RIGHT kitchen
Good afternoon, colleagues. Here came the turn of the third article on the Security Operations Center.
Today's publication covers the most important aspect of any SOC - content related to the identification and analysis of potential information security incidents. This is, first of all, the architecture of correlation rules in the SIEM-system, as well as related sheets, trends, scripts, connector settings. In the article I will tell you about the whole way of processing the source logs, starting with event handling by connectors of the SIEM system and ending with the use of these events in the correlation rules and the subsequent life cycle of the incident response.

As mentioned in previous articles, the heart of our SOC is the HPE ArcSight ESM SIEM system. In the article I will talk about the improvements of this platform for more than four years of evolution and will describe the current option settings.
')
First of all, the improvements were aimed at optimizing the following activities:
Any SIEM has a set of preset rules out of the box that, by comparing events from sources and accumulating threshold values, can notify the client of a fixed anomaly - a potential incident. Why, then, need an expensive implementation of this system, its configuration, as well as its support by the integrator and its own analyst?
To answer this question, I will tell you how the life cycle of events that fall into SIEM from sources is arranged, what is the path from triggering a rule to creating an incident and alerting the customer.
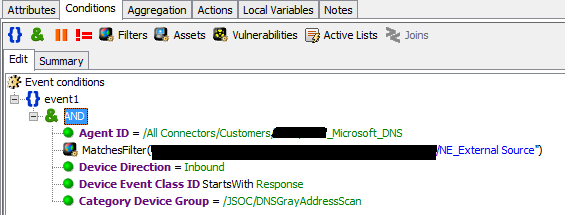
Primary event handling occurs on the connectors of the SIEM system. Processing includes filtering, categorization, prioritization, aggregation, and normalization. Events can also undergo additional preprocessing, for example, combining several events containing different information.
For example: Netscreen juniper logs for tracking arp-spoofing contain information about ip-addresses and mac-addresses in different lines:
When writing a connector, you can immediately make a merge to display all the information in a single event. The key field merge in this case is iso.3.6.1.4.1.3224.17.1.3.1. *. 276.
Next, the pre-processed event is sent to the kernel of the HPE ArcSight system, where it is subsequently processed. As part of Solar JSOC, we used all of the event processing steps to expand our ability to monitor incidents and obtain information about end systems.
As part of the event preprocessing, we try to make maximum use of the functionality associated with field mapping, additional categorization and filtering of events on connectors.
Unfortunately, the possibilities of any SIEM system are limited by the number of events processed per second (EPS) and by the volume of subsequent calculations and processing of initial events. In Solar JSOC, we have several customers for one installation of ArcSight, and the flow of events from them is quite high. The total skip of recorded incidents reaches 100-150, which implies the use of several hundred rules for calculating, filling in sheets, generating incidents and so on. At the same time, the stability of the system and a quick search of events by active channels is very important for us.
Gradually, we came to understand that to fulfill the conditions described above, part of the processing can be brought to the connector level.
For example, instead of using the pre-persistence rules to unify authentication events in various systems, including network equipment, we introduce categories at the level of map-files of connectors.
The map file for the Cisco Router looks like this:
The flow of events from DNS servers is usually one of the highest, so using regular expressions to track attempts of resolving gray addresses by external servers to scan the infrastructure becomes a very difficult task. ArcSight on a stream of 1500 EPS with DNS starts to “feel bad”, so regular expressions are also put into map-files and they are assigned a category.
Instead
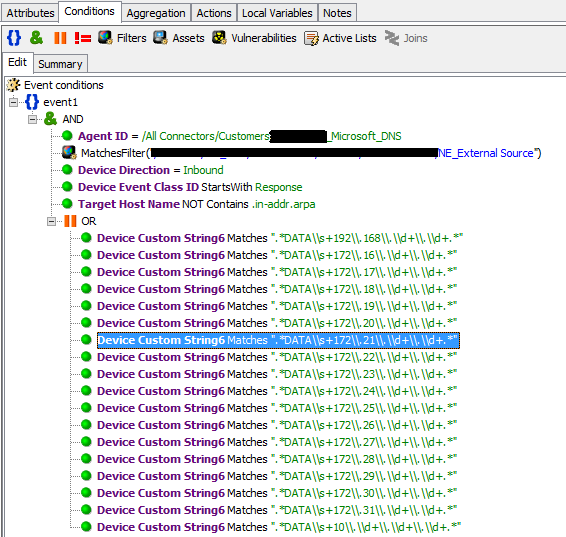
write:
The rest is taken out by regular expressions in the map file.
