Online game infrastructure
Hello, my name is Alexander Zelenin , and I on dude igrets Web developer. A year and a half ago, I talked about the development of an online game . So, it has grown a bit ... The total volume of the source code has doubled the "War and Peace". However, in this article I want to talk not about the code, but about the organization of the project infrastructure.
Table of contents
- I want to sleep well!
1.1. Stable architecture planning
1.2. Choosing a server / data center
1.3. Load balancing
1.4. Monitoring of everything and everyone
1.5. Linked project - separate server
1.6. Selection of support services - How to stop worrying and start developing
2.1. Where to store photos?
2.2. Setting up a home network
2.3. Backup and backup strategy
2.4. Your dropbox
2.5. Virtual machines
2.6. Jira - Confluence - Bitbucket - Bamboo - What is the result?
- And what about the game?
The table of contents does not reflect the chronology, although somewhere it will coincide. This is not a how-to, not a manual and the like. This is an overview article designed to give an idea of what lies behind a small project.
Almost every item has a rather extensive history (I deliberately cut everything down) and draws on a separate full-fledged article.
In case this article turns out to be in demand, I will gradually write a cycle telling how to choose and set up certain tools.
You can read in any order.
Important factors in the final infrastructure were: reliability and cost of maintenance.
Providing all this costs us less than 15 thousand rubles a month, most of which are eaten by VPC . And if you sacrifice the stability of the product itself and use a cheaper data center, then it would be possible to keep within 3 thousand. These figures take into account depreciation and replacement of defective items.
I want to sleep well
After another fall of the project at 2 am and restoring work until the morning, it became clear that this could no longer continue. And this is a story about the right side of the diagram.
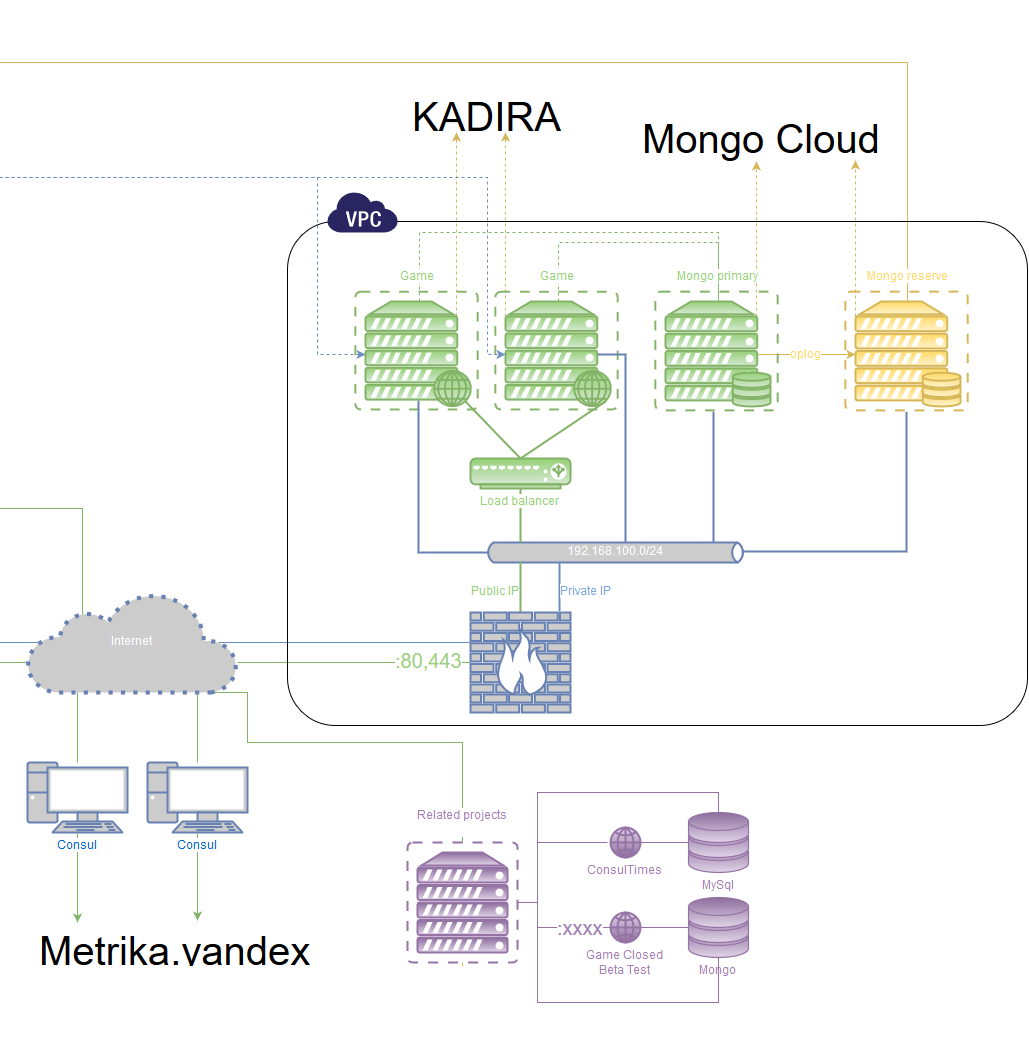
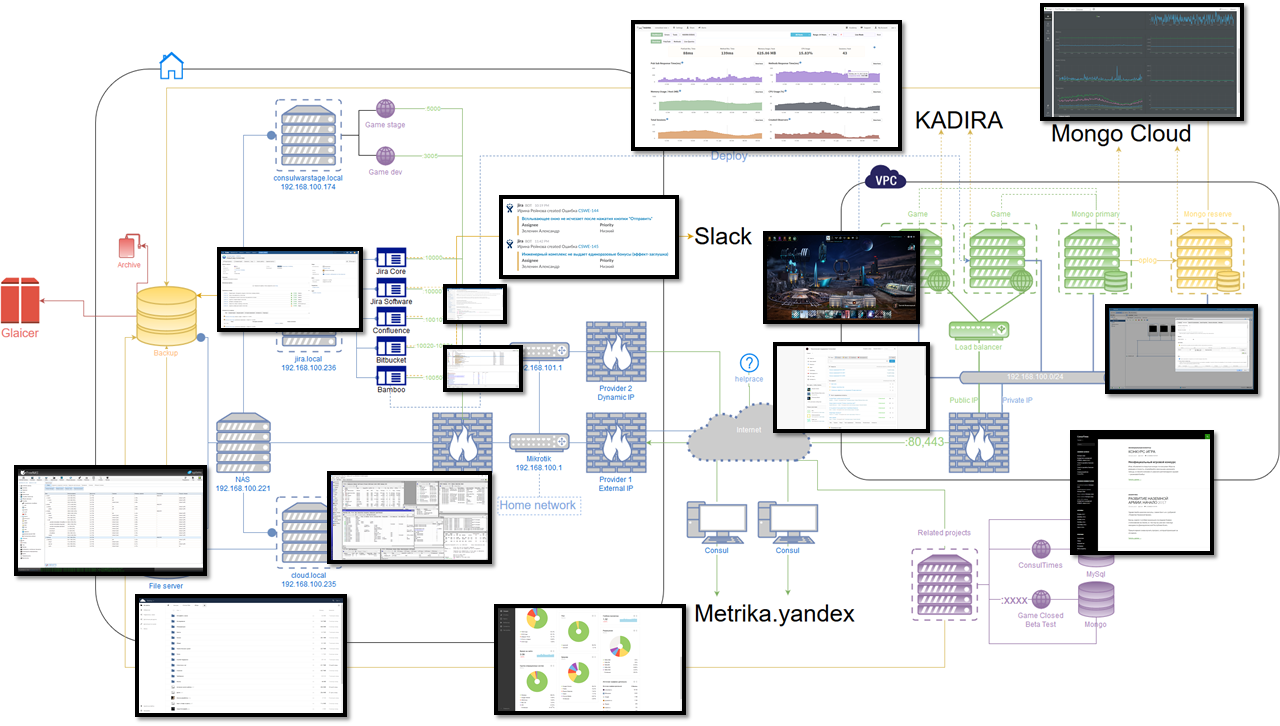
Stable architecture planning
I wanted to make it so that no matter what happens, you can sleep and not worry that the project will suddenly become unavailable for any of the reasons, and then, in a relaxed atmosphere, slowly and carefully repair everything. Along the way, I wanted to add the possibility of free horizontal scaling.
The classic recipe is to run multiple instances of the application on different servers and, at the level above, direct the user to the running one. The synchronization point is the database, so it must be as stable as the application itself.
1) Database: MongoDB
Runs on at least two different physical servers. One is the main, the rest are secondary.
Since databases and applications run on different servers and there is a chance of arbitrary inaccessibility, it is necessary to achieve full correct data synchronization when the connection is restored. For this, MongoDB has a special mechanism - at least 50% + 1 servers are required to select a server as the primary one. We also want servers with applications to participate in this voting, due to the fact that initially only 2 servers are planned for the bases (50% + 1 of 2 are the same two, that is, not enough to vote). To do this, MongoDB has a special way to run a database instance without the data itself, but only in the voting mode ( Arbiter ). Such an Arbiter is additionally placed on each server with the application.
