Kaggle: Allstate Claims Severity
I would like to describe the solution to the recent Allstate Claims Severity machine learning competition. (My result is 40 of 3055). Since this is a competition of the “ensemble Rubilovo” type, as a rule, the discussion of decisions causes unhealthy holy wars between those who have tried to participate and those who have not, so first I will make a small lyrical digression.
I apologize in advance for the abundance of English words. I don’t know how to translate some, but I don’t want to translate some.
I like to think of machine learning as three little connected directions, which I tried to depict in the picture above, and each of these directions pursues its own goals.
For example, in an academic environment, your productivity, and indeed personal steepness, is measured by the number and quality of published articles - and here the novelty of ideas is important, but how far these ideas can be put into practice right now is the tenth thing.
')
In business, how much money your models bring to the company, and here interpretability, scalability, speed, model size and so on are important.
In competitive machine learning, the challenge is to win everyone. That is, the model will be non-scalable, and it should be trained for weeks - this is acceptable.
In the overwhelming majority of cases when a company provides data for a competition, the models with the best accuracy in production are not available due to their complexity. (A classic example is the Netflix prize competition on which the best models do not apply, but the knowledge gained by the participants while working on a problem definitely gave impetus to research towards recommender systems.) And, as a result, among those who did not try to participate in machine learning is an opinion that the models that were obtained in the framework of the competition are useless. And they, of course, are right. But this audience immediately concludes that the knowledge gained during participation in competitions is also useless, and that only those who cannot find a “real” job and who have time for this “useless exercise” take part in the competition . For example, my colleague in the last work, by the name of Alex, whom I discussed in this post , thought so.
There is an opposite extreme: those who show quite good results at competitions think that they will easily spew models out of themselves, which will immediately make great money in Production, which theoretically could happen, but in practice I did not come across. Still, the accuracy of the model on the train set, test set and in production are three big differences.
I prefer thinking machine learning in business vs competitions as about climbing up vs climbing. If you pull up many times - this does not mean that you are a good climber, but at the same time pulling up helps to climb to some extent and good climbers often invest time to pull up better, while not just pulling up, but pulling up with weights , pull-ups on campusboard, with arms at different heights, etc.
Machine learning competitions work in a similar mode in the sense that if you are a Machine Learning Engineer or Data Scientist and you cannot offer something worthwhile in competitions, then perhaps it makes sense to invest some time in it. Moreover, there are a lot of competitions, they are different and something from some kind of competition can be useful for you at work or for science. At least the guys from Google, Deepmind, Facebook, Microsoft, and other serious companies periodically participate. Yes, and cases where good performance at competitions helped to find a decent job more than enough.
Task Description
Allstate has provided data for the competition at Kaggle.com not for the first time and, apparently, they like it. This time the prize at the competition - the recruiter Allstate, may force yourself to spend 6 seconds on your resume if you apply for the Junior Data Scientist position. Despite the fact that the prize is about nothing, the competition attracted more than three thousand participants, which made it a unique storehouse of specific knowledge.
The task was to create a model that would predict the amount of payment for the insured event. In general, as usual, the insurance company wants to predict who does not need insurance - and it is for them to sell it, and who may fall under the insurance case - they don’t sell or sell high.
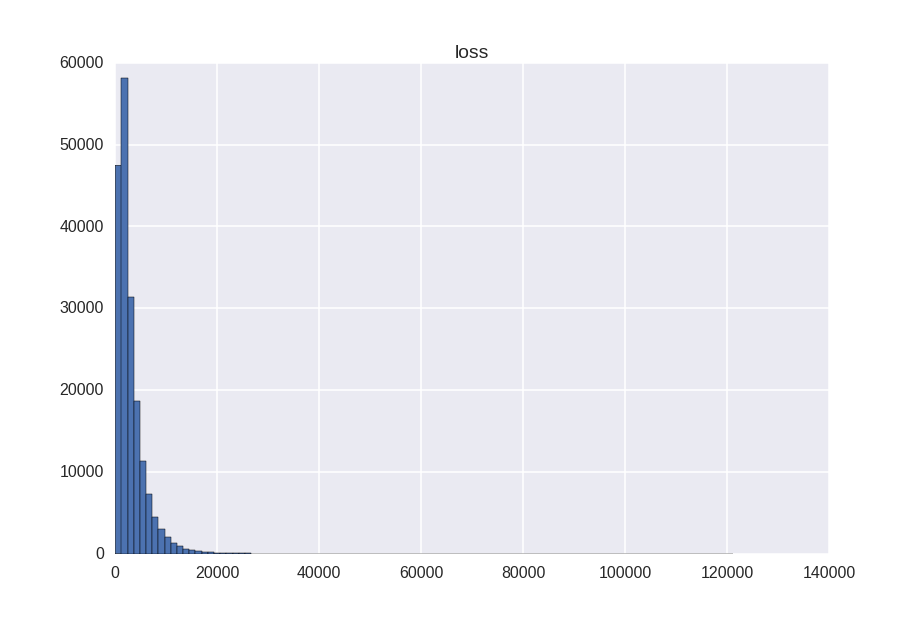
The target variable has this asymmetric distribution:
Where:
- min = 0.67
- max = 121012
- mean = 3037
Results were evaluated by the Mean Absolute Error metric
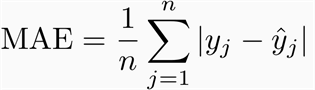
Anonymized data. 14 numerical and 116 categorical signs.
