As my fingers turned out, and I collected a bike for deployment, which saved more than 2 thousand working hours per project.
"Denis, you are now a deployment engineer." To go nuts, give two. In general, I work at CROC, which is famous for its huge projects. In this project, we supported the introduction of a giant analytical system of the data lake class for several thousand users with a volume of 150 TB. Several development teams are sawing it, for a total of about 40 people.
They have four infrastructure engineers (Ops, admins, that is, us) - we most often needed to install software on the stands, reboot the machines (the developer’s first hope: does not work - ask the engineer to reboot), roll out the database schemas and etc.

')
Developers write code that merges into the repository. From it, Jenkins gives birth to assemblies that he puts on the ball. Deploying the system from scratch for the first time took me 4 hours and 15 minutes on a timer. For each of the order of ten components (scripts of different databases, Tomcat applications, etc.) in the right order, you had to take a file from the balls, figure out where and how many copies you need to deploy, correct the settings, indicate where to look other components of the system, associate all with all and do not confuse anything.
Fingers blew out - started scripting. It began with one small script.
The system consists of a rather large number of components: 6 different applications on Tomkat, each of which is in several instances on different servers, DSE = Cassandra + Solr + Spark cluster, scripts for creating objects in them, loading initial data, migrating Oracle schemas, PostgreSQL, cluster RabbitMQ, load balancers, a bunch of external systems, and so on.
Stands also mainly consist of several different servers. Applications on all stands are distributed differently (for example, somewhere one of Tomkat's applications is deployed in a single version, and somewhere in several it hides behind the balancer, somewhere a copy of Orakla, somewhere several, etc. .).
Total, deploy such a system - many servers and many components with different and frequently changing configs, in which they want to have information about each other, the location of databases, external systems, etc., etc. Thus, deploy everything where it is necessary, not to forget anything, not to confuse and properly configure - the task is not quite trivial. There are many places to make a mistake, and the process requires attention and concentration. First, I scripted the small parts that caused the most problems. The free time was spent on the next moments of malice, union and generalization.
The result was that one shell script was ready for each piece of the system, which did everything from copying the distribution from jenkins to editing configs and deploying the application or executing the processed scripts on the database. In general, everything began like a classic admin's bike: the same scripts that write almost everything for themselves from bricks. The difference is that we decided to make these parts interchangeable and immediately (well, in a month, not immediately) thought about the structure. As a result, it first became a system of scripts, where everything is quite flexible (outside), and then the web GUI also appeared.
I have already prepared scripts for each stand and for each component of the system that perform the necessary actions. But new stands appeared, the existing ones changed, the development of the system moved by leaps and bounds, and it was more and more difficult to reflect all the changes in the scripts.
Then I described the structure of the stand and all the parts changing from the stand to the stand in the configuration files, and the scripts summarized it so that they ate the name of the stand for work, found its config and from there received the necessary information for work.
That is, now the same scripts worked on all stands, the features of which were moved to the config. So reacting to changes has become quite simple.

The config is just a scary text file, which contains a list of variables and their, actually, values. The scripts simply source this file and get all the settings in the environment variables (in fact, it has now become a bit more complicated, but just a little).
To make it even more convenient to manage the configs of the stands, I later added inclusions - bundles of logically related settings, recorded in separate files, which can be connected in bulk to configs or other inclusions. For example, the settings associated with AD are recorded in 5 different variables, and there are only two AD servers, for each of them there is an incLog with these 5 settings. To quickly switch stands, it is enough to connect the required connection between them. In order to reflect any change that occurred on the server, it is necessary to correct the settings in one file, and all stands aimed at it will know about it.
This structure of scripts was overgrown with whistlers, but mostly remained.

Actions are usually performed by a bundle - the sequence of actions makes sense, for example: on a test stand, save the NSI, recreate the circuit in Orakle, load the NSI back. If the previous component fell off with an error, probably the need for the next has disappeared. To make it more convenient, the launch script is made:
The run.sh script leaves to re-create the circuit with the preservation of the master data on the test bench, and the engineer - to drink tea.
It seemed that the engineer in the process of deploying the system is needed only to translate words from the human (“turn me first, second and compote”) into the names of the scripts in the sequence.
The team does not like the unix console, so the idea to run scripts without engineers was skeptical. But laziness pushed to make another attempt - made a page from the cgi script on Python, on which in a simple way you could select a config from the list and stick a sequence of components with the mouse. Roughly speaking, just a graphic button that can be pressed instead of a console command. She began to use.