An additional Arbiter runs on a backup server located outside the data center.
In total we have 2 DB servers online, and 5 arbitrators (the DB server is also one).
Now, whatever the instance of the database falls off - the other becomes the primary, and the fallen off becomes read-only until the connection is restored. After the restoration of communication and full synchronization, he again becomes the main one. If for some reason the second server and the backup server fall off - all databases go into read-only mode.
Monitoring is also needed (monitoring the performance of the cluster): that it is available, that the data is in place, that the backup is in order, and so on.
2) Application Nodejs
Similar to the previous one - at least two different physical servers. All applications are equal, because the synchronization point is data.
This can be achieved, because the applications themselves do not store any states, so even if one user joins different instances, it will not affect anything.
On each server there are at least 2 instances of the application, which are monitored and balanced using pm2 & nginx .
On top of this is performance monitoring.
')
Choosing a server / data center
Before choosing, it is necessary to determine how many resources our application consumes.
Since I use Meteor, then the choice of load testing fell on MeteorDown . I will check on the home server, allocating 100% of resources for the application.
Server: Intel® Xeon® CPU E5-1620 v2 @ 3.70GHz (6 cores), 32GB ECC DRR3 memory.
It will test itself, i.e. network is not counted. Yes, all this gives distortions, but acceptable.
User behavior scripts are written, data sets are generated. Run! The load is gradually increasing, but at the same time the response time to the methods is kept stable. Thousand online, two, three, five, six. Gradually, the response time begins to grow. Seven - the response time exceeds half a second. Eight - the response time becomes unacceptably long (10+ seconds). Rested in the CPU.
Six thousand - it was ten times higher than the peak online. So, we focus on 2-4 times smaller parameters, but we lay down the scaling.
1) End of closed beta test
During the beta test, registration was limited, respectively, and online too. The architecture described above was not even in the project, because until that moment everything was quite stable. At this time, the entire application worked on a single KVM VPS 'ke (4 2.2GHz cores, 4GB of memory).
By the start of the beta, it was decided to move (they have the same) to the “Failover Server” with a cost of two and a half times higher for similar characteristics, but it seems like a bunch of guarantees that everything is super stable and cool.
With the launch of an open beta test, we started accepting payments, so that our commitment increased and there was no downtime.
2) MBT
The launch was quite successful, and it seemed like even everything worked well. Suddenly, a couple of weeks later, a friend calls me in the afternoon and reports that the site is unavailable. Okay, I'm running home. I see that VPS'ka lies entirely with the word. Trying to restart - unsuccessfully. I am writing to tech support - they answer me: the disk crashed, recovery after a couple of hours.