- Train set - 188318 rows
- Test test - 125546 rows
As usual, to prevent overfitting, the test set was divided into 2 parts:
- 30% test set - Public Leaderboard - the accuracy of your model on this part could be checked during the entire competition. (5 attempts per day)
- 70% test set - Private Leaderboard - the accuracy on this part of the test set becomes known after the end of the competition and it is this that is ultimately used to evaluate your model.
That is, there is little data, and a good result can be obtained on low-powered machines without using cloud computing, for example, on laptops, which in many respects caused a large number of participants.
The level of models / participants' knowledge can be very conditionally divided into such categories, where the number is an approximate error on the Public LeaderBoard.
- 1300+ - those who know the basics of machine learning can prepare data, train linear regression and make a prediction. 16% of participants
- 1200-1300 - those who know something other than linear regression. 28% of participants.
- 1200-1120 - those who know that xgboost / LightGBM exists, but they are not good at tuning it. 9% of participants.
- 1110-1120 - those who can configure xgboost or neural networks. 22% of participants
- 1104-1110 - those who know that the arithmetic average of xgboost predictions and neural networks is more accurate than each of the predictions separately. 11% of participants.
- 1102-1104 - those who are able to build more complex linear combinations. 6% of participants.
- 1101-1102 - those who know how to use stacking. 5% of participants.
- 1096-1101 are serious guys. 3% of participants.
This gradation is very conditional, at least because of the large number of participants and the ridiculousness of the prize. That is, the public actively shared ideas and code and, for example, there were branches on the forum where it was discussed step by step what needs to be done to make 1102. As a result, as was correctly noticed by Love Bubbly , this competition was similar to Red Queen's race when you need to improve your models. every day only in order not to crawl down on the LeaderBoard, for 1102+ could be obtained by running and sedating the results of the predictions of someone else's code, which, in general, is rather low style, but it’s better than that. It is also necessary to be able to average correctly.
Ideas
Idea one
The target variable is highly asymmetric. In this case, machine learning algorithms work better on symmetric data. Some like the target variable to have a normal distribution, some not. In this case, the statement that can be found in the literature that the more symmetrical the target variable is, the better, in this case it is not true. Standard ways to increase symmetry - logarithm, exponentiation.
