The system of recommendations online store based on methods of machine learning in the Compute Engine (Google Cloud Platform)
Using the Google Cloud Platform services, you can create an effective scalable recommendation system for an online store.
An interesting situation has developed on the e-commerce market. Although total cash flow increased, so did the number of sellers. This led to the fact that the share of each store has decreased, and the competition between them is becoming more intense. One way to increase the average purchase size (and therefore profit) is to offer customers additional products that may interest them.
In this article, you will learn how to set up an environment based on the Cloud Platform to support the basic recommendation system, which over time can be refined and expanded.
')
It describes the solution for the site of a real estate rental agency that allows you to select and offer recommendations to users.
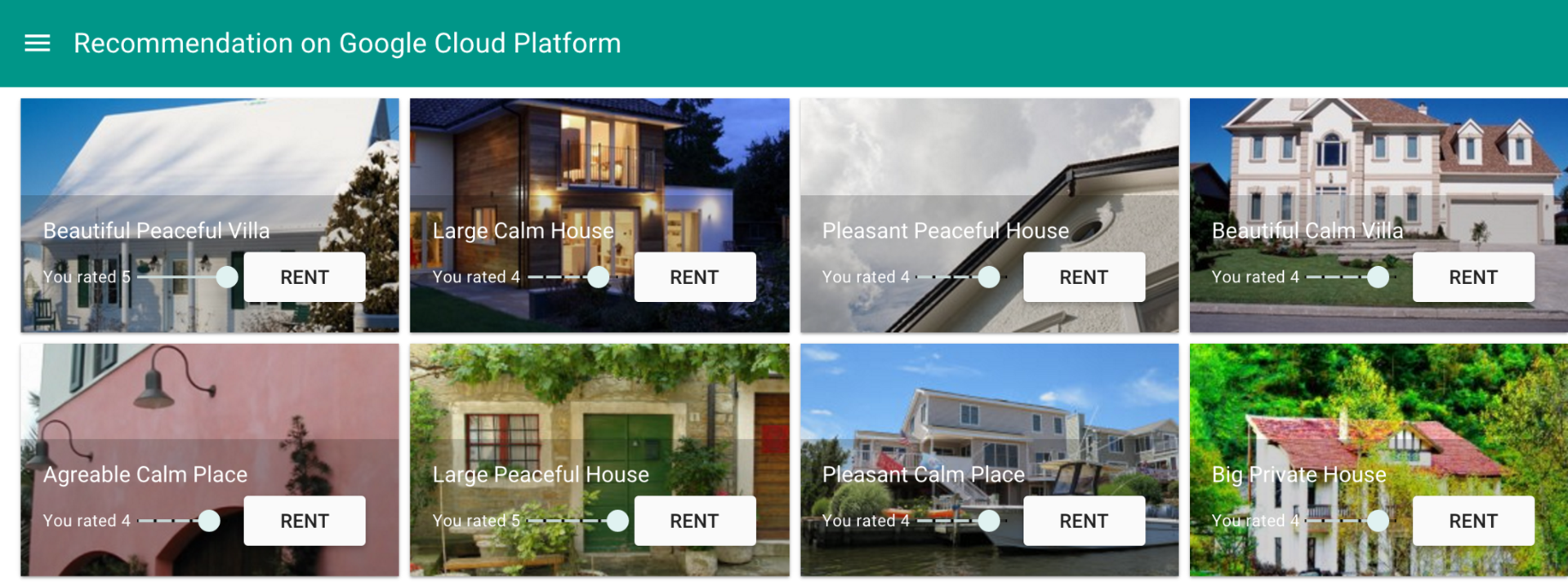
Anna is looking for vacation rentals on a specialized website. Previously, she had already rented accommodation through this site and left a few reviews, so there is enough data in the system to select recommendations based on her preferences. Judging by the estimates in Anna’s profile, she usually rents houses, not apartments. The system should offer her something from the same category.
