Neurogrid plays dota
Hello! In fact, the neural grid does not play the usual Dota 2, but in RussianAICup 2016 CodeWizards. RussianAICup is an annual open competition in artificial intelligence programming. To participate in this competition is quite interesting. This year the theme was a game similar to DotA. Since I have been training with reinforcements for some time, I wanted to try to apply it in RussianAICup. The main goal was to teach the neural network to play this game, although the occupation of the prize place would be nice, of course. As a result, the neural network keeps around 700 places. Which, I think, is not bad, due to the limitations of the competition. This article will focus on training with reinforcements and the DDPG and DQN algorithms , rather than the competition itself.
In this article I will not describe the basic information about neural networks, now there is a lot of information about them on the Internet, and I don’t want to inflate the publication. I would also like to focus on reinforcement learning using neural networks, that is, on how to train an artificial neural network to demonstrate the desired behavior by trial and error. I will describe the two algorithms in a simplified way, they have one base, and the fields of application are slightly different.
Markov state
At the input, the algorithms take the current state of the agent S. Here it is important that the state have the Markov property, that is, if possible, include all the information necessary to predict the next system states. For example, we have a stone thrown at an angle to the horizon. If we take the coordinates of a stone as a state, it will not allow us to predict its future behavior, but if we add a velocity vector of a stone to the coordinates, then this state will allow us to predict the entire further trajectory of the stone, that is, it will be Markov. Based on the state, the algorithm provides information on action A, which must be done to ensure optimal behavior, that is, such behavior that leads to the maximization of the amount of rewards. The reward R is a real number that we use to train the algorithm. The reward is given at the moment when the agent, being in the state S, performs the action A and changes to the state S '. For learning, these algorithms use information about what they did in the past and what was the result. These elements of experience consist of 4 components (S, A, R, S '). These fours we add to the array of experience and then use for training. In the articles, it is named replay buffer.
')
DQN
Or Deep Q-Networks is the same algorithm that was taught to play Atari games . This algorithm is designed for cases when the number of control commands is strictly limited and in the case of Atari it is equal to the number of joystick buttons (18). Thus, the output of the algorithm is a vector of assessments of all possible actions Q. The vector index indicates the specific action, and the value indicates how good this action is. That is, we need to find an action with the maximum rating. In this algorithm, one neural network is used, to the input of which we feed S, and the action index is defined as argmax (Q). We teach the neural network using the Bellman equation, which ensures the convergence of the neural network output to values that implement the behavior that maximizes the sum of future rewards. For this case it looks like:
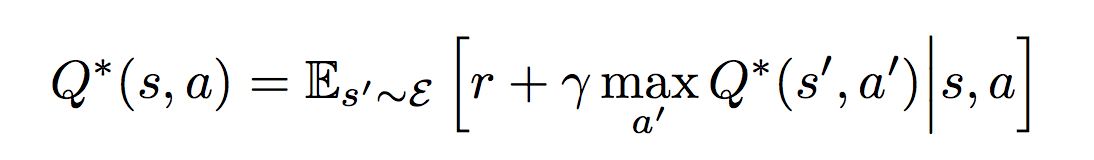

If this decrypts the following:
- Take a pack (minibatch) of N experience elements (S, A, R, S '), for example 128 elements
- For each item count
y = R + γ * max for all A ' (Q past (S', A '))
γ is the discount factor, a number in the interval [0, 1], which determines how important future awards are for us. Typical values are usually selected in the range of 0.9 - 0.99.
Q past is a copy of our neural network, but a certain number of iterations of learning backwards, for example 100 or 1000. We simply update the weights of this neural network periodically, do not teach.
Q past = (1 - α) * Q past + α * Q
α - update rate Q past , a typical value of 0.01
This trick provides the best convergence of the algorithm. - Next, we consider the loss function for our minibatch.
L = Σ by minibatch elements (y - Q (S, A)) 2 / N
We use the mean square error - Apply favorite optimization algorithm using L
- Repeat while the neural network does not learn enough
If you look closely at the Bellman equation, you can see that it recursively evaluates the current action by a weighted sum of rewards from all subsequent actions possible after the current action has been completed.
