Comparative analysis of traffic balancing methods

Sergey Zubov ( CDNvideo )
Today I would like to give a certain overview report on balancing traffic in high-load systems. Since the report is a review, we will consider various methods of balancing, what is balancing, in principle, various methods and algorithms of balancing, and will sound the pros and cons of a particular method.
')
Imagine such a surreal situation that we are farmers who are engaged in selection work, and we derive, say, new types of potatoes. We walk, we grow our own potatoes, we have great potatoes, everyone loves her, everyone likes her. We sell it on the market and then we thought: how can we find another way to sell it? We remembered that we were guys with IT's past, we did it once, we left to the breeders for the sake of a hobby, and we decided: let us sell it on the Internet.
They went, without thinking twice, bought a server, wrote down a certain web service of our online store on it, and the clients went to us. Customers have gone, sales are growing, server load is increasing, increasing, increasing. We understand that the load is growing, the server must also be somehow upgraded. We increase its capacity, we increase, we increase, customers come more and more, and, in the end, we come up against such a situation that there is no place to upgrade the server.
Such an unpleasant situation happens that the year is poor, and all the competitors have potatoes. And we have the same selection potatoes, we have it cool and drought-resistant, and everyone rushed sharply to us. Moreover, they rushed so that the load on the server increased to such an extent that the server just picked up and fell.

We took hold of the head, thought: what to do? Began to google sharply and stumbled upon such a thing as "clustering". They decided: why don't we buy another server and spread our web server on it? Went, bought, installed, and thought that everything would be good for us, that customers would start to go to both our servers, the load would level out a bit, and everything would be fine.
But after the launch, we understand that the load on one of the servers is the following:

and the load on the second server is still this:
Question: why is this happening?
And everything happens because we did not take into account the fact that the traffic between these servers must be somehow balanced. Actually, here we turn to the main question - what is balancing, and what main goals does it pursue?

First of all, balancing is used to distribute the load between our servers. Secondly, due to balancing we can increase the fault tolerance of our system, that is, for example, if one of our servers in the cluster fails, the second takes over the load if it can pull it. Through balancing, some protection against certain types of attacks, such as attacks on all connections, is also achieved.
To balancing, as well as to any system, certain demands are made. Requirements are:
- balancing must meet the requirements of fairness, i.e. Any request that comes to our system should be serviced, not just abandoned;
- balancing should be effective, i.e. we must ensure that it works in such a way that all our servers in the cluster work approximately evenly and take on a uniform load;
- due to balancing the query execution time should be reduced, i.e. the response time should be reduced - as soon as the request comes to our system, we must serve it as soon as possible, respond to it;
- balancing must meet the requirements of predictability, i.e. we must clearly understand which balancing algorithm and in which case we should use;
- uniformity of system load, in principle, this requirement is similar to efficiency;
- balancing should be scalable, i.e. With a sharp increase in load, the balancing system should ensure the stable operation of our service.
Balancing can conditionally be divided into two types according to geography - balancing can be local if we have servers located inside one data center, and balancing can be global if our resource is scattered on servers across different data centers.
More about each.

