Low-latency InfiniBand network performance on the HPC HUB virtual cluster

Modeling of complex physical processes today is considered as an important technological opportunity by many modern companies. A widely used approach to create calculators capable of calculating complex models is to create cluster systems, where the computing node is a general-purpose server connected to a low latency network and managed by its own OS (usually from the GNU / Linux family).
Introducing the virtualization layer into the system software of the computational clusters allows creating a “virtual cluster” within a few minutes. Such virtual clusters within the same OpenStack infrastructure are completely independent. The user programs inside them can be changed as needed by the user without any coordination with someone, and the logical devices on which user data resides are not available to other virtual clusters.
Low latency network support with virtualization solutions is a separate complex problem. For application programs, in most cases, modern KVM-based virtualization leads to minimal loss of computing power (<1%). However, specialized tests of low latency networks show no virtualization overhead of more than 20% on synchronization operations.
The value of low latency networks for HPC
Modern tasks of modeling physical processes require large amounts of memory and computational power in order for the calculations to be performed in practice in realistic time. Such large amounts of RAM and such large numbers of computational cores are difficult and expensive to combine in one system running one classic OS using modern technologies.
')
A much cheaper and now widely used alternative approach is the creation of cluster systems, where the computing node is a general-purpose computer controlled by its own OS. At the same time, the cluster computing nodes are synchronized and jointly managed by special software that provides the launch, maintenance and shutdown of the so-called "parallel applications". The latter are independent processes in the OS of nodes synchronized with each other due to interaction in the network. Further we will call such networks “computational networks”, computational nodes — “cluster nodes” or simply “nodes”, the control software — “cluster software”.
Modern programming concepts use two basic methods of parallelization: by data and by processes. To simulate natural phenomena, data paralleling is most often used, namely:
- at the beginning of the calculation step, parts of the data are distributed to different solvers and they perform some actions on these parts
- then the calculators exchange information according to various numerical schemes (usually quite rigidly programmed) in order to have the initial data for the next step
From the point of view of programming practice, a calculator can be anything that has at least one processor, a certain amount of memory and access to a computer network for exchanges with other calculators. In essence, a computer is a subscriber of a computer network with some (albeit relatively small) computing power. The calculator can be either a thread within a process, or a process within an OS, or a virtual machine with one or more virtual processors, or a hardware node with some kind of reduced specialized OS, etc.
The most widespread API standard for creating modern parallel applications is MPI, which exists in several implementations. The Intel OpenMP API standard, which is designed to create parallel applications within a single OS on a multiprocessor node, is also widely used. Since modern cluster nodes contain multi-core processors with a large amount of memory, a large number of options for determining the "calculator" within the framework of the parallelization paradigm of data and the implementation of this paradigm based on the approach of parallel applications are possible. The most common are two approaches:
- one processor core - one calculator
- one multiprocessor node - one calculator
To implement the first approach, it is sufficient to use MPI, for which it was actually created. In the second approach, a bunch of MPI + OpenMP is often used, where MPI is used for communication between nodes, and OpenMP for parallelization within a node.
Naturally, in a situation where parallel applications run on several nodes, the total performance depends not only on processors and memory, but also on network performance. It is also clear that network exchanges will be slower than exchanges within multiprocessor systems. Those. Cluster systems are almost always slower compared to equivalent multiprocessor systems (SMP). In order to minimize the degradation of the exchange rates in comparison with SMP machines, special low-latency computer networks are used.
Key characteristics of computer networks
The key characteristics of specialized computer networks are the latency and width of the channel (the exchange rate for large amounts of data). The transfer rate of large amounts of data is important for various tasks, for example, when nodes need to send each other the results obtained at the current calculation step in order to collect initial data for the next step. Latency plays a key role in the transmission of small messages, such as the synchronization messages necessary for the nodes to be aware of the status of other nodes whose data they need. Synchronization messages are usually very small (typical size is several tens of bytes), but they are used to prevent logical races and deadlocks (race condition, deadlock). The high speed of synchronization messages actually distinguishes a computational cluster from its closest relative - a computational farm, where the network between nodes does not provide the properties of low latency.
