The evolution of the process of deployment in the project

Denis Yakovlev ( 2GIS )
My name is Denis, I work at 2GIS, for about a year and a half I have been working on continuous delivery for web-department projects. Prior to that, he worked at Parallels and there he went from being an engineer to a team lead.
About deploy. If you and I are not releasing a boxed product, but writing some service that works somewhere, as many call it in the wild, on servers where users go, then it’s not enough for us to develop this service and test it; it is somehow enclosed in this wild nature, i.e. deliver the code there with everything necessary for its work.
')
What does it consist of? We need to deliver, first of all, the code - something we have been working on for a considerable amount of time, testing and so on.

We can do it in many ways, generally accessible and not so much, we can flood it somehow, we can connect our servers to the version control system and just get out of it.
Next, the data.

If we have a database, i.e. we use a database in our service, we periodically have a need to do something with this data. We need to either change the database structure or change the data itself, i.e. if we constantly write some new functionality, we develop, inevitably this happens with us. This is mainly done through migration. Probably everyone already knows this mechanism. If we use some generally accepted framework in development, not written by us, but which exists, everyone knows it, there are built-in migrations, i.e. we do all the usual commands. For example, yii migrate, django-admin migrate.

Few services require configuration. We added code, the data was updated, we had some changes, we have to configure. We have a config file, there are some values there, we change them, and in the process of life, we also add new values to these config files, or old ones are deprived, they are dropped. After all of this has changed, we need to either restart any services or leave them as they are.

If we have not done without using third-party software, we need to take care that we need to somehow put this software on our servers, configure it in a certain way, which we need, and upgrade it in a timely manner. Or do not upgrade, if suddenly in the new version of the software any bug came out so that everything would not have happened.
What are the decisions "head on"?

We have one servachok, we go and do it all with pens, because all the steps are known, everything is known how to do. And we have, let's say, the development team and the operating team - some admin is sitting. The development team writes documentation that now such a release and for its successful deployment you need to do this, this and that. The admin looks at this documentation, goes via SSH to the server and it handles it. So he went once, went twice, then he got tired of it.

He naturally takes what is generally available and at hand. He takes Bash, Perl and all that automates, because why do it all with your hands, when you can automate it all and just run Bash.
Pros:

It's all simple, well, fast, we work, the code is divisible, we do not notice anything, but this is good only until a certain time, for simple projects. We have, let's say, one servachok, there is a database on it, our code lies on it - this is quite a manager by one person, and he can cope with it completely.
Minuses:

But we want to develop, we develop. Our service becomes complicated, we have new services, more users come, we no longer do with one server, we already have new components, i.e. we no longer have one server with a code, but we already have a large combat circuit consisting of several servers, components, and so on. And we have in connection with this increasing complexity, i.e. with our development, there are problems that were not there before. We are increasing the amount of documentation, i.e. information on how a specially trained person to release. Even if this person has long prepared scripts that, under certain conditions, performed their work well, the complexity of these scripts also increases, their number grows, now you need to upgrade more than one server, but you need to upgrade the database, upgrade the code, something else is needed do. The difficulty increases. Scripts - this is also the software in which there may be bugs, it also starts to bring a certain headache.
Since we started all this very quickly, until we experienced any special problems, we have some amount of manual labor. At first it is not very noticeable, and then it grows like a snowball, and manual labor is an additional source of human error. Someone wrote something wrong and wrong there, or wrote it there, but not so, the second one copied incorrectly, and as a result we get a situation where there are a lot of errors and they all arise, and it’s not clear when they will end and from where come from. As a result, we have this specially trained person who was responsible for the releases, all he does is release. Those. he has no time for any of his other tasks, no time for even eating. He rolled out one release while he was rolling out, came the second release, during this release there were some errors, then another patch came for this release. In general, this big, such smut, nervousness increases, and business comes to us and says: “What can't you deliver to customers? This is simply and quickly, and here we still have a car of features going on, let's do something about it! ”
For some time, there is such an approach in our industry as Infrastructure as a code, which tells us that we need to approach the description of the configuration of our application just as we approach the development of software. So Keif Morris said:

This is a little more than simple automation, because automation is what we just take and everything we do with pens, we drive into the script, and it works. In the “Infrastructure as a code” approach, we use all practices, tools and approaches. We take it from the software development of our service and apply to the description of the infrastructure. Those. if a new approach has emerged, respectively, tulses will appear over time, i.e. software.
What tools are there?
There is such a class of products - Configuration Management System, i.e. CMS (not to be confused with Content management system!). Typical representatives - Ansible, Chef, SaltStack, Puppet. They are designed to help us, as developers or companies, in infrastructure management. And one of the tasks, one of the use cases of using such software is to bring our system into a certain state described by us. Those. if we have, we have been allocated an abstract server, there is nothing there or there is some bare axis, then with the help of such tools we bring the server to the state we need.
Let's look at some of these tools. I chose those that are used in our company to explain with examples. First, Anisble.

