Spotify: Google Cloud event subsystem migration (part 2)
In the first article, we talked about how the old message delivery system worked and the lessons we learned from its work. In this (second) article we will talk about the architecture of the new system and why we chose Google Cloud Pub / Sub as the transport mechanism for all events.

Our experience in operating and maintaining the old event delivery system gave us a lot of background information to create a new and improved one. Our current platform was built on an even older system that works with hourly logs. This design created difficulties, for example, with the distribution and confirmation of end-of-file markers on each machine issuing events. In addition, the current implementation could enter into a state of failure from which it could not automatically exit. The existence of a piece of software that requires manual intervention in the event of some failures and that runs on each machine that “generates” logs results in significant operating costs. In the new system, we wanted to simplify the work of machines with logs, processing events with a smaller number of computers located closer to the network for further processing.
')
Here the missing part is the event delivery system or a queue that implements reliable event transport and storing undelivered messages in the queue. Using such a system, we could speed up and significantly speed up the transfer of data by producers, receive confirmations with low latency and shift the responsibility for recording events in HDFS to the rest of the system.
Another change we planned was that each event type had its own channel, or topic, and the events were converted to a more structured format in the early stages of the process. More work on Producers means less time to convert data to Extract, Transform, Load (ETL) in later stages. Dividing events into topics is a key requirement for building an effective real-time system.
Since the message delivery should work all the time, we created a new system so that it works in parallel with the current one. The interfaces on both the Producer and Consumers corresponded to the current system, and we could check the performance and correctness of the new operation before switching to it.