Locally the balancing system can be applied:
- at the channel level, both with the use of a separate balancer, and without it;
- at the network level;
- at the transport level.
These are the most common methods that are used for local balancing.
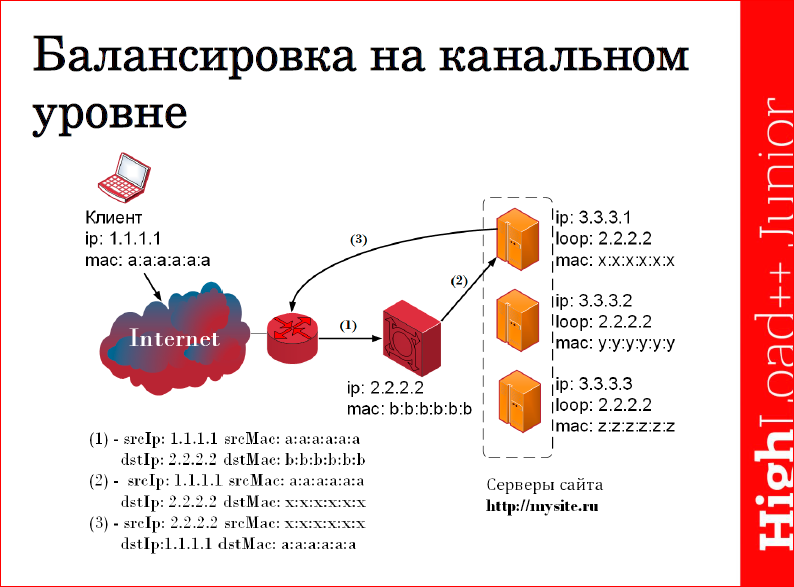
Channel level balancing is performed by the following. We take and hang on the same specialized interface of all our servers the same IP-address of our resource, to which requests will come, and from which answers will go. But the ARP request from this IP address of the server should not be answered. And we hang the same IP address on our balancer, respectively, requests will come to it, and responses from it will be sent, and it will respond to ARP requests. Thus, when receiving a request from a client, our balancer chooses a particular server using a certain algorithm, which will process this request, replaces the destination MAC and sends it to the server for processing. The server handles it, and since we did not replace the headers at the network level, then directly, bypassing the balancer, immediately responds to the client through our gateway.
Here the leadership comes to us, and says: “Guys, we sat here on VKontakte, looked through, all sorts of memes were honored and understood that men often demand borscht from their wives. We thought and decided that let us make an advertising campaign for beets, and we will sell beets. And all the money we put in there. And we will ask you to somehow reduce the cost of your cool balancing system. ”
We thought and decided: why don't we get rid of the balancer? But at the same time, we figured out how we can realize balancing without it.

And we can implement it very simply: we need to turn an incoming unicast request into a broadcast, or into a multicast, who wants it.
This is done as follows. All servers must respond to the ARP request with the same MAC address, i.e. it can be either a non-existent MAC address or some kind of multicast one. Or we can hang this multicast MAC address on our gateway. Accordingly, the request comes to our resource, and the gateway simply propagates it to all servers, so requests are sent to all servers at the same time, and each server must itself understand whether it should respond to the request or not. And it can be understood very simply, you can put, for example, put the division by zero srcIP, and then the matter of technology.
Pros and cons of the channel level balancing algorithm.

First of all, it does not depend on the protocols of the upper levels, i.e. You can balance the load on both HTTP and FTP, and SMTP. Then, we reduce costs by eliminating the dedicated balancer, in case we do not use it. Reverse traffic towards the client does not burden the balancer, which is also good, for example, for HTTP, when we have an incoming request, as a rule, is light, and the answer to it sometimes weighs tens and hundreds of times more. Then, in modern realities, a very useful plus for us is that we use only one public address, since public IP now expensive, this is undoubtedly a huge plus for our system. And such a system contributes to the rapid addition of server shutdowns in the cluster.
Of the minuses it is worth mentioning: the need to host the server in one segment, the restriction on the incoming band in the case of shared addresses, because Traffic hits all servers at the same time, loading our system.
Of the solutions that use this balancing algorithm, you can call the Linux Virtual Server.

Balancing at the network level. In principle, the mechanism is quite similar to balancing on the data link layer, with one single difference - in this case, receiving an incoming request, our balancer replaces the destination IP, respectively, applies it to the server that will process the request. The server receives it, processes it and must transfer it back to the balancer so that it performs the reverse substitution.

Advantages of this method: it also does not depend on high-level protocols; full transparency of work for the server, i.e. the server thinks that he receives a request from the client and works directly with him directly, bypassing any balancers, he does not know anything about them; and here, just as in the previous method, we use one public address, which is also a big plus.
Among the shortcomings is the increased load on the balancer due to reverse traffic. Each server must send a response, first of all, to the balancer, so that it performs the reverse substitution. Accordingly, in the case of HTTP, the load on the balancer will also be large.

Balancing at the transport level. Here is a very fine line that distinguishes balancing at the network from balancing at the transport level. Well, for simplicity, we say that in this type of balancing, incoming ports of source and destination are used when load balancing.
A very interesting example of the implementation of this type of balancing is balancing with the help of the so-called. ECMP algorithm, i.e. equal-cost multi-path. It turned out that all modern routers can distribute, balance the load themselves. To do this, it’s enough for us to announce the same subnet via a different route on the router. In this case, the balancer, having two identical routes along its common metrics, will distribute the load equally over them.
But there are a number of nuances that must also be taken into account. First of all, our router must distribute the load in such a way that packets within one TCP session fall on the same server. This time. This mode on routers, in my opinion, on modern Cisco's is called perdestination and perflow and is supported by default.
The next caveat is that if we register static routes on the router, then we must somehow automate the process of adding and removing servers from our cluster. In order to avoid this problem, we can use different routing protocols, such as BGP. Those. on each of our servers, we install some kind of software BGP router, which will announce the server network to the router, which accepts requests. From such software routers can be called Quagga or Bird.
And it is also necessary to take into account that there are pros and cons of this method:

