Using HAproxy iptables + etcd + confd for automatic service discovery in changeable networks

Sergey Puzyrev (Mail.Ru Group)
My name is Sergey Puzyrev, I am a system administrator in Mail.ru, I am engaged in the “Search” project. Yes, surprisingly, Mail.ru has a search. I love services that do not require attention. I am a system administrator, and I do not like to work as a system administrator very much, I like to do so that there is less work, so I will describe one of the solutions that we are trying to use in our work.
First, I will say a few words about what service-oriented architecture is.
')

Sufficiently large web applications can be built using combinations of a large number of small, fairly simple in nature services that communicate with each other. It is a bit like Unix, only it is not within the same computer, it is within the application. And the principles here are almost the same, i.e. Applications should do few things, but should do them well. They should not be strongly connected with each other, they should use more or less standard procedures of communication with each other.
Applications do not need to know who uses them. Accordingly, if we use static storage, then the storage of static doesn’t matter what lies in it - video, pictures, anything, its task is to just store blobs and give blobs, it doesn’t do anything anymore, and it’s not too smart .
In the same way as in Unix, clients should not know anything about services, about how services are arranged. Again, if we use the static storage service, we simply fill it with it. Storage statics is a tricky thing, but the client doesn’t care, the client wants to put a blob and wants to pick up a blob, where it lies there, how many replication factors will be there, how it will be - synchronously, asynchronously between data centers, how it will be restored to in case of an accident, they don’t care at all; they just want to think about nothing. The developers also do not want to think about anything, i.e. The concept of loosely coupled services allows you to not worry about the internal structure of other components and because of this, the developer is easier. And the developers are also the same people like us, they also do not want to think too much.
Perhaps the fourth point seems a bit obvious, but loosely coupled services, nevertheless, interact and use each other.
Let's look at what a service is.

