NoSQL - briefly about the main thing

Sergey Tulentsev (TextMaster)
My name is Sergey Tulentsev, I have been interested in NoSQL databases for several years now and will try to share my knowledge and experience with you.
Who will benefit from this report? This is a review report with a claim to structure. If you have heard about NoSQL somewhere, then in 40 minutes you will know much more, you will be easier to navigate in terms and more confidently choose databases for your project.
')
Let's also talk about typical examples of application and how we should not use NoSQL database.
A bit of history.

The term first appeared in 1998, as the dude named Carlo Strozzi called his relational database. She, however, did not provide a SQL interface for working with herself, but instead represented a set of bash scripts that sausage XML files. If you believe Wikipedia, the latest release of this database was released in 2010, and it somehow worked successfully. I learned about it only in the process of preparing for the report, and I think it’s good that I haven’t learned about it before.
In 2009, other San Francisco dudes organized a conference to discuss the new distributed databases, and they needed a hash tag for Twitter, a succinct short hash tag. Someone came up with a NoSQL hash tag to emphasize that there are databases that have SQL, ACID and all kinds of cool stuff, but we’ll talk about other databases that have nothing to do with it. The people liked the hash tag, it went out of control and still walks on the Internet.
NoSQL term. There are two interpretations: one is old, the other is new. The original one is NoSQL, that is, in general, there is no SQL, but some other mechanism for working with this database. And the newer interpretation is “Not only SQL” - this is not just SQL, i.e. maybe SQL, but there is something besides.
There is such a site http://nosql-database.org - this is a list of different NoSQL databases. Contains a description, type, link to the official project, some brief important things that you should know. You can climb at your leisure to read, but I'll tell you about the most popular ones.
The most popular database classification is by data type.
The important type is the key / value store, or the storage of key-value pairs.

This is the most populous type, and at the same time it is the simplest - it has the most primitive interface of all. And, in theory, the minimum interface for such a database consists of only 3 operations - get, set and delete. Probably, there are some databases that satisfy this interface, but usually modern common databases provide more buns, for example, you can get many keys at a time, set the key lifetime, well, respectively, get the key lifetime, some service commands to check server status ...
A prominent representative of this class is Memcashed. And here it can be attributed with a stretch of Redis. Why with a stretch? Because he actually has his own separate category, in which he has one, this category is called “data structure servers”. It is in this category, because it has several types of keys and a very rich set of commands (150 or more), with which you can create unimaginable things, but if this category is not taken into account, then so it can be attributed here - to key / value . There is Riak.
Document oriented database.

This is a very complicated version of the previous category. This added complexity - it also gives bonuses: now the values are not some kind of opaque text blob, with which nothing can be done, except for what is completely read or deleted, but now you can work more subtly with the value. If we need only a part of the document, we can read it or update only a part.
Usually in databases of this type there is a rich document structure, i.e. tree. If you roughly imagine arbitrary JSON, then any JSON that you can imagine can be written to such a database. And usually advertising, press releases say - take any JSON, put into our database and then you can analyze them. Usually, problems do not arise only with the first item, actually with placing JSON in the database, and then the nuances begin.
Typical representatives - MongoDB, CouchDB, ElasticSearch, etc.
Column Databases.

