In-depth training with the support of a virtual manager in the game against inefficiency

About the success of Google Deepmind now know and talk. Algorithms DQN (Deep Q-Network) defeat Man with a good margin of more and more games. The achievements of recent years are impressive: in literally tens of minutes of learning, the algorithms learn and win a person in Pong and other Atari games. Recently we’ve come to the third dimension - we win a person in DOOM in real time, as well as learn to drive cars and helicopters.
DQN was used to teach AlphaGo by playing thousands of games by itself. When it was not yet fashionable, in 2015, anticipating the development of this trend, the management of Phobos in the person of Alexey Spassky, ordered the Research & Development department to conduct a study. It was necessary to consider the existing machine learning technologies with a view to the possibility of using them to automate the victory in management games. Thus, in this article we will discuss the design of a self-learning algorithm in the game of a virtual manager against a living team for increasing productivity.
The applied task of analyzing machine learning data classically has the following solution steps:
- problem formulation;
- data collection;
- data preparation;
- formulation of hypotheses;
- model building;
- model validation;
- presentation of results.
This article will discuss the key decisions in the design of an intelligent agent.
More detailed descriptions of the stages from setting the task to presenting the results will be described in the following articles if the reader is interested. Thus, it is likely that we will be able to solve the problem of a story about a multidimensional and ambiguous research result without losing clarity.
Algorithm selection
So, to fulfill the task of finding the maximum efficiency of team management, it was decided to use deep learning with reinforcement, namely Q-learning. The intellectual agent forms the utility function Q of each action available to him on the basis of remuneration or punishment from a transition to a new state of the environment, which gives him the opportunity not to accidentally choose a strategy of behavior, but to take into account the experience of the previous interaction with the gaming environment.
The main reason for choosing DQN is that the agent doesn’t need a model to train with this method, nor to select an action. This is a critical requirement for the learning method for the simple reason that a formalized model of a collective of people with practical predictive power does not yet exist. However, an analysis of the success of artificial intelligence in logic games shows that the advantages of an approach based on expert knowledge become more pronounced as the environment becomes more complex. This is found in checkers and chess, where the evaluation of actions based on the model was more successful than Q-learning.
One of the reasons that training with reinforcements still leaves office clerks without work is that the method does not scale well. The Q-learning agent conducting the research is an active student who must repeatedly apply every action in every situation in order to create his own Q-function for evaluating the benefits of all possible actions in all possible situations.

If, as in the old vintage games, the number of actions is calculated by the number of buttons on the joystick, and the states by the ball position, then the agent takes dozens of minutes and hours of training to defeat the person, then in chess and GTA5 the combinatorial explosion already makes the number of combinations of game states and possible actions of space for the passage of the student.
Hypothesis and model
To effectively use Q-learning to manage a team, we need to minimize the dimension of environmental states and actions.
Our solutions:
- The first engineering solution was to present management activities in the form of a collection of mini-games. Each of them has discrete numbers of states and actions such that the order of combinations is comparable to successfully solved game problems. Thus, it is not necessary to build an algorithm that will search for an optimal control strategy in multidimensional space, but many agents are superior to the human player in tactical games. An example of such a game is task management in YouTrack. State of the environment (roughly) - time in work and status, and actions - opening, re-opening task, the appointment of a responsible. More details below.
An example of an online learning simple game:
https://cs.stanford.edu/people/karpathy/convnetjs/demo/rldemo.html
- Every office employee is an intelligent agent complicating the environment with a variety of his behavior. Personalization allows you to avoid multi-agent environments, so with one employee one learning agent plays. In the task-based mini-game, the agent receives an award when an employee works more efficiently (solves problems faster). If an employee (say, a developer) turns out to be unmanageable for a Q-learning agent, the algorithm will not converge.
- The most important simplification. In the mini-game on the setting of the problem to the employees - continuous multi-dimensional game states, if only because of the time parameter spent on the task. And the worst - not obviously determined by the rewards for the actions of the agent. The gaming environment, as a finite set of states for each mini-game and the calculation of the promotion in a particular state, is 90% formalized by our business logic managers. This is the most time-consuming and important point, because it is in the formula for expert assessment of states that the expert knowledge is contained, which is an implicit model of the environment and actions, and also determines the amount of remuneration in the agent’s training. The success of the agent's training depended on the predictive power of this implicit model.
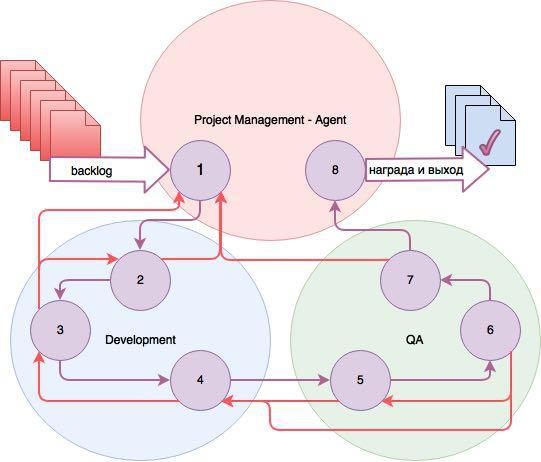
The diagram shows the states of the three game environments for the three agents who manage the work on the task.