When I use the word “service,” I mean a more or less isolated application that has three required parts. Well, he has two obligatory parts, the third one is optional.
- Firstly, there must be a protocol for communicating with the service, i.e. what kind of service it provides. This is a key point, the service itself is characterized by the protocol, and not by how it is arranged inside.
- In our case, specifically in our project, it has so historically developed that all services, for the most part, network services work on top of the TCP protocol, not on top of some overlying protocols (it so happens that we have self-written overlay protocols, but in the context of the report is not very significant). Accordingly, each service has an entry point. In our case, it is always a pair of IP + port. In the general case of the service, now it is especially fashionable with all sorts of architectures like REST, this is most often the http entry point, but not the only one, because the service is not necessarily the http service.
- And services can use each other. Here we come to the most important element about what the whole report is about - when one service wants to use another service, this service needs to know where to find another service, and this information needs to be communicated to it somehow.
What we have simple services?
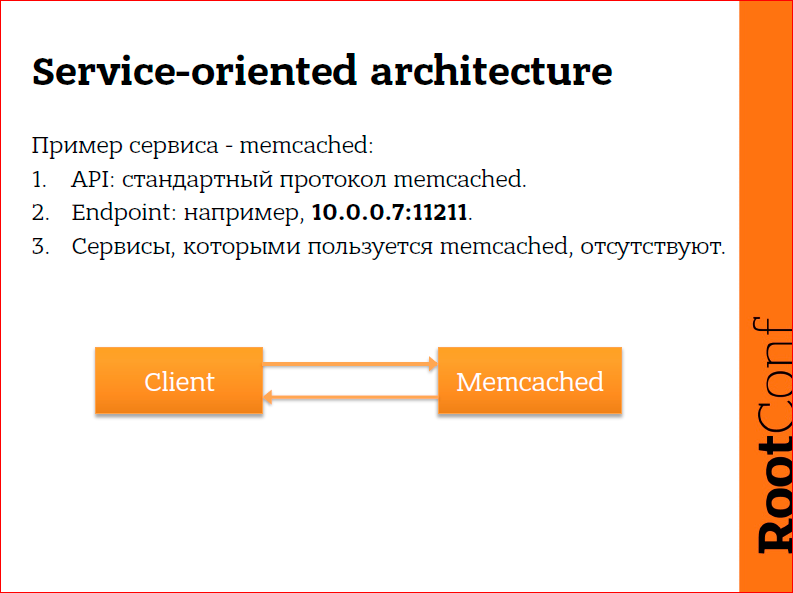
For example, we have a completely stupid service - memcached. I think everyone used it. He works on the memcached protocol, he always has an IP address and port, and he does not use anything, he just started, listens to the port and works, he does not think about anything else. The client communicates with him, the client just needs to know where to tap on TCP or UDP. Memcached, by the way, works on UDP, sometimes it can be convenient. And nothing complicated.
Service a little more complicated.
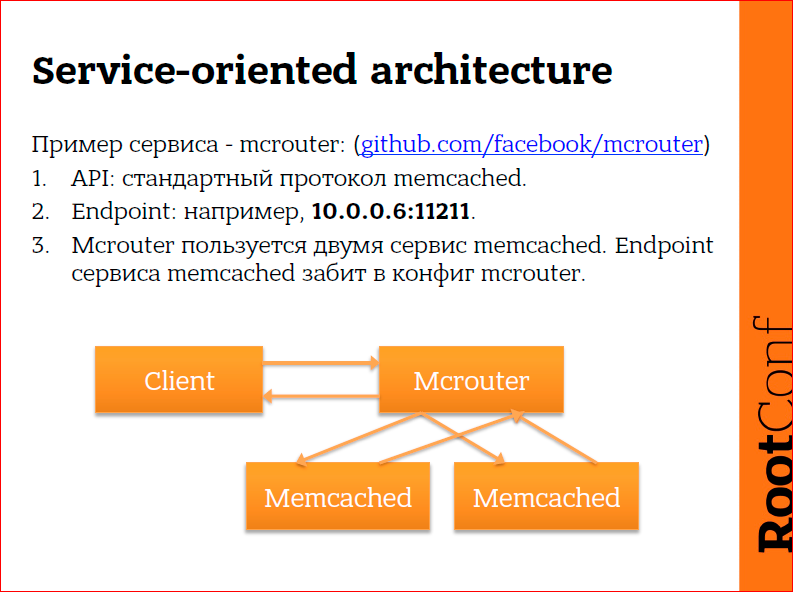
The client wants fault-tolerant memcached. There is such a thing as mcrouter, it was developed by Facebook. Mcrouter allows, for example, to replicate records that go to mcrouter on two different memcached backends. In this case, the client communicates with mcrouter via the memcached protocol and, again, he doesn’t know anything about how mcrouter works further, he doesn’t care how much memcached is there, he just wants to communicate with the memcached service, which will be fault tolerant. Mcrouter, in turn, knows where he has two memcached backends, and he replicates the data there. The client knows nothing about memcached, and mcrouter should know about memcached, but the client should know where mcrouter is located, and mcrouter should know where memcached is located. Those. here we already have three places that need to be configured:
- client must find mcrouter,
- mcrouter should find the first memcached,
- mcrouter should find the second memcached.
Let's go further.

This architecture is actually nothing special, it is any average php site. Nginx, several php nodes, storage statics, often it is external, MySQL master, MySQL slave, under mcrouter (I just love mcrouter, which is why it happened), one memcached server and internal php balancing are often used. But, nevertheless, in this really simple service, which consists of a couple of servers of physical servers, we already have 16 places that need to be configured - nginx should know about php, it should know about where memcached is located with mcrouter, nginx should know where static storage is located ... I will not read the picture anymore, we can count the number of connections between services and see how many places need to be configured and make sure that they are 16 here. And we just have a simple php site .
What will we do when we have a complex application?

This picture is not mine. I have OpenStack at work, we use it, and it is really quite complex. The image is googled by the request "OpenStack diagram", you can calculate for yourself how many places you need to configure. In fact, there are small cheats here, because the approaches that I tell in this report are used in OpenStack, but, nevertheless, there it is very nontrivial and over time to configure tires. To do what? I dont know.
At first we grabbed our heads, then we started thinking how to solve this problem. How services tell how to communicate with each other.

