Cdr. Save and Grow

Very often, creating a CDR database is given little space in the setup descriptions. As a rule, it all comes down to quoting SQL commands and promising that if you throw it into the console, then “everything will be OK”.
For example, the very first link in Google recommends creating a label like this:
CREATE TABLE `cdr` ( `calldate` datetime NOT NULL default '0000-00-00 00:00:00', `clid` varchar(80) NOT NULL default '', `src` varchar(80) NOT NULL default '', `dst` varchar(80) NOT NULL default '', `dcontext` varchar(80) NOT NULL default '', `channel` varchar(80) NOT NULL default '', `dstchannel` varchar(80) NOT NULL default '', `lastapp` varchar(80) NOT NULL default '', `lastdata` varchar(80) NOT NULL default '', `duration` int(11) NOT NULL default '0', `billsec` int(11) NOT NULL default '0', `disposition` varchar(45) NOT NULL default '', `amaflags` int(11) NOT NULL default '0', `accountcode` varchar(20) NOT NULL default '', `userfield` varchar(255) NOT NULL default '' ); ALTER TABLE `cdr` ADD INDEX ( `calldate` ); ALTER TABLE `cdr` ADD INDEX ( `dst` ); ALTER TABLE `cdr` ADD INDEX ( `accountcode` ); You can immediately note that at least two indices in the database are useless. This is calldate and accountcode. The first one is due to the fact that with the addition of records every second, the size of the index will be equal to the number of records in the database itself. Yes, this index is sorted, and you can apply some ways to speed up the search, but will it be effective? The second index (accountcode) is almost never used by anyone. As an experimental base - base with 80 million records.
Run the query:
')
SELECT * FROM CDR WHERE src=***** AND calldate>'2016-06-21' AND calldate<'2016-06-22'; /* Affected rows: 0 : 4 : 0 1 query: 00:09:36 */ Almost 10 minutes of waiting.
In other words, creating reports becomes a problem. Of course, the tablet can be ratiated, but why such sacrifices, if it is enough to optimize.
Attention! Never do it in production! Only on a copy of the base! The database is locked for a while from 1 hour to several hours and data may be lost upon abnormal termination!
So, two steps to the success of efficient CDR storage:
- Split into partitions to speed up the sample by period
- Efficient indexing
Step 0. Select storage engine
Actually there are two common options - MyISAM and INNODB. Holivarit on this topic can be infinitely long, but a comparison of engines on a real base gave an advantage in favor of MyISAM.
There are several reasons for this:
- With a clean server setup by an inexperienced admin, MyISAM works more correctly when indexing large volumes. While INNODB requires tuning. Otherwise, you can see interesting errors that the index can not be rebuilt.
- MyISAM with the inclusion of the option FIXED ROW acquires additional properties, namely:
- Resilience even when server crashes
- The ability to read a file directly from an external application, bypassing the MySQL server, which is useful
- Speed of access to random lines is higher, due to the fact that all lines have the same length
In other words, MyISAM is the best for logging (IMHO).
Let's stop on it.
Step 1. Partitions.
In view of the fact that we either supplement the base or read from it, we can effectively divide the base into files once and for all, in order to reduce the possible number of hits when reading certain time intervals. Naturally, you need to break the base on some key. But for what? Definitely, it should be time, but is it effective to beat the base by calldate? I think not, therefore we introduce an additional field, which we also need in the next step. Namely - the date. Just a date, without time.
