As I parsed the entire database of Metacritic games
Metacritic is an English-language site aggregator that collects reviews on music albums, games, movies, TV shows and DVDs. (from wikipedia).
Libraries used: lxml , asyncio , aiohttp (lxml is a library for parsing HTML pages using Python, asyncio and aiohttp will be used for asynchrony and fast data retrieval). We will also actively use XPath. Who does not know what it is, an excellent tutorial .
First you have to do some pens. Go to www.metacritic.com/browse/games/genre/metascore/action/all?view=detailed and collect all
URLs from this list:
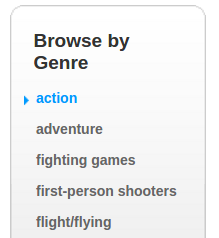
')
And save them to a .json file with the name genres.json . We will use these links to parse all games from the site by genre.
A little thought, I decided to collect all the links to games in .csv files, divided into genres. Each file will have a name corresponding to the genre. Go to the above link and immediately see the page of the genre Action. We notice that there is a pagination.
Look in the html page:

And we see that the sought-for element a , which contains the maximum number of pages, is a heir of the li element with a unique attribute class = page last_page , also note that the urls of all pages except the first one are <page 1st url> + <& page = page_number>, and that the second page in the request parameter is number 1.
Putting XPath to get the maximum page number:
// li [@ class = 'page last_page'] / a / text ()
Now you need to get each link to each game from this sheet.
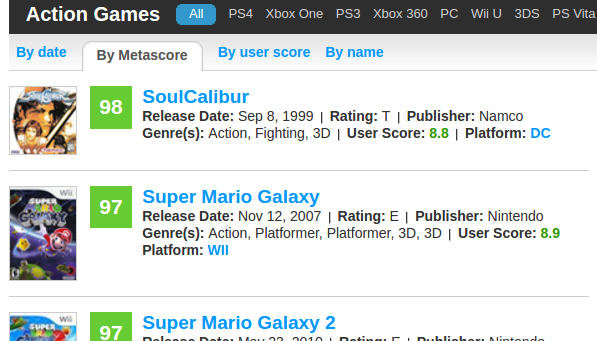
We look at the layout of the sheet and learn html.
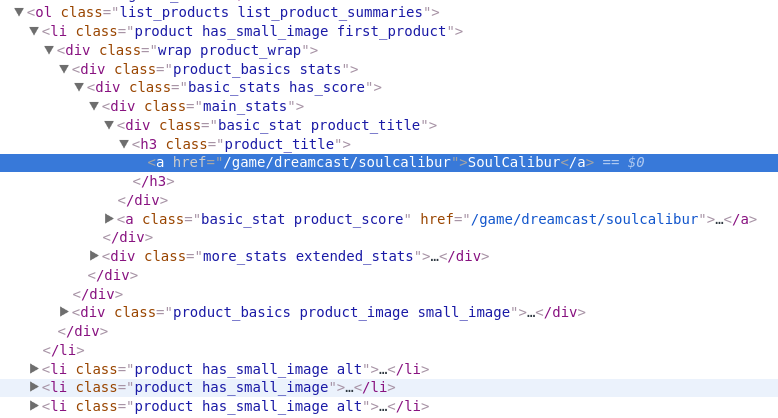
First, we need to get the list itself (ol) as the root element for the search. It has the attribute class = list_products list_product_summaries, which is unique for the page's html code. Then we see that li has a child element h3 with a child element a , in the href attribute of which the desired link to the game is located.
Putting it all together:
// ol [@ class = 'list_products list_product_summaries'] // h3 [@ class = 'product_title'] / a / @ href
Fine! Half the battle is done, now you need to programmatically organize a cycle through the pages, collecting links and saving them to files. To speed up, parallelize the operation on all the cores of our PC.
Merge all files with links into one file. If you are under Linux, then just use cat and redirect STDOUT to a new file. Under Windows we will write a small script and launch it in the folder with the genre files.
Now we have one big .csv file with links to all Metacritic games. Large enough, 25 thousand records. Plus there are duplicates, since one game can have several genres.
What is our plan next? Go through each link and extract information about each game.
Go, for example, to the Portal 2 page.
We will extract:
To shorten the post, I will immediately cite the xpaths that extracted this information.
