The most popular words in two terabytes of code
Hello friends! I analyzed 2TB code here and got the most popular words in different programming languages. The results can be viewed in the form of tag clouds and a simple list:
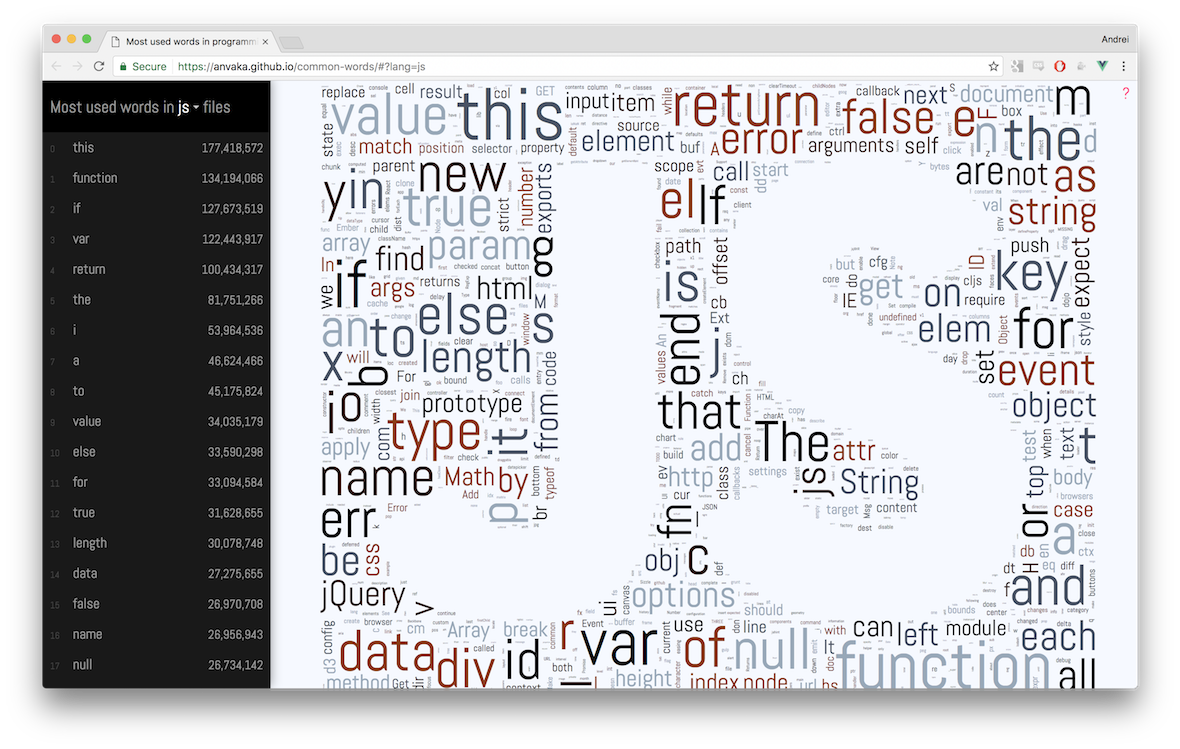
The site is here , and its source can be read on github .
Under the cat described in detail about how the data was collected, how the site was built and how the clouds fit. And a little bit of observation.
')
Enjoy reading!
I collected the data using BigQuery. Google, together with GitHub, posted a full snapshot of the sources on a public date set github_repos . The index was built at the end of 2016.
When building clouds, I impose some restrictions on the data:
BigQuery is an awesome platform. The contents of all files from the githab are stored in plain text in tables .
BigQuery allows you to write an ordinary SQL query and execute it with amazing speed.
At first I decided to break the contents of all files into words, and then use
Unfortunately, this approach takes the word out of context. I really wanted to show words with examples of how they are used:

How to be? Instead of a simple word break, I created an intermediate table, where the files are broken line by line:
Such intermediate storage reduces the size of the processed data from ~ 2TB to ~ 12GB.
Now, to get the most popular words from this table, we can break each line into individual words, but at the same time keep the original line:
It would seem that almost nothing has changed. But, in this interpretation, we can use window functions to get the top 10 lines for each word (
The current request code can be found here: extract_words.sql .
By the way ... My SQL is at a very basic level. Because if you, dear reader, find an error, or know a more suitable way - please let me know.
At the heart of all tag developers I know is this algorithm:
This code can run indefinitely, because we either stop trying after several iterations, or reduce the font size until the word fits.
For simplicity, words can be thought of as rectangles. We are trying to place all the rectangles on the screen so that no rectangle crosses the occupied pixels on the screen.
The most resource-intensive part of this algorithm is intersection checking. Especially at the end, when all the free space is basically already taken, finding a new area where you can insert a word becomes very difficult (and sometimes not possible).