The idea took root, other routine engineering actions were added, restarting individual components and servers as a whole, unloading-loading-saving information from different databases, balancing control, turning on “ballet” for the time of downtime, etc. The code name “ Button".
This creation of my crooked hands has been redone slightly, now it works on python + flask and can do everything without reloading the page: update the list of stands and their status, update the tails of logs, launch components and target them if they fake.
A colleague Andrew applied designer magic and made a beautifully designed page from the mash of my black and white divs.
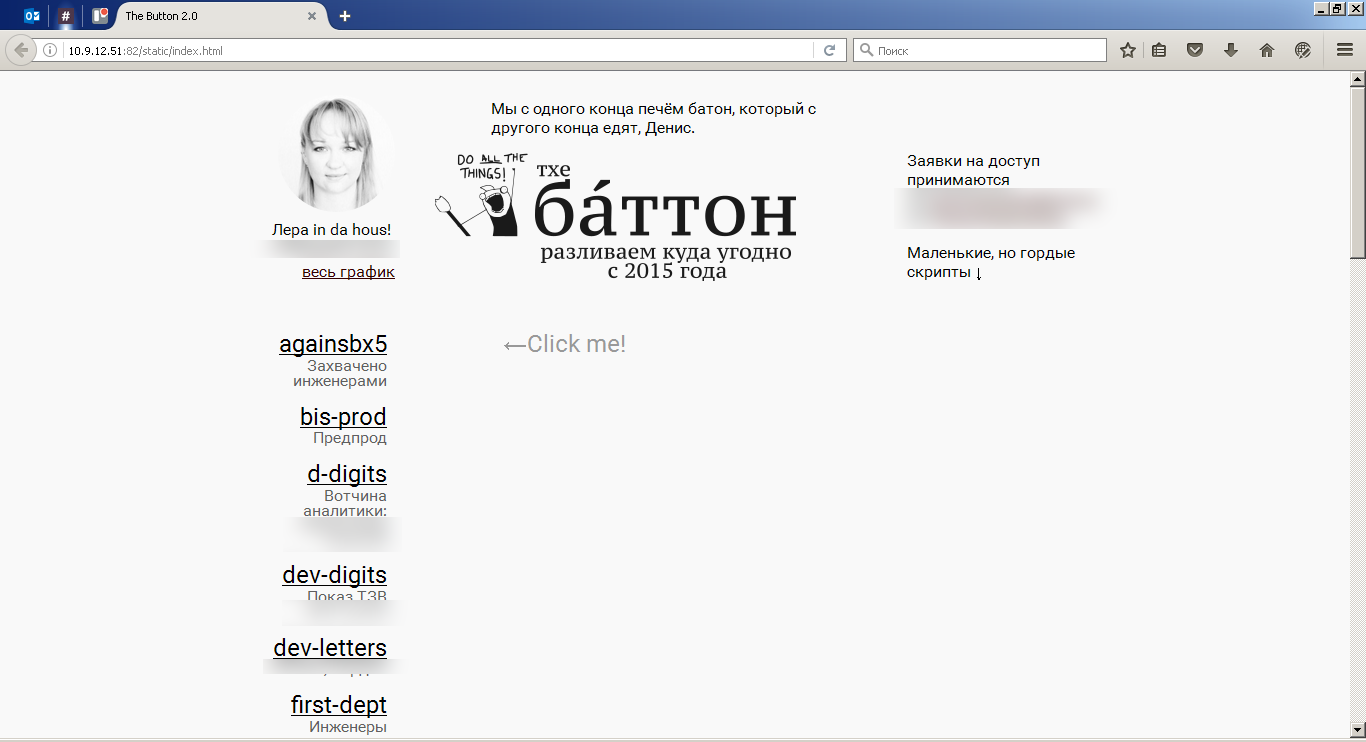
On the left there is a list of stands, there we choose a stand with which to do something. This is the name of the stand, which the engineers had previously passed to the script.
We poke the name of the desired stand, the details on the right open.