Name of the game:
// h1 [@ class = 'product_title'] // span [@ itemprop = 'name'] // text ()
We may have several platforms, so two requests will be needed:
// span [@ itemprop = 'device'] // text ()
// li [@ class = 'summary_detail product_platforms'] // a // text ()
Our description is in Summary:
// span [@ itemprop = 'description'] // text ()
Metascore:
// span [@ itemprop = 'ratingValue'] // text ()
Genre:
// span [@ itemprop = 'description'] // text ()
Date of issue:
// span [@ itemprop = 'datePublished'] // text ()
We remember that we have 25 thousand pages and grab our heads. What to do? Even with a few threads will be long. There is a way out - asynchrony and non-blocking cortices. Here is a great video from PyCon . Async-await simplifies asynchronous programming in python 3.5.2. Tutorial on Habré .
We write the code for our parser.
It turned out very well, on my computer Intel i5 6600K, 16 GB RAM, lan 10 mb / s it turned out about 10 games / sec. You can correct the code and adapt the script to the music \ movies.
Libraries used: lxml , asyncio , aiohttp (lxml is a library for parsing HTML pages using Python, asyncio and aiohttp will be used for asynchrony and fast data retrieval). We will also actively use XPath. Who does not know what it is, an excellent tutorial .
Getting links to all game pages
First you have to do some pens. Go to www.metacritic.com/browse/games/genre/metascore/action/all?view=detailed and collect all
URLs from this list:
')
And save them to a .json file with the name genres.json . We will use these links to parse all games from the site by genre.
A little thought, I decided to collect all the links to games in .csv files, divided into genres. Each file will have a name corresponding to the genre. Go to the above link and immediately see the page of the genre Action. We notice that there is a pagination.
Look in the html page:
And we see that the sought-for element a , which contains the maximum number of pages, is a heir of the li element with a unique attribute class = page last_page , also note that the urls of all pages except the first one are <page 1st url> + <& page = page_number>, and that the second page in the request parameter is number 1.
Putting XPath to get the maximum page number:
// li [@ class = 'page last_page'] / a / text ()
Now you need to get each link to each game from this sheet.
We look at the layout of the sheet and learn html.
First, we need to get the list itself (ol) as the root element for the search. It has the attribute class = list_products list_product_summaries, which is unique for the page's html code. Then we see that li has a child element h3 with a child element a , in the href attribute of which the desired link to the game is located.
Putting it all together:
// ol [@ class = 'list_products list_product_summaries'] // h3 [@ class = 'product_title'] / a / @ href
Fine! Half the battle is done, now you need to programmatically organize a cycle through the pages, collecting links and saving them to files. To speed up, parallelize the operation on all the cores of our PC.
# get_games.py import csv import requests import json from multiprocessing import Pool from time import sleep from lxml import html # . root = 'http://www.metacritic.com/' # Metacritic 429 'Slow down' # , . SLOW_DOWN = False def get_html(url): # Metacritic User-Agent. headers = {"User-Agent": "Mozilla/5.001 (windows; U; NT4.0; en-US; rv:1.0) Gecko/25250101"} global SLOW_DOWN try: # - 429, # 15 . if SLOW_DOWN: sleep(15) SLOW_DOWN = False # html requests html = requests.get(url, headers=headers).content.decode('utf-8') # html , SLOW_DOWN true. if '429 Slow down' in html: SLOW_DOWN = True print(' - - - SLOW DOWN') raise TimeoutError return html except TimeoutError: return get_html(url) def get_pages(genre): # Games with open('Games/' + genre.split('/')[-2] + '.csv', 'w') as file: writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL) # url > 1 genre_page_sceleton = genre + '&page=%s' def scrape(): page_content = get_html(genre) # lxml html . document = html.fromstring(page_content) try: # int. lpn_text = document.xpath("//li[@class='page last_page']/a/text()" last_page_number = int(lpn_text)[0]) pages = [genre_page_sceleton % str(i) for i in range(1, last_page_number)] # . pages += [genre] # . for page in pages: document = html.fromstring(get_html(page)) urls_xpath = "//ol[@class='list_products list_product_summaries']//h3[@class='product_title']/a/@href" # url . games = [root + url for url in document.xpath(urls_xpath)] print('Page: ' + page + " - - - Games: " + str(len(games))) for game in games: writer.writerow([game]) except: # 429 . . scrape() scrape() def main(): # .json . dict = json.load(open('genres.json', 'r')) p = Pool(4) # . map . p.map(get_pages, [dict[key] for key in dict.keys()]) print('Over') if __name__ == "__main__": main() Merge all files with links into one file. If you are under Linux, then just use cat and redirect STDOUT to a new file. Under Windows we will write a small script and launch it in the folder with the genre files.
