Year without a single byte
 About the author. Archie Russell (Archie Russell) - Flickr Backend Engineer
About the author. Archie Russell (Archie Russell) - Flickr Backend EngineerOne of the most costly articles in a service like Flickr is storage. In recent years, we have described various techniques to reduce cost: the use of COS , dynamic resizing on a GPU, and perceptual compression . These projects were very successful, but we continued to lose a lot of money on data storage.
At the beginning of 2016, we set ourselves the task of reaching a new level - to hold out for a whole year without buying new media at all. Using various techniques, we succeeded.
')
Cost history
Small arithmetic calculations on a napkin show that storage costs are a real concern. On a high-traffic day, Flickr users upload up to 25 million photos. Each of them requires an average of 3.25 MB, for a total of 80 TB. Naively placing them on a cloud hosting like S3 photos of one day will draw on $ 30 thousand per year and will continue to generate costs every subsequent year.
A very large service has over 200 million active users. With a thousand photos, each of them is stored on a hosting like S3 for more than $ 250 million per year (or $ 1.25 per user), plus network and other costs. All this accumulates as new accounts are registered, and existing users take photos with growing speed. Fortunately, our costs, like the costs of any major service, are different from the naive storage on S3, but still remain significant.

The cost per byte has decreased, but the size of each photo from iPhone-like platforms has grown. Image costs have not changed significantly.
Storage costs do fall off over time. For example, S3 rates dropped from $ 0.15 per gigabyte per month in 2009 to $ 0.03 per gigabyte per month in 2014, and cloud hosting providers released new tariffs for storing data with rare access. NAS manufacturers also lowered prices.
Unfortunately, this reduction in cost per byte is balanced by opposite forces. On iPhone, the increase in camera resolution, continuous shooting mode and the addition of short animations (Live Photos) increases the size of the image in bytes so quickly that the cost of the image remains almost unchanged. And the images from the iPhone are far from the biggest.
To counteract these costs, photohosting introduced a number of options. Here are just a few of them: storing photos in low quality or clamping, charging users for data storage, introducing advertisements, selling related products such as paper photo prints, and linking hosting to buying mobile devices.
There are also a number of technical approaches for cost containment. We have outlined some of them, and below we describe three approaches that we implemented: setting thresholds in storage systems, extending existing methods to save space for more images, and introducing JPG compression without loss.
Setting thresholds in storage systems
We plunged into the problem and carefully examined our storage systems. We found that the settings were set up with the assumption of a large amount of rewriting and frequent deletion of information, which did not occur. Our storage is pretty static. Users very rarely delete or change images after downloading. We also have two reserved areas. 5% is reserved for snapshots — snapshots of state useful for canceling accidental deletions or rewrites, and 8.5% of free disk space is left in reserve. In total, about 13% of the site is not used. Professionals say that 10% of the disk should be left free to avoid performance degradation, but we have found that 5% is enough for our download. So we combined the two reserved areas into one and reduced the free disk space threshold to this value. This is our easiest method of solving the problem (for now), but it brought a good result. After a couple of small changes in the configuration, we released more than 8% of our carriers.