For the selection of recommendations in real time (on the website) or after the fact (by e-mail), initial data are necessary. If we still do not know the user's preferences, you can select recommendations simply on the basis of the offers chosen by him. However, the system must constantly learn and accumulate data on what customers like. When enough information is gathered in it, it will be possible to analyze and select current recommendations using a machine learning system. In addition, the system can transmit information about other users, as well as from time to time to retrain. In our example, the system of recommendations has already accumulated enough data for the application of machine learning algorithms.
Data processing in such a system is usually performed in four stages: collection, storage, analysis, selection of recommendations (see figure below).

The architecture of such a system can be schematically represented as follows:

Each stage can be customized according to specific requirements. The system consists of the following elements:
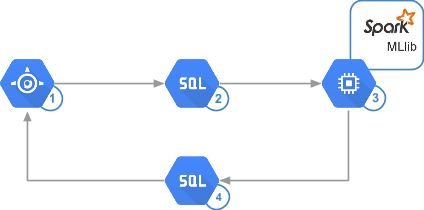
To get a quick, convenient, inexpensive and accurate solution, Google App Engine , Google Cloud SQL and Apache Spark were chosen based on the Google Compute Engine . The configuration is created using the bdutil script.
The App Engine service allows you to handle tens of thousands of requests per second. At the same time, it is easy to manage and allows you to quickly write and run code to perform any tasks - from creating a site to writing data to internal storage.
Cloud SQL also makes it easy to create our solution. It can deploy 32-core virtual machines with up to 208 GB of RAM and increase storage capacity by request to 10 TB with 30 I / O operations per second for each GB and thousands of simultaneous connections. This is more than enough for the system under consideration, as well as for many other real cases. In addition, Cloud SQL supports direct access from Spark.
Spark compares favorably with the classic Hadoop handler: its performance is 10-100 times higher, depending on the specific solution. The Spark MLlib library allows you to analyze hundreds of millions of assessments in minutes and run the algorithm more often to keep the recommendations current. Spark is characterized by simpler programming models, more convenient APIs, and a more universal language. For calculations, this framework uses memory to the maximum extent, which allows reducing the number of disk accesses. It also reduces the number of I / O operations. In this solution, the Compute Engine is used to host the analytical infrastructure. This allows you to significantly reduce costs, since payment is charged per minute upon use.
The following diagram shows the same system architecture, but now with an indication of the technologies used:
The recommendation system may collect user data based on implicit (behavior) or explicit information (ratings and reviews).
Collecting data on behavior is quite simple, since all actions can be recorded in journals without the participation of the users themselves. The disadvantage of this approach is that the collected data is more difficult to analyze, for example, to identify those data that are of the greatest interest. An example of analyzing data about explicit actions using log entries is available here .
Collecting ratings and reviews is more difficult, since many users leave them reluctantly. However, it is this data that best helps to understand customer preferences.
The more data available to the algorithms, the more accurate the recommendations will be. This means that very soon you will have to start working with big data.
The choice of the type of storage to use depends on what data you create recommendations from. It can be a NoSQL database, SQL or even an object storage. In addition to the volume and type of data, factors such as ease of implementation, the ability to integrate into the existing environment and support for the transfer must be taken into account.
A scalable managed database is great for storing user ratings and actions, as it is easier to use and allows you to spend more time. Cloud SQL not only meets these requirements, but also makes it easier to download data from Spark.
The sample code below shows the schemas of the Cloud SQL tables. The rented property is entered in the Accommodation table, and the user rating of this object is entered in the Rating table.
Spark can extract data from various sources, such as from Hadoop HDFS or Cloud Storage. In this solution, data is retrieved directly from Cloud SQL using a JDBC connector . Since Spark jobs run in parallel, this connector must be available for all instances of the cluster.
For successful analysis, it is necessary to clearly formulate the requirements for the application, namely:
The first thing you need to decide is how soon the user should receive recommendations. Immediately, at the time of viewing the site, or later, by e-mail? In the first case, of course, the analysis should be more operational.
You can choose any category of timeliness, but for Internet sales, a cross between batch analysis and almost real-time analysis is best suited, depending on the amount of traffic and the type of data being processed. The analytical platform can work directly with a database or with a dump periodically stored in permanent storage.
