Horizontal scaling. What, why, when and how?

Alexander Makarov ( SamDark )
Hello! I am Alexander Makarov, and you can know me by the framework "Yii" - I am one of its developers. I also have a full-time job - and this is no longer a startup - Stay.com, which deals with travel.
Today I will talk about horizontal scaling, but in very, very general words.
')
What is scaling, in general? This is an opportunity to increase project performance in minimal time by adding resources.
Usually scaling does not mean rewriting the code, but either adding servers or expanding existing resources. For this type of allocate vertical and horizontal scaling.
Vertical - this is when they add more RAM, disks, etc. to an existing server, and a horizontal one is when more servers are put into data centers, and the servers there already interact somehow.
The coolest question they ask is - why is it necessary, if everything on me and on one server works fine? In fact, you need to check what will happen. Ie, now it works, but what will happen next? There are two wonderful utilities - ab and siege, which kind of overtake a competitor’s users cloud, who start to hammer the server, try to request pages, send some requests. You have to specify what they should do, and the utilities generate the following reports:

and
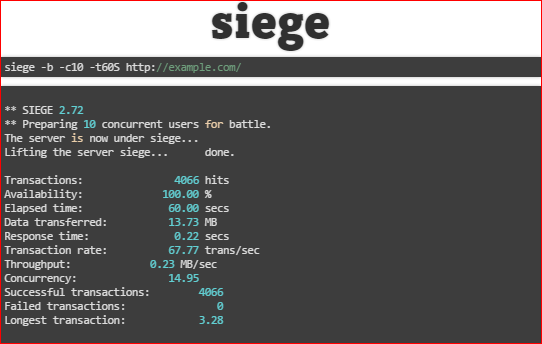
The main two parameters: n - the number of requests that need to be made; s - the number of simultaneous requests. In this way, they test competitiveness.
The output is RPS, i.e. the number of requests per second that the server is capable of processing, from which it will become clear how many users it can withstand. All, of course, depends on the project, it happens in different ways, but usually it requires attention.
There is one more parameter - Response time - response time, for which, on average, the server gave a page. It can be different, but it is known that about 300 ms is the norm, and what is higher is no longer very good, because the server performs these 300 ms, 300-600 ms are added to this, which the client performs, i.e. until everything is loaded - styles, pictures and the rest - time passes too.
It happens that in fact so far and do not have to worry about scaling - we go to the server, update PHP, we get 40% performance increase and everything is cool. Next, set up Opcache, tyunim it. Opcache, by the way, is tuned in the same way as APC, a script that can be found in the repository of Rasmus Lerdorf and which shows hits and missions, where hits are how many times PHP went to the cache, and how many times did it go to the file system get files. If you drive the entire site, or run some crawler under the links, or manually poke it, then we will have statistics on these hits and mismes. If hits are 100%, and misy is 0%, then everything is fine, and if there are misy, then you need to allocate more memory so that all our code fits into Opcache. This is a common mistake that is made - like Opcache exists, but something does not work ...
They also often begin to scale, but they don’t look, in general, because of which everything works slowly. Most often we climb into the database, we look - there are no indices, we put indices - everything flies right away, another 2 years is enough, beauty!
Well, you also need to enable the cache, replace apache with nginx and php-fpm to save memory. Everything will be cool.
All of the above is simple enough and gives you time. Time for the fact that once this will be enough, and for this we must now prepare.
How, in general, to understand what the problem? Either you have already reached highload, and this is not necessarily some crazy number of requests, etc., this is when your project does not cope with the load, and this is no longer solved by trivial methods. It is necessary to grow either in breadth or up. It is necessary to do something and, most likely, this is not enough time, something needs to be invented.
The first rule is that you can never do anything blindly, i.e. we need great monitoring. First, we gain time for some obvious optimization such as cache enablement or Main cache, etc. Then we set up monitoring, it shows us what is missing. And all this is repeated many times - you can never stop monitoring and refinement.
What can monitoring show? We can rest against the disk, i.e. in the file system, in memory, in the processor, in the network ... And it may be that, like, everything is more or less, but some errors fall. All this is allowed in different ways. You can, for example, solve a problem with a disk by adding a new disk to the same server, or you can install a second server that will only deal with files.
What you need to pay attention right now when monitoring? It:
- availability, i.e. whether the server is alive, in general, or not;
- lack of disk resources, processor, etc .;
- mistakes.
How to monitor all this?
Here is a list of great tools that allow you to monitor resources and show results in a very convenient way:
- Monit - mmonit.com/monit
- Zabbix - www.zabbix.com
- Munin - munin-monitoring.org
- Nagios - www.nagios.org
- ServerDensity - www.serverdensity.com
The first 4 tools can be put on the server, they are powerful, cool. And ServerDensity is hosted by someone, i.e. we pay money for it, and it can collect all data from the servers and display them for analysis.
There are two good services for monitoring bugs:
Usually we monitor errors like this - either we write everything to the log and then we look at it, or in addition we start emails or send sms to the developers. This is all normal, but as soon as we have a cloud of people on the service, and there is some kind of error, it starts repeating a very large number of times, it starts frantically spamming the email, or it overflows, or the developer completely loses attention and he starts to ignore letters. The above services take and errors of the same type are collected in one big pack, plus they consider how many times errors have occurred recently and in priorities the whole business is raised automatically.
Sentry can be delivered to your server, there is a source, and Rollbar is not, but Rollbar is better because it takes money for the number of errors, i.e. encourages to correct them.
About the notification, I repeat that you should not spam, attention is lost.
What, in general, need to analyze?