Intel Infiniband is one of the most popular low latency network standards today. It is the equipment of this type that is often used as a computer network for modern cluster systems. There are several generations of Infiniband networks. The most common standard now is Infiniband FDR (2011). Still remains the standard QDR (2008). Equipment suppliers are now actively promoting the next standard Infiniband EDR (2014). Infiniband ports typically consist of aggregated groups of basic bi-directional buses. The most common ports are 4x.
Latest Generation Infiniband Network Features
| QDRx4 | FDRx4 | EDRx4 | |
| Full bandwidth, Gbit / s | 32 | 56 | 100 |
| Latency port-port, ms | 1.3 | 0.7 | 0.7 |
As you know, virtualization introduces some of its specific delays when guest systems work with devices. Not an exception in this case, and the network of low latency. But because low latency (latency) is their most important feature, interfacing with virtualization environments is crucial for such networks. However, their bandwidth, as a rule, remains the same as without virtualization in a wide range of connection parameters. An important step in the development of Infiniband, made relatively recently (2011), is the use of SR-IOV technology. This technology allows the physical network adapter Infiniband to turn into a set of virtual devices - virtual functions VF. Such devices look like independent Infiniband adapters and, for example, can be handed over to exclusive control of various virtual machines or some high-load services. Naturally, IB VF adapters work on other algorithms, and their characteristics differ from the original IB adapters without SR-IOV support included.
Group operations exchanges between nodes
As already mentioned above, the MPI library is currently the most popular HPC tool. There are several basic options for implementing the MPI API:
The MPI libraries contain the basic functions necessary to implement parallel computing. Critical to HPC applications are interprocess messaging functions, especially group synchronization and messaging functions. It is worth noting that most often the group refers to all processes of a parallel application. Detailed MPI API descriptions are easy to find on the web:
The basics of the algorithms used to implement MPI are well described in [1], and many articles on this topic can be found here . Evaluations of the effectiveness of these algorithms are the subject of a large number of papers [2, 3, 4, 5]. Most often, the estimates are constructed using the methods of asymptotic analysis of the theory of algorithms and operate with concepts connection establishment time information unit transfer rate the number of units of information transmitted, the number of processors involved.
Naturally, for modern multiprocessor systems connected by a network of low latency, the parameters and it is necessary to take different for processors that interact within the same node and are located on different nodes, on the same multi-core chip and on different ones. However, a good initial estimated approximation for and in the case of tasks using several nodes of a computing cluster, are the values of latency and throughput of the computer network.
As it is easy to understand, group synchronization operations are the most demanding of the “low latency” property of the network and the scalability of this property. For our tests, we, like other authors [6], used the following 3 operations:
broadcast
The simplest of group operations is broadcast (broadcast). One process sends the same message to all the others (M denotes a buffer with data. Taken from [1]).

In computing programs, broadcast is often used to distribute some conditions, parameters at the beginning of an account and between iterations. Broadcast is often an element of the implementation of other, more complex collective operations. For example, broadcast is used in some implementations of the barrier function. There are several variants of algorithms for broadcast implementation. The optimal running time for a broadcast on a non-blocking switch full-duplex channels without hardware acceleration is:
all-reduce
The all-reduce operation performs the associative operation specified in the parameters on the data in the memory of the group of calculators, and then reports the result to all the calculators of the group. (Sign means the specified associative operation. Taken from [1]).

From the point of view of the structure of network exchanges, all-reduce is similar to the all-to-all broadcast function. This operation is used to sum or multiply, search for a maximum or a minimum among the operands located on different calculators. Sometimes this function is used as a barrier. The optimal time for an all-reduce operation on a non-blocking switch with full duplex channels without hardware acceleration is:
all-to-all
The all-to-all operation is sometimes referred to as “personalized all-to-all” or “total exchange”. During this operation, each calculator forwards the message to each other calculator. All messages can be unique (Taken from [1]).
