Mobile OCR. How it all began (part 2)
 In the previous post, we began to tell how OCR technologies “moved” from desktop computers to smartphones — and it all started with the Business Card Reader business card scanning application. But business card scanning is just one scenario where mobile recognition is needed. How other tasks of the users'
In the previous post, we began to tell how OCR technologies “moved” from desktop computers to smartphones — and it all started with the Business Card Reader business card scanning application. But business card scanning is just one scenario where mobile recognition is needed. How other tasks of the users' As we have said, the transfer of recognition technology to smartphones is associated with a bunch of limitations and difficulties. The main thing was and remains the resource intensity of the technology - it is impossible to transfer it to a mobile device as it is. But already in 2007, we had a ready-made toolkit for the ABBYY Mobile OCR Engine developer, which allowed us to digitize an image on a mobile phone and output the result in TXT format without saving the formatting. And for starters, in 2011, we decided to implement small user scenarios in which such “elementary” recognition was quite appropriate.
We wanted to understand what scenarios are in demand, so we released the experimental five Grabber for iOS: PhoneGrabber, MailGrabber, LinkGrabber, StreetGrabber and the well-known TextGrabber . Each application had its own function. For example, PhoneGrabber scanned the phone number from the ad and immediately offered to call, MailGrabber opened the email client and offered to send an email to the recognized address, and so on.
')
This is how PhoneGrabber looked like:

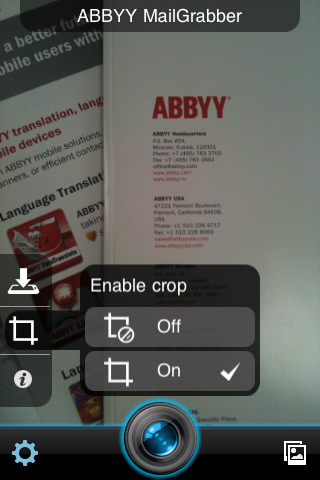
And so - MailGrabber:

TextGrabber was designed to scan small fragments of printed text from various sources (magazines, books, and even signs). The user photographed a passage of interest to him or downloaded the finished image from the photo album, and received text in electronic form at the output, which can be edited, searched on the Internet, shared.
Nostalgic version 1.0:


Suddenly, for us on a still very young TextGrabber, one of the authors of American LifeHacker reviewed, calling the app “The Best Image-to-Text App for iPhone”. The title of this review coincided with one of their popular search queries for which they are looking for such applications. Thanks to this, to this day, 5 years later, users come to the app from the review.
After the release from the reviews in the AppStore, we realized that users lack the ability to translate (for example, a menu in a restaurant abroad or instruction from Chinese-made vehicles). So in 2012, the TextGrabber version was released with integrated full-text translation. The scenario is the same - the text fragment from the image is converted into an electronic form, and then translated into the selected language.
About a year after the launch, they wrote to us from several societies of the visually impaired around the world at once and asked to support Apple’s VoiceOver technology so that blind people could also “read” from any image using a TextGrabber.
As a result, of the entire Grabber-five, the TextGrabber turned out to be the most popular, which currently supports 61 recognition languages, and translates into 104 languages. But other scenarios are not forgotten
At about the same time, we created libraries that could trim the extra background in the photo, remove the trapeze, noise, make the photo contrast. At the end of 2011, we collected these libraries in the ABBYY Mobile Imaging SDK (we wrote about this technology in detail in a blog). At the same time, so-called “mobile scanners” began to appear in the AppStore. Then one of the developers of our team proposed to make a scanner based on the MI SDK. As a result, in 2012 FineScanner iOS entered the market.
The main idea of the application is to make an adequate alternative to the desktop scanner from the iPhone (iPad). FineScanner photographed, cropped and leveled the image, removed creases and shadows, applied filters to optimize the document for viewing or printing, created PDF or JPG files from scans.
The first version of the application was unrecognized. There were questions: “But why is this even necessary if there is a phone camera?”. It was similar to the situation with the Business Card Reader, when everyone around asked why you need to scan a business card, if you can just take a picture of it. We explained that with simple photographing, a lot of “garbage” remains - the edges of the table, the shadow of a hand. FineScanner fixes all this, makes the image bleached, the letters are clear, turns the photo into PDF.
At that time, a great advantage over competitors was the ability to create multipage documents without additional settings. Then, it seems, most mobile scanners had a separate mode, which you need to switch to before shooting several pages at once. FineScanner immediately understood that several pages in one “set” should be combined into a single document.
This is how the first version of FineScanner iOS looked:



Over time, users caught on to what mobile scanning is: they understood that you can create a copy of a passport for a bank, a copy of an accounting contract, a copy of a certificate right on your mobile, and you don’t have to go to a large office copy scanner, and you just need to get your iPhone. But they again asked not just a scanner, but a scanner + OCR.
Since FineScanner was designed to work with entire pages of documents, rather than fragments of text, it was logical to ask for recognition while preserving the formatting. Hence, recognition directly on the device did not fit. We implemented recognition on the FineReader Online server. There was no registration here, we built the subscription-based monetization model that is suitable for mobile users, although in 2014 the auto-renewable subscription was not yet as popular as it is today. In addition, Apple quite tightly regulated the types of services that can use it, and until the last moment we did not know whether the Apple Review Team would approve of such an OCR subscription in FineScanner.
With OCR onboard, FineScanner became a full-featured scanner in a smartphone that can quickly make a copy of a document in PDF or JPG, and then recognize its text in 193 languages and save in 12 popular formats, including Word, Excel, Power Point. At the same time in the document tables, headers, formatting from the original will survive, as if you were working with a traditional scanner and PC. Finished documents can be opened in any application that can work with these formats, transfer to cloud storage, print, send by e-mail.
But the story of FineScanner’s development does not end there. We thought, since we say that FineScanner is an alternative to the desktop scanner, and this is so for ordinary office documents, why not try to twist the technology for scanning books (we knew that about 30% of our users scanned books)? The main problem with books, when you photograph them with a smartphone, and you don’t press them with the lid of a large scanner, these are bends of pages and lines. You have to fotkat each page separately, and not turn immediately, but the pages will still be curved, since when shooting "with hands" it is impossible to press them 100%.
The result of solving this problem was the technology BookScan, the first prototype of which we showed at the Mobile World Congress in February 2015. And in December 2015, the fifth version of FineScanner came out with the scanning mode of books on board.
How it works? When switching to the “Book” mode, FineScanner shows the viewfinder configured to capture the reversal of the book (2 lanes at once). After the photo is taken, the image is sent and processed on the server. The application returns to the user two separate images - the left and right pages with the already cropped and excess background and corrected geometric distortions. About BookScan technology, we wrote separate detailed posts, they can be found here and here .
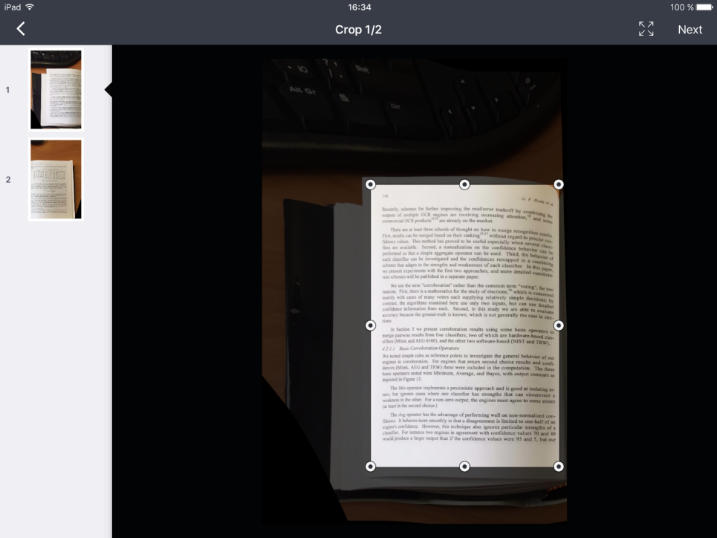
Here is the process of scanning a book:

These are the most important milestones in the development of mobile applications ABBYY until today.
You will surely ask why the “pioneers” always become the iOS versions, because Android is also a very common system? Everything is very simple. In order for the OCR to work well, a camera of at least 3 megapixels is needed. Many Android devices did not meet this requirement for a long time. The models of smartphones and tablets on iOS are no more than two dozen and they have one camera software. There are hundreds of devices on Android, and each manufacturer is trying to improve the camera software at its discretion. It becomes almost impossible to make a scanner that works equally well on all Android devices. With each new firmware, each manufacturer can pop up new bugs. And the fitting process becomes endless.
Therefore, at first we made our applications only under iOS. But when it became clear that Android is occupying an increasing market share in the number of devices on hand, we began to make applications for it. So, TextGrabber for Android saw the light in 2013 (2 years after iOS), and FineScanner more recently - in July 2016.
Of course, we are not going to stop there. We have plans to improve the existing and create a new one. First, the design of all applications will be updated soon - both on iOS and on Android. Here's what the updated FineScanner for iOS looks like.



We are considering how to combine online and offline OCR to speed up the processing of documents. But there are other, interesting plans, until we disclose the details.
In our company, new technologies are constantly being created, for example, for recognizing checks, invoices, passports, and every time we evaluate what appears in our mobile applications. If you have ideas for useful and convenient mobile scanning scripts - write in the comments, we consider any suggestions.
That's all! If you still have any questions about the history of our mobile applications, ask them in the comments.
Source: https://habr.com/ru/post/319242/
All Articles