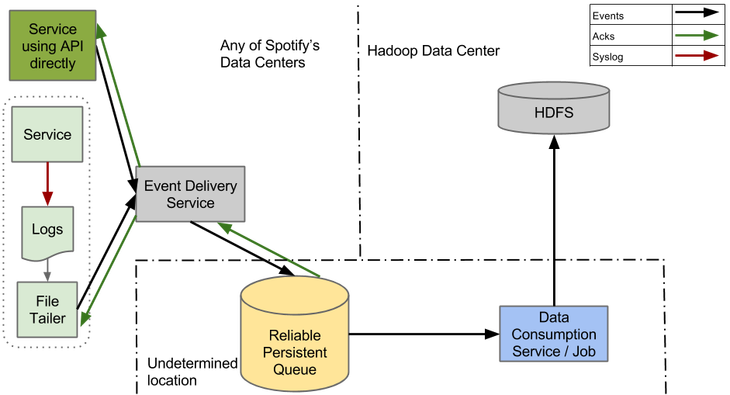
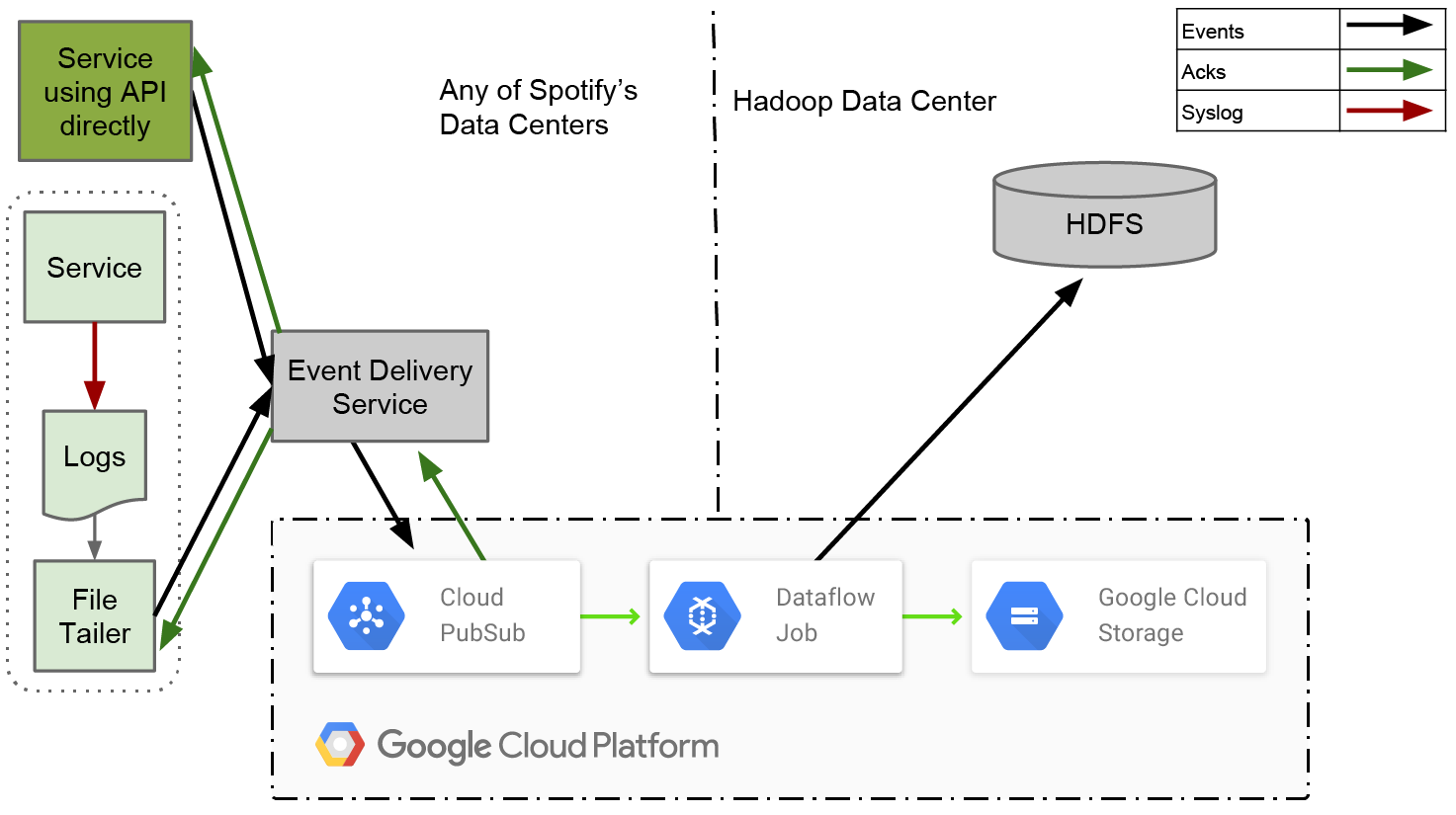
The four main components of the new system are the File Agent (File Tailer), the Event Delivery Service, the Reliable Persistent Queue, and the ETL service.
In this design, the File Agent has a much narrower remit than the Producer in our old system. It generates log files from new events and sends them to the Event Delivery Service. As soon as he receives confirmation that events have been received, this is where his work ends. There is no more complicated processing of end-of-file markers or making sure that the data has reached the end point in HDFS.
The event delivery system receives them from the Agent, translates them into the final structured format and sends them to the Queue. The service is built as a RESTful microservice using the Apollo framework and deployed using the Helios orchestrator, which is a general scheme for Spotify. This allows you to decouple customers from a certain uniform technology, and also allows you to switch to any other basic technology without interrupting service.
The queue is the core of our system and in this form is important for scaling in accordance with the growth of data flow. To cope with Hadoop downtime, it must reliably save messages for several days.
The ETL service should reliably prevent duplication and export data from the Queue to hourly assemblies in HDFS. Before he opens such a package to the downstream users, he must with a high degree of probability make sure that all the data for the package has been received.
In the figure above, you can see the block that says "Service uses the API directly." We have been feeling for some time that syslog is not an ideal API for the Event Producer. When the new system comes into operation, and the old one completely disappears from the scene, it will be logical to abandon the syslog and start working with libraries that can directly communicate with the Event Delivery Service.
Creating a Secure Delivery Queue that reliably handles huge amounts of Spotify events is a daunting task. Our goal was to use existing tools for the hardest work. Since event delivery is the basis of our infrastructure, we would like to make the system convenient and stable. The first choice was Kafka 0.8.
