How to start implementing Hadoop in the company

Alexey Eremihin ( alexxz )
I want to clean up our heads so that people understand what Hadoop is, what products are around Hadoop, and why not only Hadoop, but also the products around it can be used as examples. That is why the theme is “How to start implementing Hadoop in a company?”
The structure of the report is as follows. I will tell:
')
- What tasks I propose to solve with the help of Hadoop at the initial stages,
- what is Hadoop,
- how it is arranged inside
- what is around him
- how Hadoop is applied in Badoo as part of solving problems from the first paragraph.

Data storage. In fact, no one needs to store data, everyone needs to read it, the only question is how long will it take you to read this data if it was recorded a year or two ago. The task of reading data archives. In the next slides I will talk about these tasks in turn.

The first task is the storage of archives. Data needs to be stored for a long time to be able to read them. Need to store a year, two, three. It must be assumed that for a year, two, three iron will fail (the disk may fail, the server), and the data cannot be lost.
Data volumes are growing. Here, following the example of the BI group at Badoo, I know that our data is growing twice every year. This number scares me just to the horror. I know that in a year we will have twice as much data. Accordingly, the storage for this data needs to be scalable, and it must be assumed that it will grow. And a file is assumed as an object containing a unit of information. You can use other methods, but the file is a universal way of storing, processing and transmitting information, it is present in almost all operating systems. That is why the file.
The picture is the archive of the Ministry of Defense. The most important difference between their archives and those archives that we need is that their archives are read by units, and we must read the archives in large quantities, the data must be read.

What do you want to get from the archives reader? So that it allows to read different logs in a unified manner, because logs could be collected at different times, different systems could change historical data, as sent, long and difficult, alters do something ... Since data volumes are large, you need to assume that the data must be read in parallel. If you, for example, read 100 MB of zip, unzip it and pull the data out of it, then it takes you a few seconds, and if you need to unzip several TBs, then you have to parallel it. Either you will parallel yourself, or the environment will do it for you. And if your environment allows you to parallel, that's great.
SQL access. For me, SQL is the most universal language for accessing data and solving various data problems. It is important to understand that SQL is not only a table, it is in general a structure query language and everything that can be described in the form of a table or something similar to a table can be described queries to these objects in the SQL language. This is not something new, so many people think.
The task of reading archives is a task to parallelize, read quickly and be able to quickly process. What does quick processing mean?

For example, to quickly collect some statistics (how much data was there), filter out some user, some session with data, just find the necessary piece in a large archive, make a short excerpt from it ... As a separate subtask - the number of unique events when 10 million users come to you from 10 million unique IPs - you need to be able to do this too, and it would be great if the system could do it, i.e. this is another task - to obtain statistics, when a little such significant data is obtained from a large amount of data.
A separate task is to break by parameters. As a rule, you need to know from which cities the events came, from which countries the events came, it all depends on the system you are designing.

The fourth task is data preparation. It is more tricky, it is also related to processing and reading data, but the main difference from the previous paragraph is that if I offered to retrieve Kbytes of data from a Tbyte of data, then here I propose to get MBs or Gbytes of data from Tbytes of data. Those. you store a lot of data and you need to provide some kind of system that can work on extracts from this data. As an example, the solution of tasks recommendations. You need to see who bought what and with what, and make recommendations for which product you need to recommend other products. Those. you have logs, who bought what, but these same logs are still useless, because you need to make bundles of products. It turns out that in order to link the products to each other, they need to be linked directly through the logs of purchases. The task is reduced to the fact that you need to take a lot of data that is (usually there will still be a Cartesian product of this data for some kind of nonsense - there will be even more data), and then you will do some kind of excerpt that you put in MySQL or PostgreSQL - in general, in any storage that can process well not very large amounts of data, and you will work with them.
Item about ETL is a piece from the world of BI - Extract, Transform, Load. By and large, this is just a transfer of data, when you take data from one place, bring it to the desired form and put it in another database. As a rule, this is a collection from several databases into one, change of formats, some agreements. Again, this task is very good for SQL, but not as a language that returns some data to us, but as a language in which you can create a table as select, and there will already be a lot of data, that is, you create yourself a table.
Actually, here are four tasks: the first is reading data, and three tasks about data processing. I propose to solve these same tasks with the help of Hadoop.
Hadoop is probably not the only offer on the market that allows you to do this, but from open source, which is free and solves all problems, probably the only one.
The conference is called highload, and Hadoop is from the big data world. How does highload compare to big data? By and large, when highload starts writing logs, big data is already needed to process these logs. In general, big data is a very wide area with machine learning, with some semantic analyzes, with a whole bunch. On this occasion, separate conferences are held ... And Hadoop is an indispensable attribute of almost every report in the field of big data.
The Hadoop project started in 2007 as an open source open implementation of the idea proposed by Google back in 2004, called MapReduce. MapReduce is a way to organize algorithms, when you define two small MapReduce procedures for data processing, and these procedures, by and large, run for you, i.e. These are such callbacks that run in a heap of places, parallelized and process a large amount of data. This is a way of organizing algorithms, because MapReduce itself is not an algorithm for sorting, searching, or anything else, it is a way, a pattern for designing algorithms.
As an open implementation of the idea proposed by Google in 2004, Hadoop appears as a MapReduce in 2007, and the project develops, develops, develops, acquires a bunch of projects around itself, strongly and weakly connected, and in particular, the Hadoop core falls , for Hadoop, a distributed HDFS file system is designed and built.