This software is quite simple to understand, it is written in Python, modular, it is fairly easy to install and, as we noted for the company, the threshold of entry for using Ansible is quite low. Those. if we take a person, we say: here's Ansible for you, figure it out and start using it, by the end of the week he writes cheerfully, he understands it all.
What do we need to do after we have installed Ansible?

We first need to write, and what do we even have, with what we want to work? Those. we create a simple text file, and we write as an example above that we have the [webservers] group, we have two exams - www.example1.com and www.example2.com , the [dbservers] group, i.e. db1, db2. Roughly speaking, this is our battle circuit, and we want to work with it.
Further, in Ansible there is such an entity - playbooks:

A playbook is a set of instructions, i.e. those steps that Ansible have to do to bring our servers into the state that we need. Those. playbooks consist of hosts (we specify which hosts we want to work with) and tasks — we specify the steps Ansible needs to be taken. And there is a command - we say: "Launch this playbook, get information about hosts from this file."
Example playbook:

We specify hosts (if anyone remembers - webservers). This is the group of hosts that we have listed in the Ansible Inventor. We say that we want to put nginx on the servers that we specified there.
Tasks consist of two steps in this case:
- we first declare the name so that we can later figure out what we are doing, i.e. we write Install nginx - this step is responsible for installing nginx and we write in this case yum - this is the Ansible module, which is responsible for installing via yum. We say: "yum, put us the latest version of nginx package."
- The next step is to configure nginx, so we say to the template module: “We have default.conf file in this playbook, please put it along this path and after you have done it, i.e. . notify, restart nginx ".
We run the ansible-playbook command with this playbook, and after doing this playbook, we have an installed nginx on our webservers group servers, configured as we need.
The architecture looks like this:
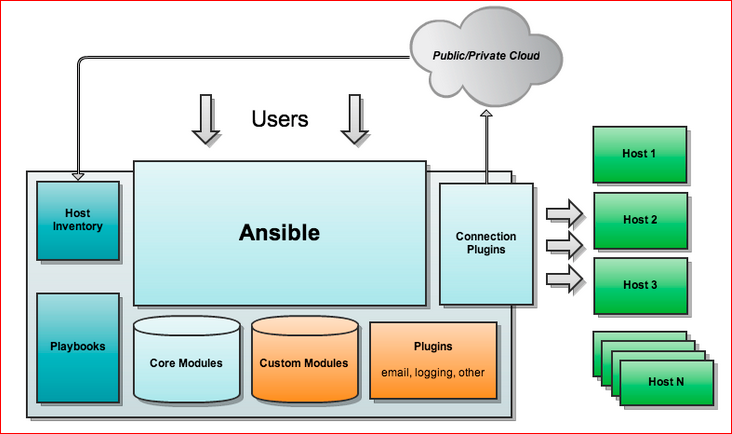
I took it from the Internet, this image can be freely google. We have Host Inventory, Playbooks, Core Modules - these are modules that are written by the Ansible team itself, which is exactly what yum, apt, and so on; Custom Modules - this is what is written there community or some other contributors; Plugins. Ansible starts, goes to the hosts and performs what it needs. It is noteworthy that on those hosts with which we work, we do not need additional software, i.e. how our servers stood-worked for us, so they work. There should be, in my opinion, only Python, but Python is almost everywhere.
With this in brief, let's see, for comparison, Chef.

Chef is the same software class, but written by another company. In my opinion, it is a bit more complicated, it may even be much more complicated than Ansible, because we have, if a person starts writing and understands Ansible by the end of the week, and begins to give out some kind of code, and with Chef several weeks to deal with it , how does it work, what chips to produce some kind of result.
How do we use terms here?