Enter an additional date field, and make a very simple trigger on the tablet, before update cdr:
BEGIN SET new.date=DATE(new.calldate); END Thus, in this field we get only the date. And immediately break the plate into partitions by year:
ALTER TABLE cdr PARTITION BY RANGE (YEAR(date)) (PARTITION old VALUES LESS THAN (2015) ENGINE = MyISAM, PARTITION p2015 VALUES LESS THAN (2016) ENGINE = MyISAM, PARTITION p2016 VALUES LESS THAN (2017) ENGINE = MyISAM, PARTITION p2018 VALUES LESS THAN (2018) ENGINE = MyISAM, PARTITION p2019 VALUES LESS THAN (2019) ENGINE = MyISAM, PARTITION p2020 VALUES LESS THAN (2020) ENGINE = MyISAM, PARTITION p2021 VALUES LESS THAN (2021) ENGINE = MyISAM, PARTITION p2022 VALUES LESS THAN (2022) ENGINE = MyISAM, PARTITION p2023 VALUES LESS THAN (2023) ENGINE = MyISAM, PARTITION pMAXVALUE VALUES LESS THAN MAXVALUE ENGINE = MyISAM) Done, now if we do the sampling with the indication of the date range, then MySQL will not have to shovel the entire database for all the years. A small plus sign is already there.
Step 2. Index the base.
Actually, this is the most important step. Experiments show that in 90% of cases there is a need for indexes on 3 columns (as needed):
- date
- src
- dst
date
MySQL can only use one index at a time, so some administrators are trying to create composite indexes. Their effect is not very high, because, as a rule, you have to choose ranges, and in this case composite indexes are ignored by MySQL, i.e. FullScan happens. We can not correct the whining behavior, but we can make it so that the number of lines for scanning is minimal and give the engine a choice of which index to use. On the one hand, we need maximum detail of the index, on the other hand, we need to spend as few operations as possible to get the range that we will iterate. That is why I recommend using the index on the date field, rather than calldate. The number of elements in the index will be equal to the number of days since the beginning of the database, which will allow the database to quickly move to the right lines.
There is another way to help the database - to make it so that it can calculate the position of the line in the file even BEFORE opening the file. For this you can use FIXED ROW. The position of the line in the file will be calculated by multiplying the line number by the length of the line, and not by enumeration. Naturally, that approach has victims - the base will take up much more disk space. Here for example:

The size of the base has grown from 18 GB to 53.8 GB. Do or not - the choice of each admin, but if space on the server allows, then this will be another plus.
src, dst
There is a little less room for optimization. More precisely, one thing:
If you do not use text numbers, for example in softphones, then these fields can be converted to BigInt, which will also have a very good effect on indexing and sampling. But if you, like us, use text numbers, then this optimization is not for you and you will have to accept lower productivity.
As a cherry on the cake - we clean up those fields that do not interest us and set the size of the fields in the expected for our case. I did it like this:
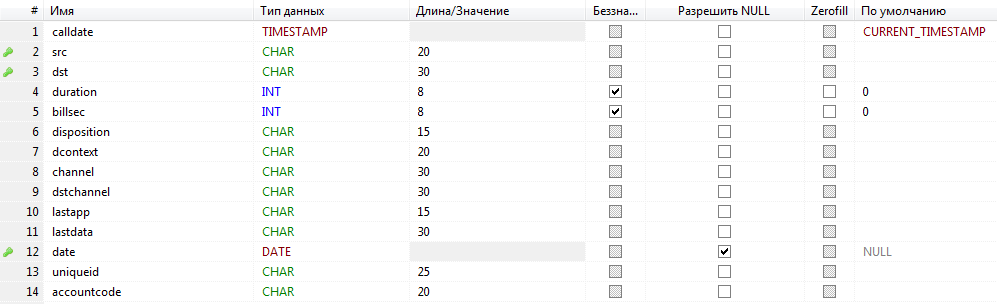
Well, the final query:
SELECT * FROM CDR WHERE src=***** AND date='2016-06-21'; /* Affected rows: 0 : 4 : 0 1 query: 0,577 sec. */ Increase by two orders of magnitude.
For example, by range:
SELECT * FROM CDR WHERE src=***** AND date>'2016-09-01' AND date<'2016-09-05'; /* Affected rows: 0 : 1 : 0 1 query: 3,900 sec. */ Source: https://habr.com/ru/post/318770/
All Articles