At this point, Hadoop begins to be suitable for solving data storage problems.
HDFS is a distributed file system that allows you to store very, very much data, but not very, very many files. It is assumed that there will be large files in it, and the data will be written there once, i.e. data rewriting is not provided.
The second part of Hadoop was originally called MapReduce - data processing. Now Hadoop has grown, literally a year and a half ago, the code written for MapReduce has broken up into two parts - YARN and MapReduce.
YARN - this is Yet Another Resource Negotiator - this is the kind of thing that is responsible for running tasks on a pile of machines, manages the computing resources of the cluster and simply transfers the tasks for execution. She does not know what tasks she is transmitting, and MapReduce already directly tasks that are being launched.
A little more about HDFS.
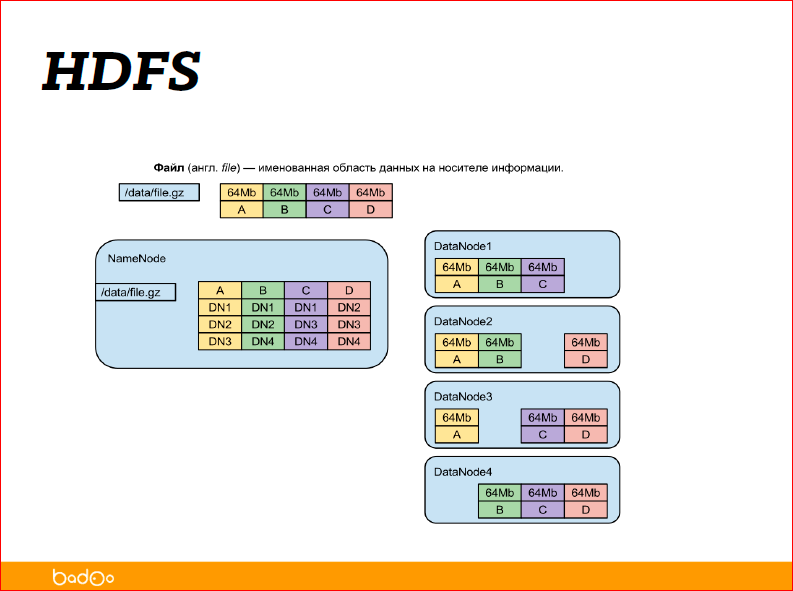
Just a file is a piece of data with a name. This is probably the most accurate definition of the file, and anything can be in the name. If you add slashes, for example, to the file name, you will get directories.
When designing HDFS, they immediately approached the idea that the system should be fault-tolerant, i.e. the data should be stored on different servers, on different disks, the system should be distributed so that it can be easily added, deleted, new servers. The device is very simple, i.e. the file is represented as a name and its contents, the content is divided into a set of blocks (the default is 64 MB, but you can specify your own), and the data is obtained as a list of blocks.
Further, there is the NameNode service, which simply remembers which blocks the file consists of, does not know anything about the blocks themselves, it just remembers that the file is blocks A, B, C and D and knows which DataNode 1.2 is stored on, 3.4 these same blocks are stored.
As you can see in the picture, each block is stored in triplicate - three yellows, three greenbacks, three purple ones. This means that the replication factor is 3 (three). In short, this means that you can lose any two servers, and the data will still be available, and you can restore them and add more copies of the files.
The replication factor in Hadoop, unlike many file systems, is file-based, i.e. You can say that this file is very, very important for me, and I want us to not exactly lose it, and therefore I want its blocks to lie in all servers of the cluster. In this case, you expose the replication factor equal to the number of servers in the cluster, and you get increased disk usage and also increased fault tolerance. And you can say that I have very, very much this data and, in principle, I will lose and lose, the data is not so often lost ... Set the replication factor to 1 (unit). Well, some of the data will be lost, but it seems like you will survive. Again, it depends on your task. Hadoop is not a thing for yourself, it is not a tick to hang, it is a thing that is needed to solve problems.