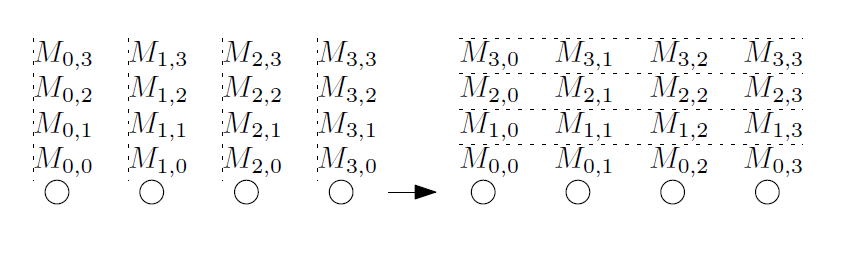
This operation is intensively used by various algorithms, such as Fourier transform, matrix transforms, sorting, parallel operations on databases. This is one of the most "difficult" collective operations. For this collective operation, the optimal algorithm depends on the ratios of the values of key variables. , , and size of transmitted messages . When using the hypercube algorithm, which is not optimal in terms of volume of shipments and is used for small messages, the time estimate is:
Other approaches to testing HPC media are also used. For example, with the help of integral tests that simulate the calculations of common problems. One of the most popular sets of integrated tests is the NAS parallel benchmarks . This test was also used to test virtual HPC environments [7].
Testing method
For the performance tests outlined in this paper, we used servers with Intel Xeon processors with 64 GB RAM and IB ConnectX-3 adapters. OpenMPI was installed on virtual and physical nodes, the node-node connection was tested using the perftest and OSU benchmarks utilities.
In details
Intel H2000JF family of servers (S2600JF motherboard) with Intel Xeon E5-2680v2 2.8 GHz processors (10 cores, HyperThreading off), 64 GB RAM of DDR3 standard, IB with ConnectX-3 family of connectX-3 (ConnectX3-rel-2_36_5000 firmware) connected via the Mellanox SwitchX switch (36 ports SX6036 FDR).
OS CentOS Linux release 7.2.1511 (CentOS 7.2), kernel 3.10.0-327.18.2.el7.x86_64, qemu / KVM customized based on 2.3.0 (version 1.5.3 is used in CentOS 7 distribution), Mellanox OFED 3.3 driver -1.0.4, qemu-kvm supported NUMA mode.
Guest OS CentOS Linux release 7.1.1503 (CentOS 7.1), kernel 3.10.0-229.el7.x86_64, Mellanox ConnectX-3 drivers. Each virtual machine was the only one on its physical server and occupied all the processors and 48 GB of RAM on it, overcommit on the processor cores was turned off.
IB adapters were switched to SR-IOV support mode, and 2 VF per adapter was created. One of the VFs was exported to KVM. Accordingly, only one Infiniband adapter was visible in the guest OS, and two in the host OS: mlx4_0 and mlx4_1 (VF).
OpenMPI version 1.10.3rc4 (included in the Mellanox OFED 3.3-1.0.4 packages) was installed on virtual and physical nodes. The node-to-node connection was tested using perftest 0.19.g437c173.33100.
Group tests were performed using OSU benchmarks version 5.3.1, compiled using gcc 4.8.5 and the above OpenMPI. Each OSU benchmarks result is an averaging of 100 or 1000 measurements, depending on a number of conditions.
On physical nodes, the tuned daemon has a latency-performance profile installed. On virtual nodes it was turned off.
OS CentOS Linux release 7.2.1511 (CentOS 7.2), kernel 3.10.0-327.18.2.el7.x86_64, qemu / KVM customized based on 2.3.0 (version 1.5.3 is used in CentOS 7 distribution), Mellanox OFED 3.3 driver -1.0.4, qemu-kvm supported NUMA mode.