The advantages of such a balancing algorithm at the transport level: it does not depend on high-level protocols, like the three previous methods; also one public address is used; there is no need to purchase additional equipment.
But there are disadvantages, such as, for example, the need to put additional software on the server. As I said earlier, these are BGP software routers, although they do not heavily load our servers. No server-affinity, i.e. all connections will break if we add or remove servers from the cluster. There is also the problem of the limitations of identical routes on different routers. The slide below shows several Cisco brand routers — eight identical routes are supported simultaneously for the first two, and up to 32 identical routes are supported for the latter. We must also ensure uniform load, which imposes certain performance requirements on our servers, for example, if we add a more efficient server to our cluster, then the load on it will be distributed exactly the same as all the others. And the last minus is the BGP protocol timeouts, i.e. if the server stops sending to the router, announce its network, i.e. it has failed, the router can still distribute the load along this route for a certain timeout.

Of the methods of global balancing, the following most common methods can be distinguished:
- DNS level balancing
- application level balancing is proxying and redirect requests,
- balancing at the network level - consider the algorithm Anycast.

In DNS balancing most often used so-called. Round Robin algorithms, i.e. This is the simplest balancing mechanism, and thus any systems can be balanced in which access to the service occurs by name. Its essence is as follows: several A-records are simply added to the DNS server with different IP addresses of all of our servers, and the server itself will issue these addresses in a cyclical manner. Those. The first request will be received by the first server, the second request - by the second server, the third request - by the third server, the fourth request - by the first server, etc.

The advantages of this algorithm: it is completely independent of high-level protocols; It does not depend on server load, due to the fact that all clients mainly have cache DNS servers, which allow compensating this problem in the event of a sharp increase in the load on our service; universality, i.e. DNS balancing can be performed both at the local level within a single data center and globally. The last most important advantage of such a balancing algorithm is a very low cost and quick start, since any site actually has a domain name, has a DNS server, so by adding a few A records you can achieve balancing at the start.
Of the minuses should be called the following. The difficulty of shutting down servers, in the case of, for example, their failure. In this case, it is necessary to provide some ways to back up these servers, for example, using the CARP or VRRP protocol. It is also difficult to distribute the load in the right proportion, because The DNS server knows nothing about how loaded each server is, but only gives out their IP. The limitation of IP addresses is the most significant disadvantage of this balancing algorithm, since Each server must have its own global IP address, and as I said, IP addresses are now expensive and limited. In addition, it is necessary to keep double the reserve of server capacity, in the case when we have one of the servers fails, and the client will break on his IP and will not receive our service.
Of the implementations, you can call any DNS server, for example, the Named server from the BIND package, PowerDNS server, etc.
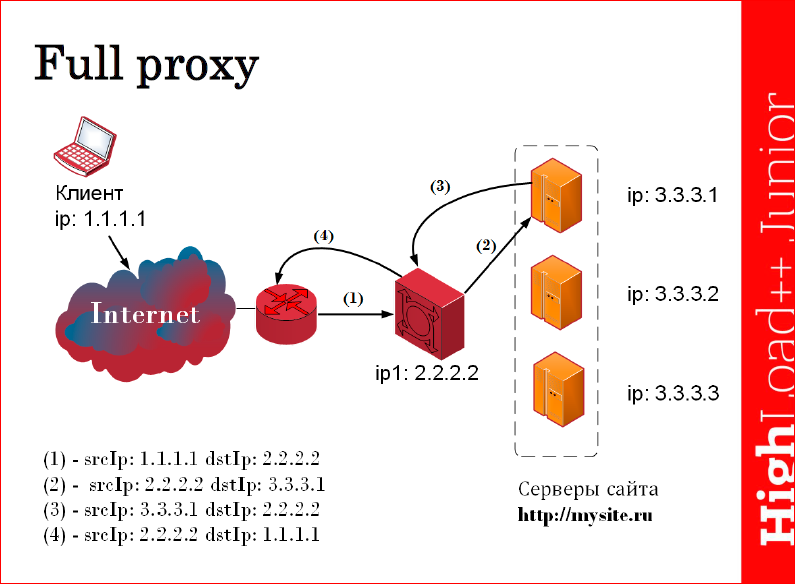
The next algorithm is the proxying algorithm. Its essence lies in the fact that as a balancer, so-called. smart proxy. Those. if the balancer receives a request to our resource, it analyzes the application level headers, accordingly, it can understand the request to which resource came to our balancer, and send a request to one or another server on which this resource is contained. Plus, when this request is received, the balancer can add to the HTTP headers, for example, information about which client the IP came from, so that the server knows where to send it later and with whom it works. After completing the request, the server sends it back to the balancer, it performs the necessary manipulations with the new headers of either the third level or the seventh level and gives it to the client.