SHTA? In the fake description of the "fault-tolerant server" I was assured that they have a server and storage systems separate, everything is super duplicated and that there will be 100% availability.
I clarify these points and they tell me that they will compensate (ta-da-yes) 30 rubles! For 6 hours of downtime. Fine.
OK, suppose I was really unlucky and some extraordinary event happened. I specify the frequency of such events and the chances of occurrence in the future - they assure that everything will be fine. Two days later - fall at 4 am. The disk crashed, but this time also with data loss :-)
3) The first move
Thanks to backups, the loss was 24 hours (at that time there was a backup once a day), and due to the transaction history at the partner, it was not difficult to recover the payments. Urgently looking for an alternative. I find, pay and move.
Three weeks later - the situation is almost the same. M-yes. A very nontrivial situation was for me.
4) Tier 3, DataLine
I study the subject more deeply: how do adult uncles solve such questions? I feel, and it's time for us to grow up.
I am working on the scheme above, I am looking for the most reliable hosters and I come to the conclusion that the choice in the Russian Federation is not so big. Almost no major players are interested in working with small projects, except for DataLine with their simplified version of CloudLite.
I agree with the support of the test period and unfold everything as planned. We transfer the domain.

Fuh, it seems to work. But somehow slowly. Inquiries return about 300ms . But at the same time there were no load jumps, i.e. It was a stable 300ms.
It was decided to leave and watch a few days. In general, the stability pleased, but the lethality was annoying.
He began to understand what was happening and immediately it became clear that the disk was a bottleneck - we have very carefully recorded the user's activity, and there was always a write queue. It turned out that within CloudLite only VSAN drives are provided and moving to SSD to fix the problem is not possible.
The alternative was to run inmemory version of mongo with replication already on the disk, but there were a few but: mongo provide a full-fledged in-memory version only for the enterprise (pa-ba-ba) 15 thousand dollars a year for one server. In my case it was completely unjustified, especially in comparison with alternative solutions for the current level (moving to SSD). There was also a tricky version of creating a memory section in linux and deploying the database there , but I'm not a fan of these kinds of hacks, and it was problematic to figure out possible problems with this approach.
In general, it was necessary to move to the SSD. In DataLine, this is only available with the conclusion of the contract and on a different platform.
On it, I also provided a test period. I deployed it all over again, this time documenting all the steps for subsequent automation. Re-transfer domain ... Hooray! Everything works quickly and as it should.
After the fact, I want to say that I am very pleased with this move, because there was not a single idle time due to DataLine (more than 8 months already).
There was one interesting idle time due to the DNS glitch (I still hosted the master zone at the first host, since all sorts of other small projects lived there), which suddenly rolled back for several months. Well, that is just started DNS to return the addresses of the old server and that's it.
To catch this error was very difficult, because someone worked, but someone does not (I originally worked). But after resetting the DNS caches on the router, everything became immediately visible.
As a result, the domain was also transferred to the DataLine and so far (pah-pah!) Works without problems.
Load balancing
So, now we have several servers and even more application instances and we need to somehow evenly distribute users to them in order to achieve maximum performance.
The task is divided into two steps - balancing to the server and balancing within the server.
1) Balancing to server
Solved at the data center level. All servers with applications are pooled, the choice of the server itself goes by two parameters: the first is a cookie, and if not, then IP hash. The idea is that requests from one user always go to the same server, so caching will work more efficiently.

Since All application servers are equal, and the weight is the same. We add check of availability of 5 seconds.
Is done.
Now user requests are distributed fairly well to the servers, and in case one of the servers ceases to be available, then within 5 seconds the user is transferred to the other.
2) Balancing within the server
There are several options. Since I use pm2 to run nodejs processes, then I can run the required number of application instances (by the number of cores) in cluster mode, which will already be managed by the node. The disadvantage of this approach is that the sticky sessions mechanism does not work , but since we keep the socket connected, then switching to another instance of the application is possible only in case of a break. In our case, this is not a problem.
The second option is to launch applications in fork mode on different ports and proxying them through nginx. The advantage here is that nginx can also distribute static, yes SSL certificate (SSL has not yet been connected, by the way, but hands will soon reach).
Register the application ports in the config, that's it.
3) Check
I check the load on the servers and see that it is evenly distributed. Fine!
Monitoring of everything and everyone
As in all tasks, we first try to understand what data we want to collect:
- Information about the health of the application, the load on it, errors and so on.
- Database health data, data size, replication, log, and so on.
- User data, input devices, screen resolutions, referral sources, and more.
- Data about the actions in the game.
1) Kadira.io
First of all, I want to note that this service, unfortunately, will soon cease to exist - it turned out to be unprofitable. But the developer promised to give out source codes and information on how to deploy it all at home. So, apparently, the project infrastructure is awaiting replenishment.