Those who work in the Linux system, as a rule, do not have problems working with Hadoop, because the commands for working with files are more or less the same. On the slide you see them. There are specific, but also very obvious commands from the series “put the local file system on the remote file system”; "Take data back"; setrep is “set the replication factor” and text is “tell Hadoop that my files are in various zip files, zip them to me, please, and give me just as text, I don’t want to guess what kind of archiver unzip it. ” This is from the command line.
Of course, with direct implementation, i.e. developers and admins work from the command line when working with these hands. As a rule, the work goes through the API. Hadoop is written in Java, so the API is Java, but there is a cool thing called WebHDFS - this is the HTTP Rest API, wrappers, in my opinion, are already for all languages.
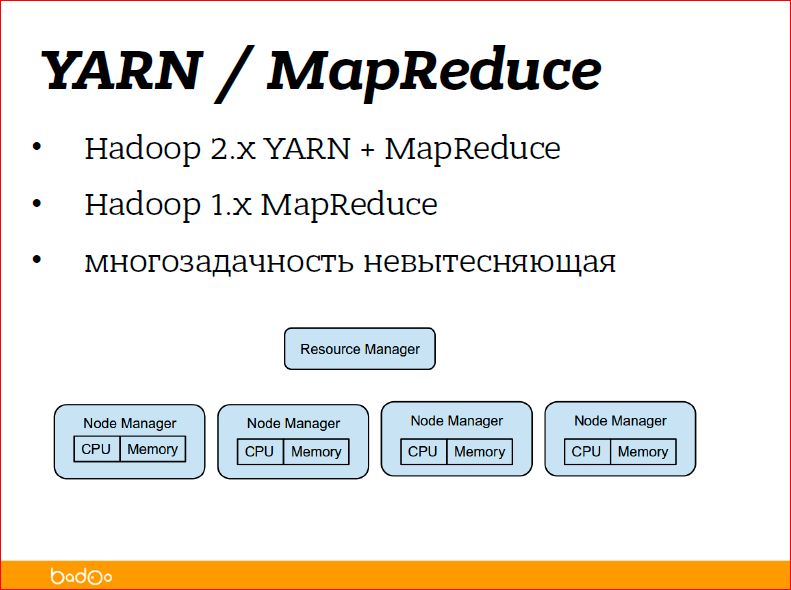
The second part, related to data processing, is the second, third and fourth tasks. As I said before, this is Yet Another Resource Negotiator / MapReduce. The principle of construction is the same as HDFS - there is a master node that drives everyone in a row and there are node managers - these are demons running on each of the servers on which you go to process data, and they just know how many resources are left on this server, and they say, "I still have the resources, maybe I will start something else for you."
To implement this all you do not need to know, just show how it works.
Here ended the center of Hadoop. Those. There is such a thing - Hadoop common is called - this is a distributed file system and the MapReduce framework. The MapReduce framework assumes that you have taken java and started writing to java for this framework and optimizing your tasks. For those who want something else from Hadoop, you should get something else.

