Comparison of lock-free algorithms - CAS and FAA on the example of JDK 7 and 8
Many cores do not happen
Atomic operations (atomics), for example, Compare-and-Swap (CAS) or Fetch-and-Add (FAA) are widely distributed in parallel programming.
Multi- or multi-core architectures are installed equally in desktop and server products, as well as in large data centers and supercomputers. Examples of designs include the Intel Xeon Phi with 61 cores on a chip that is installed in the Tianhe-2, or the AMD Bulldozer with 32 cores on a node deployed in the Cray XE6. In addition, the number of cores on a crystal is steadily growing and processors with hundreds of cores are projected to be manufactured in the foreseeable future. A common feature of all these architectures is the growing complexity of memory subsystems, characterized by several levels of cache memory with different enablement policies, different cache coherence protocols, and different network topologies on a chip, connecting cores and cache memory.
Virtually all such architectures provide atomic operations that have numerous applications in parallel code. Many of them (for example, Test-and-Set ) can be used to implement locks and other synchronization mechanisms. Others, such as Fetch-and-Add and Compare-and-Swap, allow you to build different lock-free and wait-free algorithms and data structures that have stronger guarantees of progress than blocking based on code. Despite their importance and widespread use, the implementation of atomic operations has not been fully analyzed until now. For example, in the general opinion, Compare-and-Swap is slower than Fetch-and-Add . However, this only shows that the Compare-and-Swap semantics introduce the concept of “wasted work”, as a result, the performance of some code is lower.
Compare-and-Swap
Recall what CAS is (in Intel processors it is implemented by the cmpxchg command group) - The CAS operation includes 3 operand objects: the address of the memory cell ( V ), the expected old value ( A ), and the new value ( B ). The processor atomically updates the address of the cell ( V ), if the value in the memory cell coincides with the old expected value ( A ), otherwise the change will not be fixed. In any case, the value that precedes the request time will be displayed. Some variants of the CAS method simply indicate whether the operation was successful, instead of displaying the actual value itself. In fact, the CAS only states: “Probably, the value at address V is A ; if this is the case, put B there , otherwise do not do it, but be sure to tell me which value is the current value. ”
')
The most natural way to use CAS for synchronization is to read the value of A with the value of the address V , do a multi-step calculation to get the new value of B , and then use the CAS method to replace the value of the parameter V from the old, A , to the new, B. CAS will perform the task if V has not changed during this time. What actually is observed in JDK 7:
public final int incrementAndGet() { for (;;) { int current = get(); int next = current + 1; if (compareAndSet(current, next)) return next; } } public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); } Where the method itself - unsafe.compareAndSwapInt is native, runs on a processor atomically and in an assembler looks like this, if you include a printout of the assembler code:
lock cmpxchg [esi+0xC], ecx The instruction is performed as follows: the value from the memory area indicated by the first operand is read and the bus lock after reading is not released. Then, the value at the memory address is compared with the eax register, where the expected old value is stored, and if they were equal, the processor writes the value of the second operand (ecx register) to the memory area specified by the first operand. When the recording is completed, the bus lock is released. Features x86 in this, that the recording occurs in any case, with the small exception that if the values were not equal, then the value that was obtained at the reading stage from the same memory area is entered into the memory area.
Thus, we get a work in the loop with a variable check, which can fail and all the work in the loop must be restarted before the check.
Fetch-and-add
Fetch-and-Add is simpler and does not contain any cycles (in the Intel architecture, performed by the xadd command group). It also includes 2 operand objects: the address of the memory cell ( V ) and the value ( S ) by which the old value stored at the memory address ( V ) should be increased. For example, the FAA can be described as follows: get the value located at the specified address ( V ) and save it temporarily. Then, in the specified address ( V ), enter the previously stored value, incremented by the value, which is 2 operand object ( S ). Moreover, all the above operations are performed atomically and implemented at the hardware level.
In JDK 8, the code looks like this:
public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1; } public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; } “Noo,” you say, “how does this implementation differ from version 7?”
There is approximately the same cycle and everything is done in a similar way. However, the code that you see and is written in Java is not executed in the end on the processor. The code that is associated with the cycle and the installation of a new value is eventually replaced with a single assembler operation:
lock xadd [esi+0xC], eax Where, respectively, in the eax register is stored the value by which you will need to increase the old value stored at [esi + 0xC]. I repeat, everything is done atomically. But this trick will work if you have version 8 of the JDK, otherwise the usual CAS will be executed.
What else would I like to add ...
I want to note here that the MESI protocol is mentioned here, which can be read in a very good series of articles: Lock-free data structures. The basics: where did the memory barriers go from ?
Thanks kmu1990 for clarifying the translation from English.
- CAS is an “optimistic” algorithm and allows for non-execution of the operation, while the FAA does not. The FAA does not have a clear loophole in the form of vulnerability due to remote intervention, therefore, there is no need for a cycle to retry.