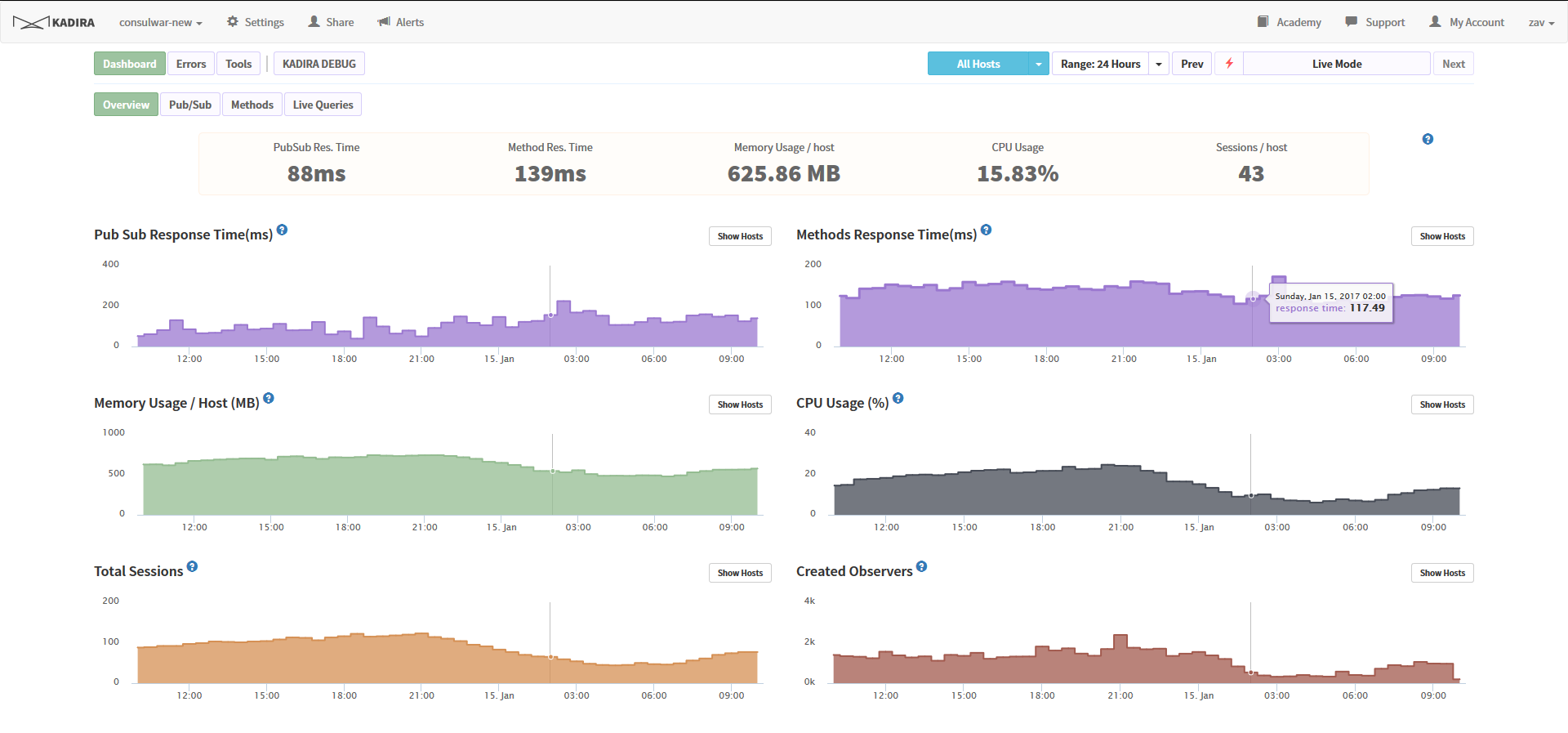
There is no need to reinvent the wheel when there are wonderful ready-made tools. Integration with the application is just the installation of a module from the package and the prescription of two lines in the config. At the output, we get resource monitoring, heavy query profiling, a current activity monitor, an error analyzer, and a whole bunch more.
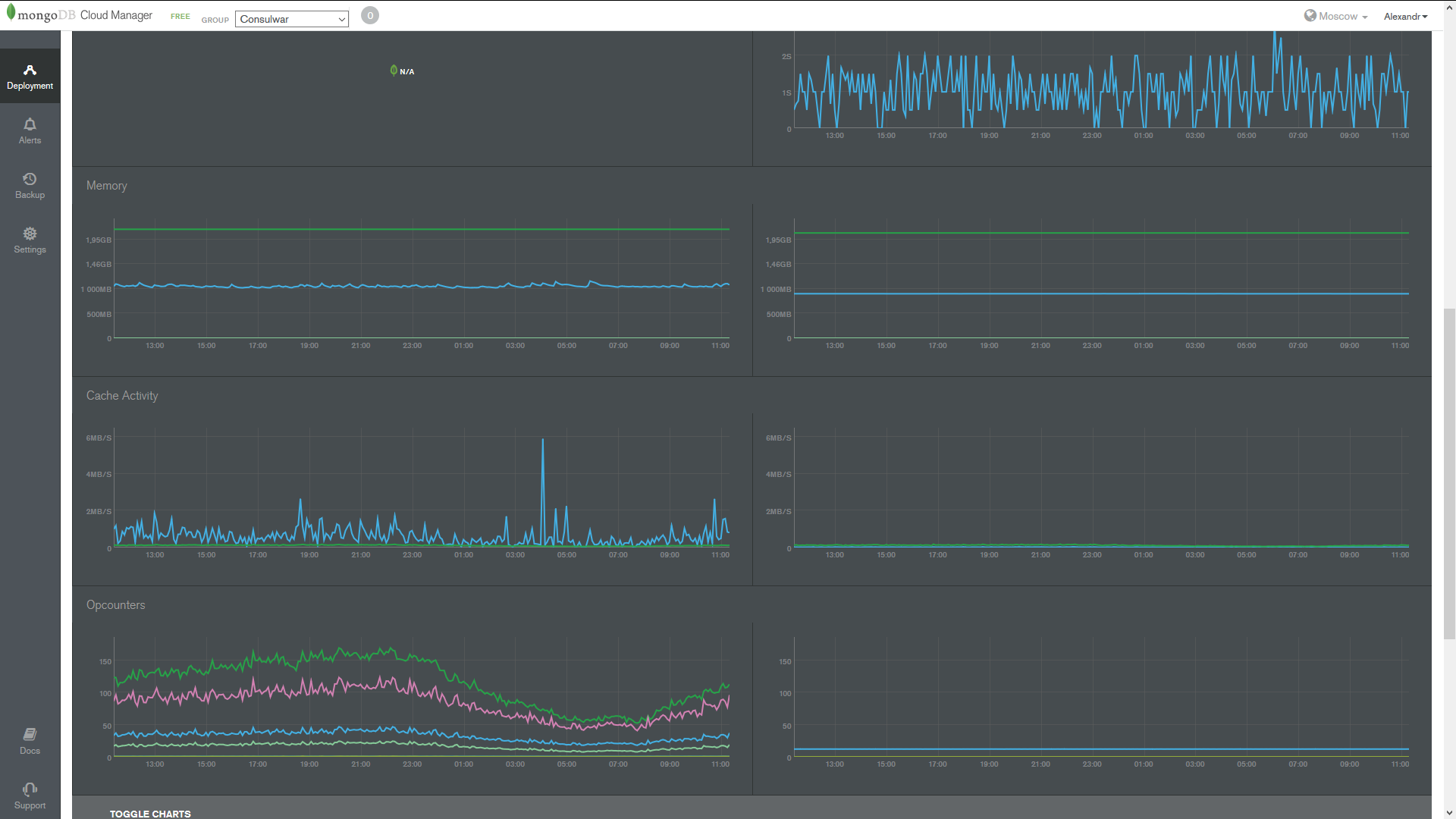
Integration is not much harder, but is placed on the database server, and not the application, respectively. We put the module, start the watch'er.