There are many reports that Kafka 0.8 is successfully used in large companies around the world and Kafka 0.8 is a significantly improved version compared to the one we use now. In particular, in it the improved Kafka brokers provide reliable permanent storage. The Mirror Maker project introduced mirroring between data centers, and Camus can be used to export Avro-structured events into hourly assemblies.
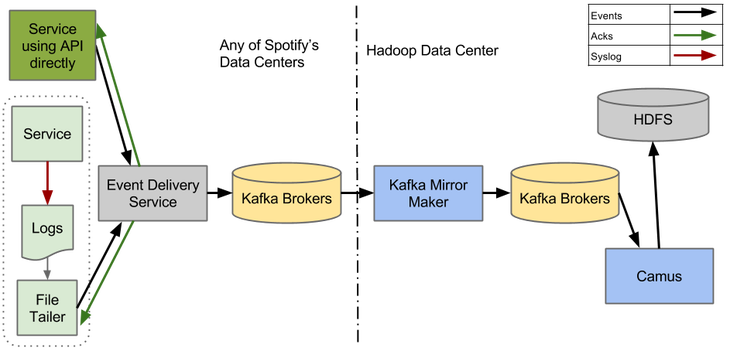
To make sure that event delivery can work correctly on Kafka 0.8, we deployed the test system, which is shown in the figure above. Embed a simple Kafka Producer in the Event Delivery Service turned out to be easy. To ensure that the system works correctly from beginning to end - from Event Delivery Service to HDFS - we have implemented a variety of integration tests in our continuous integration and delivery processes.
Unfortunately, as soon as this system began processing real traffic, it began to fall apart. The only component that turned out to be stable was Camus (but since we didn’t get too much traffic through the system, we still don’t know how Camus would behave under load).
Mirror Maker gave us the most headache. We assumed that it would reliably mirror data between data centers, but this turned out to be just not the case. It works only in ideal conditions (more precisely, the best effort basis) . As soon as a problem occurs in the target cluster, the Mirror Maker simply loses data, although it also informs the source cluster that the data was successfully mirrored (note that this must be fixed in Kafka 0.9).
Mirror Makers sometimes became confused about who was the leader in the cluster. The leader sometimes forgot that he was the leader, while the rest of the Mirror Makers from the cluster could happily try to follow him. When this happened, the mirroring between the data centers stopped.
Kafka Producer also has serious stability issues. If one or more brokers were removed from the cluster, or even simply restarted, with a certain probability, the Producer entered a state from which he could not leave himself. In this state, he could not produce any events. The only way out was a complete restart of the service.
Without even addressing the resolution of these issues, we realized that it would take a lot of energy to bring the system into working condition. We will need to define a deployment strategy for Kafka Brokers and Mirror Makers, model the required capacity and plan all system components, and also set performance metrics for the Spotify monitoring system .
We were at a crossroads. Should we make a significant investment and try to make Kafka work for us? Or should you try something else?
While we were fighting Kafka, other members of the Spotify team began experimenting with Google Cloud. We were especially interested in Cloud Pub / Sub . It seemed that Cloud Pub / Sub will be able to satisfy our need for a reliable queue: it can store undelivered data for 7 days , provides reliability through confirmations at the application level, and has at-least-once delivery semantics.
In addition to meeting our basic needs, Cloud Pub / Sub has additional benefits:
Sounds great on paper ... but too good to be true? The solutions that we created on Apache Kafka, although they were not perfect, still served us well. We had a lot of experience in dealing with various failures, access to hardware and source codes, and - theoretically - we could find the source of any problem. The transition to a managed service meant that we had to entrust the operations of another organization. At the same time, Cloud Pub / Sub was advertised as a beta version - we did not know about any organization other than Google, which would use it on the scale we needed.
With all this in mind, we decided that we need a detailed test plan to be absolutely sure that if we switch to Cloud Pub / Sub, it will meet all our requirements.
The first item in our plan was testing Cloud Pub / Sub to see if it could handle our workload. Currently, our workload reaches 700K events per second at a peak. Considering future growth and possible disaster recovery scenarios, we stopped at a test load of 2M events per second. In order to completely finish Pub / Sub, we decided to publish all this amount of traffic in one data center, so that all these requests would fall into Pub / Sub machines in one zone. We made the assumption that Google planned the zones as independent domains, and that each zone could handle equal amounts of traffic. In theory, if we could shove 2M messages into one zone, we could also send a number of zones * 2M messages in all zones. Our hope was that the system would be able to handle this traffic both on the manufacturer’s side and on the consumer’s side for a long time without degrading the service.