A vivid example of applying event filtering is also associated with DNS servers. On the HPE ArcSight SmartConnector connector server, we enable the host name resolver to addresses on the Windows connectors and network equipment. Thus, the number of DNS requests from the connector server is very significant, and all these events are clearly not needed to detect incidents, so you can successfully filter them to reduce the load on the ESM.
A second, often even more important reason for using categorization, is working with a large number of different devices, systems, and application software.
When you need to connect, for example, NetScreen, which is not very popular with Russian companies, you can add “permit” events to Solar JSOC in all rules relating to, for example:
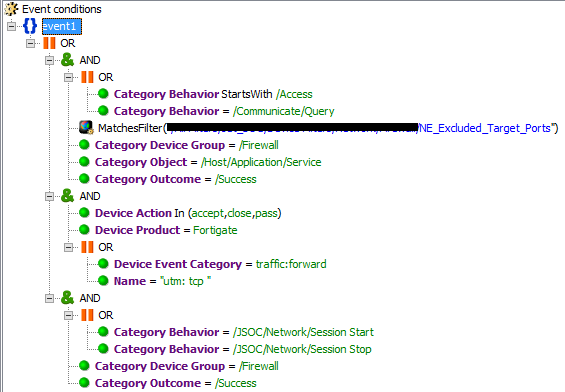
And you can use categorization or ready-made filters. Solar JSOC uses both methods in different cases. In this case, we use the Firewall_Pass filter:
As can be seen from the above examples, we use both the standard categorization of ArcSight, if it fits our requirements, and our own, which seemed universal to us.
Content Correlation Rules
As part of Solar JSOC, we concluded that the “base-mapping-incident rules” bundle works fine. Let's look at each type in order.
Basic rules
The basic rules are used to add to the events the missing information - user name, information about the owner of the account from the personnel system, additional description of the hosts from the CMDB. All this is implemented in Solar JSOC and helps us to quickly sort out incidents and get all the necessary information in a limited pool of events. This was done to ensure that our first line always had the opportunity to meet the 20 minutes allocated for SLA for critical incidents and to do a really high-quality and complete analysis.
Mapping rules
Mapping rules for a wide variety of activities play one of the most important roles. They form the primary data recorded in the active list and later used in the following situations:
Incident rules
In Solar JSOC we use the following types of anomalous activity registration:
Let us dwell on each of the options.
The easiest way to use correlation rules is to trigger when a single event from a source occurs. This works great if the SIEM system is used in conjunction with customized GIS. Many companies are limited to this method.
One of the simplest incidents is the modification of critical files on a host.
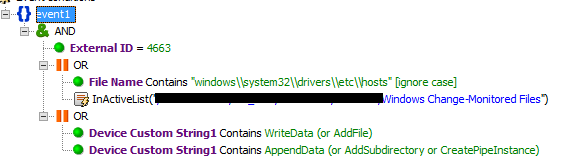
The rule looks unconditionally the file / etc / hosts, as well as all critical files specified in the active list and agreed with the client.
Sequential triggering of correlation rules for several events over a period ideally fits into infrastructure security.
Logging in under one account to the workstation and further logging into the target system under another (or the same scenario with VPN and information system) indicates a possible theft of these accounts. Such a potential threat is common, especially in the day-to-day work of administrators (domain: a.andronov, Database: oracle_admin), and causes a large number of false positives, so the creation of white lists and additional profiling are required.