One of the old projects, at the same time stable and good, is Hive.
In general, this yellow elephant around Hadoop is all winding, winding, winding in various ways. Hive translated from English is a hive, so the elephant mimicred the bee.
The idea behind Hive was to provide access to files in HDFS in the form of SQL. Those. any more or less structured log can be described in some way, it can be said that this json is there, it can be said that the data are separated by commas, then it turns out commons, Comma Separated Values (CSV), it can be said that there are space separated some ways to structure the data and set names for these pieces of data.
SQL data access is performed primarily by Hive. Other projects are also there, but they are not the only ones. As I have already said, SLQ is convenient both in terms of pulling out sample data, and in terms of collecting some statistics, because you have both count and max, various aggregation functions, grouping, and also SQL in the form create table as select is suitable for data conversion.
As an example, pulled from Hive tutorials, how to parse the apache access log:
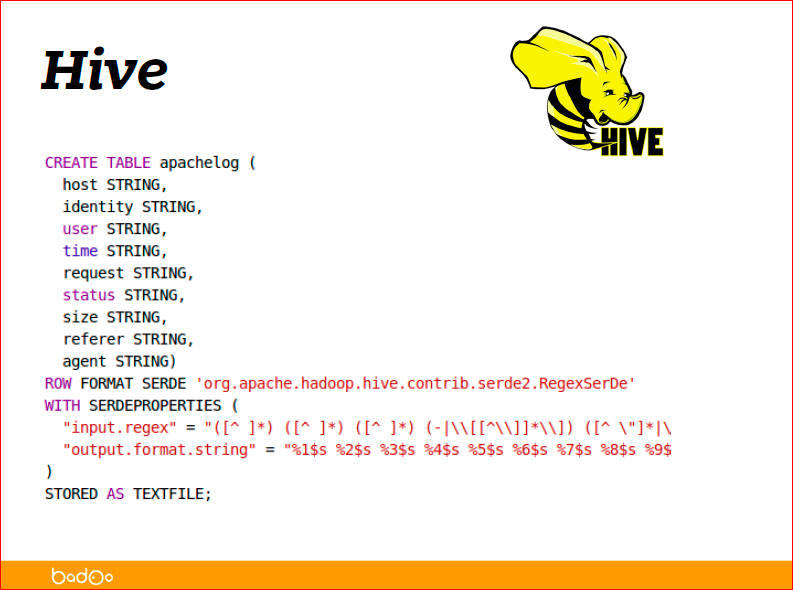
In fact, the format that lies in the apache access log is called the Combined Log Format, and the easiest way for Hive to describe it is in the form of a regular record. You see on the slide below there is a regular. They just described it in a regular way, what you have in the line, and said that in the first part is the host, the second is identity, user, time, what they wrote in the logs, what they described in the regular schedule, that’s what they see.
Regularity is probably the most inefficient way to describe data, because a regular expression will be applied to each line and this is a rather expensive operation, but at the same time one of the most flexible ways to access, to describe data. Actually, the fifth line below describes what exactly the regular schedule will be parsed.
At the end you can see that this is RegexSerDe, SerDe is a serializer-deserializer - this is a java class, which for Hive describes how to parse a string into data, and how to make a string from the data again. By and large, for data access you create a virtual table, say that it lies along some path in HDFS, and you can make a select from this table and get your statistics.
I’ve talked about Hadoop common and Hive now - these are two products. And, in general, there are many different applications and systems around Hadoop:
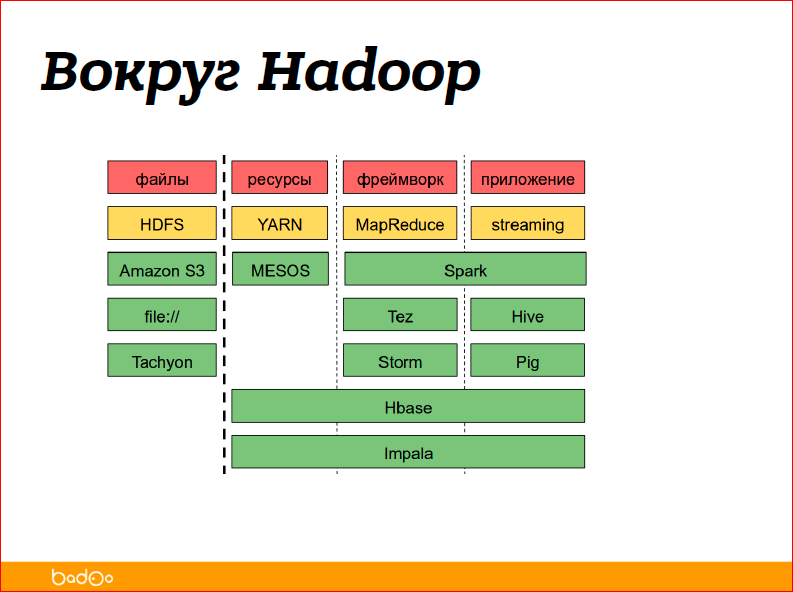
You can try to break them down into data management categories, i.e. these are files, resources — what distributes computing resources, the framework — this is what organizes calculations for you, what your mappers, reduces or other applications run, and, actually, applications — this is when you do not write code as a user, write at least SQL for data processing.
Yellowish is marked by what I told you about - HDFS, YARN, MapReduce, Streaming (I'll tell you about it later). Everything else green is a separate product. Some products provide only the framework, some provide resource management, some are complete, i.e. they are just processing the data. For example, Hbase is a key-value storage that can store its data, its files in HDFS. There are also a lot of file systems; from a funny one, we can say that it is not necessary to store data in HDFS, it can be stored just on disk, just an environment for computing organizations.