DDPG
Or Deep Deterministic Policy Gradient is an algorithm created for the case when control commands are values from continuous spaces (continuous action spaces). For example, when you drive a car, you turn the steering wheel at a certain angle or press the gas pedal to a certain depth. Theoretically, there are theoretically infinitely many possible values of the steering wheel rotation and the positions of the gas pedal, so we want the algorithm to give us these very specific values that we need to apply in the current situation. Therefore, in this approach, two neural networks are used: μ (S) is the actor that returns us the vector A, whose components are the values of the corresponding control signals. For example, this could be a vector of three elements (steering angle, accelerator position, brake pedal position) for the autopilot of a car. The second neural network Q (S, A) is a critic, which returns q - an estimate of the action A in the state S. The critic is used to train the actor and is trained using the Bellman equation:
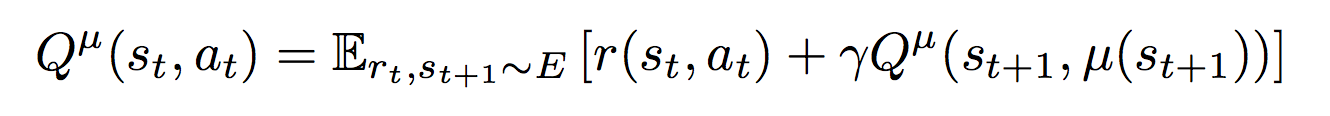
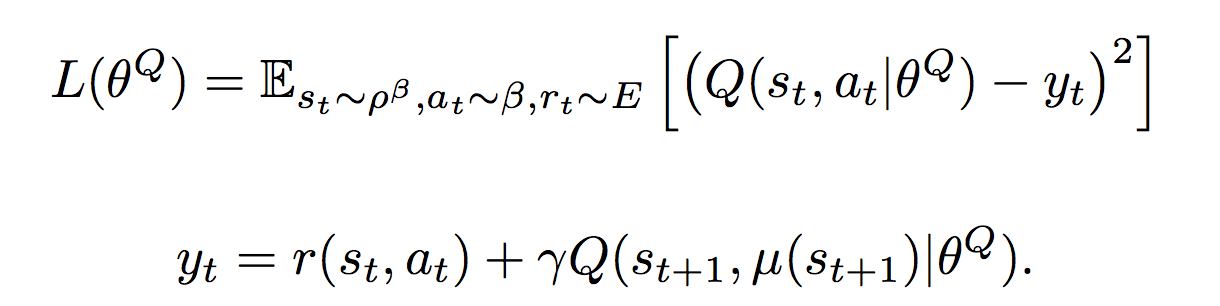
The critic is trained through the gradient from the evaluation of the critic ∇Q (S, μ (S)) by the actor weights
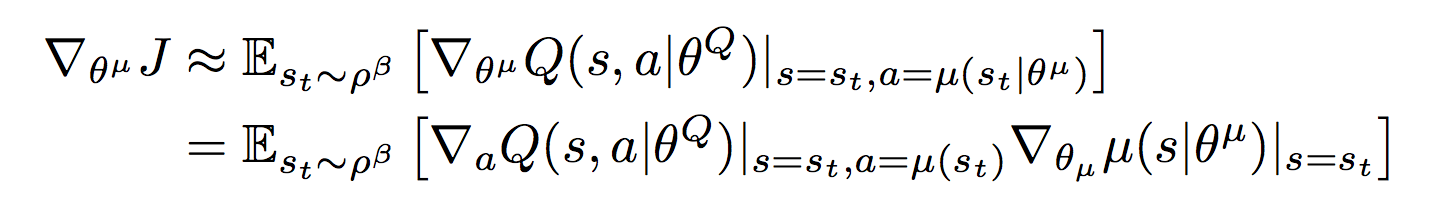
If this decrypts:
- We take minibatch from N elements of experience (S, A, R, S ')
- y = R + γ * Q past (S ', μ past (S'))
Q past , μ past is the same trick as in the case of DQN, only now it is a copy of two networks - We consider the loss function
L = Σ by mini-batches (y - Q (S, A)) 2 - We teach criticism using L
- We take the gradient in the weights of the actor ∇Q (S, μ (S)) by our favorite optimization algorithm and modify the actor with it
- Repeat until we reach the desired
RussianAICup
Now I will talk about the agent I coached for the competition. Detailed rules can read the link , if interested. You can also watch the video and description on the main page . In the competition there are 2 types of games, the first is when your strategy controls one of ten wizards. And second, when your strategy controls a team of 5 wizards, the enemy controls the opposite team of 5 wizards. The information that is available for the strategy includes all objects that are in the field of visibility of all friendly wizards, the rest of the space is covered with the fog of war:
- wizards
- minions
- buildings (towers and bases)
- the trees
- bonuses
- shells
A unit may have the following information about itself:
- coordinates
- number of hit points
- amount of mana
- time to next strike
- other parameters, there are many, in the rules there is a full description
There is a local simulator (it is on KPDV), in which you can drive your strategy against yourself or 2 built-in opponents, rather simple strategies. To begin, I decided to try to solve the problem in the forehead. I used DDPG. I collected all the available parameters about the world, they turned out 1184 and filed for input. The output I had was a vector of 13 numbers responsible for the speed of movement directly and sideways, rotation, different types of attack, as well as attack parameters, such as the range of the projectile, in general, all the parameters that exist. With a reward for the beginning, I also decided not to be wise, the game gives out the number of XP, so I gave a positive reward for increasing XP and a negative one for decreasing hit points. Having experimented for some time, I realized that in this form it is very difficult to get from the neural network sense, since the dependencies that my model had to reveal were, according to my estimates, quite complex. Therefore, I decided to simplify the task for the neural network.