The following is an example of triggering on access to an unresolved network segment from the vpn pool:

And here is an example of the third type of incident rules, which is configured to detect a virus detection event and the subsequent absence of its removal / cure / quarantine events:
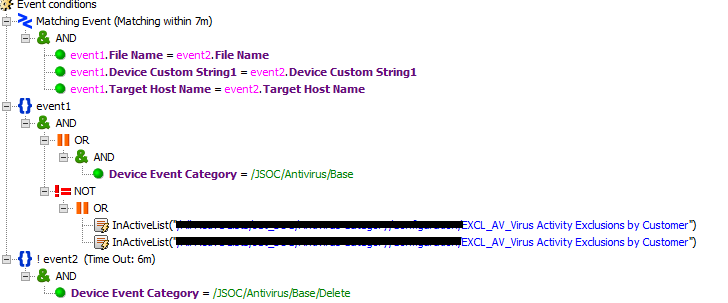
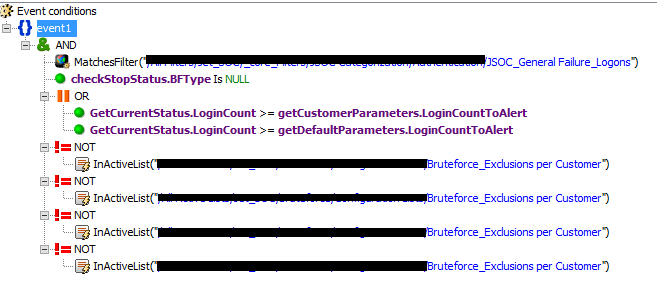
The fourth way to configure the rules is great for detecting various scans, brute force, epidemics and other things.
The rule for detecting brute force, universal for all systems, is the quintessence of all the methods described above. When setting up sources, we always use map files for categorization, so that they fall under the Failure Logons filter, then there are basic rules that are written to the sheet and are counted for it, configuration sheets are used separately to set threshold values for different customers, and Critical and non-critical users. There are also exceptions and a stop-list so that the first line does not overwhelm with similar incidents per user.
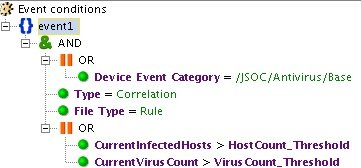
Deviation from the average is used in scenarios for detecting DDoS attacks, virus outbreaks, information leaks from the corporate network and many others.
An example is the INC_AV_Virus Anomaly Activity correlation rule, which tracks the excess of the average antivirus response rate (calculated on the basis of the profile) for a certain period.
As for the verification of the indicators of compromise, they should be singled out as a separate item, because a whole complex of works is carried out in relation to them:
The first item includes primarily working with trends and reports, as they store information for 6-12 months about visiting Internet sites, starting processes, md5-sums of executable files launched in the infrastructure, obtained from specialized protection tools or some antivirus vendors.
The second and third points are closely related. In this case, the revision is carried out depending on the number, frequency and confirmation of the fact that the actuations were combat. In the case of a large number of false positives and the absence of combat, the indicators are removed after a certain time.
Developing Solar JSOC, we learned certain lessons that became the basis for providing the service:
Conclusion
As a conclusion, I would like to summarize the recommendations for organizing my own SOC in a company:
In this article, I did not touch upon the registration of the incident, its processing by the first line, the criteria for filtering false positives, the mechanism for notifying customers and conducting additional investigations. This will be the next article in the series.
Today's publication covers the most important aspect of any SOC - content related to the identification and analysis of potential information security incidents. This is, first of all, the architecture of correlation rules in the SIEM-system, as well as related sheets, trends, scripts, connector settings. In the article I will tell you about the whole way of processing the source logs, starting with event handling by connectors of the SIEM system and ending with the use of these events in the correlation rules and the subsequent life cycle of the incident response.
As mentioned in previous articles, the heart of our SOC is the HPE ArcSight ESM SIEM system. In the article I will talk about the improvements of this platform for more than four years of evolution and will describe the current option settings.