The advantages of this balancing algorithm are that we can provide server-affinity, i.e. we can bind a specific client to a specific server, for example, using different cookie settings. Then, we can distribute different types of requests to different servers, i.e. we, for example, can keep statics on one server, which weights a little, and on another server we can hold some heavy content, and, accordingly, understanding the HTTP header, we can send the user's request to one or another server. Thanks to this balancing algorithm, we can also filter requests by URL, thus protecting ourselves from various types of attacks, and independently determine the performance of each node, i.e. not just the availability of each server at the network level, but also to understand how efficient, in this case, our software is on the server, and not to use any additional funds.
Of the minuses:
- the need to balance the load on the balancers themselves;
- this is an additional point of failure of our system;
- consumption of a very large amount of resources, because application level requests are analyzed;
- the need to have your own proxy for each type of protocol.
From implementations, you can call such software web servers as HAProxy or nginx.

Redirect requests. Redirect requests have a rather limited application - it is used mainly for global balancing, and, in particular, for HTTP, it is well applicable. Its essence lies in the fact that we receive a request from the client to our balancer, the balancer responds to it with a redirect to our server, which contains resources. For example, when receiving a request via HTTP, the balancer responds to it in response — it gives an error 302 move temporary indicating the address of the server to which our client will continue to go.

The advantages of such a balancing algorithm are that it distributes the request to different servers by analyzing the application level headers.
Cons - this is a rather small applicability to high-level protocols; an increase in response time due to the appeal to the redirector; in fact, for each client request we have two requests, i.e. The first request goes to the balancer, the second request is made by the client directly to the server. Thus, if, for example, a client requests some content that is cut into pieces, then the client will perform two requests for each piece, which dramatically increases the customer service time.
Solutions include the nginx software web server.

And the last kind of balancing that I wanted to talk about is balancing on the basis of Anycast. This balancing algorithm does not require any customization by the client, and its essence is as follows: we are announcing the same network prefix from different geographic areas. Thus, each client request will be routed to the server closest to it, which will process it.

The advantages of this method are that we provide the minimum delay in processing the request, since the client will be served on the server closest to it, not only from a geographical point of view, but also from a topological one. We ensure the delivery of traffic, bypassing the main communication channels, respectively, we get some cheaper traffic. Another plus is that the network itself distributes the load - we don’t actually participate here and don’t care about it, i.e. This process falls on the shoulders of the ISP. High resiliency of this balancing algorithm, for example, if one of the servers fails, then all requests to it will simply be transferred to the server nearest from it. It’s easy to add and remove any of our servers - just stop announcing BGP, for example, a subnet, and all user requests will be routed to other servers.
From the minuses it should be mentioned that there is a possibility of rebuilding the routes, which is quite critical for a TCP session. For example, if within one session the packets go along a different route to another server, we will simply receive a reset via TCP, and the session will be interrupted. There is no possibility to control from which node the user is serviced, since this is the network itself, we cannot know where the user is currently serviced, without resorting to various additional solutions. Expensive equipment, i.e. if, for example, we use hardware routers, which is quite an expensive thing. Another important point is that when using balancing based on Anycast, it is necessary to take into account the interests of Internet providers. Since we all know that Internet providers love to peering with each other and, therefore, ideally, packages should follow the shortest route, but in fact it turns out that the Internet provider sends packages where it is cheaper for them, and you need to have mind