Filtering is a key component of the recommendation system. Here are the main approaches to filtering:
The Cloud Platform supports all three types; however, a collaborative filtering algorithm based on Apache Spark was chosen for this solution. For more information about content and cluster filtering, see the appendix .
Collaborative filtering allows you to abstract from the attributes of the product and make predictions, taking into account the tastes of the user. This approach is based on the premise that the preferences of two users who liked the same product will be the same in the future.
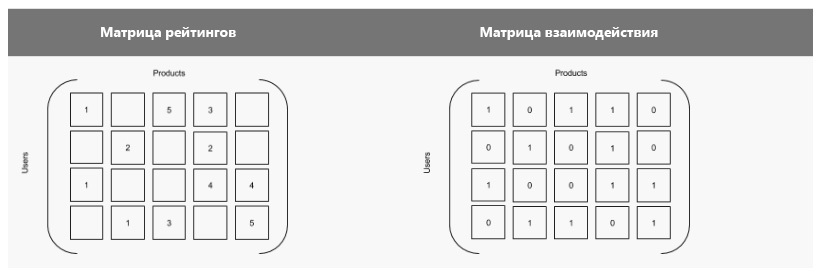
Data on assessments and actions can be represented as a set of matrices, and products and users - as values. The system will fill in the missing cells in the matrix, trying to predict the attitude of the user to the product. Below are two variants of the same matrix: the first shows the existing estimates; in the second, they are indicated by a unit, and the missing estimates are zero. That is, the second option is a truth table, where the unit indicates the interaction of users with the product.
In collaborative filtering, two main methods are used:
This solution uses a model method based on user ratings.
All the analysis tools required for this solution are available in PySpark , the Python API for Spark. Scala and Java open up additional features; see the documentation for Spark .
In Spark MLlib, ALS (Alternating Least Squares) algorithm is used to train models. In order to achieve the optimal ratio between displacement and dispersion, we need to adjust the values of the following parameters:
The diagram shows the different ratios of dispersion and displacement. The center of the target is the value that you want to predict using the algorithm.

The following is an example code for running the ALS learning model in Spark.
For ALS-based collaborative filtering, three data sets are used:
To choose the best model, you need to calculate the root mean square error (RMSE), based on the calculated model, the test sample and its size. The smaller the RMSE, the more accurate the model.
To speed up the output of analysis results, they should be loaded into the database with the ability to query on demand. Cloud SQL is great for this. Using Spark 1.4, you can write analysis results directly to the database from PySpark.
The scheme of the Recommendation table is as follows:
Now consider the code for learning models.
The Spark SQL context makes it easy to connect to a Cloud SQL instance through a JDBC connector. Data is loaded in a DataFrame format.
At the core of Spark’s work is the concept of RDD (Resilient Distributed Dataset) - an abstraction that allows you to work with elements in parallel. RDD is a read-only data collection based on persistent storage. Such collections can be analyzed in memory, which allows for iterative processing.
As you remember, to select the best model, you need to divide the data sets into three samples. The following code uses a helper function that arbitrarily separates non-overlapping values as a percentage of 60/20/20:
Note. In the Rating table, the columns should go in the following order: accoId, userId, rating. This is due to the fact that the ALS algorithm makes predictions based on the specified product / user pairs. If the order is broken, you can either change the database or reorder the columns using the map function in RDD.
As already mentioned, in the ALS method, our task is to adjust the rank, regularization and iteration in such a way as to finally obtain the optimal model. The system already has user estimates, so the results of the train function should be compared with the test sample. It is necessary to ensure that the user's tastes are taken into account in the training set.
Note. The howFarAreWe function uses the model to predict estimates in a test sample based only on product / user pairs.
, , , . -, .
, Cloud SQL, ,
, , GitHub .
SQL- .
Cloud Platform MySQL:

, :
, , , .
SSH. Spark , -.
8080. . . , IP- (, 1.2.3.4 :8080). Spark , .

Spark
- Cloud Dataproc.
GitHub .
, . , . : . .
. . .
, , . , , .
, , :


0 1. 1, .

:

P1 P2 :
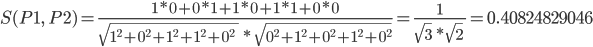
. :
. Mahout Maven.