Their strong point is the ability to store a large amount of data with a large number of attributes. If you have a couple of billions of records, each of which has 300 attributes - this is for you in the column database.
They store data in a slightly different way than, for example, relational databases — relational databases are stored in rows, i.e. all attributes of one line are next. These do the opposite, they keep separate columns.
There is a file - all fields of this column from all 3 billion records are stored in it, everything is stored side by side. Accordingly, another column is stored in a different file. Due to this, they can apply improved compression by using information about the data type of the column. It can also speed up requests if, for example, we need 3 columns out of 300, then we do not need to ship the remaining 297.
Representatives are HBase, Cassandra, Vertica. Vertica, by the way, has a SQL interface, but this is still a column database.
Graph database.
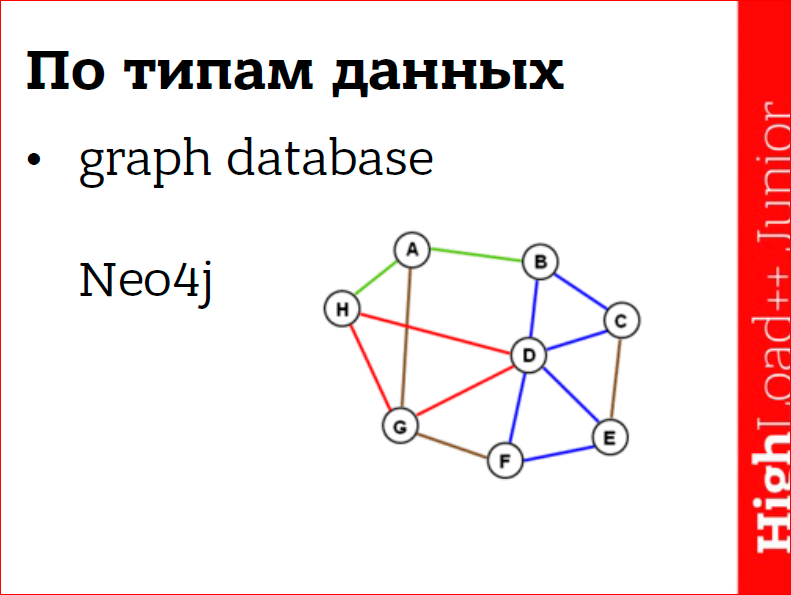
Designed for processing graphs. Just in case, let me remind you that a graph is such a thing from discrete mathematics - a set of vertices connected by edges. If you look at any interesting complex problem, then there is a great chance that we will find a graph there. For example, social networks are one big graph. Road network and routing, product recommendation.
The strength of these databases is that due to their specialization they can effectively perform all operations on graphs, but also because of the same specialization they are not very common.
Still, not every task has a graph, and if it’s there, it’s probably not very large and it’s often cheaper to code on the knee some processing of graphs in the application, rather than dragging a whole new database into the project, behind which need to follow. And the new database delivers a whole bunch of problems. In my practice it was.
Multi-model database.

These are such databases, which simultaneously includes two or more categories from the previous ones.
You want - write documents, you want - columns. FoundationDB, for example, has a main layer - key / value and on top of this layer is somehow attached a SQL layer. I downloaded the distribution kit and subscribed to the newsletter, they sent me e-mails every week, but I didn’t manage to install and run it, to feel how it works. And now it will not succeed, because a couple of months ago, in March, these guys were bought by Apple and immediately removed all references to the distribution jump from the site and now, apparently, this product will not be publicly available. She probably worked well, since they were bought.
There are two more that we have the opportunity to touch until someone has bought them either.
There is also a classification by the method of data storage.

There are databases that do not store data at all, they have everything in memory. Accordingly, any process reboot entails data loss. There are two ways out: either not to store important data there that cannot be recovered, or to aggressively use replication. From unimportant data, this is, for example, a cache, if our cache disappears somewhere, then the application will not fall down, it will slow down until the cache returns, does not warm up, but nothing fatal happens.
Sometimes this mode is used to speed up performance. Take Redis, for example. It can handle tens, hundreds of thousands of operations per second. And some people, of course, use this and load it to the full extent, but if it works in the mode of saving data, i.e. either resets snapshots, or the log writes, then no disk can cope with this, and working with the disk will slow down the server. Therefore, you can apply such a trick - we take a system of three Redis'ov, one master, his two slaves. On the master, we disable all persistence, and it does not touch the disk at all, and we write there, because it is a master. On the first slave, we also disable persistence, and read from it. And at the last slave - nobody touches him, does not read, and on it we include persistence. And he, according to the settings, saves data to disk. In the event of a disaster, it will be a copy of the data from which you can recover.
Redis has two models by which he can save data to disk. First of all, it can save snapshots - this is the current database impression. To make this impression good, Redis forks, creates a copy of his process, so that the impression is not spoiled by the records that occur to the master. And this fork already saves this snapshot, because no one writes to it.
This method is very good, except that it requires additional memory. Depending on the activity that takes place on the server, you may need up to twice the memory reserve. If you have a 2 GB database, then you need to keep another 2 GB free to save snapshots.
You can also configure it to write data to the log - this is a different technique. That is, when a recording team comes to him, he quickly writes it immediately to the log and continues to work, i.e. These 2 modes - snapshot and log - they are independent, but you can configure either one or the other, or both. In general, this log is only added here - this is its plus, and the data that have already been included in the log, they do not change and cannot be broken. Therefore, usually people put this log on a separate disk with a separate head, and on this disk no one, except Redis, does anything and does not touch the disk head. And this head always points to the end of the file. And the recording of new operations to the end of the file is much faster than if it happened on a regular system where other activity occurs.
Other databases, for example, MongoDB, - they have a different model, called in-place updates. They have one copy of the database, data files, and they directly “live” change them. This is not a very safe practice, and if during the change, for example, the power is turned off, then you have a database of scrapbooking and you are guilty. Therefore, several versions ago, they added logging - this is how they call the control log, and even made it enabled by default. Therefore, now Mongo can be run without two replicas, and there will be a chance that it will not spoil your data.
Speaking about NoSQL, it is impossible to mention the CAP-theorem, it’s like 2 boots - a pair.

