Working with DSL: creating your own analyzer using Python libraries
In our blog on Habré, we write not only about topics related to information security, but we pay considerable attention to software development issues - for example, we are conducting a cycle about creating and implementing DevOps tools . Today we will discuss the use of domain-specific languages (DSL) for solving specific problems using Python.
The material was prepared on the basis of a statement by Positive Technologies developer Ivan Tsyganov at the PYCON Russia conference ( slides , video ).
')
Task
Imagine that we decided to write our own log rotation system. Obviously, it needs to be customized. The structure of the real Log Rotate config is similar to the Python dictionary. Let's try to go this way and write our configuration in the dictionary.
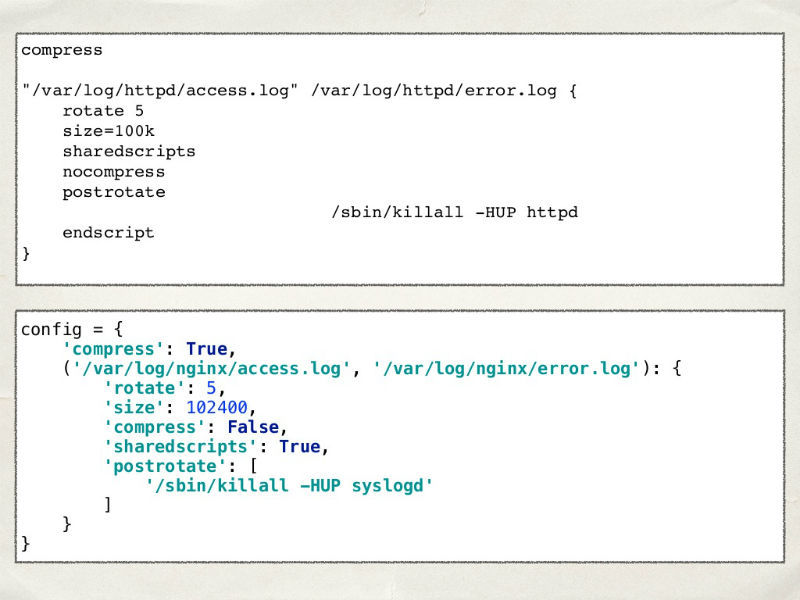
It seems to be all right - there is a list of files, the rotation period is also there, everything is the same. The only difference is that in Log Rotate we can specify the units of measure for the file size, but in our configuration - for now. The first thought is to allow them to be set in a special line and to process it, splitting into spaces.

This is a good way that will work until the moment when users of our system ask you to let them specify a delta to the size used (“1 megabyte + 100 kilobytes”). Why they need it, they did not say, but we love our users. To implement this functionality, we use regular expressions.

It seems to be working, but users now want not only support for operations of addition, subtraction, multiplication and division, but also for all arithmetic. And here it becomes clear that using a regular expression to solve such a problem is not a good idea. Much better suited for this subject-oriented language.
What is DSL
According to Martin Fowler's definition, a subject-oriented language (DSL) is a language with limited expressive capabilities, focused on a specific subject area.
There are internal and external DSL. The first include such libraries as PonyORM, WTForm and Django models, and the second SQl, REGEXP, TeX / LaTeX. Internal DSLs are a kind of extension to the base language, and external ones are completely independent languages.
If we develop an internal DSL for our task, we can create a function or a constant that can be used inside the configuration file.

But the restrictions imposed by the basic language will remain and we will not succeed in getting rid of the extra brackets and multiplication signs between the number and the variable (MB, KB).
When using the same external DSL, we will be able to invent the syntax ourselves - this will allow us to get rid of the unnecessary brackets and multiplication signs. But we will have to develop our language analyzer.
Let's return to our task.
But what if we need to store the configuration file separately from the code? This will not be a problem. Just save our dictionary with the configuration in a YAML file and allow users to edit it.
Technically, this YAML is already an external DSL, and no analyzers are needed for it. You can load it using existing libraries and process only the size field:

Analyzers in Python
Take a look at what Python has to write analyzers.
Library PLY (Python Lex-Yacc)
The analyzer consists of lexical and syntactic analyzers. The source text goes to the input of a lexical analyzer, the task of which is to split the text into a stream of tokens, that is, the primitives of our language. This stream of tokens enters the parser, which checks the correctness of their location relative to each other. If everything is in order, then either the code is generated, or its execution, or the construction of an abstract syntax tree.
Tokens are described by regular expressions: four tokens for arithmetic operations, a token for units of measure, numbers and brackets. If our lexical analyzer feeds the expression below, it will parse it into the next token stream:

But if you pass it a semantically incorrect string, we get a meaningless set of tokens:

In order to avoid unnecessary work on the analysis of the correct location of tokens, we need to describe the grammar of our language.