from os import listdir from os.path import isfile, join onlyfiles = [f for f in listdir('.') if isfile(join(mypath, f))] fout=open("all_games.csv","a") for path in onlyfiles: f = open(path) f.next() for line in f: fout.write(line) f.close() fout.close() Now we have one big .csv file with links to all Metacritic games. Large enough, 25 thousand records. Plus there are duplicates, since one game can have several genres.
Extract information about all games
What is our plan next? Go through each link and extract information about each game.
Go, for example, to the Portal 2 page.
We will extract:
- Name of the game
- Platforms
- Description
- Metascore
- Genre
- Date of issue
To shorten the post, I will immediately cite the xpaths that extracted this information.
Name of the game:
// h1 [@ class = 'product_title'] // span [@ itemprop = 'name'] // text ()
We may have several platforms, so two requests will be needed:
// span [@ itemprop = 'device'] // text ()
// li [@ class = 'summary_detail product_platforms'] // a // text ()
Our description is in Summary:
// span [@ itemprop = 'description'] // text ()
Metascore:
// span [@ itemprop = 'ratingValue'] // text ()
Genre:
// span [@ itemprop = 'description'] // text ()
Date of issue:
// span [@ itemprop = 'datePublished'] // text ()
We remember that we have 25 thousand pages and grab our heads. What to do? Even with a few threads will be long. There is a way out - asynchrony and non-blocking cortices. Here is a great video from PyCon . Async-await simplifies asynchronous programming in python 3.5.2. Tutorial on Habré .
We write the code for our parser.
from time import sleep import asyncio from aiohttp import ClientSession from lxml import html # , . games_urls = list(set([line for line in open('Games/all_games.csv', 'r')])) # . result = [] # . total_checked = 0 async def get_one(url, session): global total_checked async with session.get(url) as response: # . page_content = await response.read() # . item = get_item(page_content, url) result.append(item) total_checked += 1 print('Inserted: ' + url + ' - - - Total checked: ' + str(total_checked)) async def bound_fetch(sm, url, session): try: async with sm: await get_one(url, session) except Exception as e: print(e) # 30 429. sleep(30) async def run(urls): tasks = [] # . . sm = asyncio.Semaphore(50) headers = {"User-Agent": "Mozilla/5.001 (windows; U; NT4.0; en-US; rv:1.0) Gecko/25250101"} # User-Agent, Metacritic async with ClientSession( headers=headers) as session: for url in urls: # . task = asyncio.ensure_future(bound_fetch(sm, url, session)) tasks.append(task) # . await asyncio.gather(*tasks) def get_item(page_content, url): # lxml html . document = html.fromstring(page_content) def get(xpath): item = document.xpath(xpath) if item: return item[-1] # - , None return None name = get("//h1[@class='product_title']//span[@itemprop='name']//text()") if name: name = name.replace('\n', '').strip() genre = get("//span[@itemprop='genre']//text()") date = get("//span[@itemprop='datePublished']//text()") main_platform = get("//span[@itemprop='device']//text()") if main_platform: main_platform = main_platform.replace('\n', '').strip() else: main_platform = '' other_platforms = document.xpath("//li[@class='summary_detail product_platforms']//a//text()") other_platforms = '/'.join(other_platforms) platforms = main_platform + '/' + other_platforms score = get("//span[@itemprop='ratingValue']//text()") desc = get("//span[@itemprop='description']//text()") # . return {'url': url, 'name': name, 'genre': genre, 'date': date, 'platforms': platforms, 'score': score, 'desc': desc} def main(): # . loop = asyncio.get_event_loop() future = asyncio.ensure_future(run(games_urls)) loop.run_until_complete(future) # . - . print(result) print('Over') if __name__ == "__main__": main() It turned out very well, on my computer Intel i5 6600K, 16 GB RAM, lan 10 mb / s it turned out about 10 games / sec. You can correct the code and adapt the script to the music \ movies.
Source: https://habr.com/ru/post/319966/
All Articles