Different implementations are trying to speed up this part of the algorithm by indexing the occupied space.
I wanted to try something different. Instead of indexing the occupied space, I wanted to have an index of the free area. So you can immediately select a large rectangle in which there is guaranteed a place for a new arrival.
For the index, I used a quad tree . Each intermediate tree node stores information about how many free / occupied pixels there are. So you can instantly sweep aside quadrants in which there are not enough free pixels.
The easiest way to see it in the picture. Here is the quad-tree of the JS logo:

White empty rectangles are free space. If you need to add a new rectangle which is smaller than any of these empty rectangles - we can safely draw it there.
This approach gives good results, but can lead to visual artifacts. After all, no new rectangle can be located at the intersection of quadrants:

Moreover, what if none of the free quadrants are large enough? And if the adjacent quadrants are combined, then there is enough space?
The union of free quadrants was my next step. I just "expand" quads to the left / right of the target. This slows down the build time a little, but reduces artifacts and gives better results:

By the way ... My handler code is not available with the site. It was quickly written and is difficult to use in other contexts. If you need a good handler, look at
amueller / word_cloud
In general, I was pleased with the speed of building a tag cloud. But in the context of my site this speed was not enough.
I used SVG to draw words on the screen. The rendering of so many text-based SVG elements can easily block the UI stream for a few seconds. Where are the positions for the tag cloud?
Fortunately, you can remove the stacker offline. Instead of counting the positions of the words on the fly, when the browser opens the page, I decided to count the positions once, save them to a file, and then draw them statically. This allows us to focus on optimizing the UI flow.
In order not to block the browser for long periods of time, you need to break all the work into small pieces, and perform it asynchronously. At one iteration of the event loop, we add N words and exit the function so that the browser can handle other events. At the next iteration, we add more words, and so on.
For these purposes, I wrote anvaka / rafor . This library is an adaptive, asynchronous `for` loop based on
Using the mouse, keyboard, or touch-screen, you can zoom in, delete a map, and move it around the screen, just like Google Maps does. All this is done using the panzoom library.
I use vue.js for UI. It is easy to use and quick to use. It is especially cool to have vue components in separate files - you don't often have to switch between js / markup / styles. Hot-reload makes development especially enjoyable.
Application state is stored in a single appState object. When you select a programming language, words and their context are loaded asynchronously.
For the exchange of events between components, I use my mini-library ngraph.events . Initially, I made it for a speedy exchange of events in my graph libraries. But here it works fine as a dispatcher.