, . , . , , . k- .
, , , .
, , , (, , ). (CRM) - (ERP).
, . , , . , Cloud Platform API, Breezometer .
An interesting situation has developed on the e-commerce market. Although total cash flow increased, so did the number of sellers. This led to the fact that the share of each store has decreased, and the competition between them is becoming more intense. One way to increase the average purchase size (and therefore profit) is to offer customers additional products that may interest them.
In this article, you will learn how to set up an environment based on the Cloud Platform to support the basic recommendation system, which over time can be refined and expanded.
')
It describes the solution for the site of a real estate rental agency that allows you to select and offer recommendations to users.
Who is not familiar with the cloud platform Google Cloud Platform - take a look at a series of webinars
| [January 19, Thursday, 11:00 Moscow time] Overview of the Google Cloud Platform
Link to webinar entry [February 3, Friday, 11:00 Moscow time] Cloud Infrastructure Services Google Cloud Platform
Link to webinar entry [February 17, Friday, 11:00 Moscow time] Tools for working with Big Data and Machine Learning from the Google Cloud Platform
Link to webinar entry [March 2, Thursday, 11:00 Moscow time] Practical seminar: step-by-step demonstration of Google Cloud Platform services
|
Webinars lead | |
|---|---|
Oleg Ivonin@GoogleAmsterdam  Cloud Web Solutions Engineer Oleg is developing tools for analyzing the cost of configurations and planning the cloud architecture of solutions based on the Google Cloud Platform. Oleg's developments are used in publicly available GCP tools, for example Google Cloud Platform Pricing Calculator | Dmitry Novakovsky@GoogleAmsterdam  Customer Engineer Dmitry is engaged in sales support and development of architectural solutions for business customers of the Google Cloud Platform. Dmitry's main focus is in the field of infrastructure services: Google Compute Engine (GCE), Google App Engine (GAE) and Google Container Engine (GKE / Kubernetes). |
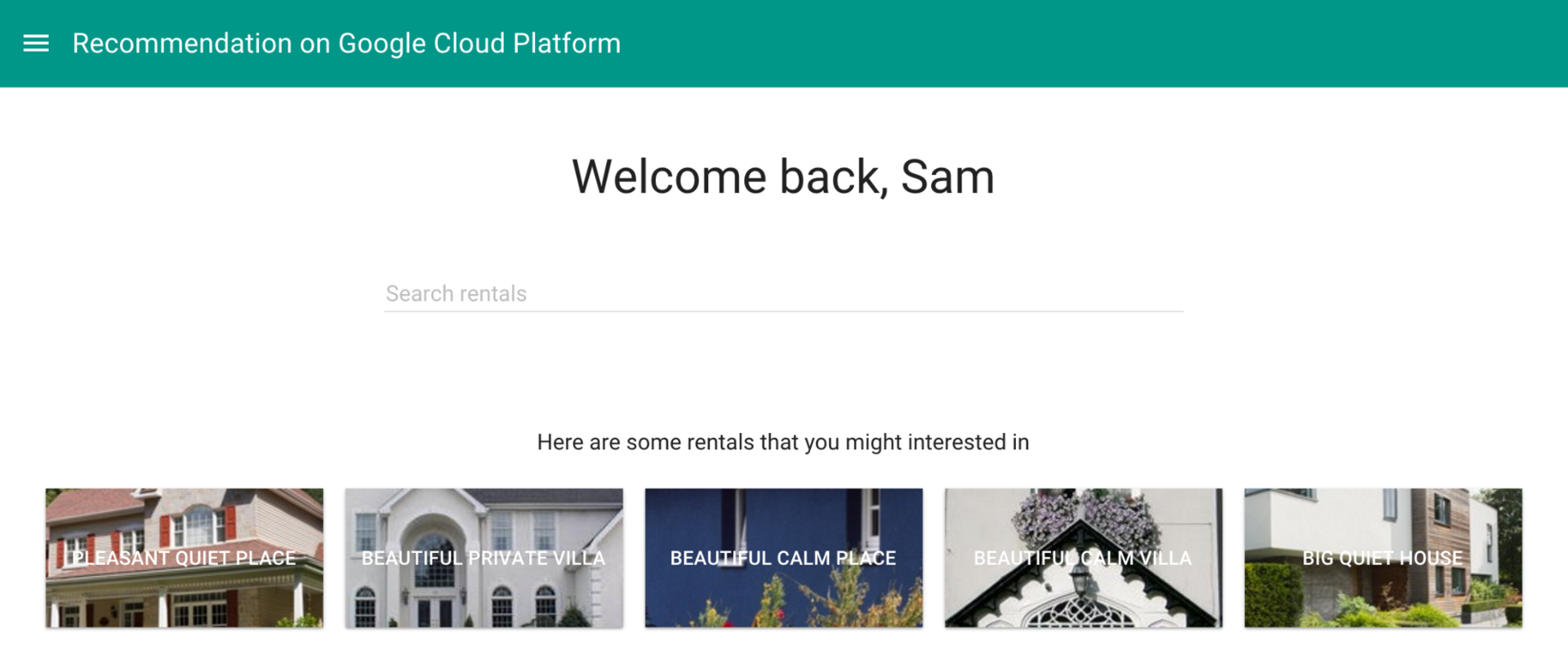
| Perhaps, as you read the article, you will have a desire to recreate this scenario in the Google Cloud Platform - by clicking on the link you will receive $ 300 to test GCP services within 60 days |
Scenario
Anna is looking for vacation rentals on a specialized website. Previously, she had already rented accommodation through this site and left a few reviews, so there is enough data in the system to select recommendations based on her preferences. Judging by the estimates in Anna’s profile, she usually rents houses, not apartments. The system should offer her something from the same category.
Solution Overview