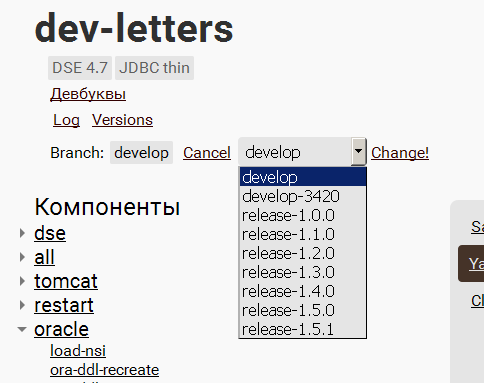
dev-letters is a name. Below is a brief description of the stand from the engineers (from the comment, the first line of the config). Links "see logs" and deployed versions of software, then - an indication of which branch will be taken assembly for this stand. And the ability to change this thread:
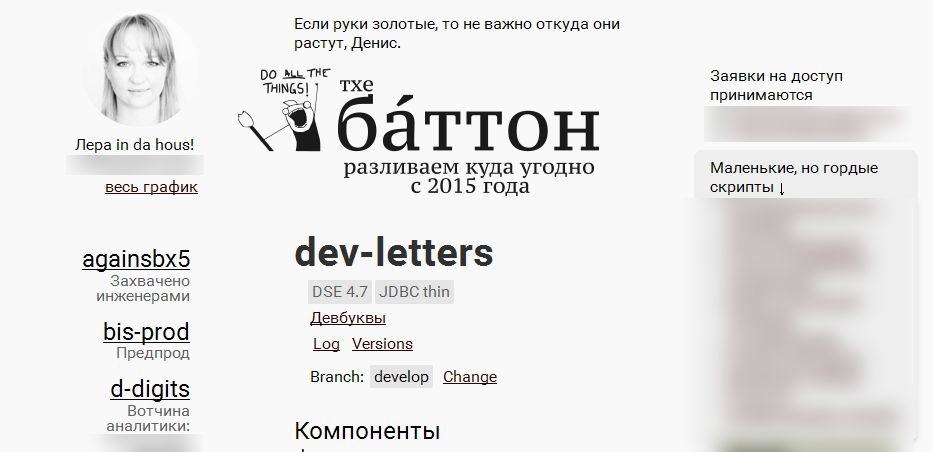
All scripted actions with stands are categorized and Components are signed. These are the names of actions that engineers previously transmitted to scripts:
When a component-action is selected from the list, it goes to the right side of the page:

Here they form a turn of execution: distribute them in the right order (or add them in the right order). For example, on the screen it will be executed: unload nsi, recreate the scheme in the Oracle database, load nsi back.
In order not to type in frequently used sequences, you can save them in a Combo and launch them with a few clicks, bypassing the search for the necessary components in the list.
Below are user comments on the stand. It is possible to leave a message to colleagues that the stand has been captured for very important work so that no one has touched it.

The last comment is displayed in the list of stands to make it easier to get a general picture of the stands and choose where to work.
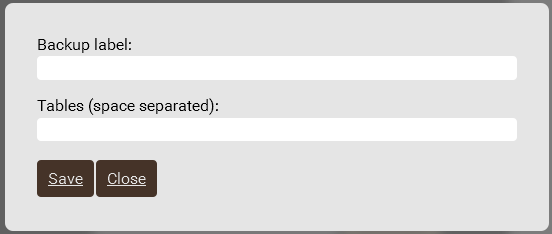
There is an exchange of data between the stands, in particular, between Cassandras. You can click the Save data button, come up with a name for the archive and a list of tables, then the data will be carefully saved. Then you can select another stand and load them there with the Load data button, selecting the desired archive from the list of available ones.

Users are authenticated via corporate AD. There is a simple access control: roles that can be allocated to users, and privileges for different stands, which can be assigned to roles. This is so that none of the still inexperienced colleagues will launch destructive components (re-creating the database, for example) on important stands.
A specially trained unicorn writes about all actions through the button to the command Slack. So everyone knows what is happening.

Also, the unicorn reports if the scripts fell off with an error so that the user that the 3-hour backup of the backup was cut off after 10 minutes of work, found out immediately, and not after 3 hours (besides, he would not need to constantly watch the process).

So, without waiting for the notifications of a caring unicorn, to find out how the process is going on, there are logs of script execution.

In order to see what is now deployed on our stand from our software, the Button with the system component of the system records the source of the distribution that was used for this. What we managed to record can be viewed and concluded that it is now deployed on the stand.

There is also a script that once a day passes through all the configs of the stands, goes to all the servers involved and looks at what works out of the system components, what versions of the system and our software are installed, what is running, what is not, when the last time there were calls to tomkats etc.