Immediately on the spot we monitor the database server resources, we see the time of requests, replication lags, tips to update the database.
Quite a cool thing here - it is instant information in case of unavailability of the database in the mail.
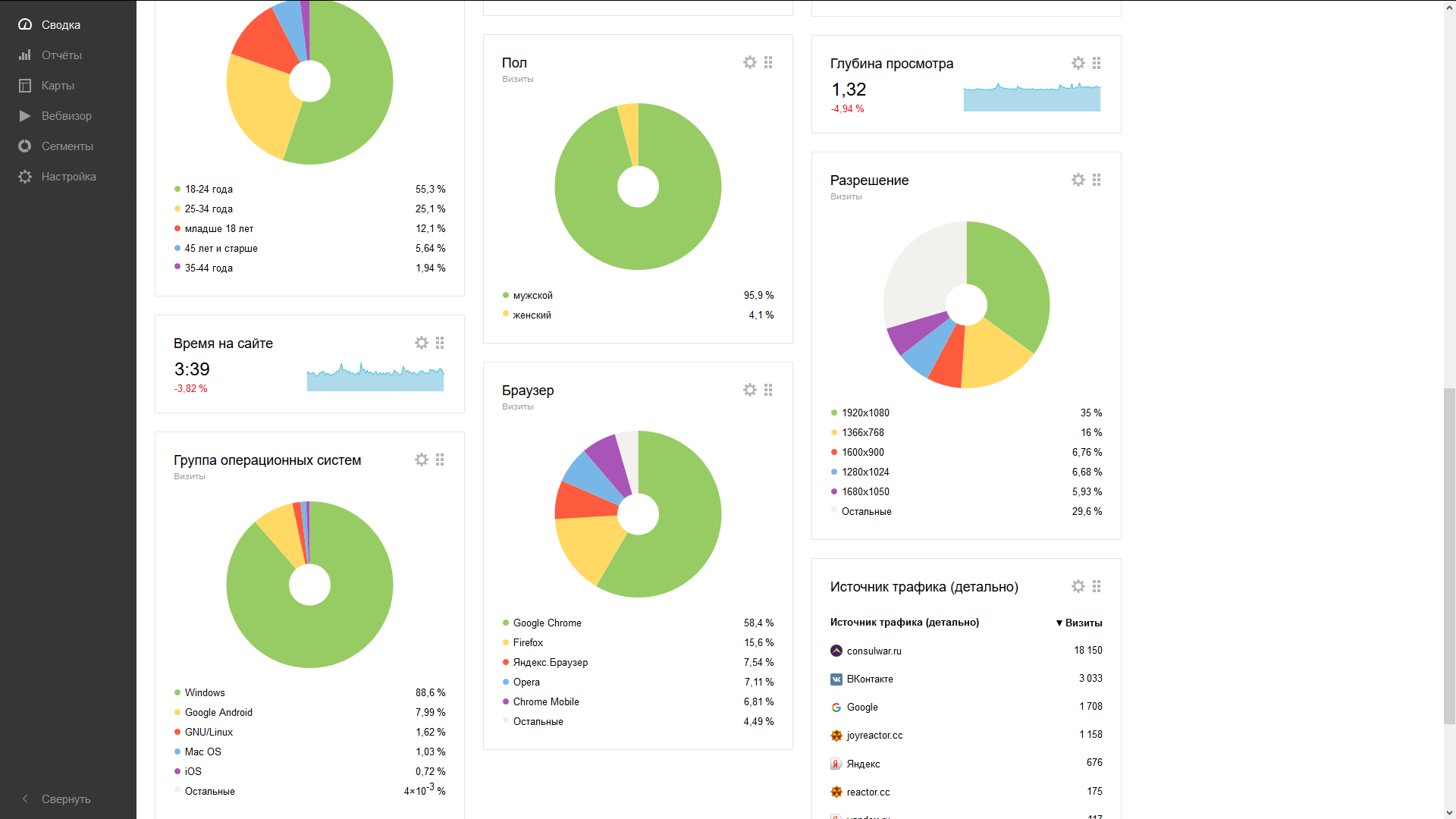
Integration is a bit more complicated than Kadira, because in addition to installing the module, it is necessary to modify the application so that it informs the script of the metrics about navigating through the pages (in the SPA it is not always obvious which monitors should be monitored, therefore it is done this way). Add the desired code to the router, and ready: gender, age, transitions, visits, devices, and so on. All in one place. Conveniently!
4) Action in the game
Recorded in the application database, of course. You can subsequently configure it to transfer old data that is necessary only for analysis to a separate server. For like, Monga also has tools .
Linked project - separate server
Over time, the project is cluttered with various additions. For example, we had a newspaper, which was made by the users themselves. Initially, it was created and placed somewhere in one of the players, but then it closed abruptly and the player disappeared. It was decided to deploy an analogue on wordpress and to give the moderators the opportunity to publish articles on the near-game topics there.

Of course, on an existing server, you should not run this for at least security reasons.