- Cookbooks are recipes. If, in the case of Ansible, everything is human-readable, well and understandable, then in the case of Chef cookbooks, this is Ruby here, it will take some time to learn, if not completely, but some basic level of this programming language.
- We also have Roles - ways to group Cookbooks. Suppose we have a “web server” role to configure a web server. We need to put nginx, configure, do something else, pop-up and so on. We have divided it into several cookbooks, and we are doing a separate role - the “web server”, in which we say that these cookbooks are included there, and we assign this role to the servers we need. And then we see that we have so many web servers, and in such ways we bring them to the desired state.
- We have Environment - a description of our environment, i.e. if we have a development environment, a staging environment, there is a production environment, which differs in some settings, i.e. we have here an opportunity, in my opinion, to describe in JSON, to declare a list of variables that distinguish our environments, respectively, to assign values for each environment.
Chef exists in several configurations, i.e. how to install it.
- Chef server.
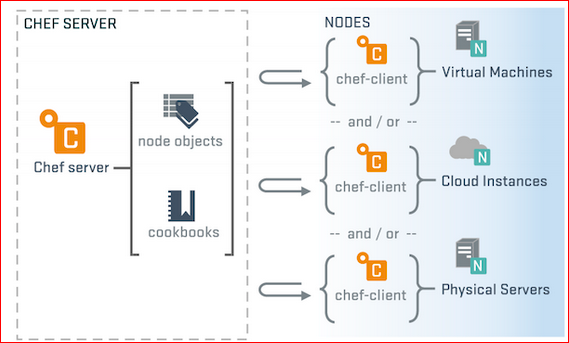
We put a separate server somewhere in our environment, in which all our cookbooks, roles, environments, description nodes and so on are stored.
On each node of ours there is a client software - Chef client, which is configured on this server. And it goes there for the description of this node, i.e. she comes and
says: “I am such a node, please tell me what I have for roles, for some additional settings, for recipes that I need
to do? Chef server replies to her: “Here, please follow these recipes with these input parameters,” and the utility uses it all.
If anyone noticed, the Ansible is a little different, i.e. in the case of the Chef server, we, first, install additional software on our nodes, and we go
on the nodes themselves, or somehow remotely have to call this Chef client. In Ansible, we say Ansible playbook on our working wheelbarrow, and it goes on its own via SSH
does everything on our servers.
But this is one configuration Chef. - Next we have Chef zero - this is a light version of Chef Server, i.e. without gui, it is in memory, i.e. we just lifted it up so lightly, loaded all our information there for testing, checked it all out, stopped it, killed Chef zero, and everything was free in us - everything is fine.
- There is also Chef solo - this is the open source version of the Chef client utility, which, unlike the first two cases, does not require connecting to some external server. We don’t need a Chef server or Chef zero here, we simply say Chef solo in this case that: “We have a path that our recipes lie on, please follow from here and there such recipes.” In this configuration, we get that all our cookbooks, recipes should be at the right time for us on the same instance where we have Chef solo.
This is a simple example of what a nginx installation on Chef looks like in recipes.

I want to point out that this is a very small part of the functionality of all these tools that I mentioned, i.e. there are much more possibilities, use cases, components and so on. These are big complex tools, they solve a wide range of tasks, but now in the framework of this report, we are talking only about one use case - how will we understand.
Suppose we looked at something, decided, decided that some tool is suitable for us, and what awaits us besides any technical questions? We work in a team. We can say that from today we use, say, Ansible. Well, what do we get next?
We receive new process issues - this is a zone of responsibility, i.e. I, as a team leader, decide that we now use Ansible, but I have a question, who should write my playbooks?