All this is going to an excel spreadsheet and is given to users so that you can analyze how stands are used, how to distribute them among developers, where to add / pick up pieces of hardware.

We have one stand to which access for security reasons is closed at the physical level, but our system should work there anyway. For this, there is a special stand on the list.
With it, everything, as with the rest of the stands, only when components are collected in the execution queue, does another process occur. The scripts copy themselves, cut off unnecessary parts (such as a page, privileges and configurations of development stands), create a script to call all the components specified in the queue. Then add to this all distributions of components, collect the resulting archives and spread on the ball.
That is, for all the stands it connects itself where it needs, and does the right things. And for where it is impossible to connect, he packs himself in a suitcase, from which he comes out of the bag and does his job upon arrival. It turns out such a “delayed execution”: scripts are formed that need to be attributed to the wall, run ./run_all.sh, and everything will be the same as with the other stands.
The cherry on the cake is at the top, as you can see, the technical information, in particular, the engineer on duty, his phone, gertrude, so that the developer can see that the page has actually been updated, and all sorts of minor utilities:
In order to try to understand whether this wonderful bike brings us some kind of benefit, I tried to estimate the time that Button won to the engineers.
If you take a typical scenario that runs more often than others: the database structure has changed, you need to roll up the migrations and update (say, one) the application affected by the update, it will take about 30-40 minutes in the case of one server.
Depending on the number of servers with such an application, the number of operations for copying the application to the server and correcting a heap of parameters in configs will change (+ the Kassandra, Orakla and Solara schemes).
The button does it on its own, without delay and user participation, you only need to select the desired steps. But is it all worth the effort if it needs to be done once a year. How many actions start per day?
To answer this question, I tried to roughly analyze the run logs. Judging by the first entries in the logs, we launched this version of the Button to work around February 1, 2016. On November 10, 2016, 185 days passed, of which, roughly speaking, 185 * 5/7 = 132 working days.
22192219/132 = 16.8106 launches per day.
But each launch is a whole sequence of components: let's calculate how many were there in total:
6442/132 = 48.8030 components per day.
It is difficult to accurately calculate how many hands we would deploy each component, but I think it is possible to estimate with a finger to the sky in 20 minutes. If so, then hands to do what the Button does on average per day will be 48 * 20/60 = 16 hours. 16 hours of work of the engineer - without errors, jambs, sticking on the Internet, lunch and chatting with colleagues.
You can also add that the button on all stands works simultaneously when the user needs it. Different users on different stands do not interfere with each other. In the case of an engineer, here you should add the time that the user-customer misses while waiting in line at the engineer.
On the one hand, it is not, because our developers have no root access to the products. They are not ready to receive it, because along with access, it is necessary to take responsibility, and there is a rather complicated infrastructure - Infiniband, Sparky, that's all - it is very easy to shoot yourself in the foot.
On the other hand, we have anyone, because any member of the team can roll the assembly onto the stands where he has access.
Assemblies on the product, for example, most often rolls the leader of the testing group.
Why not a docker or another ready-made solution?
Initially, the task was how to “at least learn how to put all this bunch of software together and make it work”. In the process of “learning,” a part was scripted, then another and another, and it turned out such a bike.
It began as a small automation. It was necessary to execute a bunch of database scripts from the directory - made a script that bypasses the directory and runs everything in it. Then it was thought that it would be cool to convert each script into UTF by force, adding this procedure to the same place. Then they began to add directives to each script in order to set the level of consistency with which to execute the script. Then they began to remove empty lines from each of them when they changed the version of the database client, and he spat on it. And so on.
We almost did not have a clear milestone, before which it was a gathering of such petty automation, and then became a system. It somehow grew by itself, in small steps. Therefore, the question of surely there is some kind of finished product arose only when our craft was solving the problem. Then it turned out that we need to replace something that works and closes the question with something that we have to study and sharpen to fit our needs (it is not known what file size).
That's how we got the control panel all at once: in a few clicks you can switch on the maintenance splash screen, migrate database schemas, rebuild indexes, install new assemblies at once with the necessary settings for the stand and without stopping users (due to sequential unbalancing) - any version on any stand, transfer data between stands, look at the state of stands and change histories on them.
The scripts under the hood are designed so that it is quite simple to adapt or modify them, so that other projects are slowly beginning to adapt the Button for themselves or to write their own bike based on the same ideas.