The secondary servers were decided to stir with a cheaper provider, because their availability is uncritical.
Although the hoster was still selected, leasing capacity in shooting gallery 3 to the data center.
Selection of support services
You also need a public place to collect information about errors. The best option was the possibility of collecting proposals from players and voting on them. Completely optional - posting change logs right there. The possibility of free placement for small companies or up to any limit was very desirable.
I tried about three dozen systems and eventually settled on helprace .
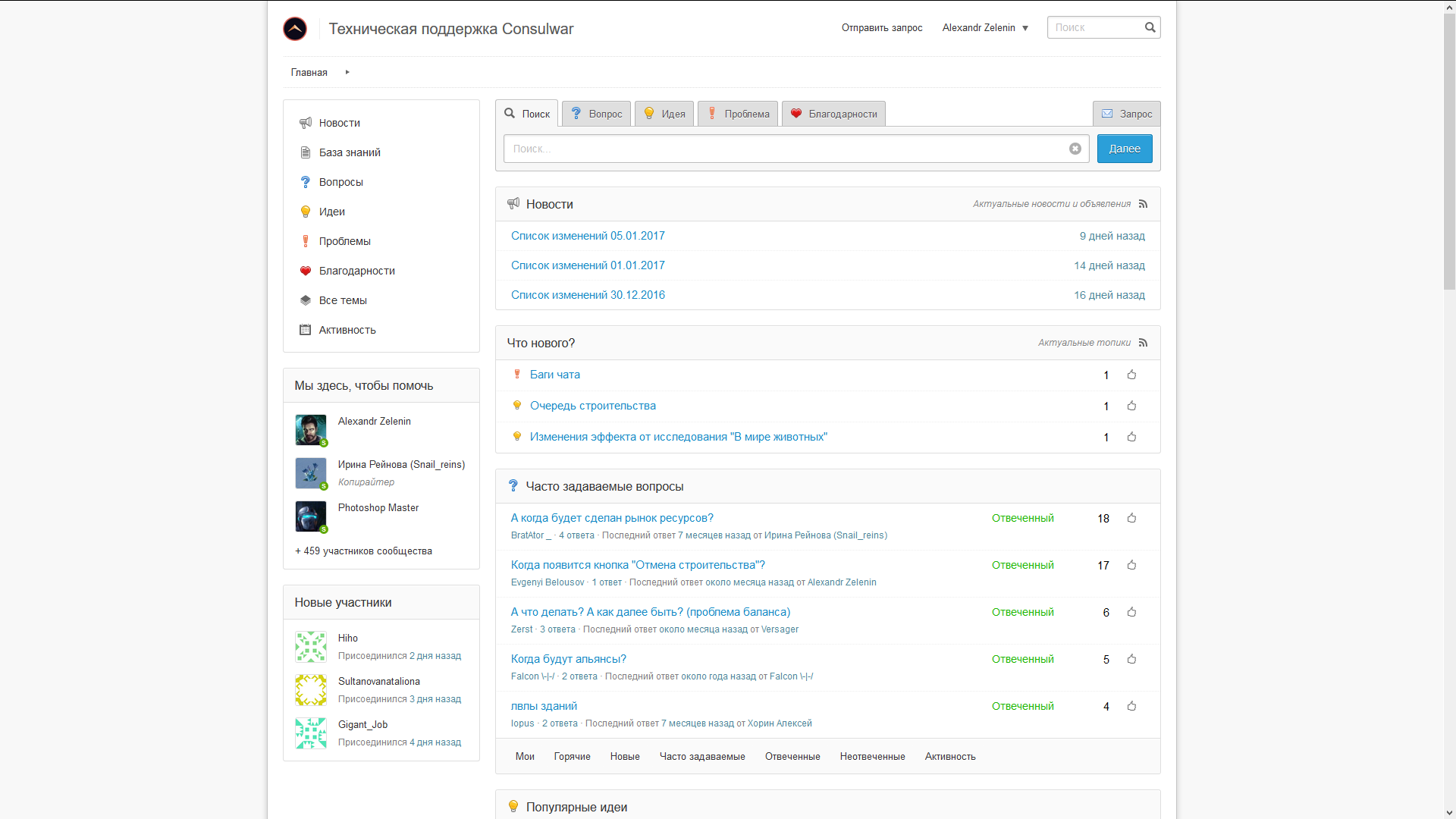
Directly as if made a request. In general, they have integration with external login, but only in the paid version. Since One of the goals was to save on the cost of maintenance, the system requires registration separately.