The easiest way is to simply take the configs and write in them where are the services that our service wants to use. Those. In the example with mcrouter, we hammer memcached addresses into the mcrouter configuration file. Very quickly, very easy, nothing at all. Those. Come on, restart, work. We don't have to think about anything else. While we have two physical servers, we are fine. Even when we have 30 physical servers, it’s almost normal for us, they fly out once every two months, and nothing happens to us. When we have 3000, we start having problems, because they never work together. All the time, several pieces are lying, all the time they are somehow broken, somewhere the rack has fallen over the network, somewhere the server has broken down, somewhere some server has to be broken, etc., and panic begins. This is the moment number one.
Moment number 2 - due to the fact that we have a bunch of IP-addresses and incomprehensible ports in configs, all the time is unclear. You go into the config and look: what the hell? And there are numbers and nothing is clear. You have to keep the documentation, and the documentation tends to lag behind reality. And in the middle of the night you broke the application, you go, you try to understand what kind of garbage, you do not find anything, you swear, then you fix it somehow, you cry ... There are some problems.
The third point is when you have a service that is used by 1000 other services, and it suddenly changes, for example, its endpoint (entry point), you need to reconfigure as many as 1000 services so that they now go to another place. And it hurts, because it hurts to reconfigure 1000 seats. It is difficult, in principle, at least what kind of architecture you will use.
Therefore, the trivial solution is to use DNS instead of IP addresses.

Very easy. There is not much difference, just the place we are fixing, the place where we will make changes, we are trying to move from the daemon config we use to the DNS zone.
We, as it were, solve part of the problem, and we create part of the problem in this way. Because you still need documentation that will lag behind reality. It will work better for us than IP addresses in a large project, but only slightly better, because there will be no connection with reality, with what is now working, and what is not working, in the configs. Your racks will also fall, and you will need to go and fix somewhere manually if the software is not fit to live with it. And the software is often not adapted to live with it, especially when the software is 10 years old. For example, in the case of mcrouter and several memcached backends, it is especially hard to add new memcached instances. Or, for example, you want to have replication not two, but three, and you just can not just fix the DNS situation to correct the situation. You still need to go and edit the config, and perhaps not in one place, and then edit the config somewhere else. And the same problems. When there are few servers, there are no problems, when there are many, then there are problems.
Fourth, DNS is out of the box, it is a priori asynchronous, it can never be synchronous, we cannot make changes to the DNS and get a click to make us good. No, even at TTL = 60 sec. we can have this information reach the demons for a few minutes. Therefore, the DNS is also not very suitable for us. We also have such a problem. Because for hundreds of services DNS works fine, for thousands it is already bad.

We all say that we use configuration management systems, it is fashionable. But often, unfortunately, it is clear that they are not used. It would seem that it will save us, but not everything is so good, because the configuration management system, again, solves problems on a large project, but the problem I was talking about is not a problem that is solved by the configuration management system, because Rolling out the system and configuration on thousands of machines takes a lot of time. Konstantin from Mail.ru reported on how Puppet works for them, you can ask how much it takes them to roll out everything. These are not even minutes, but rather hours, and therefore we again cannot quickly respond to changes in infrastructure. This is the moment number one.
Moment number 2. Given that the configuration management system is often a bunch of templates and a bunch of structured information, if you organize templates incorrectly, you can get problems with the expansion in advance. Those. in order for some seemingly trivial place to change, that with endpoint hardcards in configs you could fix very quickly, you will have to rewrite the templates, test the templates, test it in the dev-environment, then roll it out into production. And you will spend half a day on a simple procedure for increasing the number of backends from two to five. Therefore, unfortunately, configuration management systems also do not completely solve this problem.

It seems to me that the main problem here is that the person who commits, who configures is attracted to this whole thing. This is all wrong. In fact, we have robots break, robots exploit each other. I think we are superfluous there. Let's see what we can do.

