For example, the Veeam SureBackup technology allows you to automatically test virtual machines from backups and ensure that they can be restored. The SureBackup task (see the post “SureBackup - automatically checking the possibility of restoring data from a backup” ) automatically starts all machines, taking into account their dependencies (for example, first a domain controller and only then an Exchange server), in an isolated virtual laboratory, it checks their performance ( including using scripts written by the user) and sends the corresponding reports by email.
Do not complete the instant machine recovery process (Instant VM recovery)
And finally, the worst advice on today's topic is specifically on Veeam: start a virtual machine using Instant VM recovery and forget about it. Forget it completely. In this case, you are guaranteed a whole ton of problems. Running the machine directly from the repository will result in locking the recovery point, so other tasks (for example, SureBackup or BackupCopy) simply won't start. This happens due to the fact that the machine is started directly from the backup file in read mode, that is, without writing any changes to the file itself. This creates a separate file on the C: drive of the Veeam backup server, which will grow to an incredible size, if you leave the machine running for at least a few days.
What is the right way then? To avoid this, immediately after the completion of Instant VM recovery, be sure to transfer the machine to the production environment. Learn more about this process in the Veeam User Guide .
Conclusion
I hope this article will help save time, money and get rid of the headaches from the problems described. Have something to add to the list of "worst practices"? Then share it in the comments!
And in conclusion, I provide links to our best posts about best backup practices, whatever product you use:
Source: https://habr.com/ru/post/320632/
All Articles