At the very beginning, we stumbled upon a stumbling block: the Cloud Pub / Sub Java client did not work well enough. This client, like many other Google Cloud API clients, is automatically generated from API specifications. This is good if you want clients to support a wide range of languages, but not too much if you want to get a high-speed client for one language.
Fortunately, Pub / Sub has a REST API, so it was easy for us to write our own library . We created a new client, thinking first of all about his speed. To use resources more efficiently, we used asynchronous Java. We also added queues and batch processing to the client. (This is not the first time we had to roll up our sleeves and rewrite the Google Cloud API client - in another project we developed a high-speed client for the Datastore API.)
With the new client, we were ready to start loading Pub / Sub in an adult way. We used a simple generator to send bogus traffic from the Event Service to Pub / Sub. Formed traffic was redirected through two Pub / Sub topics in a ratio of 7: 3. To generate 2M messages per second, we launched Event Service on 29 machines.
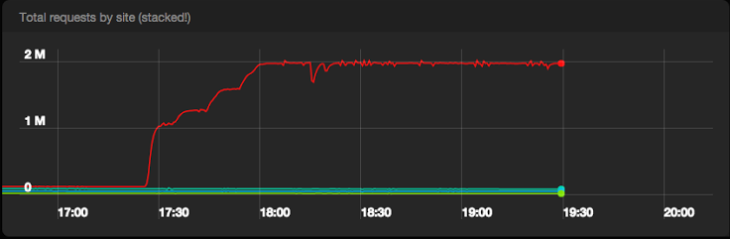
Number of successful requests per second to Pub / Sub from all data centers
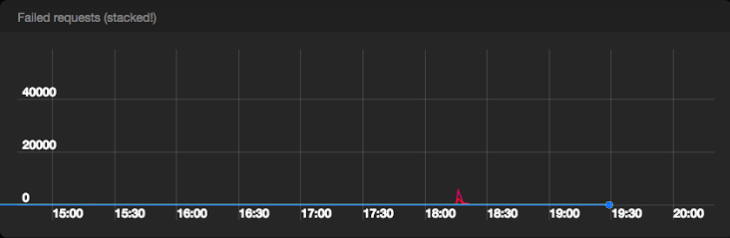
Number of unsuccessful requests per second to Pub / Sub from all data centers
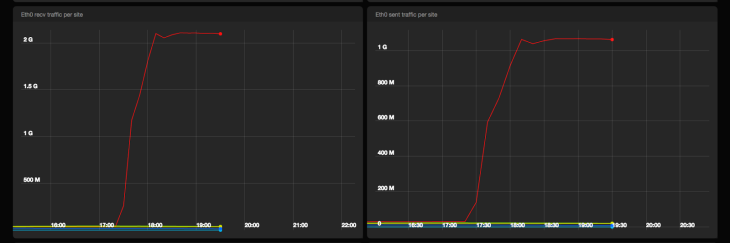
Inbound and outbound network traffic from Event Service machines in bps
Pub / Sub passed the test with honor. We published 2M messages without any quality problems and almost did not receive server errors from the Pub / Sub backend. Enabling batch processing and compression on Event Service machines resulted in approximately 1 Gpbs of traffic to Pub / Sub.

Google Cloud Monitoring graph for total published messages in Pub / Sub
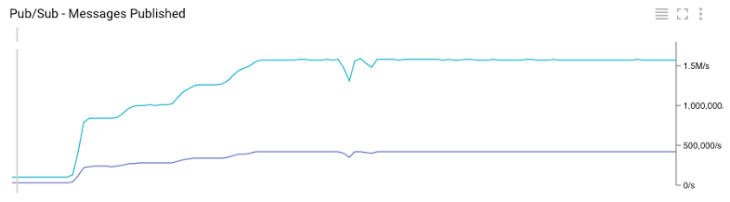
Google Cloud Monitoring graph for the number of posted posts in Pub / Sub topics
A useful side effect of our test is that we were able to compare our internal metrics with the metrics provided by Google. As shown in Charts 3 and 6, they ideally match.