It is difficult to say whether we have arranged everything in the best way (probably not), but to work it works.
It turned out to save about 16 working hours of the administrator per day - these are two whole diggers. So now I have three of the casket, the same from the face. If you suddenly have questions not for comments, my mail is dpotapov@croc.ru.
They have four infrastructure engineers (Ops, admins, that is, us) - we most often needed to install software on the stands, reboot the machines (the developer’s first hope: does not work - ask the engineer to reboot), roll out the database schemas and etc.
')
Developers write code that merges into the repository. From it, Jenkins gives birth to assemblies that he puts on the ball. Deploying the system from scratch for the first time took me 4 hours and 15 minutes on a timer. For each of the order of ten components (scripts of different databases, Tomcat applications, etc.) in the right order, you had to take a file from the balls, figure out where and how many copies you need to deploy, correct the settings, indicate where to look other components of the system, associate all with all and do not confuse anything.
Fingers blew out - started scripting. It began with one small script.
What happened
The system consists of a rather large number of components: 6 different applications on Tomkat, each of which is in several instances on different servers, DSE = Cassandra + Solr + Spark cluster, scripts for creating objects in them, loading initial data, migrating Oracle schemas, PostgreSQL, cluster RabbitMQ, load balancers, a bunch of external systems, and so on.
Stands also mainly consist of several different servers. Applications on all stands are distributed differently (for example, somewhere one of Tomkat's applications is deployed in a single version, and somewhere in several it hides behind the balancer, somewhere a copy of Orakla, somewhere several, etc. .).
Total, deploy such a system - many servers and many components with different and frequently changing configs, in which they want to have information about each other, the location of databases, external systems, etc., etc. Thus, deploy everything where it is necessary, not to forget anything, not to confuse and properly configure - the task is not quite trivial. There are many places to make a mistake, and the process requires attention and concentration. First, I scripted the small parts that caused the most problems. The free time was spent on the next moments of malice, union and generalization.
The result was that one shell script was ready for each piece of the system, which did everything from copying the distribution from jenkins to editing configs and deploying the application or executing the processed scripts on the database. In general, everything began like a classic admin's bike: the same scripts that write almost everything for themselves from bricks. The difference is that we decided to make these parts interchangeable and immediately (well, in a month, not immediately) thought about the structure. As a result, it first became a system of scripts, where everything is quite flexible (outside), and then the web GUI also appeared.
I have already prepared scripts for each stand and for each component of the system that perform the necessary actions. But new stands appeared, the existing ones changed, the development of the system moved by leaps and bounds, and it was more and more difficult to reflect all the changes in the scripts.
Then I described the structure of the stand and all the parts changing from the stand to the stand in the configuration files, and the scripts summarized it so that they ate the name of the stand for work, found its config and from there received the necessary information for work.
That is, now the same scripts worked on all stands, the features of which were moved to the config. So reacting to changes has become quite simple.