For the selection of recommendations in real time (on the website) or after the fact (by e-mail), initial data are necessary. If we still do not know the user's preferences, you can select recommendations simply on the basis of the offers chosen by him. However, the system must constantly learn and accumulate data on what customers like. When enough information is gathered in it, it will be possible to analyze and select current recommendations using a machine learning system. In addition, the system can transmit information about other users, as well as from time to time to retrain. In our example, the system of recommendations has already accumulated enough data for the application of machine learning algorithms.
Data processing in such a system is usually performed in four stages: collection, storage, analysis, selection of recommendations (see figure below).
The architecture of such a system can be schematically represented as follows:
Each stage can be customized according to specific requirements. The system consists of the following elements:
- Front-end. Scalable interface part, where all user actions are recorded, that is, data is collected.
- Storage. Permanent storage available for machine learning platform. Loading data into it can include several steps, such as import, export, and data conversion.
- Machine learning. A machine learning platform where analysis of collected data and selection of recommendations is performed.
- The second element is Storage. Another storage, which is used by the interface part in real time or after the fact, depending on when you need to provide recommendations.
Component selection
To get a quick, convenient, inexpensive and accurate solution, Google App Engine , Google Cloud SQL and Apache Spark were chosen based on the Google Compute Engine . The configuration is created using the bdutil script.
The App Engine service allows you to handle tens of thousands of requests per second. At the same time, it is easy to manage and allows you to quickly write and run code to perform any tasks - from creating a site to writing data to internal storage.
Cloud SQL also makes it easy to create our solution. It can deploy 32-core virtual machines with up to 208 GB of RAM and increase storage capacity by request to 10 TB with 30 I / O operations per second for each GB and thousands of simultaneous connections. This is more than enough for the system under consideration, as well as for many other real cases. In addition, Cloud SQL supports direct access from Spark.
Spark compares favorably with the classic Hadoop handler: its performance is 10-100 times higher, depending on the specific solution. The Spark MLlib library allows you to analyze hundreds of millions of assessments in minutes and run the algorithm more often to keep the recommendations current. Spark is characterized by simpler programming models, more convenient APIs, and a more universal language. For calculations, this framework uses memory to the maximum extent, which allows reducing the number of disk accesses. It also reduces the number of I / O operations. In this solution, the Compute Engine is used to host the analytical infrastructure. This allows you to significantly reduce costs, since payment is charged per minute upon use.