Our second important test was devoted to consumption. For 5 days, we measured end-to-end delays under heavy loads. At the time of the test, we published, on average, about 800K messages per second. To simulate real loads, the speed of publication changed throughout the day. To ensure that we can use several topics at the same time, all data was published for two topics in a ratio of 7: 3.
Slightly surprised by the behavior of Cloud Pub / Sub is that it’s necessary to create subscriptions before saving messages - while no subscriptions exist, no data is saved. Each subscription stores data independently, and there are no restrictions on how many subscriptions a consumer may have. Consumers are coordinated on the server side, and the server is responsible for sufficient message allocation for all consumers requesting data. This is very different from Kafka, where data is stored in the created topic and the number of consumers in the topic is limited by the number of sections in the topic.

In our test, we created a subscription, an hour later we began to consume data. We consumed them in batches of 1000 messages. Since we did not try to reach the consumption limit, we just wanted to slightly exceed the current peak level. It took 8 hours. After we reached it, Consumers continued to work at the same level that corresponded to the speed of publication.
The average end-to-end delay, which we measured during the test period — including the restoration of the backlog — was around 20 seconds. We did not observe message losses during the entire test period.
On these tests, we made sure that Cloud Pub / Sub is the right choice for us. Delays were small and constant, and the only limitation in capacity we encountered was the established quota. In short, choosing Cloud Pub / Sub instead of Kafka 0.8 for our new message delivery platform was the obvious choice.
After the events are securely stored in Pub / Sub, it’s time to export them to HDFS. To take full advantage of Google Cloud, we decided to try Dataflow.
In the last article of this series, we will talk about how Dataflow was used for our purposes. Stay with us!
How to create a new event delivery system for Spotify
Our experience in operating and maintaining the old event delivery system gave us a lot of background information to create a new and improved one. Our current platform was built on an even older system that works with hourly logs. This design created difficulties, for example, with the distribution and confirmation of end-of-file markers on each machine issuing events. In addition, the current implementation could enter into a state of failure from which it could not automatically exit. The existence of a piece of software that requires manual intervention in the event of some failures and that runs on each machine that “generates” logs results in significant operating costs. In the new system, we wanted to simplify the work of machines with logs, processing events with a smaller number of computers located closer to the network for further processing.
')
Here the missing part is the event delivery system or a queue that implements reliable event transport and storing undelivered messages in the queue. Using such a system, we could speed up and significantly speed up the transfer of data by producers, receive confirmations with low latency and shift the responsibility for recording events in HDFS to the rest of the system.
Another change we planned was that each event type had its own channel, or topic, and the events were converted to a more structured format in the early stages of the process. More work on Producers means less time to convert data to Extract, Transform, Load (ETL) in later stages. Dividing events into topics is a key requirement for building an effective real-time system.
Since the message delivery should work all the time, we created a new system so that it works in parallel with the current one. The interfaces on both the Producer and Consumers corresponded to the current system, and we could check the performance and correctness of the new operation before switching to it.
The four main components of the new system are the File Agent (File Tailer), the Event Delivery Service, the Reliable Persistent Queue, and the ETL service.
In this design, the File Agent has a much narrower remit than the Producer in our old system. It generates log files from new events and sends them to the Event Delivery Service. As soon as he receives confirmation that events have been received, this is where his work ends. There is no more complicated processing of end-of-file markers or making sure that the data has reached the end point in HDFS.
The event delivery system receives them from the Agent, translates them into the final structured format and sends them to the Queue. The service is built as a RESTful microservice using the Apollo framework and deployed using the Helios orchestrator, which is a general scheme for Spotify. This allows you to decouple customers from a certain uniform technology, and also allows you to switch to any other basic technology without interrupting service.
The queue is the core of our system and in this form is important for scaling in accordance with the growth of data flow. To cope with Hadoop downtime, it must reliably save messages for several days.