States:
- Task registered (backlog);
- The task is open;
- In work;
- The development is complete, the task is open for testing (QA);
- Open for testing;
- Being tested;
- Ready, tested;
- Closed.
The list of actions for each of the three agents is different. Project Manager - Agent assigns the performer and tester, the time and priority of the task. The agents working with Dev and QA are personal for each artist and tester. If there is a transfer of a task further, agents receive rewards, if the task comes back - punishment.
The greatest reward all agents receive at the closing task. Also for Q-learning, DF and LF (the factor of discounting and training, respectively) were selected in such a way that the agents were focused on closing the task. In the general case, the calculation of reinforcement takes place according to the optimal control formula, which takes into account, among other things, the difference in the estimate of time and real costs, the number of task returns, and so on. The advantage of this solution is its ability to scale to a larger team.
Conclusion
The iron on which the calculations were performed - GeForce GTX 1080.
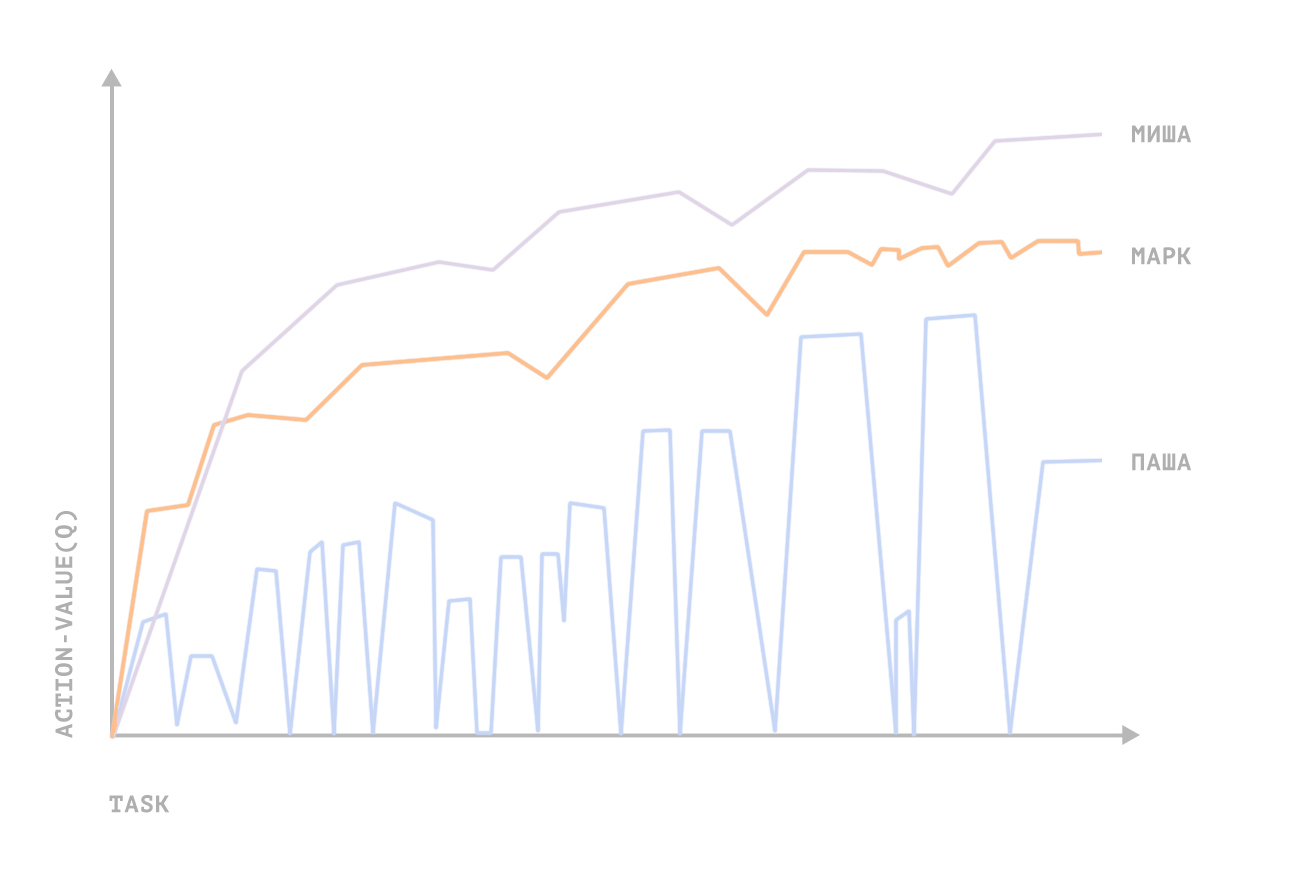
For the above mini-games with the formulation and management of the task in Youtrack, the control functions converged to higher than average values (employee productivity increased relative to working with a human manager) for 3 people out of 5. The overall productivity (in hours) almost doubled. There were no satisfied experimental staff from the test group; dissatisfied 4; one abstained from ratings.
Nevertheless, we made conclusions for ourselves that in order to use the “in combat” method, it is necessary to bring in the model expert knowledge in psychology. The total duration of development and testing is more than a year.
')
Source: https://habr.com/ru/post/319768/
All Articles