The theorem was formulated in the year 2001, and some believe that it has lost its relevance and should not be talked about at all, but worth mentioning. It sounds like this: a distributed system can not simultaneously have more than two of the following three characteristics - it is availability (availability), consistency (consistency) and resistance to network discontinuities (partition tolerance).
In fact, we have only two choices - either availability or consistency, because we have partition tolerance everywhere by default. I am not aware of systems that could not survive a network break, which would destroy themselves if the network was broken.
Accessibility is if we have a distributed system, and we apply to any of its nodes and are guaranteed to receive a response. If we request some data, we may get outdated versions of this data, but we will get the data, not the error, or we might not reach this server. If we received the data, then the system is available.
In contrast, the system can be reconciled. What does consistency mean? If we have recorded some data on one node and after some time on another node, we are trying to read this data, if the system is consistent, we will receive a new version of the data, which we have recorded elsewhere.
Accordingly, distributed systems like to refer themselves to one of two camps, either on an AP or on a CP.

In fact, there is a third secret class - it's just P, but no database vendor likes to admit that his system is like that, and not of these two. That is, if it is simply P, it has neither accessibility nor consistency.
Accordingly, if the system calls itself CP (i.e. consistency and partition tolerance), then when it breaks (if we have a cluster and it is spaced, for example, by two data centers, and the connection is broken between data centers), a consistent system? It, if we turn to the node, and the node sees that it cannot reliably provide this record, that it does not have, for example, communication with the majority of system nodes, it will simply refuse the application in this record and it will not succeed. When the connection is then restored, the application can try again and it can work.
And if the system calls itself an AP, then it will do its utmost to satisfy the application’s requests by returning outdated data to it, it can accept the write request and write it down somewhere, so that it can be executed on the entire cluster. There are nuances here. For example, if we have divided the cluster in two, and we write in both parts, then there is a chance that we will get conflicts, i.e. we in one part wrote some data into one key, and others in the other, and when the connection is restored, the problem arises - which version of the data is correct?
Especially for AP systems, the term “Eventual consistency” was invented, roughly translated into Russian, which means if there were no conflicting entries, then sometime later the cluster will come to a consistent state, without any guarantees for specific intervals - sometime .
But in real life one does not have to rely on the absence of conflicts and we need to think in advance how we will deal with them.
The easiest option, if we have 2 conflicting entries, is to resolve the conflict in time, roughly speaking, the last entry made after all wins.
Some more systems blame the whole thing on applications. When an application tries to read data, and the database sees that there are conflicts, it returns to the application all conflicting versions, and the application itself, guided by its logic, will have to select the correct version and give it to the database.
A smarter approach is to use data types in which the occurrence of conflicts, if not impossible, is very difficult. For example, the data type is set. If we have broken clusters, and in one half we add member A to the set, and add B and C in the other half. When the connection is restored, we can easily keep these records together, we simply combine these sets, and we get one resulting set (A, B and C).
Another example is counters. We can independently increment the counters, and when the connection is restored, we simply add them up and get the resulting counter. The Riak database has a special term - CRDT - it stands for conflict-free replicating data types. By abbreviation can google, if interested.
Let's talk about using NoSQL. When should I use?
- If you need high scalability.
This is one of the most important, if not the most important reason for using this type of database, because at the expense of its reduced complexity, it is easier to scale. Previously, the main scaling of the application fell on the application, for example, we have 20 memokashy, and the application collects them into one hashring to ensure reliability and scalability, then modern databases do everything for you, in some you do not even need to configure anything. Just run the node, it finds the cluster itself, enters into it, downloads a part of the data and begins to give up some of the data. Thus, we achieve the desired linear scalability - this is also one of the holy grails of the NoSQL world.