Setting thresholds in storage systems
Expansion of existing approaches
In previous articles, we have described the dynamic generation of reduced copies of images and perceptual compression. The combination of the two methods reduced storage space for reduced copies by 65%, although we did not apply these techniques to many images uploaded until 2014. There is one big reason for this: large-scale changes in old files are inherently risky, and the safe conduct of an operation requires considerable time and effort by developers.
We were afraid that if we expand the operation of the system of dynamic generation of reduced copies, this would greatly increase the load on the infrastructure of dynamic generation, so we decided to remove static reduced copies only from the least popular images. Using this approach, we kept all the load on the dynamic generation of reduced copies within the entire four GPUs. The process has heavily loaded storage systems; to minimize the load, we randomized operations across different volumes. The whole process took about four months, and as a result, we freed up even more space than after adjusting the thresholds in storage systems.
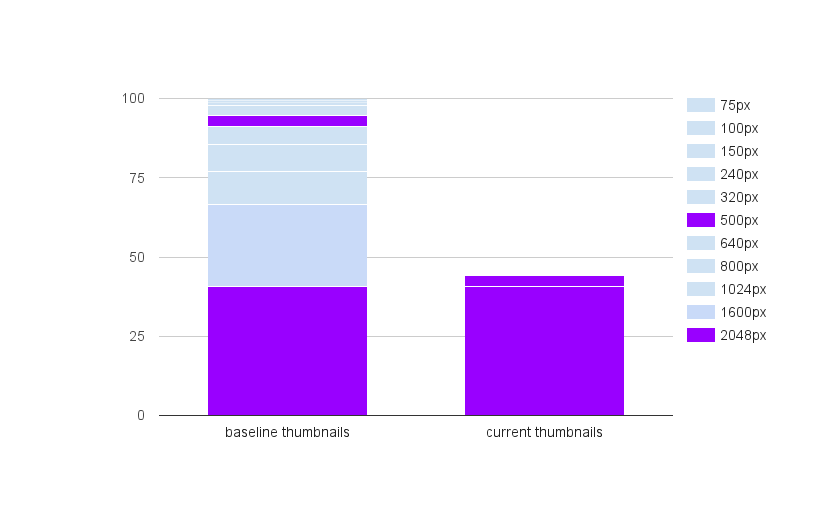
Reducing the number of thumbnail sizes
JPG lossless compression
Flickr has long been a supporter of the byte-accurate recording of downloaded images. This imposes a limit on the maximum possible amount of free space, but there are tools for compressing lossless JPG photos. Two well-known tools - PackJPG and Lepton , from Dropbox. These programs decode a JPG, and then very carefully compress it using a more efficient method. Usually it is possible to reduce the JPG by about 22%. The scale of Flickr is a lot. The disadvantage is that clamping consumes a lot of CPU resources. PackJPG works at a speed of about 2 MB / s on one core, that is, approximately 15 core-years will be needed to compress the petabyte of photos. Lepton uses several cores and at a speed of 15 MB / s is much faster than PackJPG, but requires approximately the same CPU resources to perform the same work.
This CPU requirement also complicates the daily operation of the service. If we press through all the images on Flickr, then we will potentially need thousands of cores to perform decoding tasks. We thought about introducing some restrictions on access to compressed images, such as requiring a user to authorize access to the originals, but ultimately decided that if we access only private photos with rare access, then unpacking will be an infrequent event. In addition, the limitation of the maximum size of images limited the maximum computational resources for unpacking. We rolled out this change as part of an existing set of technologies, without the requirement to allocate additional CPU resources, and only with the smallest change from the user's point of view.
Launching the lossless compression procedure on the original user photos was probably our most risky action. Smaller copies can be recreated without problems, but the damaged original image cannot be restored. The key element of our strategy was the “clamp-unpack-check” method: each squeezed image was unpacked and compared with the original original before the original was deleted.
Work is still ongoing. We squeezed a significant part, but processing the entire archive is a long process, and we have reached our goal of “not a single new byte per year” by the middle of the year.
Options for the future
There are a few more ideas that we are studying, but have not yet implemented.
In the current storage model for each image there is an original and thumbnails, which are stored in two data centers. Such a model suggests that images should be ready to view relatively quickly at any one time. But private photos on accounts that have been inactive for more than a few months are unlikely to be viewed. We can “freeze” these photos, erase their reduced copies and generate them again if the “sleeping” user returns. This “defrosting” process will take less than 30 seconds for a typical account. In addition, for private photos (but not “sleeping” users) we could switch to one uncompressed version of each reduced copy, keeping the compressed version in the second data center with the possibility of unpacking if necessary.
Perhaps we do not even need two copies on the disk of each original photograph of the “sleeping” user. We outlined a model in which we move one copy to a slower system with tape drives with sparse access, and leave the other on disk. This will reduce the availability of data during a crash, but since these photos belong to “sleeping” users, the effect will be minimal, and users will still see thumbnails of their photos. The most sensitive part here is the placement of data, because the search time on tape drives is prohibitively long. Depending on the conditions of what is considered a “sleeping” photo, such methods can save up to 25% more disk space.
We also studied the possibility of eliminating duplicates, but determined the number of duplicates in the region of 3%. Users do have a lot of duplicates of their own images on their devices, but they are calculated by our download tools. We also looked at alternative graphical formats that can be used for reduced copies. WebP may be more compact than regular JPG, but using perceptual compression allowed us to get closer to WebP in size in bytes with faster resizing operations. The BPG project offers much more efficient H.265 coding, but has intellectual property burdens and other problems.
There are several optimization options for video. Although Flickr is mainly for photos, video files are usually much larger and take up much more space.
Conclusion

Several stages of optimization
Since 2013, we have optimized our storage system by about 50%. Thanks to the latest efforts, we lived 2016, without buying a single additional carrier, and we still have additional optimization options.
Peter Norby, Teja Komma, Shijo Joy and Bei Wu formed the backbone of our team for zero-byte budget. Many others have contributed.
Source: https://habr.com/ru/post/319570/
All Articles