The ETL service should reliably prevent duplication and export data from the Queue to hourly assemblies in HDFS. Before he opens such a package to the downstream users, he must with a high degree of probability make sure that all the data for the package has been received.
In the figure above, you can see the block that says "Service uses the API directly." We have been feeling for some time that syslog is not an ideal API for the Event Producer. When the new system comes into operation, and the old one completely disappears from the scene, it will be logical to abandon the syslog and start working with libraries that can directly communicate with the Event Delivery Service.
Choosing a Secure Delivery Queue
Kafka 0.8
Creating a Secure Delivery Queue that reliably handles huge amounts of Spotify events is a daunting task. Our goal was to use existing tools for the hardest work. Since event delivery is the basis of our infrastructure, we would like to make the system convenient and stable. The first choice was Kafka 0.8.
There are many reports that Kafka 0.8 is successfully used in large companies around the world and Kafka 0.8 is a significantly improved version compared to the one we use now. In particular, in it the improved Kafka brokers provide reliable permanent storage. The Mirror Maker project introduced mirroring between data centers, and Camus can be used to export Avro-structured events into hourly assemblies.
To make sure that event delivery can work correctly on Kafka 0.8, we deployed the test system, which is shown in the figure above. Embed a simple Kafka Producer in the Event Delivery Service turned out to be easy. To ensure that the system works correctly from beginning to end - from Event Delivery Service to HDFS - we have implemented a variety of integration tests in our continuous integration and delivery processes.
Unfortunately, as soon as this system began processing real traffic, it began to fall apart. The only component that turned out to be stable was Camus (but since we didn’t get too much traffic through the system, we still don’t know how Camus would behave under load).
Mirror Maker gave us the most headache. We assumed that it would reliably mirror data between data centers, but this turned out to be just not the case. It works only in ideal conditions (more precisely, the best effort basis) . As soon as a problem occurs in the target cluster, the Mirror Maker simply loses data, although it also informs the source cluster that the data was successfully mirrored (note that this must be fixed in Kafka 0.9).
Mirror Makers sometimes became confused about who was the leader in the cluster. The leader sometimes forgot that he was the leader, while the rest of the Mirror Makers from the cluster could happily try to follow him. When this happened, the mirroring between the data centers stopped.
Kafka Producer also has serious stability issues. If one or more brokers were removed from the cluster, or even simply restarted, with a certain probability, the Producer entered a state from which he could not leave himself. In this state, he could not produce any events. The only way out was a complete restart of the service.
Without even addressing the resolution of these issues, we realized that it would take a lot of energy to bring the system into working condition. We will need to define a deployment strategy for Kafka Brokers and Mirror Makers, model the required capacity and plan all system components, and also set performance metrics for the Spotify monitoring system .
We were at a crossroads. Should we make a significant investment and try to make Kafka work for us? Or should you try something else?
Google Cloud Pub / Sub
While we were fighting Kafka, other members of the Spotify team began experimenting with Google Cloud. We were especially interested in Cloud Pub / Sub . It seemed that Cloud Pub / Sub will be able to satisfy our need for a reliable queue: it can store undelivered data for 7 days , provides reliability through confirmations at the application level, and has at-least-once delivery semantics.
In addition to meeting our basic needs, Cloud Pub / Sub has additional benefits:
- Accessibility - as a global service, Pub / Sub is available in all areas of the Google Cloud . Data transfer between our data centers will not go through our normal Internet service provider, but will be used by Google’s core network.
- A simple REST API - if we didn't like the client library that Google provides, then we could easily write our own.
- Operational responsibility lay with someone else - there is no need to create a resource miscalculation model or deployment strategy, set up monitoring and warnings.
Sounds great on paper ... but too good to be true? The solutions that we created on Apache Kafka, although they were not perfect, still served us well. We had a lot of experience in dealing with various failures, access to hardware and source codes, and - theoretically - we could find the source of any problem. The transition to a managed service meant that we had to entrust the operations of another organization. At the same time, Cloud Pub / Sub was advertised as a beta version - we did not know about any organization other than Google, which would use it on the scale we needed.
With all this in mind, we decided that we need a detailed test plan to be absolutely sure that if we switch to Cloud Pub / Sub, it will meet all our requirements.