The audience is always very happy - hundreds of error messages, mountains of suggestions and wishes. Sometimes even slips a low-profile praise the game and developers :-)
How to stop worrying and start developing
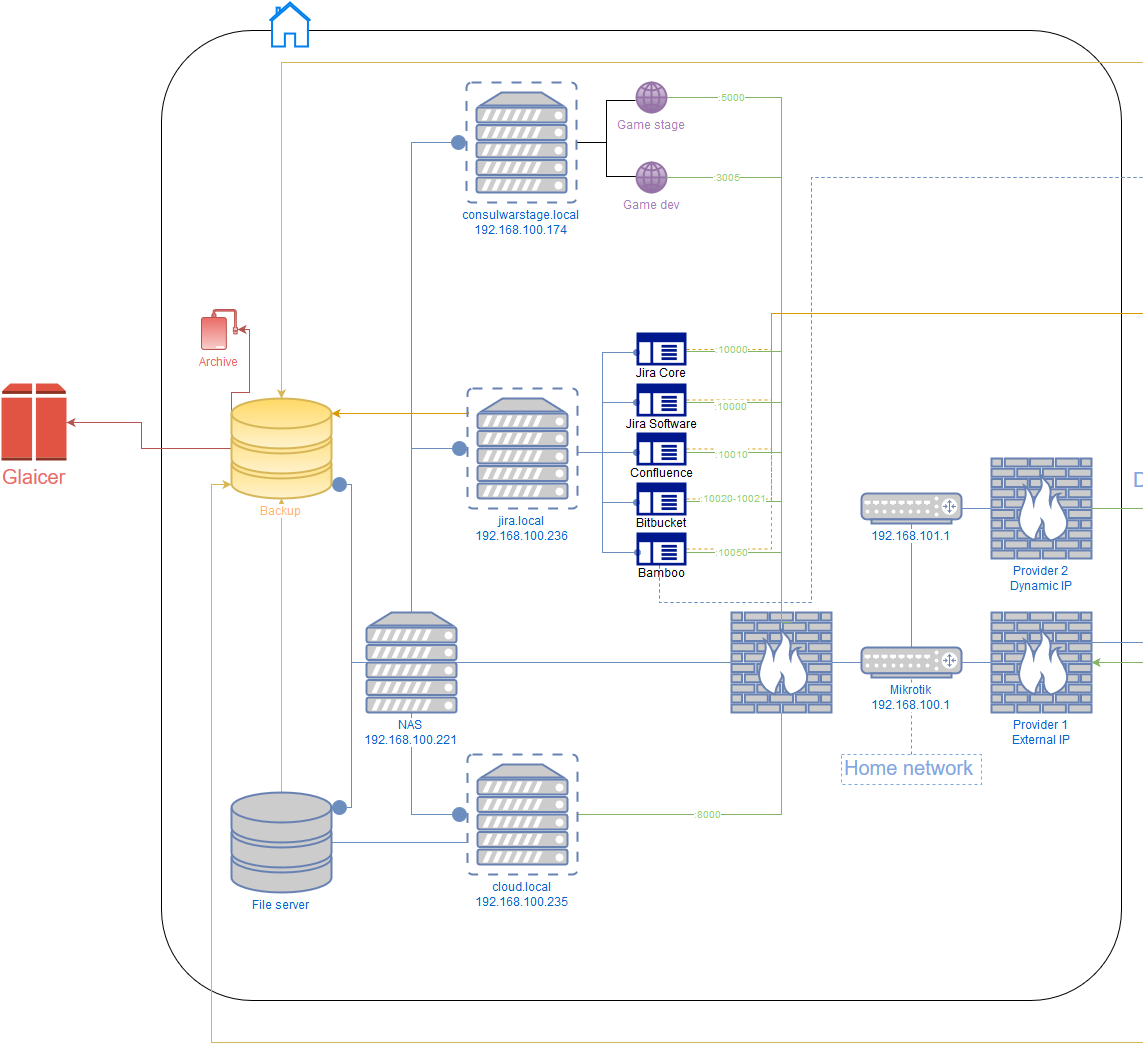
And this is a story about the left side of the scheme.
Where to store photos?
A slightly strange heading in the framework of this article, but this very question led to the appearance of a home server.
Before the trip to India right on the last day, the devil pulled me to go clean the matrix on the Canon D350 to an authorized center. There, the “master” with a dirty fucking claw scratched the matrix in the trash. Before the plane was less than 8 hours, so there was no time for disassembly, something must be solved. According to the reviews, we found a good point at the station, arrived there, gave it to the masters (there’s nothing to lose). The guys twisted, asked: “what happened to the matrix :-)”? .. They cleaned it somehow slyly and it became even acceptable (photos from India were made on this camera), for which they thank.
But when I came home, I was shooting a little, because all sorts of unpleasant stains in the photographs were spoiled even very successful frames.
It's time to take a new camera, but really seriously - FullFrame right away . First, the choice fell on the Nikon D800. 37 megapixels ... Mom dear, is that how much raw will it weigh? 50-100 megabytes! (As a result, by the way, I took the D750 with a much more pleasant weight of raw'ok.)
I like to keep the archive (deleting only duplicates and completely unsuccessful frames), and over time it became clear that there was just not enough home computer. With such a weight is 12,000 photos per terabyte. It seems that it is a lot, but in fact it is a few years of not very active shooting. To understand - over the past year, the archive has exceeded 50 thousand photos. And yes, sometimes for some tasks I return to my photo archive to find the one I need.
A little googling, I realized that NAS was invented just for this. Then I came across ZFS and realized that it is wonderful to detect problems that I have already had several times:

(It’s funny that I couldn’t upload a picture with an error; I had to take a screenshot and cut it out.)
Tracking down such problems is difficult. They were still able to fly to backup and duplicate in the raid.
I was also saved by the fact that NAS nifiga were not available in my city (Kaliningrad), although now the situation is a little better.
After a very long analysis (in general, it took more than 200 hours to solve the problem in the header), it was decided to build your server and put FreeNAS there.

In general, I collected right away for a long time, and the system potentially expands to petabyte storage and half a terabyte of RAM. At the moment there are only 12 terabytes of space and 32GB of memory. The total cost came out comparable or cheaper than ready-made NAS solutions (from 4 drives), while the flexibility and potential are much higher.
Setting up a home network
Immediately it became immediately obvious that the old dir-300 just wouldn't let me work comfortably with the server. Even if I took and went to pofot a bit, took 200 frames and started to dump (200 * ~ 75) 15GB, then the copy process itself would take about 20 minutes! Think about what speed we need? Judging by the tests, the disks in the planned WD Red storage system give out 100-150 megabytes per second, which means that the gigabit channel will be enough for us with exclusive use. And if just two users? For example, someone from the family will decide to watch a movie in HD 4k (from another physical disk)? This means that at least 2 channels should go to the server.
After analyzing the market, it became clear that we should take MikroTik . The choice fell on the CRS109-8G-1S-2HnD - eight gigabit ports and an incredible configuration capability.
Continuity of access
I was very frustrated when the inaccessibility of the network through the fault of the provider (Hello, Beeline!) Made it impossible for me to work. (Well, yes, there is still a mobile Internet, but this is not even a comfortable job at all, especially since he doesn’t catch anything here and also needs a separate solution in the form of an external antenna.)