The following diagram shows the same system architecture, but now with an indication of the technologies used:
Data collection
The recommendation system may collect user data based on implicit (behavior) or explicit information (ratings and reviews).
Collecting data on behavior is quite simple, since all actions can be recorded in journals without the participation of the users themselves. The disadvantage of this approach is that the collected data is more difficult to analyze, for example, to identify those data that are of the greatest interest. An example of analyzing data about explicit actions using log entries is available here .
Collecting ratings and reviews is more difficult, since many users leave them reluctantly. However, it is this data that best helps to understand customer preferences.
Data storage
The more data available to the algorithms, the more accurate the recommendations will be. This means that very soon you will have to start working with big data.
The choice of the type of storage to use depends on what data you create recommendations from. It can be a NoSQL database, SQL or even an object storage. In addition to the volume and type of data, factors such as ease of implementation, the ability to integrate into the existing environment and support for the transfer must be taken into account.
A scalable managed database is great for storing user ratings and actions, as it is easier to use and allows you to spend more time. Cloud SQL not only meets these requirements, but also makes it easier to download data from Spark.
The sample code below shows the schemas of the Cloud SQL tables. The rented property is entered in the Accommodation table, and the user rating of this object is entered in the Rating table.
CREATE TABLE Accommodation ( id varchar(255), title varchar(255), location varchar(255), price int, rooms int, rating float, type varchar(255), PRIMARY KEY (ID) ); CREATE TABLE Rating ( userId varchar(255), accoId varchar(255), rating int, PRIMARY KEY(accoId, userId), FOREIGN KEY (accoId) REFERENCES Accommodation(id) ); Spark can extract data from various sources, such as from Hadoop HDFS or Cloud Storage. In this solution, data is retrieved directly from Cloud SQL using a JDBC connector . Since Spark jobs run in parallel, this connector must be available for all instances of the cluster.
Data analysis
For successful analysis, it is necessary to clearly formulate the requirements for the application, namely:
- Timeliness How fast should an application make recommendations?
- Filtering data . Will the application generate recommendations based only on the tastes of the user, on the opinions of other users or on the similarity of products?
Timeliness
The first thing you need to decide is how soon the user should receive recommendations. Immediately, at the time of viewing the site, or later, by e-mail? In the first case, of course, the analysis should be more operational.
- Real-time analysis involves processing the data at the time of its creation. Systems of this type, as a rule, use tools capable of processing and analyzing event streams. Recommendations in this case are made instantly.
- Batch analysis involves periodic data processing. This approach is appropriate when you need to collect enough data to get the actual result, for example, to find out the daily sales volume. Recommendations in this case are developed after the fact and are provided in the format of electronic distribution.
- An almost real-time analysis involves updating the analytic data every few minutes or seconds. This approach allows you to provide recommendations during one user session.
You can choose any category of timeliness, but for Internet sales, a cross between batch analysis and almost real-time analysis is best suited, depending on the amount of traffic and the type of data being processed. The analytical platform can work directly with a database or with a dump periodically stored in permanent storage.
Data filtering
Filtering is a key component of the recommendation system. Here are the main approaches to filtering:
- Content, when recommendations are selected by attributes, that is, by similarity with the goods that the user is viewing or evaluating.
- Cluster, when goods are selected that are well combined with each other. In this case, the opinions and actions of other users are not taken into account.
- Collaborative, when products are selected that are viewed or selected by users with similar tastes.
The Cloud Platform supports all three types; however, a collaborative filtering algorithm based on Apache Spark was chosen for this solution. For more information about content and cluster filtering, see the appendix .
Collaborative filtering allows you to abstract from the attributes of the product and make predictions, taking into account the tastes of the user. This approach is based on the premise that the preferences of two users who liked the same product will be the same in the future.
Data on assessments and actions can be represented as a set of matrices, and products and users - as values. The system will fill in the missing cells in the matrix, trying to predict the attitude of the user to the product. Below are two variants of the same matrix: the first shows the existing estimates; in the second, they are indicated by a unit, and the missing estimates are zero. That is, the second option is a truth table, where the unit indicates the interaction of users with the product.