There are systems for discovering services, they are characterized by several things. First, we introduce two concepts - the service can be registered in the service discovery system, in which case it starts and is registered. After this, another service that wants to use the service that we have just registered goes to the service discovery system and asks: “Do you have such a service, and where is it if you have one?”. The service discovery system tells him: “Look, I have this one,” and the service, who wanted to find out where to go, found out and went where he needed. Or did not go if I could not.
This is very similar to DNS, but it is not quite DNS, rather, it is not DNS at all. It so happened that, historically, a service detection system (there are quite a few, below is a list of several pieces that exist in principle) also often work as means of distributed locking, and using them, respectively, is necessary with this in mind.
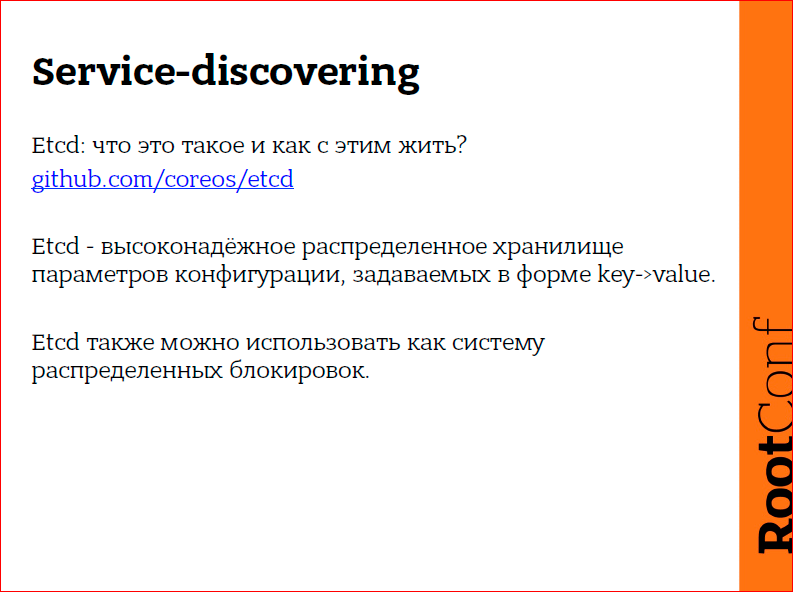
I'll talk a little specifically about the stack of software, which will be discussed further. What is Etcd? Etcd is a special data warehouse, which is strictly consistent, transactions are performed only on the entire cluster at once, more precisely, on the cluster quorum, and therefore they are strictly serialized. It is impossible to make changes to the cluster, when we do not have a quorum in either half, it is impossible. Etcd works according to the Raft algorithm. The Raft algorithm is a look at Paxos, if someone has heard about Paxos, and an attempt to make Paxos easier. Unfortunately, Raft is still quite complicated, so I will leave its description outside of this conference, it’s just too long. But, nevertheless, how does etcd work? On each server we have running the etcd daemon that communicates with the rest of the etcd daemons using the primary login. Those. we run etcd on each server, and we must specify at least one etcd cluster already in the cluster, then they will find each other. This whole magic is protected in etcd. And next time they will already know how to start. And when we need to communicate with the service discovery system, namely etcd, we will always communicate with the local loop. Those. etcd will always add a local loop on any server that we, in principle, have.