')
First of all, the improvements were aimed at optimizing the following activities:
- Reducing the time to connect a new client and connectors settings.
- Profiling core infrastructure activities.
- Reducing the number of false positives.
- Increase of informativeness and completeness of client notifications about recorded potential incidents.
Any SIEM has a set of preset rules out of the box that, by comparing events from sources and accumulating threshold values, can notify the client of a fixed anomaly - a potential incident. Why, then, need an expensive implementation of this system, its configuration, as well as its support by the integrator and its own analyst?
To answer this question, I will tell you how the life cycle of events that fall into SIEM from sources is arranged, what is the path from triggering a rule to creating an incident and alerting the customer.
Primary event handling occurs on the connectors of the SIEM system. Processing includes filtering, categorization, prioritization, aggregation, and normalization. Events can also undergo additional preprocessing, for example, combining several events containing different information.
For example: Netscreen juniper logs for tracking arp-spoofing contain information about ip-addresses and mac-addresses in different lines:
iso.3.6.1.4.1.3224.17.1.3.1.2.274 = IpAddress: 192.168.30.94
iso.3.6.1.4.1.3224.17.1.3.1.2.275 = IpAddress: 172.16.9.231
iso.3.6.1.4.1.3224.17.1.3.1.2.276 = IpAddress: 172.16.9.232
iso.3.6.1.4.1.3224.17.1.3.1.3.274 = Hex-STRING: AC 22 0B 74 91 4C
iso.3.6.1.4.1.3224.17.1.3.1.3.275 = Hex-STRING: 20 CF 30 9A 17 11
iso.3.6.1.4.1.3224.17.1.3.1.3.276 = Hex-STRING: 80 C1 6E 93 A0 56
When writing a connector, you can immediately make a merge to display all the information in a single event. The key field merge in this case is iso.3.6.1.4.1.3224.17.1.3.1. *. 276.
Next, the pre-processed event is sent to the kernel of the HPE ArcSight system, where it is subsequently processed. As part of Solar JSOC, we used all of the event processing steps to expand our ability to monitor incidents and obtain information about end systems.
Connector settings
As part of the event preprocessing, we try to make maximum use of the functionality associated with field mapping, additional categorization and filtering of events on connectors.
Unfortunately, the possibilities of any SIEM system are limited by the number of events processed per second (EPS) and by the volume of subsequent calculations and processing of initial events. In Solar JSOC, we have several customers for one installation of ArcSight, and the flow of events from them is quite high. The total skip of recorded incidents reaches 100-150, which implies the use of several hundred rules for calculating, filling in sheets, generating incidents and so on. At the same time, the stability of the system and a quick search of events by active channels is very important for us.
Gradually, we came to understand that to fulfill the conditions described above, part of the processing can be brought to the connector level.
For example, instead of using the pre-persistence rules to unify authentication events in various systems, including network equipment, we introduce categories at the level of map-files of connectors.
The map file for the Cisco Router looks like this:
event.eventClassId, set.event.deviceAction, set.categoryOutcome, set.event.categoryDeviceGroup
SEC_LOGIN: LOGIN_SUCCESS, Login, Success, / JSOC / Authentication
SEC_LOGIN: LOGIN_FAILURE, Login, Failure, / JSOC / Authentication
SYS: LOGOUT, Logout, Success, / JSOC / Authentication
The flow of events from DNS servers is usually one of the highest, so using regular expressions to track attempts of resolving gray addresses by external servers to scan the infrastructure becomes a very difficult task. ArcSight on a stream of 1500 EPS with DNS starts to “feel bad”, so regular expressions are also put into map-files and they are assigned a category.
Instead
write:
The rest is taken out by regular expressions in the map file.
A vivid example of applying event filtering is also associated with DNS servers. On the HPE ArcSight SmartConnector connector server, we enable the host name resolver to addresses on the Windows connectors and network equipment. Thus, the number of DNS requests from the connector server is very significant, and all these events are clearly not needed to detect incidents, so you can successfully filter them to reduce the load on the ESM.