Guest OS CentOS Linux release 7.1.1503 (CentOS 7.1), kernel 3.10.0-229.el7.x86_64, Mellanox ConnectX-3 drivers. Each virtual machine was the only one on its physical server and occupied all the processors and 48 GB of RAM on it, overcommit on the processor cores was turned off.
IB adapters were switched to SR-IOV support mode, and 2 VF per adapter was created. One of the VFs was exported to KVM. Accordingly, only one Infiniband adapter was visible in the guest OS, and two in the host OS: mlx4_0 and mlx4_1 (VF).
OpenMPI version 1.10.3rc4 (included in the Mellanox OFED 3.3-1.0.4 packages) was installed on virtual and physical nodes. The node-to-node connection was tested using perftest 0.19.g437c173.33100.
Group tests were performed using OSU benchmarks version 5.3.1, compiled using gcc 4.8.5 and the above OpenMPI. Each OSU benchmarks result is an averaging of 100 or 1000 measurements, depending on a number of conditions.
On physical nodes, the tuned daemon has a latency-performance profile installed. On virtual nodes it was turned off.
Tests were run on two nodes (40 cores). The measurements were carried out in series of 10-20 measurements. As a result, the arithmetic average of the three lowest values was taken.
results
The network parameters listed in the table are ideal, and in a real situation they are unattainable. For example, the latency between two nodes with Infiniband FDR adapters (datagram mode), measured using ib_send_lat , is 0.83 µs for small messages, and the useful throughput (excluding service information) between two nodes, measured using ib_send_bw , is 6116.40 MB / with (~ 51.3 Gbit / s). Penalty latency and bandwidth in real systems due to the following factors:
- additional switch latency
- delays due to OS nodes
- loss of bandwidth to ensure the transfer of service information protocols
The launch was carried out on the server with the command:
ib_send_bw -F -a -d mlx4_0 on the client:
ib_send_bw -F -a -d mlx4_0 <server-name> So ib_send_lat between a pair of guest OSs located on different physical servers shows a latency of 1.10 µs (an increase in delay of 0.27 µs, a ratio of latencies of native and virtualized IB is 0.75), and ib_send_bw shows a bandwidth of 6053.6 MB / s (~ 50.8 Gbit / s , 0.99 of the useful channel width without virtualization). These results are in good agreement with the results of tests of other authors, for example [6].
It is worth noting that in the host OS, the test did not work with the SR-IOV VF, but with the adapter itself. The results are presented in three graphs:
- all message sizes
- messages only up to 256 bytes inclusive
- relationship of test execution times for native Infiniband and for VF
The broadcast test was launched both in the host and in the guest OS as:
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_bcast The worst time ratio is 0.55, for most tests the ratio is not worse than 0.8.



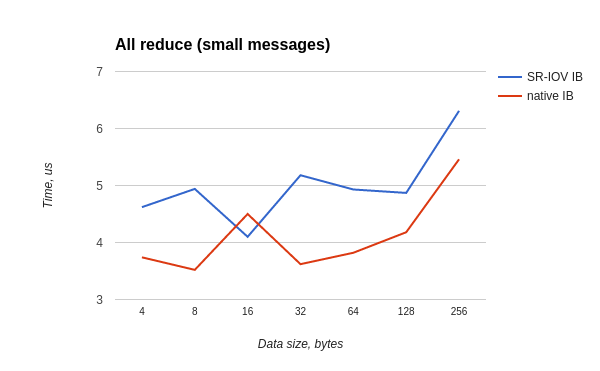
The all-reduce test started in both the host and the guest OS as:
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_allreduce The worst time ratio is 0.7, for most tests the ratio is not worse than 0.8.