The config is just a scary text file, which contains a list of variables and their, actually, values. The scripts simply source this file and get all the settings in the environment variables (in fact, it has now become a bit more complicated, but just a little).
Here he is
#BUTTON_DESC=DSE 4.7JDBC thin<br>
# include "defaults.include"
BUILD_DIRS="data-facade/release-1.5.0:DATA_FACADE,SOMEAPP process-runner/release-1.5.0:PROCESS_RUNNER integration-services/release-1.5.0:INTEGRATION scripts/release-1.5.0:CASS_DDL,ORA_DDL,SOLR_SCHEMA fast-ui/release-1.5.0:FAST_UI cache-manager/release-1.5.0:CACHE_MANAGER"
DSE_HOSTS="xxxdevb.lab.croc.ru xxxdevc.lab.croc.ru xxxdevd.lab.croc.ru xxxdeve.lab.croc.ru"
CASSANDRA_CONNECTION_HOSTS="xxxdevb.lab.croc.ru xxxdevc.lab.croc.ru xxxdevd.lab.croc.ru xxxdeve.lab.croc.ru"
CASS_DDL_NODE="xxxdeve.lab.croc.ru"
SOLR_URL="http://xxxdeve.lab.croc.ru:8983/solr"
ORA_DATABASES="xxxdevg.lab.croc.ru:1521/test"
ORA_CONN_STRING="jdbc:oracle:thin:@xxxdevg.lab.croc.ru:1521/test"
ORA_OPSTORE_PW="###"
ORACLE_HOSTS="DEVG"
DEVG_ADDR="xxxdevg.lab.croc.ru"
DEVG_INSTANCES="TEST"
DEVG_TEST_SID="test"
PG_SERVER="xxxdeva.lab.croc.ru"
DATA_FACADE_HOSTS="xxxdevb.lab.croc.ru"
SOMEAPP_HOSTS="xxxdevb.lab.croc.ru"
PROCESS_RUNNER_HOSTS="xxxdeva.lab.croc.ru"
PP_PROXY_PROCESS_RUNNER_URL="http://xxxdeva.lab.croc.ru:8080/xxx-process-runner"
XX_API_URL="http://#.#.#.#/###/api/"
CASS_DDL_ADD_BOM="yes"
CASS_DDL_TEST_SEED="yes"
KEYSPACE=xxx
REPLICATION_STRATEGY="{'class':'NetworkTopologyStrategy', 'Solr':3}"
CATALINA_HOME=/usr/share/apache-tomcat-8.0.23
CASS_DDL_DISTR_NAME="cass-ddl.zip"
SOLR_DISTR_NAME="solr-schema.zip"
DATA_FACADE_TARGET_WAR_NAME="data-facade.war"
SOMEAPP_DISTR_PATTERN='rest-api-someapp-*-SNAPSHOT.war'
SOMEAPP_TARGET_WAR_NAME="someapp.war"
PROCESS_RUNNER_TARGET_WAR_NAME='xxx-process-runner.war'
PROCESS_RUNNER_DISTR_PATTERN='resources/distr/xxx-process-runner.war'
PROCESS_RUNNER_RESOURCES_DISTR_DIR="resources"
CASS_REQ_FETCHSIZE=100
CASS_REQ_BATCHSIZE=10
CASS_REQ_MAX_LOCAL=2
CASS_REQ_MAX_REMOTE=2
CASS_REQ_CONSISTENCY_LEVEL="LOCAL_QUORUM"
INTEGRATION_AD_SEARCH_NAME="OU=TOGS, DC=testxxxx,DC=local;OU=GMC,DC=testxxxx,DC=local;OU=CA,DC=testxxxx,DC=local"
INTEGRATION_LDAP_PROVIDER_ADDRESS="#.#.#.#"
INTEGRATION_LDAP_PROVIDER_PORT="389"
INTEGRATION_LDAP_SECURITY_PRINCIPAL='testxxxx\\\\lanadmin'
INTEGRATION_LDAP_SECURITY_CREDENTIALS='!'
INTEGRATION_AD_ROOT_DEPARTMENT="DC=testxxxx,DC=local"
SSTABLELOADER_OPTS=""
CASS_REQ_QUEUESIZE=1
OSR_URL=http://#.#.#.#/SPEXX
QUEUE_HOST="xxxdevg.lab.croc.ru"
QUEUE_API_HOST="http://xxxdevg.lab.croc.ru:%s/api/"
QUEUE_ENABLE="true"
TOMCAT_HOSTS="DEVA DEVB"
DEVA_ADDR="xxxdeva.lab.croc.ru"
DEVA_CATALINA_HOMES="CH1"
DEVA_CH1_APPS="PROCESS_RUNNER"
DEVB_ADDR="xxxdevb.lab.croc.ru"
DEVB_CATALINA_HOMES="CH1"
DEVB_CH1_APPS="DATA_FACADE SOMEAPP FAST_UI CACHE_MANAGER"
CACHE_MANAGER_URL=http://xxxdevb.lab.croc.ru:8080/cache-manager/To make it even more convenient to manage the configs of the stands, I later added inclusions - bundles of logically related settings, recorded in separate files, which can be connected in bulk to configs or other inclusions. For example, the settings associated with AD are recorded in 5 different variables, and there are only two AD servers, for each of them there is an incLog with these 5 settings. To quickly switch stands, it is enough to connect the required connection between them. In order to reflect any change that occurred on the server, it is necessary to correct the settings in one file, and all stands aimed at it will know about it.
This structure of scripts was overgrown with whistlers, but mostly remained.
Actions are usually performed by a bundle - the sequence of actions makes sense, for example: on a test stand, save the NSI, recreate the circuit in Orakle, load the NSI back. If the previous component fell off with an error, probably the need for the next has disappeared. To make it more convenient, the launch script is made:
./run.sh "test" "save-nsi ora-ddl-init load-nsi" The run.sh script leaves to re-create the circuit with the preservation of the master data on the test bench, and the engineer - to drink tea.