A second, often even more important reason for using categorization, is working with a large number of different devices, systems, and application software.
When you need to connect, for example, NetScreen, which is not very popular with Russian companies, you can add “permit” events to Solar JSOC in all rules relating to, for example:
- direct Internet access bypassing the proxy;
- referring to potentially dangerous hosts on versions of various reputation databases;
- application protocol scanning and more.
And you can use categorization or ready-made filters. Solar JSOC uses both methods in different cases. In this case, we use the Firewall_Pass filter:
As can be seen from the above examples, we use both the standard categorization of ArcSight, if it fits our requirements, and our own, which seemed universal to us.
Content Correlation Rules
As part of Solar JSOC, we concluded that the “base-mapping-incident rules” bundle works fine. Let's look at each type in order.
Basic rules
The basic rules are used to add to the events the missing information - user name, information about the owner of the account from the personnel system, additional description of the hosts from the CMDB. All this is implemented in Solar JSOC and helps us to quickly sort out incidents and get all the necessary information in a limited pool of events. This was done to ensure that our first line always had the opportunity to meet the 20 minutes allocated for SLA for critical incidents and to do a really high-quality and complete analysis.
Mapping rules
Mapping rules for a wide variety of activities play one of the most important roles. They form the primary data recorded in the active list and later used in the following situations:
- Quick retrospective search for activities.
These profiling rules, for example, include Profile_IA_Internet Access (Proxy). This rule writes to the list all referrals to sites through a proxy server. This sheet contains the following fields:
But the list has a limit of 3 million records, so every day at night we enter data into a trend, which has an order of magnitude more storage space.
This sheet is used both for standard investigation of incidents and for retrospective verification of indicators of compromise for a long period of time - up to 1 year. - Creating and fixing profiles.
For example, authentication or network profiles for critical hosts. The collection of such a profile takes from one to two weeks, after which it is unloaded and sent to the client. There is a coordination and fixing of a profile, further the incident rule is configured. The appearance of any activity that does not fall into the profile by the specified parameters causes the triggering of this rule, the analysis of the incident by the first line and the notification of the client.
For the convenience of changing the status, we use the configuration file.
If the status is InProgress, the profile is collected, if the status is Finished, the incident rule starts. - Calculation of average, maximum and fluctuation indicators.
The rule “Abnormal statistics of viral activity” works according to this principle. We consider for a certain period statistics on viral infections of the client’s infrastructure, and if a surge occurs on any day, we notify the client of the anomaly, as it may indicate targeted malicious actions by the attacker.
Incident rules
In Solar JSOC we use the following types of anomalous activity registration:
- According to a single event from the source.
- By several consecutive events from one or several sources for the selected period.
- On the occurrence of one and not the occurrence of another event for a certain period.
- Upon reaching the threshold value of events of the same type.
- By the deviation of the statistical indicators from the reference or average value.
- Separately worth checking indicators of compromise.
Let us dwell on each of the options.
The easiest way to use correlation rules is to trigger when a single event from a source occurs. This works great if the SIEM system is used in conjunction with customized GIS. Many companies are limited to this method.
One of the simplest incidents is the modification of critical files on a host.
The rule looks unconditionally the file / etc / hosts, as well as all critical files specified in the active list and agreed with the client.
Sequential triggering of correlation rules for several events over a period ideally fits into infrastructure security.
Logging in under one account to the workstation and further logging into the target system under another (or the same scenario with VPN and information system) indicates a possible theft of these accounts. Such a potential threat is common, especially in the day-to-day work of administrators (domain: a.andronov, Database: oracle_admin), and causes a large number of false positives, so the creation of white lists and additional profiling are required.
The following is an example of triggering on access to an unresolved network segment from the vpn pool:
And here is an example of the third type of incident rules, which is configured to detect a virus detection event and the subsequent absence of its removal / cure / quarantine events:
The fourth way to configure the rules is great for detecting various scans, brute force, epidemics and other things.
