Automation of load testing: a bunch of Jmeter + TeamCity + Grafana

Image: Flickr
In our blog on Habré, we continue to talk about building a DevOps culture in a company — for example, in one of the last topics we described what tasks we solve with the help of the SaltStack system. Today we will talk about another interesting topic - the automation of load testing using a bunch of several ready-made tools.
')
As it was before
We needed to monitor the servers on which the load testing was carried out - to collect performance metrics of the processor, memory, operating system, etc. It was also necessary to monitor the status of databases, busses and queues, and sometimes it was sometimes necessary to work with logs. All these tasks were solved by our own development Python scripts, the information was stored in a SQLite database, and reports were generated using CSV files.
Here is the scheme:

Cons of this approach:
- All that is highlighted in the picture with a curly bracket was subsequently stored dead in the artifactory, it was extremely difficult to analyze the data.
- Our functionality allowed us to build a report only with a rigid form - without filters and displaying correlations.
- The main disadvantage is that the report was generated only at the end of the test.
New bundle
In the end, we abandoned our own bicycles and decided to use the fruits of other people's labors. As a result, a new bunch of several instruments was born.
Data storage
InfluxDB product was used as a data storage system. This is one of the few DBMSs created for storing time series (performance metrics, analytics, events). She is able to aggregate data on the fly, and the system is also easy to use due to the fact that it uses SQL-like syntax. Of the other advantages:
- Regular expression support.
- Automatic cleaning of old data.
- Scalable.
- Availability of libraries for popular languages.
- Easy deployment and administration.
Consider an example of using InfluxDB for measurements. Suppose we need to measure the temperature of the machine X of type Y in the time interval.
For this we have the parameters:
- Measurement: temperature;
- Tags: machine, type;
- Fields: internal_temperatre, external_temperature.
Tags are used for aggregation and filtering, data is stored in the fields for storage - they are not indexed, only one value is stored for the “measurement + tag + timestamp” combination, the time accuracy is set (s, ms, μs, ns). The duration of data storage is set by the purge policy.
Here is what the dimension will look like:
temperature, machine-unit42,type=assembly internal=32, external=100 1434055562000000035 It is easy to form, easy to transfer and it does not require large expenditures of resources.
Monitoring
We decided to use Zabbix as a monitoring tool. We use cross-platform agents on Windows and Linux-hosts. Both passive and active checks are used. Through active checks, the collection of metrics from hosts from closed networks is implemented. In addition, we actively used the autodiscovery feature for virtual machines on ESXi hosts.
Analysis
The open-source project grafana is used by the data analysis tool - it is great for creating dashboards, building graphs, and standardizing queries and dashboards. The system can build queries for different data sources - the same InfluxDB, Zabbix, Elasticsearch, etc. In general, the product is really convenient - you can create signatures for records and playlists, search for dashboards, export and import data.
Well, it is impossible not to mention the interface that does not make the eyes bleed (hi, Zabbix).

Final configuration
After reviewing the elements of the system, let's talk about how it all works together in the end.
All important operating system and hardware metrics are monitored with Zabbix, as well as with the help of modernized scripts on Python. Metrics collected by scripts are stored in InfluxDB, information is displayed in Grafana.
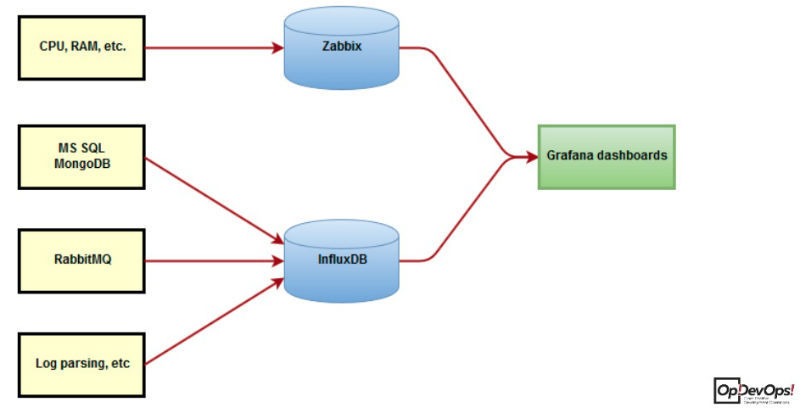
Automation
Having prepared the infrastructure, we dealt with the issues of test automation. The Apache JMeter product was used for this. That's what it is for:
- It can fully emulate the work of real users with the system - in our case, requests between the server and the browser.
- The system generates statistical data on the server operation - for example, the processing time of incoming requests and the processing of incoming responses.
- Sends work results to InfluxDB and for display in Grafana.
On the way to its implementation it was necessary to solve several problems.
- It was necessary to develop a simple mechanism for deploying the tool on the servers.
- To establish an easy process for starting and carrying out load testing.
- Develop a simple integration of test results into Grafana.
- Organize online monitoring of load testing.
Here is what we did to solve them:
- Developed a load script that covers up to 80% of all user operations.
- Implemented a testing launch mechanism through TeamCity.
- Implemented the display of online statistics on the operation of our product MaxPatrol UI.
- Made a simple script update via git.
This is how the test task launch interface in TeamCity looks like:

Jmeter has a plug-in (Backend Listener) for sending data to InfluxDB

Bottom line: how everything works
At the moment, the process of load testing is the start of a task in TeamCity - you just need to select the necessary parameters at startup. Further, the statistics on the work of the UI are displayed immediately in the form of ready-made interactive graphs. Updated scripts are automatically pulled up via Git in TeamCity.
PS The story about our experience of using SaltStack was presented in the framework of DevOps-mitap, which took place in the fall of 2016 in Moscow.
Video:
Slides
The link presents presentations of 16 reports presented during the event. All presentations and video presentations are added to the table at the end of this topic-announcement .
Authors : Ivan Ostanin, Sergey Tikhonov
Source: https://habr.com/ru/post/320228/
All Articles