Accelerate data transfer to localhost

One of the fastest way interprocess communication is implemented using shared memory (Shared Memory). But it seemed to me not logical that in the algorithms I found, the memory still needs to be copied, and after restarting the client (and it was allowed only one), the server must also be restarted. Taking the will into a fist, I decided to develop a full-fledged client-server using shared memory.
And so, first you need to determine the functional requirements for the client-server being developed. The first and main requirement: the data should not be copied. Secondly, "multi-client" - several clients can connect to the server. Third, customers can reconnect. And fourth, whenever possible, the software should be cross-platform. From the requirements imposed, we can distinguish the components of the architecture:
- component that encapsulates work with shared memory;
- memory manager (allocator);
- a component that encapsulates work with a forwarding data buffer and
implementing the ideology of "copy on write" (hereinafter CBuffer); - interprocess mutex;
- interprocess conditional variable or its analogue;
- and directly the client and server.
There are a lot of problems with shared memory. Therefore, we will not reinvent the wheel and take the boost.interprocess to the maximum. First, let's take the classes shared_memory_object, mapped_region, which make it easier for us to work with shared memory in linux and windows. From there, you can take the implementation of IPC semaphore - which will perform the functions of both mutex and conditional variable. We also take as a model for CBuffer, a boost implementation of std :: vector (When working with shared memory, you cannot use pointers, only offsets. Therefore, std :: vector + allocator will not work for us). Even in boost, you can find an implementation of interprocess deque, but I did not find how to use it when developing a client server. And there was only a question with the memory manager (allocator) for shared memory. Naturally, he is in boost, but he is focused on solving other problems. Thus, from boost, libraries that do not need to be compiled (header only) will be taken. Although the boost under MSVC may not agree with this point of view, so do not forget about the cudgel - the BOOST_ALL_NO_LIB preprocessor prohibits the use of “pragma comment". (Memories from the night monologue: “What the hell are linked to the boost!”)
')
Client and server implementation
Implementing data transfer between clients and servers is rather trivial. It is similar to the implementation of a supplier-consumer model (producer-customer) using semaphores, where the “transmitted” message is the offset (address) of the transmitted buffer, and the synchronization objects are replaced with their interprocess counterparts. Each client and server has its own displacement queue, which plays the role of a receive buffer and a semaphore, which is responsible for notification of a change in queue. Accordingly, when the buffer is sent to another process, the buffer offset is put in the queue, and the semaphore is released (post). Then another process reads the data and captures the semaphore (wait). By default, the process does not wait for data to be received by another process (nonblock). An example implementation can be taken from here . In practice, in addition to the transfer of the buffer itself, it is often necessary to also transmit identifying information. This is usually an integer. Therefore, the ability to transfer a number has been added to the Send method.
How do clients connect to the server?
The algorithm is quite simple, server data is strictly on a certain offset in the shared memory. When the client “opens” the shared memory, it reads the structure at the specified address, if it does not exist, then the server does not exist, if it does, it allocates memory for the client data structure, fills it, and raises an event on the server indicating the offset to the structure. Next, the server adds a new client to the linked list of clients and raises a “connected” event in the client. Disconnection is done in a similar way.
Connection state evaluation
Checking the status of the connection between the client and the server is built like TCP. With a time interval, a packet of life is sent. If it is not delivered, it means that the client has collapsed. Also, to avoid possible deadlocks due to a “collapsed” client that did not release the synchronization object, the memory for the life packet is allocated from its own server reserve.
Memory manager implementation
As it turned out, the most difficult task in implementation like IPC is the implementation of a memory manager. After all, he should not only implement the malloc and free methods on one of the known algorithms, but also prevent leakage when the client crashes, provide the ability to “reserve” memory, allocate a memory block at a particular offset, prevent fragmentation, be thread-safe, and cases of absence of free blocks of the required size, expect it to appear.