Finally, anvaka / query-state binds the query string to bidirectional binding to the choice of programming language.
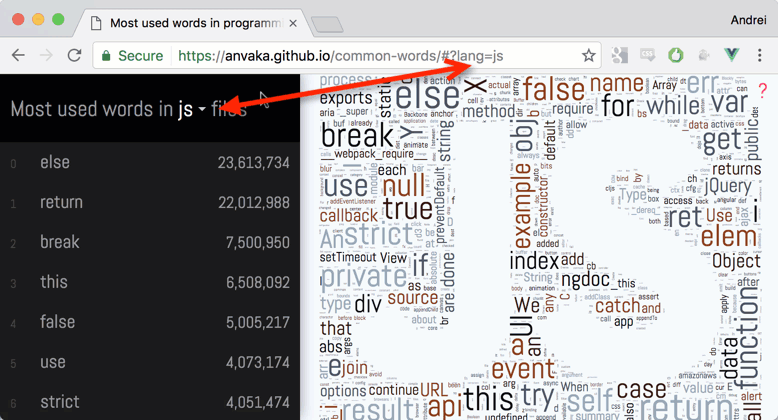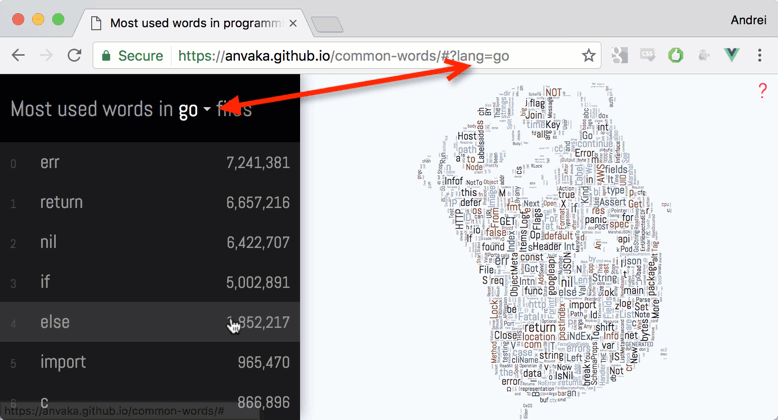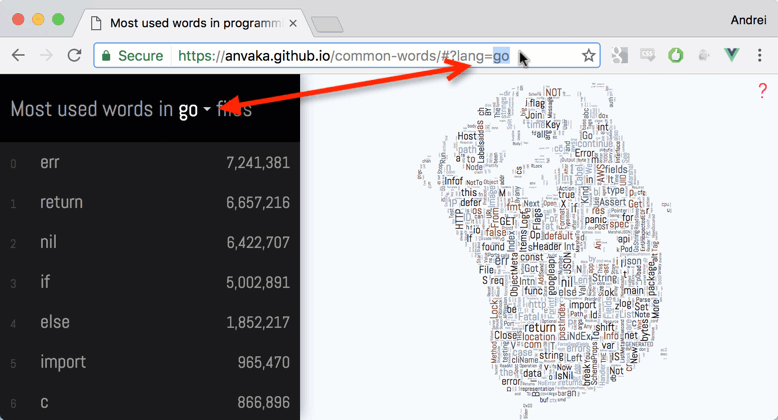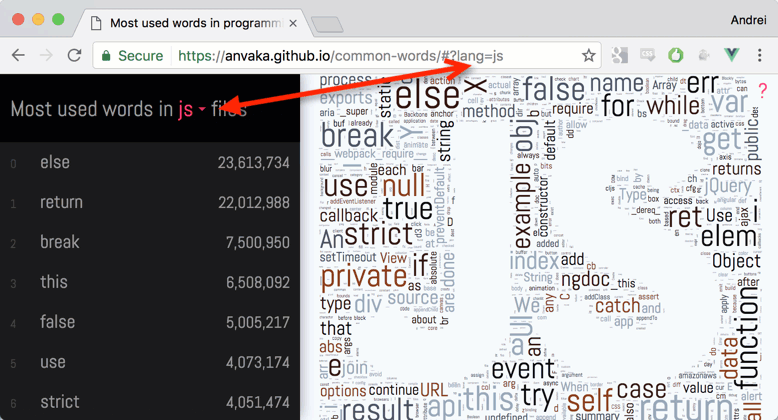
This project has been my evening hobby for the past two months. Despite all the flaws of the tag clouds, I was very interested.
I sincerely hope that you enjoyed this study too :)!
Thank you, dear reader, for your attention. And special thanks to my soul mate for her endless support and hints.
The site is here , and its source can be read on github .
Under the cat described in detail about how the data was collected, how the site was built and how the clouds fit. And a little bit of observation.
')
Enjoy reading!
Observations
- The most popular text in all programming languages was the text from licenses. Among all Java languages won here. Of the 966 most popular words, 127 were about the license:

Probably, the culture of adding licenses to each .java file is much stronger than in other languages. Have you seen the official hello world ? Luais the only programming language in which an obscene word has entered the top. Can you find- In Go, the most popular word was
err. There are no exceptions in this language?
How?
I collected the data using BigQuery. Google, together with GitHub, posted a full snapshot of the sources on a public date set github_repos . The index was built at the end of 2016.
When building clouds, I impose some restrictions on the data:
- The maximum length of a string with a word should not exceed 120 characters. This helps to get rid of the generated code (for example, in minified javascript).
- Punctuation (
, ; : .), Operators (+ - * ...) and numbers are ignored. For example, the stringa + b + 42will be counted as two wordsaandb - Since the text of the licenses overloaded the visualizations, I removed all the lines in which there are marker words that are specific to the licenses (for example,
license,noninfringementand so on ... ) - The register of words is taken into account.
Thisandthisare considered two different words.
How was the data collected?
BigQuery is an awesome platform. The contents of all files from the githab are stored in plain text in tables .
| File | Content |
|---|---|
| File 1.h | // File 1 content \ n # ifndef FOO \ n # define FOO ... |
| File 2.h | // File 2 content \ n # ifndef BAR \ n # define BAR ... |
BigQuery allows you to write an ordinary SQL query and execute it with amazing speed.
At first I decided to break the contents of all files into words, and then use
GROUP BY to count them.| Word | How many times have I met |
|---|---|
| File | 2 |
| content | 2 |
| ... | ... |
Unfortunately, this approach takes the word out of context. I really wanted to show words with examples of how they are used:
How to be? Instead of a simple word break, I created an intermediate table, where the files are broken line by line:
| Line | How many times did I meet a string |
|---|---|
| // File 1 content | one |
| #ifndef FOO | one |
| #ifndef FOO | one |
| ... | ... |
Such intermediate storage reduces the size of the processed data from ~ 2TB to ~ 12GB.