Linear scalability is when, by increasing cluster resources, we obtain a proportional increase in cluster characteristics. Doubled the number of servers - got twice the performance. If we scale linearly - we are very cool. - Prototyping is also an important point.
Traditionally, relational databases require a certain amount of maintenance, both before and during the project. Those. Before the start of the project, it is desirable for us to think over the database schema, create it, run the database with it, and then when the project is up and running, new business requirements may come, or we will find that we were somehow wrong, we need to add a column ... Often this is a blocking operation. What does this mean? We either need to put the application, i.e. turning it off for a minute, a few days, depends on the complexity of the situation, or manually conduct the process of updating the scheme. Those. we roll the circuit onto the slave, upgrade it to the master, switch all the other slaves to it and in turn roll it over the circuit too. And before that, you should not forget to roll out the code that can simultaneously work with the new and old versions of the database so that errors from the application do not fly. This is all done, but it is a confusion. Why do when you can not do? Therefore, schemaless databases, document orientation especially, they attract by this, that you can simply start using a new data scheme, and it will simply appear in your file data. , , . , , . MongoDB , Postgres . - — .
: , , , - , , , . - .
, , . Mongo , .. , , 20- join', Mongo, Mongo. Profit. - — .
, , . , , Redis. . Redis' , 10 , , . - — .
, e-mail. . , e-mail. , , e-mail' . , - worker e-mail. - .
, — , , . facebook, , , . , Amazon S3 . Riak' Mongo .
. , Riak' — 2-3- , Mongo — 16 , , 16 . - .
- Redis, Riak Casandra . - — « ».
, , ? , , , SELECT COUNT(DISTINCT) — . , -, - , Hadoop Hadoop' .
— . . — HyperLogLog. , . Salvatore ( Redis'), . , , , , 12 , 0,8%. — , .. 2 7 — 12 . , . ( ). - Another example is the content management system.
For document databases. You can take an article with content, with checkboxes and settings, and write it down, and use it. - Full text search.
In some relational databases it is built in and it can satisfy basic needs, but if you need something more, then you need to take Sphinx or ElasticSearch.
How not to use NoSQL database?
- .
, , . , : « » « , », .. , - . , , . Hacker News Redis', , , , - . - , « MongoDB» — Sarah Mei.
MongoDB — . , — , — , — , , , — ! , , , . — , , , , — , 5 — .
, , , , . ID', ID' . , . - Embedding — .

— . , e-mail, , . — … — .
, , , , ( ) — , 10 . 5 .
TextMaster' . , — , — . , .. . . .
2 , , , . , .. , . Those. Embedding' . - Embedding- — Embedding.
1- — MongoDB — - . , , Mongo , , , « «ruby»», ««ruby» «nosql»» ««ruby», «nosql»» — . , , — , . -, 2- , ID' , , .
, , .. . ID' , .. . - .
« JSON, ». — . , , , . - .
Stack Overflow ( ) « 5- , ?». . , « ?». Those. , , - , . , MongoDB — — , . - .
To summarize

It is very useful to know your subject area and try to anticipate future queries that may arise. In the example of the series, for the customer - it was obvious that there is value in being able to see the actor's filmography. If the developers saw this, too, then the story would have been different. It is useful to follow the news in the world of databases. Technology develops very quickly, and in just a few days there may be some thing that will seriously facilitate your life. In my case - it was the algorithm for counting unique characters. And you shouldn’t trust too much press releases and advertising - everything is perfect everywhere, you have to look at the flaws, options are possible, someone is looking for negative feedback on the forums, someone is reading the code, someone is waiting for the 3rd service pack ' a. The main thing is to choose a database, based not only on the merits,but also of the disadvantages.
Contacts
" Sergei.tulentsev@gmail.com
" tech.tulentsev.com
This report is a transcript of one of the best speeches at the training conference for developers of high-load systems HighLoad ++ Junior .
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Well, the main news is that we have begun preparations for the spring festival " Russian Internet Technologies ", which includes eight conferences, including HighLoad ++ Junior . Are we going to talk about NoSQL this year ? For sure!
Source: https://habr.com/ru/post/319052/
All Articles