For a start, I rebuilt the state so that it represented not just a collection of all the incoming information, but was submitted as a circular review from a controlled wizard. The whole circular review was divided into 64 segments, each segment could get 4 closest objects in this segment. There were 3 such circular reviews for friendly, neutral and enemy units, as well as to indicate where to move. The result was even more parameters - 3144. I also began to give a reward for moving in the right direction, that is, along the path to the enemy base. Since the circular view includes information on the relative position of objects, I also tried to use the convolutional network. But nothing worked. Wizards just spun in one place without the slightest glimpse of intelligence. And I left for some time trying to read information about training neural networks and get inspiration.
After some time, I returned to the experiments, having already inspired, reduced the learning rate from 1e-3 to 1e-5, greatly reduced the number of input parameters to 714, while abandoning some data in order to speed up the information processing. I also decided to use the neural network only for movement and rotation, and left the shooting behind a manually-written simple strategy: if we can shoot, we turn in the direction of the weakest enemy and shoot. Thus, I removed from the neural network a task that is rather difficult for learning, but easy for prescribing: aiming and shooting. And he left a rather difficult formalizable task of advance and retreat. As a result, glimpses of intelligence on a conventional fully connected network became noticeable. After training it for some time (a couple of days on the GeForce GTX 1080 for the experiment), having achieved a good management quality (the network beat the built-in opponent), I decided to load the network into the sandbox.
I unloaded the weights of the network from Tensorflow and zhardkodil them in the form of h files. The result was an archive of several tens of megabytes and the sandbox refused to accept it, saying that the maximum file to download is 1 MB. I had to cut down the neural network much more strongly and spend a lot of time (about a week or a few weeks, I don’t remember exactly) on its training, selection of hyperparameters and fit into the 1 MB archive size. And when I finally tried to download again, it showed that the limit for the unzipped archive is 2 MB, and I had 4 MB. Feyspalm. Overcoming stormy feelings, I began to squeeze the neural network even more. As a result, it has shrunk to the following architecture:
394 x 192 x 128 x 128 x 128 x 128 x 6 394 is the input layer, in all layers except the last and the last but one, relu is used, in the last but one tanh as an activation function, in the last one there is no activation function. In this form, the control was not so good, but a glimpse of intelligence was noticeable and I decided to load this option exactly a few hours before the start of the final. With minor improvements, he still plays russianaicup.ru/profile/Parilo2 in the sandbox around 700 places in the ranking. In general, I am pleased with the result at the moment. Below is a video with an example of a 1x1 match, my strategy controls the whole team of 5 wizards.
Suggestions for improving the competition
The competition is quite interesting to participate. There are buns in the form of a local simulator. I would like to suggest changing the format somewhat. That is, to run on the server only the server part and the rating table, and the clients to connect via the Internet to the server and participate in duels. In this way, you can take the load off the server, as well as remove resource restrictions for strategies. In general, since it is made in many online games like Starcraft 2 or the same Dota.
Code
Agent code is available on github . Used with C ++ for both management and training. The training is implemented as a separate WizardTrainer program, which depends on TensorFlow, the strategy connects over the network to the trainer, throws the state of the environment there and receives from there the actions that need to be performed. She also sends all the experience she receives there. Thus, several agents can be connected to one neural network and it will manage all at the same time. It's not so easy to collect it, if you need to ask me how.
Resources
For more information about training with reinforcement, these, as well as other algorithms, you can see in David Silver's wonderful course from Google DeepMind. Slides are available here .
Original articles DDPG and DQN . I took the formulas from them.
Thank you for reading to the end. Good luck on the path of knowledge!
PS I apologize for the size of the formulas, I didn’t want them to be small, I overdid it with a print screen.
Source: https://habr.com/ru/post/319518/
All Articles