Basic algorithm
The basis of the implementation of the memory manager was taken Free List algorithm. According to this algorithm, all unallocated blocks of memory are combined into a one-way linked list. Accordingly, when allocating a block of memory (malloc), the first free block is searched, the size of which is not less than the required one, and is removed from the linked list. If the size of the requested block is less than the size of the free, then the free block is divided into two, the first is equal to the requested size, and the second is “extra”. The first block is a dedicated block of memory, and the second is added to the list of free blocks. When freeing a block of memory (free), the block to be released is added to the free list. Next, the adjacent free memory blocks are combined into one. The network has a set implementation of a memory manager with the Free List algorithm. I used the heap_5 algorithm from FreeRTOS.
Algorithmic features
From the point of view of developing a memory manager, a distinctive feature of working with shared memory is the lack of "help" from the OS. Therefore, in addition to the list of free memory blocks, the manager is also obliged to save information about the owner of the memory block. This can be done in several ways: to be stored in each allocated block of PID process memory, to create a table “offset of allocated block of memory - PID”, to create an array of allocated blocks of memory for each PID separately. Since the number of processes is usually small (no more than 10), a hybrid decision was made, an index (2 bytes) of the displacement array of allocated memory blocks was stored in each allocated memory block, each PID has its own array, which is located at the end of the “process block” (in this block contains information about the process) and is dynamic.
The array is cleverly organized; if a memory block is allocated by a process, then the cell stores the offset of the allocated memory block; if the memory block is not allocated, then the cell contains the index of the next “not allocated” cell (in fact, a simply connected list of “free” cells of the array is organized, as in the algorithm Free List). Such an algorithm of the array, allows you to delete and add the address in constant time. Moreover, when allocating a new block, it is not necessary to look for the table corresponding to the current PID, its offset is always known in advance. And if you keep the offset of the "process block" in the allocated memory block, then when you release the block, you also do not need to look for the table. Due to the accepted assumption about the smallness of the number of processes, the “process blocks” are combined into a one-way linked list. Thus, when allocating a new memory block (malloc), the complexity of adding information about the owner is O (1), and when freeing (free) the memory block O (n), where n is the number of processes using shared memory. Why not use a tree or hash tables to quickly find the offset of the "process box"? The array of allocated blocks is dynamic, therefore, the offset at the “process block” may change.
As stated above, for the operation of the “client-server” it is necessary to add the ability to “reserve” memory blocks. This is implemented quite simply, the backup memory block is “allocated” for the process. Accordingly, when it is necessary to allocate a block of memory from the reserve, the backup block of the process is released, and then the operations are similar to the usual allocation. Further, allocating a block of memory at a given address is also easy, because Information about the cast blocks is stored in the "process block".
With such a large amount of constantly stored service information, memory fragmentation may occur due to different “life” of blocks, therefore in the memory manager all service information (long lifetime) is allocated from the end of the area, and the allocation of “user” blocks (short lifetime) at first. Thus, service information will fragment the memory only in the absence of free blocks.
The memory structure is shown in the figure below.
Memory structure
And what happens if one of the processes using shared memory crashes?
Unfortunately, I did not find a way to get an event from the OS “process ended”. But it is possible to check whether the process exists or not. Accordingly, when an error occurs in the memory manager, for example, the memory has run out, the memory manager checks the status of the processes. If the process does not exist, then on the basis of the data stored in the “process unit”, the leaked memory returns to the turnover. Unfortunately, due to the lack of an event “process ended”, a situation may arise when the process collapsed at the time of owning the interprocess mutex, which naturally leads to the lock of the memory manager and the inability to start the “wipe”. To avoid this, the header of the mutex is added to the header. Therefore, if necessary, the user can call the test forcibly, say every 2 seconds. (watch dog method)
Due to the use of “copy-on-write”, a situation may occur when several processes simultaneously own the buffer, and according to the law of meanness, one of them collapsed. In this case, there may be two problems. First, if the failed process was the owner of the buffer, it will be deleted, which will lead to SIGNSEV in other processes. The second, due to the fact that the collapsed process did not reduce the counter in the buffer, it will never be deleted, i.e. there will be a leak. I didn’t find a simple and productive solution to this problem, but, fortunately, this situation is rare, so I made a strong-willed decision, if there is another owner besides the fallen process, then to hell with it, let the memory leak, the buffer moves to the process that started the cleanup.