Ecosystem. Sometime in Hadoop, someone introduced, used the word "ecosystem", and so they called all the products related to Hadoop. I found a list that lists 150 different products and systems related to Hadoop, among them the data acquisition system, machine learning, and SQL, and NoSQL.
Look for suitable products for your tasks, I do not know what tasks you have, I told you the most basic ones. Someone told me that there is a different classification, there are 300 products around Hadoop. But, as I said, Hadoop is a word that often describes the whole ecosystem, all the products, the whole family.

Now a little about Hadoop in Badoo.
Why do you need these numbers to be useful? The numbers can be useful, from the point of view that Hadoop scales quite linearly. Those. if you assume twice as much data, you simply multiply the numbers by two. If you plan the data volumes in half, divide these numbers by two.
Naturally, all this is related to the tasks, because depending on the tasks that you solve, you will be limited to various things. Someone will rest on the network, someone will rest on the processes, someone will rest on the performance of the disk. Nobody can promise anything. Just count and watch.
The cluster is actually small - 15 servers. In general, everything is written.
Why 2 data preparation servers? Because Badoo is located in two data centers - one is in Prague, the other - in Miami. In each datacenter we prepare the data - this means that we collect from the entire datacenter what we want to put in Hadoop, zip it up and transfer it between the datacenters in archived form.
The amount of data we collect:

In principle, there is one server in each data center, it turns out that 1 Gbps of traffic arrives, i.e. by and large, we will soon begin to rest against the network, we will probably install another server in each data center.
What else is interesting - here are a number of files and blocks. We intentionally make files not very large, because large files in a zipped format are read very poorly.
The average replication factor is 2.75, not 3, because we have a big piece of data that we are not really afraid of losing, but it's just nice to have it and spend 20 TB of storage. You need to save 20 TB, your replication factor is 3, which means you have to prepare 60 TB of disks. If you decide to put the replication factor 2, you immediately have an extra 20 TB of disks - this is delicious. The data is necessarily compressed, because we have the most used, the most problematic thing - this is the amount of data.
This was the first task. Those. This slide is about data storage, how distributed file systems are organized - this is the first task about data storage.

, — . , — Hive, Spark Streaming. - , , -, Hive. , , Hive . SQL, , - , , -, JDBC — .
, RRD, , .. timeseries. - , , , .. , . timeseries. timeseries , - .
, , . , realtime. Realtime Hadoop — , - . realtime.
Spark. Spark - MapReduce, Hadoop . Spark, Hadoop, . SQL , Streaming , Spark'e . , . Streaming — , Hadoop common MapReduce , , . , , , — , , HDFS, , .
MapReduce, , , , MapReduce , .
, , — json, tab separated. .
Tab separated , , , .
Json , , - , , , .

« » — - , , - , Hadoop, -, , Hadoop. , , .
- . , , , , .
Gzip — -, , , , . bzip2 , bzip2 10 , 10 , .. 10% . , gzip bzip — , 1 , , , . , . bzip2, , Hadoop, , .
lzo — , , , bzip, - lzo, bzip. - — . , gzip', , , , , . 150- . , .
- , ? , — . . , , , , , , , , — .
- / . , , , 20150522, .. , . , 22- , 21- — , .
- . , , , .
- , — , . — Hadoop , , , . , , 150 — , 150 .

What not to do. Do not run Hadoop on a weak iron - these are the first three points. You can run it, but you will get a bunch of restrictions, i.e. take and run everything on one server, you will not get any redundancy, normal parallelism, nothing. If you have a small project and you want to install it, Hadoop is not needed for one small project - this is an illusion.
, , , - . 1 — Hadoop , 1 — , Hadoop, - , , . , . , . Those. , .
— . , , Hadoop - . , , Hadoop .
, , 5. , - , , , — , , , , , Hadoop. Hadoop , , . , , Hadoop , Hadoop . Hadoop , , - — .
, , , Hadoop , , , , , .

Hadoop, — , , , . , . , .
— «Hadoop Definitive Guide» — , Hadoop . — «MapReduce Design Patterns» «Hadoop Operations» — , — . , .
Contacts
» alexxz
» a.eremihin@corp.badoo.com
» Badoo
This report is a transcript of one of the best speeches at the training conference for developers of high-load systems HighLoad ++ Junior .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we have begun preparations for the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior . ! .
Source: https://habr.com/ru/post/319138/
All Articles