Developers? They come to me and say: "We will not write playbooks, because we do not know the combat configuration." Well, I go to admins and say: "Now you write playbooks". They say: “We will not write playbooks, sorry, we will not, because we do not know the application.” This is an example of air to understand. And we have to somehow resolve this situation, because it turns out that the knowledge for writing playbooks and recipes is spread. We have a part of knowledge in one team, a part - in another team.
I will give an example of how such a thing we decided in our department. We have a lot of products, services, and they are of varying degrees of complexity. And one very complex, highly loaded our project is the Web API. We did this: our admins took Chef, wrote the entire database. We have 3 data centers for 18 servers, decentralization and more. And such administrators took over the task, wrote all this configuration, got divided into all data centers, made sure that it all worked. Then in the process of product life, when those parameters change which the admins do not know about, as I gave an example - i.e. something changed in our kofig, we started to use other, some other utilities ... This is all that is decided during the product development process. Admins have come, taught developers how to write playbooks, told what Chef is, what it is eaten with, how to cook, and then after this point the development team itself began to write these playbooks. When our changes are critical or very complex, risky, the development team takes it, writes it itself and simply gives it to the administrators for a review, and they watch how it will fit into the current infrastructure and leave some comments.
Other services are simpler. They took and saw that Chef is too difficult, redundant and so on for us. They took Ansible, wrote it themselves, quickly figured it out, wrote everything themselves, came to the admins and said: “Look, is it possible?”. They looked and said: "Yes, no, I do not know, maybe."
With the area of responsibility the question arises. Silver bullets, like almost everywhere, no. It is necessary so rezolvit, probably, in each project, in each service in its own way.
And, of course, our workflow is changing. We have new tasks, tools, and our workflow development is changing.
If with writing, everything is clear - we looked at something, studied it, we were given an instance of this Chef server or something else, we took our favorite text editor, somehow got used to it, started writing ... But the next question arises - what we need - it's all testing, because we get exactly the same code as he behaves, we also need to understand. And if, God forbid, at this moment, the developers deploy their services to themselves on the working wheelbarrow, here everything is bad and sad, and without virtualization you will not get by. Because I need to raise a wheelbarrow, suddenly I wrote something bad there that everything broke, I need to quickly kill it all, redo it, fix it, redo it, see how it works ... I know, I saw such teams, I saw such companies which still do not use virtualization at all. Maybe this is normal, permissible, but I personally do not understand how to live without virtualization. If we deploy on our car and there is no virtualization, then in this moment it is simply necessary.
Vagrant is not a testing tool, but it can help us see quickly. What is this Vagrant? This is a software for creating a virtual environment. This is a wrapper over many virtualization providers, like virtual boxing, VM var, and so on. And a plus - it still has integration with the above configuration systems, i.e. with Chef, Ansible, with Puppet.
To deploy my car, i. I set myself a Vagrant and I just need to do a vagrant init - this is what I specify, what distribution I need.

In my current directory, a vagrant file appears - the configuration file of my future virtual machine. And in the same directory I say: “vagrant up” and after a while a virtual machine rises on my host, where I can do what I want, then bang it and something else, i.e. do with it what I want.
Here is a quick example about Chef solo:

In the Vagrant file, I write that in my Chef Solo provision, my cookbooks are located there, and please add me a recipe for this machine, which is called apache and is responsible for installing apache.
Then, when I say “vagrant up” for this machine, it rises, and this recipe, which sets apache, is executed.
Vagrant'a itself is not enough for testing. I saw in the RootConf program there is a separate report on how to test the infrastructure. They talk about test frameworks, which allow you to test the infrastructure. I know that there is a test kitchen, which is based on Vagrant, and it allows me to write tests when we bring up a virtual machine, and you point out to him: tie me a system, virtualization ... Then you say: I have a set of tests that look simple enough, we need to check that everything was set up in our country, that the demons were running, the files we need are in a certain place. Actually, we write tests of this kind, and after raising a virtual machine, it runs them and says “OK” or “not OK”.
These are all the simplest options, i.e. infrastructure testing is also a separate big topic. We have slightly opened the door to this world, but there are still many questions, many techniques and so on.
What would you like to recommend, where to start? The tools are large, a lot of information, I want to take a try. From myself I can say that the recommendations are as follows - if we have some small simple service, then take what is already known, i.e. put nginx or postgres and stuff. Try to start with a little, write a recipe, playbook, perform simple, well-known actions, then you can understand, you need it at this stage, or you are still satisfied with the bash scripts, or you do it with pens. Understand whether you need this. And understand that you are more comfortable.
I gave a reference here:
- https://galaxy.ansible.com
- https://supermarket.chef.io/cookbooks
- https://docs.ansible.com/playbooks_best_practices.html
Each tool has community, bestpractice, repositories with written cookbooks, i.e. all known software that needs to be installed, configuration, and more. As for this, all playbooks have already been written, best contracts have been worked out, and we go to these supermarkets or Galaxy and just take what we need - like cubes - and execute, build, so we have a ready infrastructure.
Regarding such an important aspect as the cost, we can say that these products are mostly free. hef started wanting money from the 12th version, so many are still sitting on the 11th version, and Ansible want money for the web-face, I think the Ansible tower is called. And in other configurations, all this can be taken for free and quickly applied.
Contacts
» 2GIS company blog
This report is a transcript of one of the best speeches at the training conference for developers of high-load systems HighLoad ++ Junior .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we have begun preparations for the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior .
Source: https://habr.com/ru/post/319314/
All Articles