RPS and Response time - if the response time begins to fall, then we need to do something.
The number of processes, threads and queue sizes - if it all starts to multiply, get clogged up, etc., then something is wrong again, you need to analyze in more detail and somehow change the infrastructure.
Also worth looking at business analysis. Google Analytics for site types is great, and mixpanel - for event logging, it works on desktop applications, on mobile, on the web. It is possible and on the basis of some of their data to write, but I would advise the finished services. The point is that our monitoring can show that the service is alive, that everything works, that the overall Responce time is normal, but when we, for example, register in the mixpanel, we start tracking, it shows that they are somehow not enough. In this case, it is necessary to look at how quickly certain events, pages, and what the problems are. The project should always be “hung” with analysis in order to always know what is happening, and not to work blindly.
The load, in general, arises or is planned, or not, may occur gradually, maybe not gradually:

How to deal with the load? All business solves, and only the issue price is important. Important:
- for the service to work,
- so that it is not very expensive, do not ruin the company.
The rest is not very important.

If it is cheaper to scan, optimize, write to the cache, fix some configs, then this should be done without thinking about scaling and buying additional hardware, etc. But it happens that "hardware" becomes cheaper than the work of a programmer, especially if programmers are very savvy. In this case, the scaling begins.

In the figure, the blue thing is the Internet, from which requests are coming. A balancer is put, the only task of which is to distribute requests to separate front-end servers, accept responses from them and give them to the client. The point here is that 3 servers can handle (ideally) 3 times as many requests, excluding any overhead for the network and for the work of the balancer itself.
What does this give us? The above ability to handle more requests, and more reliability. If the traditional scheme falls nginx or application, or rested on the disk, etc., then everything fell. Here, if we have one frontend fell off, then that's okay, the balancer, most likely, it will understand and send requests to the remaining 2 servers. Maybe it will be a little slower, but it's not scary.
In general, PHP is a great thing to scale, because it follows the Share nothing principle by default. This means that if we take, say, Java for the web, then the application starts, reads all the code, writes the maximum data to the program memory, everything is spinning, working, the request takes very little time, very few additional resources. However, there is an ambush - because the application is written in such a way that it should work on one instance, be cached, read from its own memory, then nothing good can happen when scaling. And in PHP, by default, there is nothing in common, and this is good. All that we want to share, we put it in memcahed, and memcahed can be read from several servers, so everything is fine. Those. weak connectivity is achieved for the application server layer. It's fine.
What, in general, to balance the load?
Most often this was done by Squid or HAProxy, but this is before. Now the author of nginx took and parted from nginx + balancer in nginx, so now he can do all the things that Squid or HAProxy used to do before. If it starts not to withstand, you can put some cool expensive hardware balancer.
The problems that the balancer solves are how to choose a server and how to store sessions? The second problem is purely PHP's, and the server can be selected either in turn from the list, or by the geography of some IP's, or by some statistics (nginx supports least-connected, that is, to which server there are fewer connections , he will throw it on him). We can write for the balancer some code that will choose how to work with it.
Here, this link describes a balancer svezhepartirovanny in nginx:

I recommend it to everyone, there are very simple configs, everything is as simple as possible.
What if we hit the balancer?
There is such a thing as DNS Round robin is a great trick that allows us not to spend money on a hardware balancer. What are we doing? We take a DNS server (no one hosts the host DNS server, it’s expensive, not very reliable, if it fails, then nothing good will happen, everyone uses some companies), we write more than one server in the A record, and a few. These will be A-records of different balancers. When the browser goes there (there are no guarantees, in fact, but all modern browsers do this), it selects one of the A-records from the A-records in turn and gets either to one balancer or to the second. The load, of course, may not be spread evenly, but at least it is smeared, and the balancer can withstand a little more.
What to do with the sessions?
Sessions are default files. This is not the case, because each of the frontend servers will have sessions in its file system, and the user may fall for one, then the second, then the third, i.e. session, he will lose every time.
There is an obvious desire to make a shared file system, connect NFS. But you don’t need to do that - it’s dreadfully slow.
You can write to the database, but also not worth it, because The database is not optimal for this work, but if you have no other choice, then, in principle, it will do.
You can write in memcached, but very, very carefully, because memcached is, after all, a cache and it has the ability to wipe out as soon as it has few resources, or there is no place to write new keys - then it starts to lose old without warning session start to get lost. For this, you must either follow, or choose the same Redis.
Redis is a normal solution. The point is that we have Redis on a separate server, and all our frontends break in there and start reading their sessions with Redis. But Redis is single-threaded and sooner or later we can properly rest on it. Then do sticky sessions. The same nginx is put and it is informed to it that it is necessary to make the session so that the user, when he came to the server and was given a session cookie, so that later he would only go to this server. Most often this is done by IP-hash. It turns out that if Redis is on each instance, respectively, there are different sessions there, and the read-write throughput will be much better.
What about cookies? You can write to cookies, there will be no repositories, everything is fine, but, first, we still need to have session data somewhere, and if we start writing cookies, it can grow and not get into the repository, but , secondly, you can only store IDs in cookies, and we still have to contact the database for some session data. In principle, this is normal, solves the problem.
There is a cool thing - a proxy for memcached and Redis:

They, it seems, support parallelization out of the box, but this is done, I would not say that it is very optimal. But this thing - twemproxy - it works something like nginx with PHP, i.e. as soon as the answer is received, it immediately sends the data and closes the connection in the background, it turns out faster, consumes less resources. Very nice stuff.

Very often there is such a mistake of “cycling” when they start writing, such as “I don’t need sessions! I will now make a wonderful token that will be transferred back and forth ”... But, if you think about it, this is again a session.
In PHP, there is a mechanism like session handler, i.e. we can put our handler and write to cookies, to the database, to Redis - anywhere, and all this will work with standard session start, etc.