Now, to get the most popular words from this table, we can break each line into individual words, but at the same time keep the original line:
| Line | Word |
|---|---|
| // File 1 content | File |
| // File 1 content | content |
| #ifndef FOO | ifndef |
| #define FOO | FOO |
| ... | ... |
It would seem that almost nothing has changed. But, in this interpretation, we can use window functions to get the top 10 lines for each word (
SELECT ... OVER (PARTITION BY ...) - as in this question on StackOverflow ).The current request code can be found here: extract_words.sql .
By the way ... My SQL is at a very basic level. Because if you, dear reader, find an error, or know a more suitable way - please let me know.
How to draw a tag cloud?
At the heart of all tag developers I know is this algorithm:
`w`:
1. `w` (x, y)
2. - 1.This code can run indefinitely, because we either stop trying after several iterations, or reduce the font size until the word fits.
For simplicity, words can be thought of as rectangles. We are trying to place all the rectangles on the screen so that no rectangle crosses the occupied pixels on the screen.
The most resource-intensive part of this algorithm is intersection checking. Especially at the end, when all the free space is basically already taken, finding a new area where you can insert a word becomes very difficult (and sometimes not possible).
Different implementations are trying to speed up this part of the algorithm by indexing the occupied space.
- Some use Summed area table . This is a special data structure that allows you to say or cross a new rectangle on the screen in
O(1)time. Unfortunately, the structure needs to be updated after changes on the screen, which gives mediocre performance. - I saw some use varieties of R-trees to index the occupied space. In this approach, the search for intersections is slower than with Summed Area Tables, but maintaining the index is faster. However, the implementation of R-trees is not the most trivial task.
I wanted to try something different. Instead of indexing the occupied space, I wanted to have an index of the free area. So you can immediately select a large rectangle in which there is guaranteed a place for a new arrival.
For the index, I used a quad tree . Each intermediate tree node stores information about how many free / occupied pixels there are. So you can instantly sweep aside quadrants in which there are not enough free pixels.
The easiest way to see it in the picture. Here is the quad-tree of the JS logo:
White empty rectangles are free space. If you need to add a new rectangle which is smaller than any of these empty rectangles - we can safely draw it there.
This approach gives good results, but can lead to visual artifacts. After all, no new rectangle can be located at the intersection of quadrants:
Moreover, what if none of the free quadrants are large enough? And if the adjacent quadrants are combined, then there is enough space?
The union of free quadrants was my next step. I just "expand" quads to the left / right of the target. This slows down the build time a little, but reduces artifacts and gives better results:
By the way ... My handler code is not available with the site. It was quickly written and is difficult to use in other contexts. If you need a good handler, look at
amueller / word_cloud
How was the site made?
Text rendering
In general, I was pleased with the speed of building a tag cloud. But in the context of my site this speed was not enough.
I used SVG to draw words on the screen. The rendering of so many text-based SVG elements can easily block the UI stream for a few seconds. Where are the positions for the tag cloud?
Fortunately, you can remove the stacker offline. Instead of counting the positions of the words on the fly, when the browser opens the page, I decided to count the positions once, save them to a file, and then draw them statically. This allows us to focus on optimizing the UI flow.
In order not to block the browser for long periods of time, you need to break all the work into small pieces, and perform it asynchronously. At one iteration of the event loop, we add N words and exit the function so that the browser can handle other events. At the next iteration, we add more words, and so on.
For these purposes, I wrote anvaka / rafor . This library is an adaptive, asynchronous `for` loop based on
requestAnimationFrame() . All iterations are performed at different stages of the event cycle, and thereby reduces the load on the UI stream. The initial loading of the site looks smoother.Navigation and Zoom
Using the mouse, keyboard, or touch-screen, you can zoom in, delete a map, and move it around the screen, just like Google Maps does. All this is done using the panzoom library.
Application model
I use vue.js for UI. It is easy to use and quick to use. It is especially cool to have vue components in separate files - you don't often have to switch between js / markup / styles. Hot-reload makes development especially enjoyable.
Application state is stored in a single appState object. When you select a programming language, words and their context are loaded asynchronously.
For the exchange of events between components, I use my mini-library ngraph.events . Initially, I made it for a speedy exchange of events in my graph libraries. But here it works fine as a dispatcher.
Finally, anvaka / query-state binds the query string to bidirectional binding to the choice of programming language.
Finally
This project has been my evening hobby for the past two months. Despite all the flaws of the tag clouds, I was very interested.
I sincerely hope that you enjoyed this study too :)!
Thank you, dear reader, for your attention. And special thanks to my soul mate for her endless support and hints.
Source: https://habr.com/ru/post/320256/
All Articles