Usually the memory manager returns NULL or throws an exception if there is no free block of memory. But we are “not interested” in the allocation of a memory block, but in its transfer, i.e. the absence of a free block, does not mean an error, but about the need to wait until another process releases the block. Waiting in a loop, it usually smells bad. Therefore, the manager has two selection modes: classic, if there is no free block, returns NULL and waiting, if there is no free block, the process is blocked.
Implementation of the remaining components
The basis of the implementation of the remaining components is boost, so I’ll only focus on their features. A feature of the component that encapsulates the work with shared memory (hereinafter CSharedMemory) is the presence of a header with an interprocess mutex for synchronizing the methods of working with shared memory. As practice has shown, one cannot do without it. Since usually the size of the data buffer does not change or only changes from the beginning (for example, inserting a header into data buffers for transmission over the network.) The memory reservation algorithm in CBuffer is different from the memory reservation coefficient algorithm in std :: vector. Firstly, in the CBuffer implementation, the ability to set the reserve first is added, by default it is 0. Secondly, the memory reservation algorithm is as follows: if the size of the allocated block is less than 128 bytes, then 256 bytes are reserved, if the data buffer size is less than 65536, then it is reserved buffer size plus 256 bytes, otherwise buffer size plus 512 bytes is reserved.
A few words about using sem_init in Linux
The main sources give a not entirely correct version of the program code for using sem_init between processes. In Linux, you need to align the memory for the sem_t structure, like this:
(_sem_t*)(((uintptr_t)mem+__alignof(sem_t))&~(__alignof(sem_t)-1) Therefore, if your sem_post (sem_wait) returns EINVAL, try to align the memory for the sem_t structure. An example of working with sem_init .
Total
The result is a client-server, the transfer rate of which does not depend on the amount of data, it depends only on the size of the transmitted buffer. The price of this - some restrictions. In Linux, the most significant of these is the “leakage” of memory after the “completion” process. You can delete it manually or restart the OS. When used in windows, the problem is different; there, the shared memory on the hard drive “leaks” if it has not been deleted by calling the server class method. This problem is not fixed by restarting the OS, only by manually deleting the files in the boost_interprocess folder. Since I sometimes have to work with old compilers, the boost version 1.47 is in the repository, although with the latest versions, the library works faster.
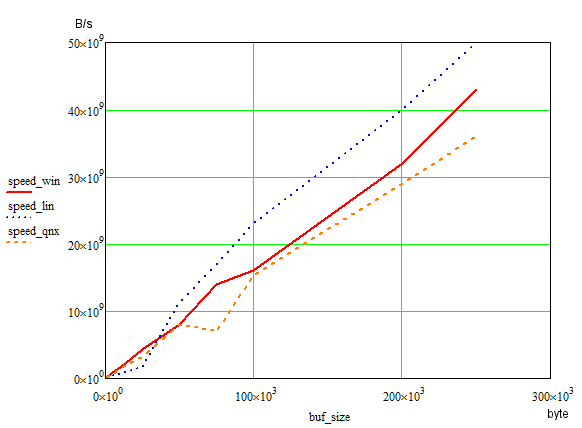
The test results are presented on the graph below (Linux and QNX were tested in the VMBox virtual machine)
Where to get the source?
The source code for the stable version is here . There are also binaries (+ VC redistributable) for quick launch of the test. For fans of QNX, the source has a toolchain for CMake. I remind you, if CMake does not compile the source, clean the environment variables, leaving only the directories of the target compiler.
And finally, a link to the implementation of LookFree IPC using shared memory.
Source: https://habr.com/ru/post/320508/
All Articles