GUI
It seemed that the engineer in the process of deploying the system is needed only to translate words from the human (“turn me first, second and compote”) into the names of the scripts in the sequence.
The team does not like the unix console, so the idea to run scripts without engineers was skeptical. But laziness pushed to make another attempt - made a page from the cgi script on Python, on which in a simple way you could select a config from the list and stick a sequence of components with the mouse. Roughly speaking, just a graphic button that can be pressed instead of a console command. She began to use.
The idea took root, other routine engineering actions were added, restarting individual components and servers as a whole, unloading-loading-saving information from different databases, balancing control, turning on “ballet” for the time of downtime, etc. The code name “ Button".
This creation of my crooked hands has been redone slightly, now it works on python + flask and can do everything without reloading the page: update the list of stands and their status, update the tails of logs, launch components and target them if they fake.
A colleague Andrew applied designer magic and made a beautifully designed page from the mash of my black and white divs.
On the left there is a list of stands, there we choose a stand with which to do something. This is the name of the stand, which the engineers had previously passed to the script.
./run.sh "dev-letters" "save-nsi ora-ddl-init load-nsi" We poke the name of the desired stand, the details on the right open.
dev-letters is a name. Below is a brief description of the stand from the engineers (from the comment, the first line of the config). Links "see logs" and deployed versions of software, then - an indication of which branch will be taken assembly for this stand. And the ability to change this thread:
All scripted actions with stands are categorized and Components are signed. These are the names of actions that engineers previously transmitted to scripts:
./run.sh "dev-letters" "save-nsi ora-ddl-init load-nsi" When a component-action is selected from the list, it goes to the right side of the page:
Here they form a turn of execution: distribute them in the right order (or add them in the right order). For example, on the screen it will be executed: unload nsi, recreate the scheme in the Oracle database, load nsi back.
In order not to type in frequently used sequences, you can save them in a Combo and launch them with a few clicks, bypassing the search for the necessary components in the list.
Below are user comments on the stand. It is possible to leave a message to colleagues that the stand has been captured for very important work so that no one has touched it.
The last comment is displayed in the list of stands to make it easier to get a general picture of the stands and choose where to work.
There is an exchange of data between the stands, in particular, between Cassandras. You can click the Save data button, come up with a name for the archive and a list of tables, then the data will be carefully saved. Then you can select another stand and load them there with the Load data button, selecting the desired archive from the list of available ones.
Users are authenticated via corporate AD. There is a simple access control: roles that can be allocated to users, and privileges for different stands, which can be assigned to roles. This is so that none of the still inexperienced colleagues will launch destructive components (re-creating the database, for example) on important stands.
A specially trained unicorn writes about all actions through the button to the command Slack. So everyone knows what is happening.
Also, the unicorn reports if the scripts fell off with an error so that the user that the 3-hour backup of the backup was cut off after 10 minutes of work, found out immediately, and not after 3 hours (besides, he would not need to constantly watch the process).
So, without waiting for the notifications of a caring unicorn, to find out how the process is going on, there are logs of script execution.
In order to see what is now deployed on our stand from our software, the Button with the system component of the system records the source of the distribution that was used for this. What we managed to record can be viewed and concluded that it is now deployed on the stand.
There is also a script that once a day passes through all the configs of the stands, goes to all the servers involved and looks at what works out of the system components, what versions of the system and our software are installed, what is running, what is not, when the last time there were calls to tomkats etc.
All this is going to an excel spreadsheet and is given to users so that you can analyze how stands are used, how to distribute them among developers, where to add / pick up pieces of hardware.
We have one stand to which access for security reasons is closed at the physical level, but our system should work there anyway. For this, there is a special stand on the list.
With it, everything, as with the rest of the stands, only when components are collected in the execution queue, does another process occur. The scripts copy themselves, cut off unnecessary parts (such as a page, privileges and configurations of development stands), create a script to call all the components specified in the queue. Then add to this all distributions of components, collect the resulting archives and spread on the ball.
That is, for all the stands it connects itself where it needs, and does the right things. And for where it is impossible to connect, he packs himself in a suitcase, from which he comes out of the bag and does his job upon arrival. It turns out such a “delayed execution”: scripts are formed that need to be attributed to the wall, run ./run_all.sh, and everything will be the same as with the other stands.