Producer Test Load
The first item in our plan was testing Cloud Pub / Sub to see if it could handle our workload. Currently, our workload reaches 700K events per second at a peak. Considering future growth and possible disaster recovery scenarios, we stopped at a test load of 2M events per second. In order to completely finish Pub / Sub, we decided to publish all this amount of traffic in one data center, so that all these requests would fall into Pub / Sub machines in one zone. We made the assumption that Google planned the zones as independent domains, and that each zone could handle equal amounts of traffic. In theory, if we could shove 2M messages into one zone, we could also send a number of zones * 2M messages in all zones. Our hope was that the system would be able to handle this traffic both on the manufacturer’s side and on the consumer’s side for a long time without degrading the service.
At the very beginning, we stumbled upon a stumbling block: the Cloud Pub / Sub Java client did not work well enough. This client, like many other Google Cloud API clients, is automatically generated from API specifications. This is good if you want clients to support a wide range of languages, but not too much if you want to get a high-speed client for one language.
Fortunately, Pub / Sub has a REST API, so it was easy for us to write our own library . We created a new client, thinking first of all about his speed. To use resources more efficiently, we used asynchronous Java. We also added queues and batch processing to the client. (This is not the first time we had to roll up our sleeves and rewrite the Google Cloud API client - in another project we developed a high-speed client for the Datastore API.)
With the new client, we were ready to start loading Pub / Sub in an adult way. We used a simple generator to send bogus traffic from the Event Service to Pub / Sub. Formed traffic was redirected through two Pub / Sub topics in a ratio of 7: 3. To generate 2M messages per second, we launched Event Service on 29 machines.
Number of successful requests per second to Pub / Sub from all data centers
Number of unsuccessful requests per second to Pub / Sub from all data centers
Inbound and outbound network traffic from Event Service machines in bps
Pub / Sub passed the test with honor. We published 2M messages without any quality problems and almost did not receive server errors from the Pub / Sub backend. Enabling batch processing and compression on Event Service machines resulted in approximately 1 Gpbs of traffic to Pub / Sub.
Google Cloud Monitoring graph for total published messages in Pub / Sub
Google Cloud Monitoring graph for the number of posted posts in Pub / Sub topics
A useful side effect of our test is that we were able to compare our internal metrics with the metrics provided by Google. As shown in Charts 3 and 6, they ideally match.
Consumer Stability Test
Our second important test was devoted to consumption. For 5 days, we measured end-to-end delays under heavy loads. At the time of the test, we published, on average, about 800K messages per second. To simulate real loads, the speed of publication changed throughout the day. To ensure that we can use several topics at the same time, all data was published for two topics in a ratio of 7: 3.
Slightly surprised by the behavior of Cloud Pub / Sub is that it’s necessary to create subscriptions before saving messages - while no subscriptions exist, no data is saved. Each subscription stores data independently, and there are no restrictions on how many subscriptions a consumer may have. Consumers are coordinated on the server side, and the server is responsible for sufficient message allocation for all consumers requesting data. This is very different from Kafka, where data is stored in the created topic and the number of consumers in the topic is limited by the number of sections in the topic.
In our test, we created a subscription, an hour later we began to consume data. We consumed them in batches of 1000 messages. Since we did not try to reach the consumption limit, we just wanted to slightly exceed the current peak level. It took 8 hours. After we reached it, Consumers continued to work at the same level that corresponded to the speed of publication.
The average end-to-end delay, which we measured during the test period — including the restoration of the backlog — was around 20 seconds. We did not observe message losses during the entire test period.
Decision
On these tests, we made sure that Cloud Pub / Sub is the right choice for us. Delays were small and constant, and the only limitation in capacity we encountered was the established quota. In short, choosing Cloud Pub / Sub instead of Kafka 0.8 for our new message delivery platform was the obvious choice.
Next step
After the events are securely stored in Pub / Sub, it’s time to export them to HDFS. To take full advantage of Google Cloud, we decided to try Dataflow.
In the last article of this series, we will talk about how Dataflow was used for our purposes. Stay with us!
Source: https://habr.com/ru/post/320192/
All Articles