We define that an expression can be a number or a digit, followed by a unit of measure, an expression in brackets, or two expressions separated by an operation.
For each rule, an explanation is needed of what the parser should do when the conditions described by it arise. Since we are dealing with arithmetic, it is also desirable to comply with all its rules - with the priority of multiplication operations, parentheses, and so on.
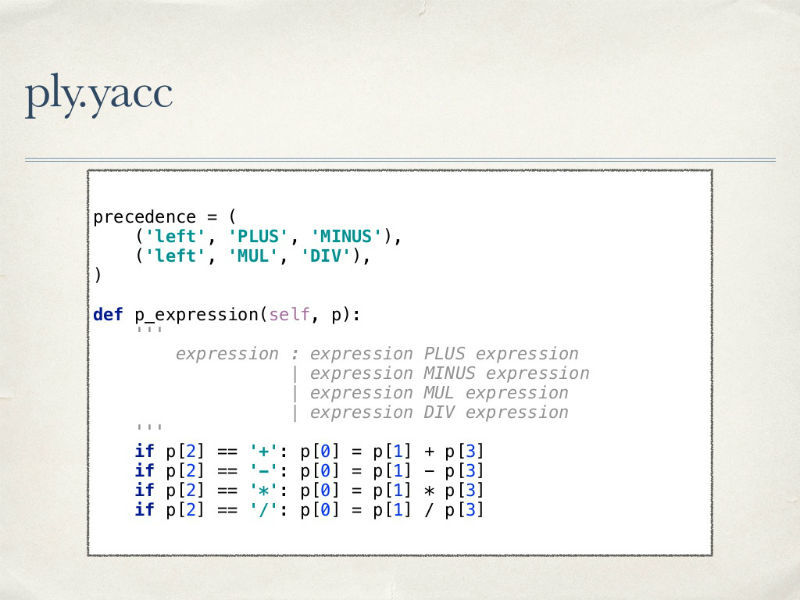
Using the PLY tool has a number of advantages: it is flexible, provides convenient debugging mechanisms for analyzers, excellent error handling methods, and the code of the library itself is well read.
However, it is impossible to do completely without drawbacks - the input threshold at the start of using the tool is very high, and analyzers using PLY are truly verbose.
Library funcparserlib
Another interesting tool for creating analyzers is the funcparserlib library. This is a functional parser combinator. Analyzer development using this library also begins with the declaration of tokens as regular expressions. Then the parser itself is described - the primitives are defined, the operations used are described, which, for the convenience of processing, are also grouped by priority (multiplication and division / addition and subtraction).

Now we need to describe the rest of the grammar - for this we declare, describe what the expressions will look like, and then describe the priorities of the operations.

The advantages of funcparserlib include the compactness of this library and its flexibility. Because of the same compactness, a lot of things have to be done in it by hand - out of the box there are not many possibilities available. And since this library is a combinator of functional parsers, it will appeal to lovers of functional programming.
Pyparsing library
Another option for creating an analyzer is the pyparsing library. Immediately take a look at the parser code:
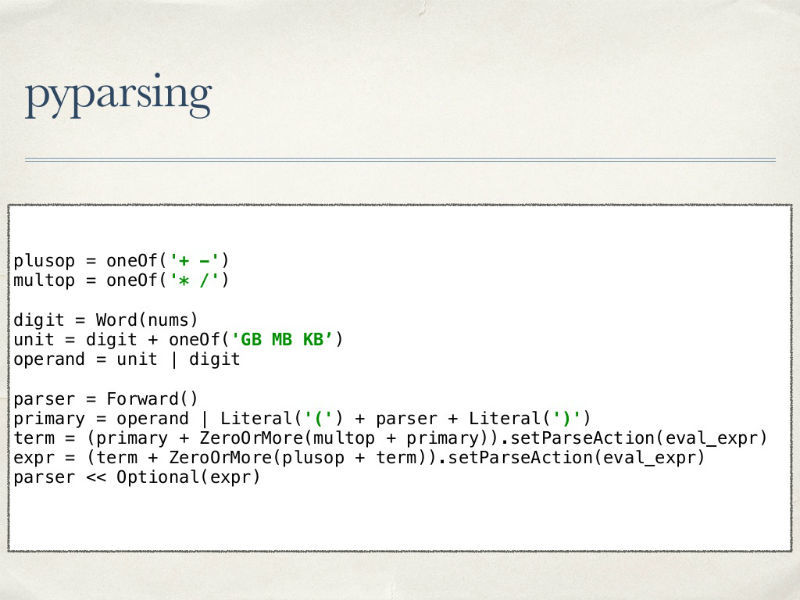
Nowhere are tokens described; all attention is immediately paid to the final language and the description of operations on expressions with regard to priorities.
In out-of-box pyparsing there are useful basic elements, for example, methods for working with priorities - this simplifies the code and makes it more understandable. In addition, there is the possibility of extending functionality and creating your own components. On the other hand, the tool cannot boast of having high-quality documentation, and debugging the resulting compact analyzer is much more complicated than a word-of-mouth analyzer using PLY.
What about speed
Let's talk about the speed of work in case of using each of the described libraries. Our analysis shows that when processing simple cases, PLY turns out to be the fastest.

In the course of the tests, we “fed” to all analyzers the task of adding all numbers from zero to 9999. Here is the result in milliseconds that the candidates showed:

Error messages
Do not forget that we wrote our analyzer in order to parse one of the fields in the config of the log rotation system. Obviously, if any errors occur in the analyzer's work, the user needs to report this in a clear format - in which line, in which position and what exactly went wrong.
Another advantage of PLY is that the library has a built-in error handling mechanism that occurs during the lexical and syntactic analysis stages. At the same time, the state of the parser is not lost - after an error, you can try to continue working

What ultimately choose
The final choice of the parser creation tool depends on the tasks and conditions of their execution. There are a number of such combinations:
- If you need to quickly describe everything, and speed is not the main thing - pyparsing is quite suitable.
- In case you like functional programming, and speed is also not very important - funcparserlib is the obvious choice.
- But if the speed of work is most important and I would also like to describe all the rules “as it should be” by textbooks - of course, you need to choose PLY.
If there is a possibility of processing user data by means of the language itself, it is worth doing so, or using regular expressions. In more complex cases, it makes sense to start with the use of internal DSL, and if this option is not suitable, start using ready-made languages to structure the data (Yaml, Json, XML). To write your own analyzers should be in extreme cases when none of the above does not solve the problem.
Source: https://habr.com/ru/post/319320/
All Articles