The next piece of the puzzle is Confd. Confd is a etcd listener, i.e. etcd stores keys and allows these keys to be changed. Confd allows you to pick up the key and track changes in etcd. This is done via http long polling, i.e. configd is actually an http client, and etcd is an http server. Confd asks etcd: “Look, there is such a key, I want to follow it,” and hangs himself in long polling. As soon as someone else wrote or modified this key in etcd, updated it, whatever, etcd terminates the connection and gives an answer. Therefore, the reaction occurs very quickly. Those. if a transaction occurs, the connected confd will immediately know about it. So etcd is used as a message bus.
Confd is able to respond to changes in etcd and run something. Initially, it was adapted to take data from etcd, templify, enclose the config and restart the daemon. But in fact, it can just jerk some script that will do more complex logic, if what you can stuff into confd doesn't work by itself. And considering that etcd is just http, it’s quite possible to live with it by talking to fget or any other favorite http client, on Python, on anything. You can write these little scripts on anything, do not use confd, if its logic does not suit you. We just used it, it happened.
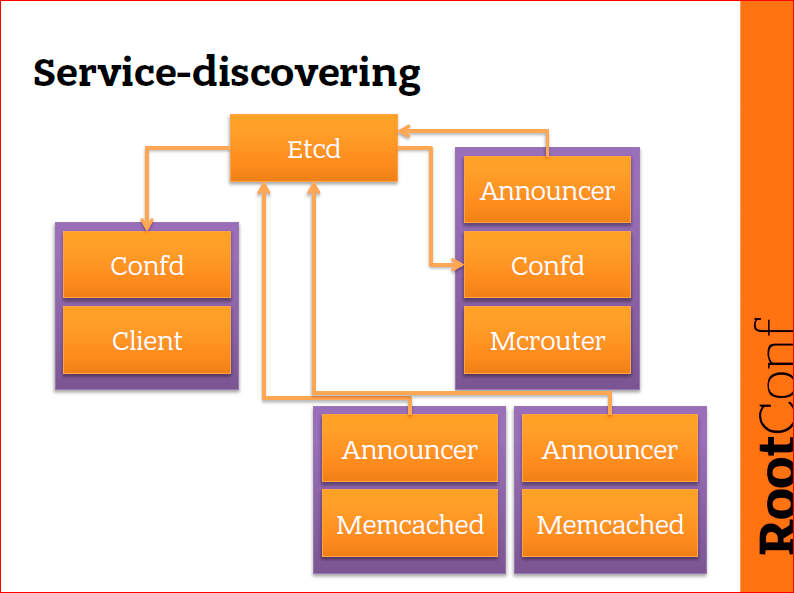
How does this work approximately? Here is the very scheme with the client, mcrouter and memcached. What's happening? I drew etcd separately, because you don’t need to draw it in every place, and etcd is present on all machines. Every machine we have has etcd. And every time we communicate with etcd, we communicate with the loop. It is important. Some machines have confd. Confd is not present on memcached, confd is responsible for what it reads in etcd data and configures a daemon configured on the local machine. Those. cars are purple rectangles, and orange rectangles are demons that are running on machines. A client is some kind of abstract client, it can be a service, it can be some kind of our application, but it wants to use mcrouter. Mcrouter, in turn, is a client to memcached. So we have different types: we have a client, we have mcrouter, memcached and, in addition, we have common components - confd and announcer.
What happens next? When memcached starts, a small bash script runs next to it and tries to determine the endpoint at which memcached is available. He takes this line, i.e. endpoint of this memcached (announcer knows where memcached is running) and writes to etcd: “Hi, I am memcached, I am available here.” The second memcached does exactly the same and writes: “Hi, I am also memcached, and I am available here.” And now in etcd there are two entries about memcached available: memcached 1 and memcached 2, and they have different IP addresses, because they are different machines, and in etcd there is already information about this. After that, we have an old mcrouter. On mcrouter there is also a announcer who tells where mcrouter is available. Etcd is not one machine, it is a cluster service, the instance of which is located on each machine. Confd reads from etcd what the announcer memcached wrote there. After that, confd finds out that memcahed is available at these two addresses and configures mcrouter so that mcrouter goes to these memcached. Further, if one of these memcahed falls, a key will appear in etcd after a few seconds, and this record will disappear. Confd, which keeps track of keys in etcd, recognizes this and reconfigures mcrouter so that mcrouter stops using dead memcahed. If a third memcahed appears, then confd, again, will know about it, because confd on mcrouter tracks changes to all keys in etcd, well, conventionally, memcahed *. Those. as soon as at least some memcahed appears, the confd on mcrouter will recognize and reconfigure mcrouter. For the client, this whole thing happens transparently, he just communicates with mcrouter, and the client in turn learns how to communicate with mcrouter with the help of the same etcd. It works like this. On a fairly simple case.