The rule for detecting brute force, universal for all systems, is the quintessence of all the methods described above. When setting up sources, we always use map files for categorization, so that they fall under the Failure Logons filter, then there are basic rules that are written to the sheet and are counted for it, configuration sheets are used separately to set threshold values for different customers, and Critical and non-critical users. There are also exceptions and a stop-list so that the first line does not overwhelm with similar incidents per user.
Deviation from the average is used in scenarios for detecting DDoS attacks, virus outbreaks, information leaks from the corporate network and many others.
An example is the INC_AV_Virus Anomaly Activity correlation rule, which tracks the excess of the average antivirus response rate (calculated on the basis of the profile) for a certain period.
As for the verification of the indicators of compromise, they should be singled out as a separate item, because a whole complex of works is carried out in relation to them:
- a retrospective verification of indicators is being conducted;
- indicators are recorded in special sheets for their further detection;
- after the time expires, the relevance of the indicators of compromise is reviewed.
The first item includes primarily working with trends and reports, as they store information for 6-12 months about visiting Internet sites, starting processes, md5-sums of executable files launched in the infrastructure, obtained from specialized protection tools or some antivirus vendors.
The second and third points are closely related. In this case, the revision is carried out depending on the number, frequency and confirmation of the fact that the actuations were combat. In the case of a large number of false positives and the absence of combat, the indicators are removed after a certain time.
Developing Solar JSOC, we learned certain lessons that became the basis for providing the service:
- Client interaction and feedback from it is an essential element in the work of the Security Operations Center. It allows you to better understand the processes within the customer, which means - to create exclusion lists for various incident rules and reduce the number of false positives several times. For one client, it can be completely normal to use TOR on a host, and for another, it is a direct way to dismiss an employee. Some VPN-access has only trusted administrators who can work with the entire infrastructure, others have access to half of the employees, but they only work with their station.
- Collecting profiles. The overwhelming majority of the company's employees work according to the same scenario every day. It is easy to profile it, therefore, it is quite simple to identify anomalies. Therefore, in Solar JSOC we use the same rules, but the parameters, lists, filters in them are individual for each client.
- Complex rules do not work . The greater the number of clarifying conditions and the initiating events involved in the correlation rule, the less chance there is that such a scenario will “take off” from all customers. It is necessary to make universal rules, and "adjustment" to do at the level of exceptions.
- SIEM should solve only its own tasks. No need to try to force the SIEM system to solve a Zabbix task or a DDoS detection solution. The latter is not enough that “eats up” the resources of the system, it also does not help prevent this very DDoS.
At the same time, I would like to note: no matter how well the SIEM system is configured, false positive events will always be present. If not, then SIEM is dead. But false-positive are also different. Resetting a top manager's password at night can be explained as an unexpected decision to work from home and the inability to remember the password, or the actions of an attacker. But there are also situations when false positives occur at the level of technology and are not currently added to the incident rule as regular exceptions. That is why it is important to have qualified monitoring engineers who can identify the real incident. The specialist must possess a set of information security knowledge, anticipate the vectors of possible attacks and know the final systems for analyzing events.
Conclusion
As a conclusion, I would like to summarize the recommendations for organizing my own SOC in a company:
- The most important element of SOC is the SIEM-system, the issues of its choice were discussed in the first article of the cycle, but the most important point is its adjustment to the requirements of the business and infrastructure features.
- Creating correlation rules to detect various attack scenarios and the activities of intruders is a huge body of work that never ends due to the constant development of threats. That is why it is necessary to have your own qualified analyst on the staff of the company.
- The first line of monitoring engineers should be formed on the basis of the information security department. The specialist should be able to distinguish false positives from real incidents and carry out a basic analysis of events. This requires skills in the field of information security and an understanding of possible attack vectors.
In this article, I did not touch upon the registration of the incident, its processing by the first line, the criteria for filtering false positives, the mechanism for notifying customers and conducting additional investigations. This will be the next article in the series.
Source: https://habr.com/ru/post/320262/
All Articles