In collaborative filtering, two main methods are used:
- Anamnestic - the system calculates matches between products or users;
- model - the system works on the basis of a model that describes how users evaluate products and what actions they take.
This solution uses a model method based on user ratings.
All the analysis tools required for this solution are available in PySpark , the Python API for Spark. Scala and Java open up additional features; see the documentation for Spark .
Training models
In Spark MLlib, ALS (Alternating Least Squares) algorithm is used to train models. In order to achieve the optimal ratio between displacement and dispersion, we need to adjust the values of the following parameters:
- Rank - the number of unknown factors that the user was guided by when grading. In particular, this may include age, gender and location. To some extent, the higher the rank, the more accurate the recommendation. The minimum value of this parameter will be 5; we will increase it in increments of 5 until the difference in the quality of recommendations starts to decrease (or until there is enough memory and processor power).
- Lambda is a regularization parameter that allows you to avoid overtraining , that is, a situation with a large variance and a small offset . Dispersion is the scatter of predictions made (after several passes) with respect to a theoretically correct value for a particular point. Offset - distance of forecasts from the true value. Re-training is observed when the model works well on training data with a known level of noise, but in reality it shows poor results. The more lambda, the less retraining, but the higher the offset. For testing, values of 0.01, 1, and 10 are recommended.
The diagram shows the different ratios of dispersion and displacement. The center of the target is the value that you want to predict using the algorithm.
- Iteration is the number of learning passes. In this example, 5, 10, and 20 iterations should be performed for different combinations of the “Rank” and “Lambda” parameters.
The following is an example code for running the ALS learning model in Spark.
from pyspark.mllib.recommendation import ALS model = ALS.train(training, rank = 10, iterations = 5, lambda_=0.01) Model selection
For ALS-based collaborative filtering, three data sets are used:
- The training set contains data with known values. This is what the perfect result should look like. In the solution in question, this sample contains user estimates.
- The test sample contains data that allows the training sample to be refined in order to obtain the optimal combination of parameters and select the best model.
- The test sample contains data that allows you to test the performance of the best model. This is equivalent to real-world analysis.
To choose the best model, you need to calculate the root mean square error (RMSE), based on the calculated model, the test sample and its size. The smaller the RMSE, the more accurate the model.
Conclusion of recommendations
To speed up the output of analysis results, they should be loaded into the database with the ability to query on demand. Cloud SQL is great for this. Using Spark 1.4, you can write analysis results directly to the database from PySpark.
The scheme of the Recommendation table is as follows:
CREATE TABLE Recommendation ( userId varchar(255), accoId varchar(255), prediction float, PRIMARY KEY(userId, accoId), FOREIGN KEY (accoId) REFERENCES Accommodation(id) ); Code analysis
Now consider the code for learning models.
Extracting data from Cloud SQL
The Spark SQL context makes it easy to connect to a Cloud SQL instance through a JDBC connector. Data is loaded in a DataFrame format.
pyspark / app_collaborative.py
jdbcDriver = 'com.mysql.jdbc.Driver' jdbcUrl = 'jdbc:mysql://%s:3306/%s?user=%s&password=%s' % (CLOUDSQL_INSTANCE_IP, CLOUDSQL_DB_NAME, CLOUDSQL_USER, CLOUDSQL_PWD) dfAccos = sqlContext.load(source='jdbc', driver=jdbcDriver, url=jdbcUrl, dbtable=TABLE_ITEMS) dfRates = sqlContext.load(source='jdbc', driver=jdbcDriver, url=jdbcUrl, dbtable=TABLE_RATINGS) Convert DataFrame to RDD and create datasets
At the core of Spark’s work is the concept of RDD (Resilient Distributed Dataset) - an abstraction that allows you to work with elements in parallel. RDD is a read-only data collection based on persistent storage. Such collections can be analyzed in memory, which allows for iterative processing.
As you remember, to select the best model, you need to divide the data sets into three samples. The following code uses a helper function that arbitrarily separates non-overlapping values as a percentage of 60/20/20:
pyspark / app_collaborative.py
rddTraining, rddValidating, rddTesting = dfRates.rdd.randomSplit([6,2,2]) Note. In the Rating table, the columns should go in the following order: accoId, userId, rating. This is due to the fact that the ALS algorithm makes predictions based on the specified product / user pairs. If the order is broken, you can either change the database or reorder the columns using the map function in RDD.