Two providers work at our entrance - Beeline and Rostelecom. At first it was necessary to set them up separately, from which I started.
Oh, these dancing Beeline connections on microtic routers! I managed to connect with a tambourine and dances, but I ate a lot of time and nerves. Plus, a manual tune-up is sometimes required, since I didn’t like the solution with the constantly running script on the router at all. Beeline at the entrance, by the way, also distributes everything from the microtic, which was doubly surprising.
And Rostelecom is pulling the fiber to the apartment (Pitchfork this marketer!), So you can't do without an additional router. Well, the router is not connected with the microtic at all, since, in fact, it’s just a network.
At Beeline for an additional fee was purchased (a long time ago) external IP, which I always used as one of the authorization tools and for access to internal resources.
But in order for it all to work together and at the same time, it was necessary to tighten the knowledge of networks and packages. For more or less simple settings and understanding of what is happening, I advise you to familiarize yourself with the presentation Bandwidth-based load-balancing with failover. The easy way.
Public access to internal resources
On the server there will be some resources available from the external network. How to achieve this? As mentioned above, I have an external IP. The external IP is referenced by a generic subdomain of the form * .home.domain
There are several options to settle: layer 7 or port.
Initially, I set it up using layer 7 on the router, checking what was behind the asterisk and directing it to the right place, but it quickly became clear that such use very heavily loads the router's processor. Given the fact that the resources will be used only by a small circle of people, it was decided to use cheaper port addressing.
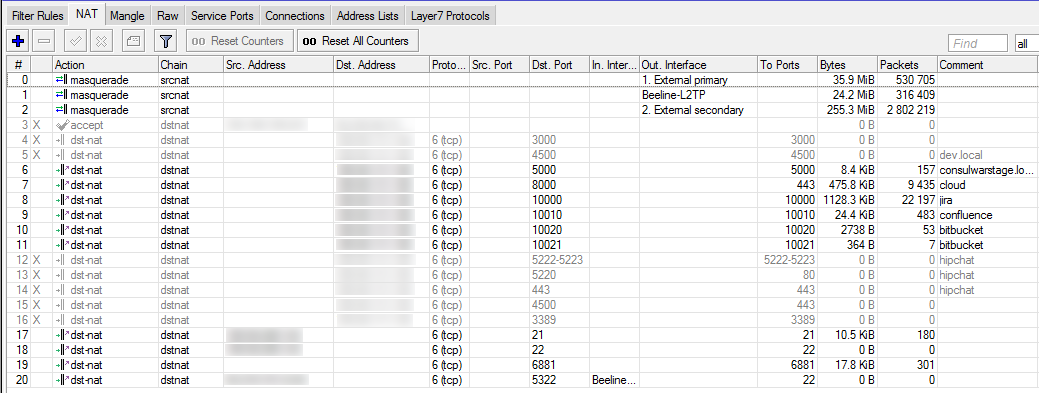
We set the rule in the firewall, allowing connection to certain ports on the external IP, add the rule to the NAT -connection with the internal ip and port ... It works! (By the way, when working with two connections, it is necessary that the answer goes through the same provider to which the request came. This is called sticky connections and described in the same presentation.)
Full access
Suppose we are leaving for some time in another country. How to get full access, as if I'm inside the network? Of course, you need a VPN .
On the router, we start the VPN server, add it to the bridge , create a user — that's it. A connection is created without any additional software.
Backup and backup strategy
Let's start by dividing the value of stored information. We distinguish three gradations:
1) (, ).
2) , ().
3) , ( , ).
4 : (media), (photo), (work), (backup).
:
work media.
backup .
photo , backup 50%. jpg . , .
media , .. .
:
jail , read-only backup. Amazon Glaicer work , jpg' .
:
, . — . Those. . , , .
? , . 5 : , , .
, .. , .
dropbox
, . , — . Owncloud — .
jail . jail -. owncloud .
. . .
Virtual machines
, , .
Virtualbox — . , .. jail phpvirtualbox FreeNAS.
virtualbox , freenas, , .
, , , . git , nodejs , . , , . All OK? , — , .
Docker , - . , , : « Docker, — », , , . — , - , 1 :-)
Jira — Confluence — Bitbucket — Bamboo
RealtimeBoard , . .
GitLab , . - , .
, Jira - , . , 10 10$. 60$ .
Jira
, — «».
20 .
— « ». , , «»:

1) -, «».
2) 6 : , , , , ( ), .
3) : , , .
4) . : (, ), , , , , post-. 10 .
5) : , , , — (, ).
6) , (, ).
7) . , « dev» bitbucket, , , dev. « » pull request' bitbucket' .
8) — «».
9) «» .
10) -, , « ».
11) - «» - «».
12)…
13) ???
999) Profit!
. :-) , , . , .
Confluence
. , Jira, .
, Jira. . , Jira . Conveniently!
.
Bitbucket
Git , .
, Jira, .
protected master dev. force , 1 . . , .
Bamboo
Gitlab CI , Jira — .
, , , , , .
, 1 , .
: , dev stage , master , , , , . :)
Slack
Slack , .. .
. , , — . , . , → . Conveniently. ? .
, , - .
What is the result?
, .. , - , .
. . , , .
, .
(, , , ), , . . , , .
— .
?
And the game is still in the open beta stage, and the gameplay itself is still far from the current plans, but we are moving towards it. We really like what comes out. We hope that the players too :) Now there is an active redesign, which is why some screens have gone a bit, but others are much better than what was before.

Honestly, I thought it would be a very small review article, and it came out like this.
I repeat - absolutely every point is worthy of an article (or even a cycle) of a similar volume.
As soon as there is time and a suitable mood, I will draw everything up. I apologize for some inaccuracies - many things were written from memory, and much time has passed. By preparing detailed articles there will already be accuracy :)
Well, if you have read to the end, then you - well done. Thanks for that .
Source: https://habr.com/ru/post/319582/
All Articles