- If you use the standard CAS approach, assuming that your system uses the most popular implementation of coherence via snoop-base or “eavesdropping,” this can trigger a read-to-share transaction to get the main cache line or the state E. CAS operation, in essence, puts the cache line in the state M (Modified), which may require an additional transaction. Thus, in the worst case, the standard CAS approach may subject the bus to two transactions, but the Fetch-And-Add implementation will seek to send the line directly to the M state. In the process, you could speculate on values and get a shortcut without preloads, as it tries to get a “bare” CAS. In addition, it is possible with complex implementations of the processor to perform consistent operations and target line research in the M state. Finally, in some cases, you can successfully insert a prefetch-write instruction (PREFETCHW) before performing operations to avoid an update transaction. But this approach should be applied with special attention, as in some cases it may do more harm than good. Given all this, the FAA, where possible, has an advantage. In other words (thanks for the jcmvbkbc hint) - in order to make CAS you need to load the old value from memory, which gives two memory accesses, but to make xadd the old value you don’t need to load, and memory access needs only one.
- Suppose you are trying to increase a variable (for example, increment) using a CAS loop. When CAS begins to stray quite often, you can find that the branch to exit the cycle (usually occurs with no or light load) begins to predict erroneous paths that predict us that we will stay in the loop. Therefore, when the CAS ultimately reaches the goal, you catch a branch mispredict (erroneous branch assumption) when you try to exit the loop. This can be painful on processors with a deep pipeline and lead to a whole heap of out-of-order (extraordinary executions) machine specs. As a rule, you do not want this piece of code to lead to a loss of speed. In connection with the above, when CAS begins to often fail, the branch begins to predict that the control remains in the loop and, in turn, the loop runs faster due to successful prediction. As a rule, we want some back-off in a loop. And with a light load with infrequent failures, the branch mispredict serves as a potential implicit back-off. But with a higher load, we lose the advantage of the back-off resulting from branch mispredict. The FAA has no cycles and no problems.
Tests
And finally, I wrote a simple test that illustrates the work of atomic incrementing in JDK 7 and 8:
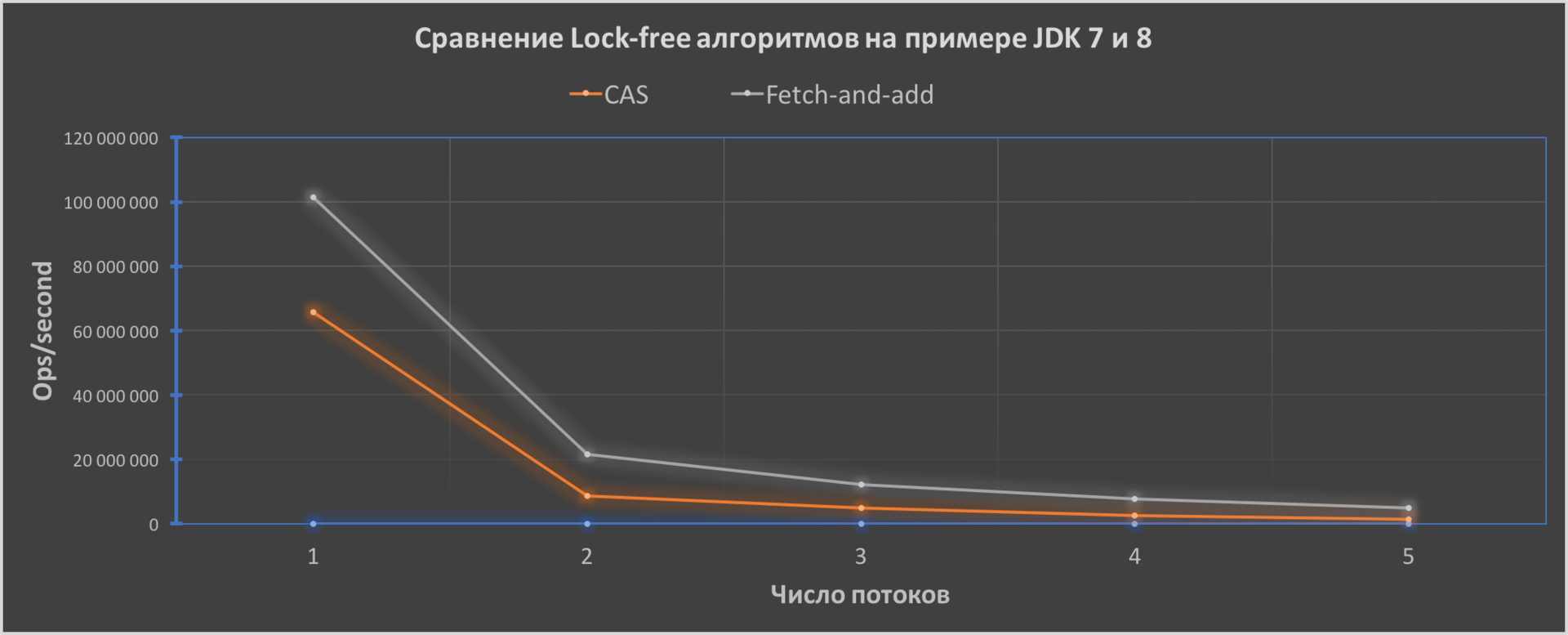
As we can see, the FAA code performance will be better and its efficiency will increase with an increase in the number of threads from 1.6 times to approximately 3.4 times.

Java versions for tests: Oracle JDK7u80 and JDK8u111 - 64-Bit Server VM. CPU - Broadwell generation Intel Core i5-5250U, OS - macOS Sierra 10.12.2, RAM - 8-Gb.
Well, if you're interested, the link to the test code is the test source .
Waiting for comments, improvements and more.
Source: https://habr.com/ru/post/319036/
All Articles