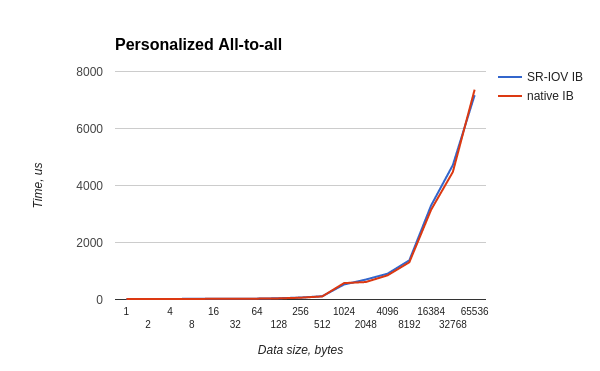
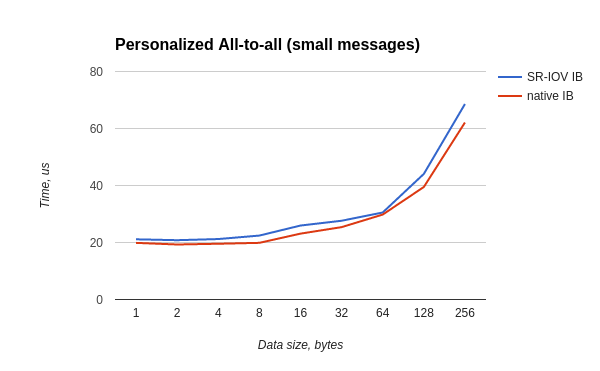
The all-to-all test started in both the host and the guest OS as:
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_alltoall The worst time ratio is 0.87, for most tests the ratio is not worse than 0.88.

Discussion
The gear form of the graphs presented in the tests, on the one hand, is due to the result of a not very large sample of tests, but, on the other hand, it is just the desired effect of the method of selection of the smallest measured values used for profiling programs. The rationale for this method is the reasoning that a code fragment cannot execute faster than its maximum speed, and all processes that can occur in the system simultaneously with the execution of the test code either do not affect its speed or slow it down. The presence of seemingly contradictory results, when the virtualized test is executed a little faster (2-5% of acceleration), than the non-virtualized one should be attributed to the features of the drivers and firmware of IB adapters, which, firstly, have their own optimization schemes, and secondly, still a little work differently in both cases (data buffer sizes, interrupt handling features, etc.).
The features of modern virtualization technologies introduce additional sources of delay compared to the situation where there is no virtualization layer. Significant for HPC are three types of such delays:
- Slowing the speed of the network of low latency. In our particular case, slowing down Infiniband in the SR-IOV virtual function mode. This delay is the central theme of this work and is discussed above.
- Programs and services that are external to the virtualization shell will occasionally require CPU time, and will reset the caches of counting applications. In a rather complicated way, it will introduce a variety of desynchronization and delays in counting applications running under the virtualization shell. Such systematic interference can be extremely unpleasant for any kind of "extreme" programs, or for improperly optimized ones. Of course, it is worth understanding that without a virtualization layer, counting programs will work faster. However, in most practically important cases, the performance penalty due to the presence of the control code outside the virtualization shell on modern multi-core nodes does not exceed a few percent, and most often it is <1%. In addition, there are a number of approaches that allow you to select and fix the processor cores, which will deal with loads outside the virtualization shell, excluding them from the virtualized environment. As a result, the impact on the processor cores and their caches inside the virtualization shells can be minimized.
- When working with a virtual APIC, there are numerous exits to the hypervisor, which is quite expensive in terms of delay (tens of microseconds). This problem has become relevant recently due to the growth of requests for multi-core virtual machines, and attention has been paid to it at various conferences and in specialized publications, for example [8,9]. Such delays occur when interrupts are delivered, including from SR-IOV devices (in our case, Infiniband) on a guest, and when the processor core wakes up from a sleeping state (IPI), for example, when a message is received
In the opinion of the authors, the most radical methods of reducing virtualization penalties for handling interrupts are either using Intel processors with vAPIC support, or using container virtualization (for example, LXC) for counting nodes. The materiality of the delay arising in the handling of interrupts in KVM is also indirectly indicated in [7], where the authors establish a link between the increase in the number of interruptions and a significant decrease in the performance of the virtualized version of the test.