Sessions should be closed by this wonderful method.
As soon as we read everything from the session, we are not going to write there, it needs to be closed, because the session is often blocked. It should, in general, be blocked, because without locks there will be problems with competitiveness. On the files, this can be seen immediately, in other repositories the blockers are not on the whole file at once, and this is a little easier.
What to do with the files?
You can cope with them in two ways:
- some kind of specialized solution that gives an abstraction, and we work with files as with a file system. This is something like NFS, but NFS is not necessary.
- Sharding with PHP.
Specialized solutions from what really works are GlusterFS. This is what you can set yourself. It works, it is fast, gives the same interface as NFS, only works at a normal, tolerable speed.
And Amazon S3 is, if you're in the Amazon cloud, is also a good file system.
If you implement from the side of PHP, there is a wonderful library Flysystem, covered with excellent tests, it can be used to work with all sorts of file systems, which is very convenient. If you immediately write all the work with files with this library, then it will be easy to transfer from the local file system to Amazon S3 or others - to rewrite the line in the config file.
How it works? A user loads a file from a browser, he can either get to the frontend and crawl out of file servers from there, or a script for the upload is made on each file server and the file is uploaded directly to the file system. Well and, in parallel, it is written to the database, which file on which server is lying, and we can read it directly from there.
It is best to distribute files with nginx or Varnish, but it's best to do everything with nginx, since we all love and use him - he will cope, he is good.

What is going on with the database?
If everything has come up against the PHP code, we are doing a bunch of front-ends and still accessing the same database - it will cope for a long time. If the load is not terrible, then the database lives well. For example, we did JOINs with 160 million rows in the table, and everything was fine, everything ran well, but there, however, the RAM needed to be allocated more for buffers, for cache ...
What to do with the database, if we rested in it? There are techniques such as replication. Usually, master slave replication is done; there is a replication master master. You can replicate manually, you can do sharding and you can do partitioning.
What is a master slave?

One server is selected as the main server and a bunch of servers are secondary. It is written on the main one, and we can read from the master, but we can also read from the slaves (in the picture, the red arrows are what we write, the green arrows are what we read). In a typical project, we have read operations much more than write operations. There are atypical projects.
In the case of a typical project, a large number of slaves can relieve both the master and, in general, increase the speed of reading.
It also provides fault tolerance - if one of the slaves has fallen, then nothing needs to be done. If a master falls, we can quickly make one of the slaves a master. True, this is usually not done automatically, it is an emergency situation, but there is a possibility.
Well, and backups. Database backups do everything differently, sometimes it is done by a MySQL dump, while it freezes the entire project tightly, which is not very good. But if you make a backup from some slave, after stopping it, the user will not notice anything. It's fine.
In addition, on the slaves, you can do heavy calculations, so as not to affect the main base, the main project.
There is such a thing as read / write split. There are 2 server pools being made - a master, a slave, a connection on demand, and the logic for choosing a connection varies. The point is that if we always read from slaves, and always write to the master, there will be a small ambush:

those.replication is not immediate, and there is no guarantee that it will be executed when we make any request.
There are two types of samples:
- for reading or for output;
- for recording, i.e., when we have chosen something and then it needs to be changed and written back.
If the sample is for recording, then we can either always read from the master and write to the master, or we can execute “SHOW SLAVE STATUS” and see Seconds_Behind_Master there (for PostgreSQL there is also a super query in the picture) - it will show us a number. If this is 0 (zero), it means that everything has already been replicated in our country, we can safely read it from the slave. If the number is greater than zero, then we must look at the value — either we should wait a bit and then read from the slave, or read from the master immediately. If we have NULL, it means that we have not yet replicated, something is stuck, and we need to look at the logs.
The reasons for this lag are either a slow network, or the replica fails, or too many slaves (more than 20 to 1 master). If the network is slow, then it is understandable, it must be somehow accelerated, assembled into single data centers, etc. If the replica fails, then you need to add replicas. If there are too many slaves, then you have to come up with something interesting, most likely, to do some kind of hierarchy.
What is a master master?
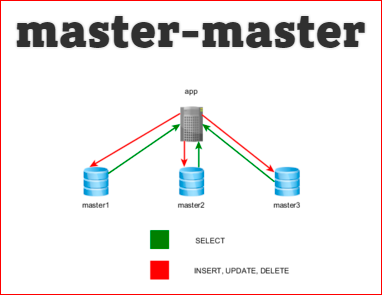
This is a situation where there are several servers, and it is written everywhere and read. The advantage is that it can be faster, it is fault tolerant. In principle, everything is the same as that of the slaves, but the logic, in general, is simple - we simply choose a random connection and work with it. Cons: the replication lag is higher, there is a chance to get some inconsistent data, and if any breakdown occurred, it starts to spread over all the masters, and no one knows what kind of master is normal, what kind of broken ... This whole thing begins to replicate by circle, i.e. very weakly clogs the network. In general, if you had to do a master-master, you need to think 100 times. Most likely, you can get by with a master slave.
You can always replicate with your hands, i.e. organize a couple of connections and write immediately in 2, 3, or something to do in the background.
What is sharding?
In fact, this spreading data across multiple servers. You can shard individual tables. Take, for example, a photo table, a user table, etc., we take them to separate servers. If the tables were large, then everything becomes smaller, memory eats less, everything is fine, only JOIN'it is impossible and you have to make queries of the WHERE IN type, i.e. First we select a bunch of ID's, then we substitute all these ID's for the request, but to another connection, to another server.
You can shard some of the same data, that is, for example, we take and make several databases with users.

You can simply select the server - the remainder of the division by the number of servers. The alternative is to get a card, i.e. for each record, keep in some Redis or the like. value key, i.e. where is the record.
There is an easier option:
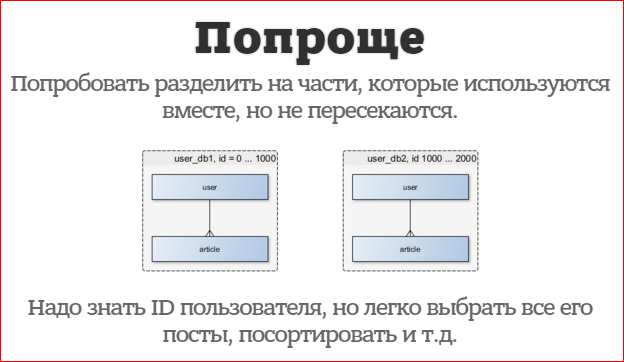
Harder is when you cannot group the data. You need to know the ID of the data to get them. No JOIN, ORDER, etc. In fact, we are reducing our MySQL or PostgreSQL to a key-valuation storage, because we can not do anything with them.
Common tasks become unusual:
- Select TOP 10.
- Page breakdown.
- Choose the lowest cost.
- Select user posts X.
If we zashardirovali so that everything scattered across all servers, it is already beginning to be solved very nontrivially. In this situation, the question arises - why should we, in general, SQL? Shouldn't we write to Redis right away? Did we choose the right storage?
Out of the box, sharding is supported by such things as:
- memcache;
- Redis;
- Cassandra (but she, they say, does not cope at some point and begins to fall).
How to deal with statistics?
Often they like to count statistics from the main server - from a single database server. This is fine, but requests in statistics are usually creepy, multi-page, etc., therefore, it is a big mistake to consider statistics on the main data. For statistics, in most cases, realtime is not needed, so we can set up a master slave replication and already calculate these statistics on the slave. Or we can take something ready - Mixpanel, Google Analytics or the like.