Selection of parameters for training models
As already mentioned, in the ALS method, our task is to adjust the rank, regularization and iteration in such a way as to finally obtain the optimal model. The system already has user estimates, so the results of the train function should be compared with the test sample. It is necessary to ensure that the user's tastes are taken into account in the training set.
pyspark / find_model_collaborative.py
for cRank, cRegul, cIter in itertools.product(ranks, reguls, iters): model = ALS.train(rddTraining, cRank, cIter, float(cRegul)) dist = howFarAreWe(model, rddValidating, nbValidating) if dist < finalDist: print("Best so far:%f" % dist) finalModel = model finalRank = cRank finalRegul = cRegul finalIter = cIter finalDist = dist Note. The howFarAreWe function uses the model to predict estimates in a test sample based only on product / user pairs.
pyspark / find_model_collaborative.py
def howFarAreWe(model, against, sizeAgainst): # Ignore the rating column againstNoRatings = against.map(lambda x: (int(x[0]), int(x[1])) ) # Keep the rating to compare against againstWiRatings = against.map(lambda x: ((int(x[0]),int(x[1])), int(x[2])) ) # Make a prediction and map it for later comparison # The map has to be ((user,product), rating) not ((product,user), rating) predictions = model.predictAll(againstNoRatings).map(lambda p: ( (p[0],p[1]), p[2]) ) # Returns the pairs (prediction, rating) predictionsAndRatings = predictions.join(againstWiRatings).values() # Returns the variance return sqrt(predictionsAndRatings.map(lambda s: (s[0] - s[1]) ** 2).reduce(add) / float(sizeAgainst)) , , , . -, .
pyspark/app_collaborative.py
# Build our model with the best found values # Rating, Rank, Iteration, Regulation model = ALS.train(rddTraining, BEST_RANK, BEST_ITERATION, BEST_REGULATION) # Calculate all predictions predictions = model.predictAll(pairsPotential).map(lambda p: (str(p[0]), str(p[1]), float(p[2]))) # Take the top 5 ones topPredictions = predictions.takeOrdered(5, key=lambda x: -x[2]) print(topPredictions) schema = StructType([StructField("userId", StringType(), True), StructField("accoId", StringType(), True), StructField("prediction", FloatType(), True)]) dfToSave = sqlContext.createDataFrame(topPredictions, schema) dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite') , Cloud SQL, ,
pyspark/app_collaborative.py
dfToSave = sqlContext.createDataFrame(topPredictions, schema) dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite') , , GitHub .
SQL- .
Cloud Platform MySQL:
, :
, , , .
bdutil
SSH. Spark , -.
8080. . . , IP- (, 1.2.3.4 :8080). Spark , .
Spark
Cloud Dataproc
- Cloud Dataproc.
Manual
GitHub .
application
, . , . : . .
. . .
, , . , , .
, , :
0 1. 1, .
:
P1 P2 :
. :
git clone https://github.com/apache/mahout.git mahout export MAHOUT_HOME=/path/to/mahout export MAHOUT_LOCAL=false #For cluster operation export SPARK_HOME=/path/to/spark export MASTER=spark://hadoop-m:7077 #Found in Spark console . Mahout Maven.
Clustering
, . , . , , . k- .
, , , .
from pyspark.mllib.clustering import KMeans, KMeansModel clusters = KMeans.train(parsedData, 2, maxIterations=10, runs=10, initializationMode="random") ?
, , , (, , ). (CRM) - (ERP).
, . , , . , Cloud Platform API, Breezometer .
Softline - Google Cloud Premier Partner
Softline is the largest Google corporate services provider in Russia and the CIS and the only partner with the status of Google Cloud Premier Partner. Over the years, the company was recognized as the best partner of the year in the Enterprise segment, partner of the year in the EMEA region in the SMB segment. |
Source: https://habr.com/ru/post/319704/
All Articles