It is difficult to estimate these delays, except the first one, using simple formulas, similar to those given in [1], for several reasons:
- The first and main one is that these delays appear asynchronously with a counting-task algorithm that works in a virtualized environment.
- The second reason is that these delays depend on the “history” of the computational node as a whole, including both the counting task algorithm and the virtualization software — the states of the caches, memory, controllers
It is also important to understand that when a large number of packets are sent over a low latency network, in particular, when large messages are fragmented, the interrupt generation rate will grow according to a complex law, which can lead to nontrivial dependencies of the message transfer rate on their length and again stack of virtualization software.
The creators of traditional cluster computing systems make great efforts to eliminate interference for computing tasks:
- shutting down all unnecessary OS services
- minimization of all network exchanges
- minimization of any other interrupt sources for nodes
In the case of a combination of virtualization and cloud software, we are only at the beginning of this optimization path for high performance computing.
findings
Comparative tests of a set of three commonly used MPI operations (broadcast, all-reduce, personalized all-to-all) showed that the virtualization environment based on qemu / KVM and using SR-IOV technology shows an increased test time by an average of 20% ( in the worst case, by 80% with broadcast packets of sizes 16 and 32Kb). This drop in performance, although noticeable, is not critical for most parallel applications related to continuum mechanics, molecular dynamics, signal processing, etc. Ease of use of a virtualized environment, the ability to quickly expand the computational field and its settings multiply compensates for the costs of a possible increase in the computing time.
For tasks that require rapid random access of one node to the memory of another, such a delay can be critical. Most likely, it will not allow efficient use of virtualized clusters for solving such problems.
In practice, the degradation of computational program performance is often much less than the indicated values (max 20%). This is because most of the time well-written and widely used programs still consider and process data inside the calculator, rather than perform synchronization or data transfer operations. After all, the authors of parallel code always strive to select such algorithms and implementation techniques that minimize the need for synchronization and transfers between calculators.
Literature
In details
- A. Grama, A. Gupta, G. Karypis, V. Kumar. Introduction to Parallel Computing, Second Edition. Addison-Wesley, 2003
- R. Thakur, W. Gropp. Improving the Mpi Collective Communication on Switched Networks, 2003
- R. Thakur, R. Rabenseifner, W. Gropp. Optimization of Collective Communication Operations in MPICH. Int'l Journal of High Performance Computing Applications, - 2005 - Vol 19 (1) - pp. 49-66.
- J. Pješivac-Grbović, T. Angskun, G. Bosilca, GE Fagg, E. Gabriel, JJ Dongarra. Performance analysis of MPI collective operations. Cluster Computing - 2007 - Vol. 10 - p.127.
- BS Parsons. Accelerating MPI communication and imbalance awareness. Ph. D. Thesis on Computer Science, Purdue University, USA, 2015
- J. Jose, M. Li, X. Lu, KC Kandalla, MD Arnold, DK Panda. SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience. International Symposium on Cluster, May 2011
- A. Kudryavtsev, V. Koshelev, A. Avetisyan. Modern HPC cluster virtualization using KVM and Palacios. High Performance Computing (HiPC) Conference, 2012
- D. Matlack. KVM Message Passing Performance. KVM forum, 2015
- R. van Riel. KVM vs. Message Passing Throughput, Reducing Context Switching Overhead. Red Hat KVM Forum 2013
The material was prepared by Andrey Nikolaev, Denis Lunev, Anna Subbotina, Wilhelm Bitner.
Source: https://habr.com/ru/post/319940/
All Articles