Of the benefits here - it works really fast. Those. it happens instantly. In the case of memcahed and mcrouter, this will happen in less than a second, because all these demons are very quickly restarted. And if we have no problems with connectedness, the cluster is not broken, and everything is normal, then we don’t need to remember where these memcaheds are located, we don’t care where we start, and they immediately appear in the cluster, there Immediately there is a load. And as an admin, I become happy, joyful from this, I want to jump and run from happiness.
In addition, I do not even need to think about the documentation, because I do not need to write down what I have and where I work. I have always already recorded that where it works. I always see it, because the documentation comes from what is where it is running, and not vice versa. Those. initial launch, not documentation. And in the case when we work with hardcodes, first we have hardcodes, and then we run.
There are, of course, several drawbacks, they are written, I think, they should not even be commented on, because the system really becomes complicated and it becomes really scary what to do if it all falls apart and we have a nightmare with a data center.
There are two points here. The first point is complexity. The complexity is not so terrible, especially considering that we have a lot of services. The difficulty with the hardcode, the complexity with the DNS is much higher, because here we have once set up, and after that the routine operations of moving services to the service stop, to the start of services, adding, changing - they become almost free, and we do not rule DNS zones , we do not rule configs, we are not afraid to copy-paste tsiferki from one place to another, it all works. Therefore, on the one hand, it is difficult, but on the other hand, it is actually simpler, because time is notable saving.
Secondly, scary. Of course, it’s scary, all of a sudden this whole thing will disappear and the kirdyk will come to her. Here, etcd saves us so much happiness that even if there is a complete crash of everything that can be assumed, etcd remains available for reading. It is not possible to write to the broken cluster; you can read the latest changes from the broken cluster, which have flown to the broken part of the cluster. Each etcd node always keeps a complete dump of all the data we have. Etcd does not shardit data, and even if the machine has all the network interfaces down, what it got in etcd, while it was in a cluster, remains on it. If your data center has fallen off, then you will still have quorum in the cluster in the part of data centers that you have all together, and you can even write there if you are lucky. Well, at least you can read from there. Despite the fact that changes occur frequently, they do not occur every two seconds, so even if everything falls apart, we are still more or less normal.
And there is one more minus, this is the third point - that it is necessary for demons in a good case to be able to work with etcd natively. This usually happens better because many demons do not like reloading, because we can make mistakes in the patterns with which confd will configure our demons, we can make mistakes somewhere else. If this is a code that is sewn right into our services, it will work more stable and better. This is desirable because if it were necessary, such things as confd and announcer scripts would not appear.

We tried to solve several problems, and in fact the service-discovering system in the form in which I described it cannot completely solve our problems. There are a few points.
Our application in the search starts, reads 40-200 GB in RAM, locks it in memory, and then, finally, starts listening to the port, and starts working with it. And so it lives for a long time. We have few records, we have a lot of reading. This is a search engine, it is clear that the search knows almost nothing about when clients work with it. But, unfortunately, because of this type of life, the demon starts five minutes here. Accordingly, if some small thing changes with me, I can’t afford five minutes of service downtime, no way, because they all will restart at the same time - I specifically achieved that they are all fast, and now they all quickly themselves restarted, I can't live like this. This is the first problem. The situation with confd and the constant restart of the demons is bad, we can not afford it.
The second problem, as in any long-living project, and Search Mail.ru has existed since 2008, there is a sufficient amount of code that no one wants to intercept. The developers quit, etc. And, accordingly, we cannot teach some of our demons to work with etcd. Some can, which are in hot development.
This is one of those two problems that we cannot solve ourselves.
The third point is the task that we wanted to solve, so that we did not need to reconfigure thousands of places.
We seem to be getting better, but we have the first point, according to which we cannot restart anything.
And one more thing, this is a general requirement for any system - we should not become worse from the moment we implement it. If we now use hardcode and DNS, then if we implement a service discovery system, we should not get a degradation in reliability, compared to what we have. Therefore, we went further and began to introduce new good crutches.

We started to think and decided to make a little bit clever service, such that the applications or our services, the clients did not need to change the type of connection with any other services, servers at all. In different contexts, the same service can be both a client and a server.

This scheme you have already seen. This is how it lives in our normal mode, and in this case confd configures our client. The client is the application that I do not want to reboot.
And so we decided to do this:

We add HAproxy between the client and mcrouter. Again, the client and mcrouter are some abstract examples; you can actually stick anything here.
What we get from this profit? Client communicates with HAproxy. HAproxy listens to the loop, in the client's config we are crammed, that memcached is available at 127.001: 11.211. Always, everywhere, on any server that wants to use mcrouter. We have HAproxy running, which listens to the loop, and the loop is always clogged in the config. Confd, in turn, configures no longer a client, confd configs HAproxy, HAproxy listens to the loop and proxies these calls to the real mcrouter. Where is the real mcrouter, HAproxy learns from confd, confd, in turn, from etcd.
Here, it seems to me, nothing much more difficult becomes. Immediately the question: why is there no HAproxy on mcrouter in order to communicate with memcached using HAproxy? In fact, it can be inserted there, but mcrouter is smart and works higher than the TCP protocol, it fits into the memcached protocol, and therefore, mcrouter, unfortunately, has to be configured manually. But mcrouter almost does not store the state, so the restart is not terrible for him. We can easily rebuild demons that do not store states, and they quickly start. We cannot rebuild the demons that store states, because they start a long time. And in general it hurts. Therefore, we stick a crutch in the form of HAproxy to them.