This is the main idea that helps to spread everything across different servers and scale. Firstly, a profit is immediately visible from this - even if you have one server and you start to do something in the background, the user gets an answer much faster, but later spreads the load, i.e. we can drag all this processing to another server, we can even process it in PHP. For example, in Stay.com, the pictures are resized on Go.
How?
You can immediately take Gearman. This is a finished piece for processing in the background. There are libraries for PHP, drivers ... And you can use queues, i.e. ActiveMQ, RabbitMQ, but the queues send only messages, they don’t call the handlers themselves, they don’t execute, and then you have to think of something.
The general sense is always the same - there is the main software, which places some data in the queue (usually this is “what to do?” And data for this), and some service — it either gets enough or it arrives (if the queue is able to actively to lead) this data, it processes everything in the background.
Let's go to the architecture.
The most important thing when scaling is to make as little connectivity as possible in the project. The less connectedness, the easier it is to change one solution to another, the easier it is to transfer part to another server.
Connectivity happens in the code. SOLID, GRASP - these are the principles that allow to avoid cohesion precisely in the code. But coherence in the code for the separation of the servers, of course, affects, but not as much as the coherence of the domain layer with our environment. If we write a lot of code in the controller, it turns out that we will probably not be able to use it in another place. It will not be easy for us to transfer all this from the web controller to the console and, accordingly, it is more difficult to transfer to other servers and process there differently.

Service-oriented architecture.
There are 2 approaches to partitioning systems:
- , .., , , , , ..
, , .. … , Sales Customer — , , , . , ; - — , .. Sales Customer user, 2 user. , -. , .
, . , , Sales - , , , «» .
What is with the domain layer?
The domain layer is divided into some services, etc. - This is important for the development of the application, but for scaling its design is not very important. In the domain layer, it is extremely important to separate it from the environment, the context in which it runs, i.e. from the controller, console environment, etc., so that all models can be used in any context.
There are 2 books about the domain layer, which I advise everyone:
- “Domain-Driven Design: Tackling Complexity in the Heart of Software” by Eric Evans,
- "Implementing Domain-Driven Design, Implementing Domain-Driven Design".
I also advise you to follow the links:
- BoundedContext — http://martinfowler.com/bliki/BoundedContext.html (, — ,
, , user); - DDD — http://martinfowler.com/tags/domain%20driven%20design.html — .
In architecture, again, it is necessary to adhere to the principle of share nothing, i.e. if you want to do something general, always do it consciously. Logic is preferably thrown on the side of the application, but in this it is worth knowing the measure. You should never, say, do stored procedures in a DBMS, because it is very difficult to scale. If it is transferred to the application side, then it becomes easier - we will make several servers and everything will be executed there.
Don't underestimate browser optimization. As I have already said, of those 300-600 ms, which requests are executed on the server, 300-600 ms are added to them, which are spent on the client. The client doesn’t care if the server is fast or if the site worked so quickly, so I advise using Google PageSpeed, etc.
As usual, abstraction and fragmentation are not at all free. If we break up the service into many microservices, then we will no longer be able to work with beginners and will have to pay our team a lot and a lot to dig through all the layers, to sort through all the layers, besides this the service may start to work more slowly. If in compiled languages it is not scary, then in PHP, at least until version 7, it is not very ...
Never act blindly, always monitor, analyze. Blindly, almost all the default solutions are wrong. Think! Do not believe that there is a "silver bullet", always check.
Some more useful links:

On ruhighload.comalmost all principles are painted in a super-accessible form, very superficially, but coolly, with drawings, etc. I advise you there to look at the reviews of how various large companies found cool solutions.
In the English-speaking Internet, the word “highload” is not known, so search there by the word “sclability”.

Often it is tried on live servers. To do this in any case is not necessary, there are such cool things as DigitalOcean and Linode, where you can raise the node, deploy any environment there, any server, potest everything, paying for it 1-2 bucks, maximum.
PS Full slides of this speech, see slides.rmcreative.ru/2015/horizontal-scaling-highload/ and blog rmcreative.ru .
Contacts
» SamDark
This report is a transcript of one of the best speeches at the 2015 HighLoad ++ Junior high-load system developers training conference .
- Junk! - you say.
- Eternal values! - we will answer.
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we have begun preparations for the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior .
Source: https://habr.com/ru/post/319526/
All Articles