What balancing algorithms are used? I have already told you about the methods, now I’ll tell you how we choose which server to send requests to. There are several common algorithms that I would like to talk about.
- About Round Robin I told above. Its significant drawback is that the load in this case is distributed without taking into account the specific features of a particular server. The Weighted Round Robin algorithm allows you to hang on each server a certain weighting factor that will take into account the power and performance of a particular server, i.e. a more productive server will receive requests more often.
- The next algorithm is Least Connections, i.e. in this case, not only the load on the server, but also the number of simultaneous connections to this server at the moment will be taken into account. If we want, for example, to improve this algorithm, then we can use the Least Connections algorithm, for example, with weights, i.e. additionally hanging on each server a certain weighting factor in accordance with its performance and power.
- Destination Hash Scheduling and Source Hash Scheduling are so-called. algorithms that analyze the IP address of either the source or the addressee and choose from a certain static table a particular server to which the request will be proxied.
- And the Sticky Sessions algorithm — in this case, the client is bound to a specific server, and, accordingly, all packets in one session will only go to this server.

Then I want to voice a few solutions integrators, because they are often used. We do not use these solutions in our service, so I’ll just call them.Solutions from Cisco are listed here - these are Cisco ACE solutions, a kind of hardware balancer, which theoretically has a capacity of up to 16 Gbit per second and supports almost all of the balancing algorithms and algorithms I mentioned. Cisco also has a solution called Cisco CSS, has gigabit ports, allows balancing traffic at the network level and performing global balancing at the DNS level. From F5, the solution is BigIP, which is quite flexible, has its own scripting language and thanks to it, we can customize the balancing in the way we are more comfortable and how we want it. And the solution from the radware company, it is called Alteon NG - performs and supports almost all the balancing algorithms, allows you to analyze the setting of cookies, bind the client to a specific server and a number of other features. Who caresThat can google and find information, it is available.
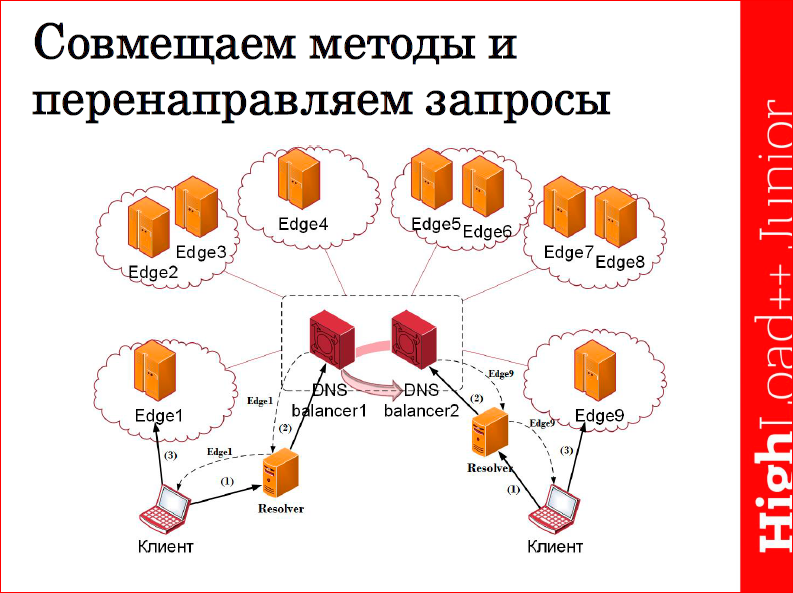
And in conclusion, I would like to talk about how we use various algorithms and methods of balancing, and how they can be combined in every way.
Since we are an SDN provider, we have a network of servers that are geographically distributed, respectively, we need not just load balancing between servers, we also need to redirect all client requests to the server closest to them. How it works?We have several balancers, balancers are a kind of patched DNS server that we issue, just using the usual DNS Round Robin. Having received it at his disposal, the client sends a request to him for receiving an A-record and, accordingly, the address of the server that will process it. Each balancer is aware of the availability of each server in all locations that are geographically distributed, respectively, forms a complex metric that takes into account the load of each server at the moment, the use of CPU resources, memory utilization, server availability from the network point of view, then analyzes the distance from each server to the client, etc. Those.a certain complex metric is calculated, on the basis of which a decision is made about where we should redirect this client's request, and, as a rule, the closest server is selected not only in terms of geography, but also in terms of topology, thus service time of each client is reduced and service is accelerated.

Balancing is easy! Even cats can balance, as we see.
Contacts
» S.zubov@cdnvideo.com
This report is a transcript of one of the best speeches at the training conference for developers of high-load systems HighLoad ++ Junior .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we have begun preparations for the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior . Such reports as this - our main pride!
Source: https://habr.com/ru/post/319262/
All Articles