The cherry on the cake is at the top, as you can see, the technical information, in particular, the engineer on duty, his phone, gertrude, so that the developer can see that the page has actually been updated, and all sorts of minor utilities:
How much time saves
In order to try to understand whether this wonderful bike brings us some kind of benefit, I tried to estimate the time that Button won to the engineers.
If you take a typical scenario that runs more often than others: the database structure has changed, you need to roll up the migrations and update (say, one) the application affected by the update, it will take about 30-40 minutes in the case of one server.
Depending on the number of servers with such an application, the number of operations for copying the application to the server and correcting a heap of parameters in configs will change (+ the Kassandra, Orakla and Solara schemes).
The button does it on its own, without delay and user participation, you only need to select the desired steps. But is it all worth the effort if it needs to be done once a year. How many actions start per day?
To answer this question, I tried to roughly analyze the run logs. Judging by the first entries in the logs, we launched this version of the Button to work around February 1, 2016. On November 10, 2016, 185 days passed, of which, roughly speaking, 185 * 5/7 = 132 working days.
Number of launches:
[dpotapov@dpotapovl logs]$ (sum=0; for f in *.log ; do sum=$(expr $sum + $(grep "requested run" "$f" | wc -l)) ; done ; echo $sum) 22192219/132 = 16.8106 launches per day.
But each launch is a whole sequence of components: let's calculate how many were there in total:
for f in *.log ; do grep "requested run" $f \ |sed 's/^.*\[\(.*\)\].*$/\1/' \ | while read l ; do for w in $l ; do echo "$w" \ | sed 's/,$//' done done \ done \ > /tmp/requests.list cat /tmp/requests.list | wc –l [dpotapov@dpotapovl logs]$ cat /tmp/requests.list | wc –l 6442 6442/132 = 48.8030 components per day.
It is difficult to accurately calculate how many hands we would deploy each component, but I think it is possible to estimate with a finger to the sky in 20 minutes. If so, then hands to do what the Button does on average per day will be 48 * 20/60 = 16 hours. 16 hours of work of the engineer - without errors, jambs, sticking on the Internet, lunch and chatting with colleagues.
You can also add that the button on all stands works simultaneously when the user needs it. Different users on different stands do not interfere with each other. In the case of an engineer, here you should add the time that the user-customer misses while waiting in line at the engineer.
Is it already a devops?
On the one hand, it is not, because our developers have no root access to the products. They are not ready to receive it, because along with access, it is necessary to take responsibility, and there is a rather complicated infrastructure - Infiniband, Sparky, that's all - it is very easy to shoot yourself in the foot.
On the other hand, we have anyone, because any member of the team can roll the assembly onto the stands where he has access.
Assemblies on the product, for example, most often rolls the leader of the testing group.
Why not a docker or another ready-made solution?
Initially, the task was how to “at least learn how to put all this bunch of software together and make it work”. In the process of “learning,” a part was scripted, then another and another, and it turned out such a bike.
It began as a small automation. It was necessary to execute a bunch of database scripts from the directory - made a script that bypasses the directory and runs everything in it. Then it was thought that it would be cool to convert each script into UTF by force, adding this procedure to the same place. Then they began to add directives to each script in order to set the level of consistency with which to execute the script. Then they began to remove empty lines from each of them when they changed the version of the database client, and he spat on it. And so on.
We almost did not have a clear milestone, before which it was a gathering of such petty automation, and then became a system. It somehow grew by itself, in small steps. Therefore, the question of surely there is some kind of finished product arose only when our craft was solving the problem. Then it turned out that we need to replace something that works and closes the question with something that we have to study and sharpen to fit our needs (it is not known what file size).
Summary
That's how we got the control panel all at once: in a few clicks you can switch on the maintenance splash screen, migrate database schemas, rebuild indexes, install new assemblies at once with the necessary settings for the stand and without stopping users (due to sequential unbalancing) - any version on any stand, transfer data between stands, look at the state of stands and change histories on them.
The scripts under the hood are designed so that it is quite simple to adapt or modify them, so that other projects are slowly beginning to adapt the Button for themselves or to write their own bike based on the same ideas.
It is difficult to say whether we have arranged everything in the best way (probably not), but to work it works.
It turned out to save about 16 working hours of the administrator per day - these are two whole diggers. So now I have three of the casket, the same from the face. If you suddenly have questions not for comments, my mail is dpotapov@croc.ru.
Source: https://habr.com/ru/post/318532/
All Articles