Why did we do that? Because we could not do anything. Now we can not rebuild and we can rebuild only HAproxy, it's free. It is conditionally free, but much more free, than five minutes of a demon’s downtime due to a change somewhere in some small configuration.
Secondly, given that there are a lot of services and a lot of different code, you need to configure a lot, and these templates are confusing to write to confd too. Once writing all the templates for HAproxy is much simpler, and then we don’t think about anything, we just fill in the loop everywhere. For memcached, this will be port 11.211, for MySQL, this will be port 33.06, but all applications always communicate with the loop. They generally do not think about anything. We don't even need to reconfigure anything anywhere.
Thirdly, HAproxy has wonderful reports from which statistics can be taken, which is often difficult to get from the application, we got it for free, it was not the goal, but it could suddenly be used and it helps.
Fourthly, HAproxy is not just a proxy, it is also a balancer. If we have simple demons that require balancing, which can be implemented using HAproxy, we can get it for free.
And additional buns - timeout on connections, additional active checks of connections to backends. This is all in HAproxy, and we don’t need to build it into demons that communicate using non-standard protocols that aren’t even at all http.
But there is a problem, HAproxy does not know how to UDP, and UDP daemons exist. Konstantin talked about Graphite, Graphite works on UDP, he can TCP, but when there are many metrics, TCP is a strong overhead here, and HAproxy in UDP does not know how to do it. Therefore, we use DNAT.

DNAT has the same functionality, if necessary, it can conditionally replace HAproxy in this case, but it does not have any additional HAproxy buns. Therefore, it is possible to live and use it with it. If we really have a problem with the performance of HAproxy, for example, then we can insert DNAT instead of HAproxy for TCP, but in this case all the problems of TCP, connections, timeouts and all that I’m talking about should still be solved by the client, if we use TCP mode. Here is an example with statsd and Carbon for Graphite, when one communicates with one another via UDP. And here many components are not indicated like annauncer'ov, simply because they do not fit into this scheme, the screen is small, and the hands are big.

Why are we all doing this? It has become almost painless to move services between different places. Mail.ru networks have an interesting feature - if you need, conditionally, to pull the server out of one rack and put it into another, then I need to reconfigure the network for it. I can not do otherwise. Therefore, I have these painful procedures. Even just taking one memcached on one server, raising it on another, and so, to replace, I still need to reconfigure the network. This is how our network works. We solved this task with the help of this tool, and in general it becomes much simpler because we do not need to go and edit 25 network configs and then another 1000 configs and demons.
The second point is that when we have mcrouter or some other demon of a similar role, there are several memcached under it and memcahed suddenly need to do more. These things are not solved with the help of DNS, in principle, but with the help of etcd they are solved, because we can write the right templates and correctly decompose the data in etcd when the demons start, so that the pools expand and our fords are silky.
The third moment is an additional moment that we got for free. There are a lot of demons, something was launched 35 years ago, and we don’t know about it, it’s not in monitoring, there’s no documentation, we only find it when it falls. If everything is stuck in etcd, then we always see who communicates with whom. Secondly, if we have HAproxy, we also see how much it communicates. We get all the metrics for free. Thirdly, in this case, we have separated the moment of configuring the daemon that is running and the configuration of the client daemon. No, they are just combined, in the usual case they are combined, because of this we can simply take a seal in the port when we configure the client daemon and get the problem.
This is not a fictional case. I ran into this case two days ago. My admin just made a mistake and introduced another port. On 10 servers, it rolled out, the service began to degrade, and we started to feel sad. This happens because people are not perfect, it happens. But if we use robots, then robots, if properly exploited, are much more advanced than humans, if we follow them correctly. And when we have a new service, only in this case we need to configure something manually. If we reconfigure the old services, everything happens automatically, and we do not need to constantly commit, manually, restart, monitor hard and so on.
Contacts
» S.puzirev@corp.mail.ru
» Mail.Ru Group company blog
— devops RootConf .
- HighLoad.Guide — , , , . 30 . !
— " - ", , RootConf . !
Source: https://habr.com/ru/post/320524/
All Articles