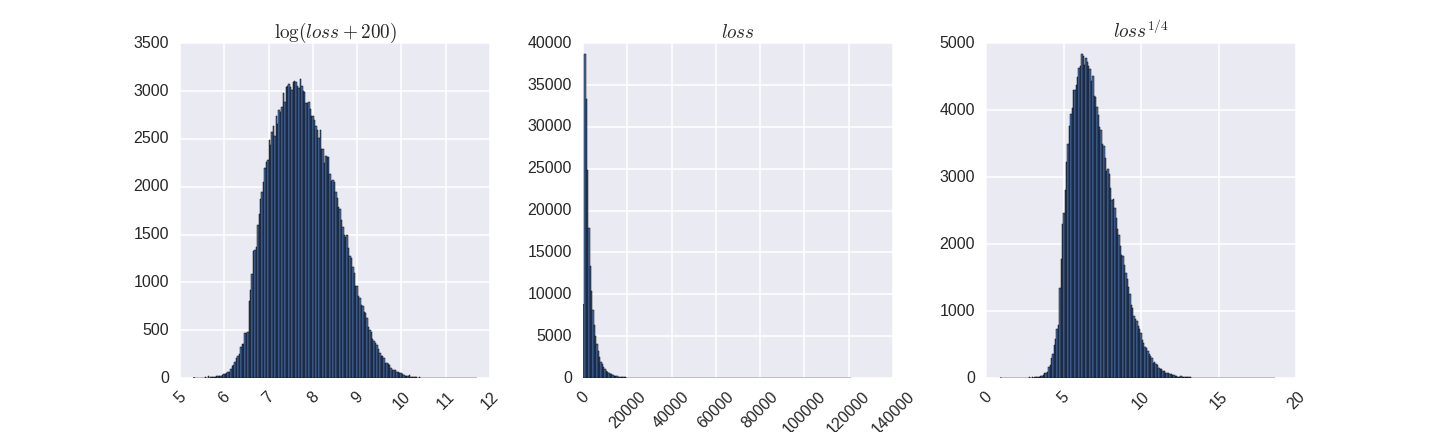
That is, we want something more symmetrical than what was originally, but, since our target MAE metric is from an untransformed target variable, we want an error during training on large values, like 120,000, to be more than 100, but not 1200 times. And the correct transformation is the one that translates the target variable into something symmetrical, but with a thick right tail. For example, the fourth degree root has shown itself very worthy of me, better than the logarithm.
Second idea
This is a competition:
- on data of mixed type that do not have a local structure
- size of training data 10 ^ 4 - 10 ^ 7
This is the type and volume on which in 95% of cases xgboost has no competitors. What happened here.
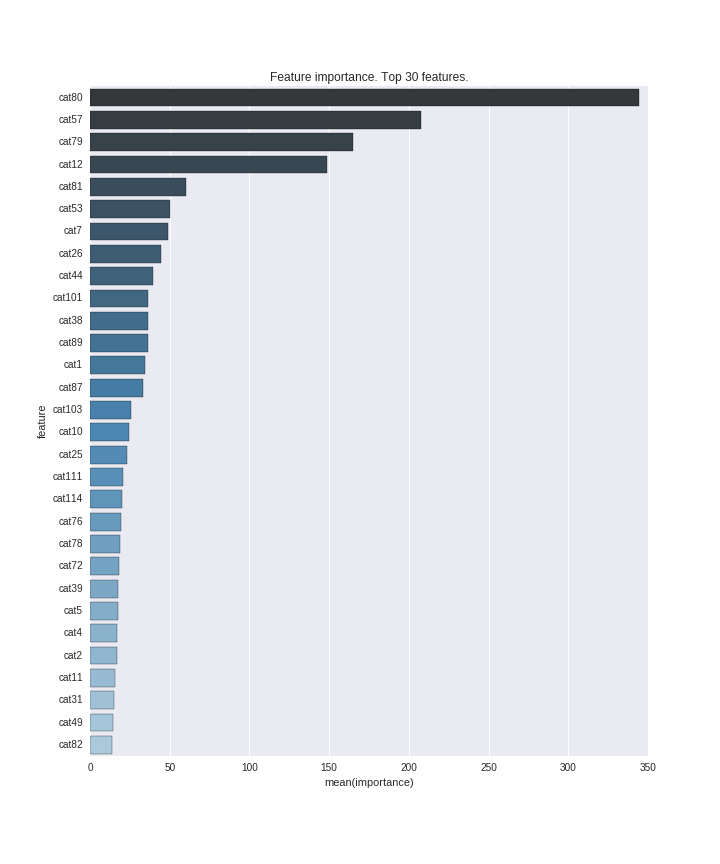
On this graph, the top 30 most important signs.
Mathias Müller obtained 1109 using xgboost on the original data, which corresponds to the top 25%. (As a result, he finished the competition third)
Idea three
How to find good hyperparameters? There are several methods:
- Manually.
- GridSearch - set the grid and check everything or some subset of parameters.
- More intelligent methods like Hyperopt or BayesianOptimization
In practice, BayesianOptimization has done well to find good candidates + manual spin.
What ranges of parameters to check? God knows. I believed that they write in the literature that the structure of the algorithm based on gradient boosting is such that it makes no sense to use trees with a depth of more than 10. They lie. In most cases it is, but this is not enough on this data. The best models used deeper trees, up to max_depth = 25.
Fourth idea
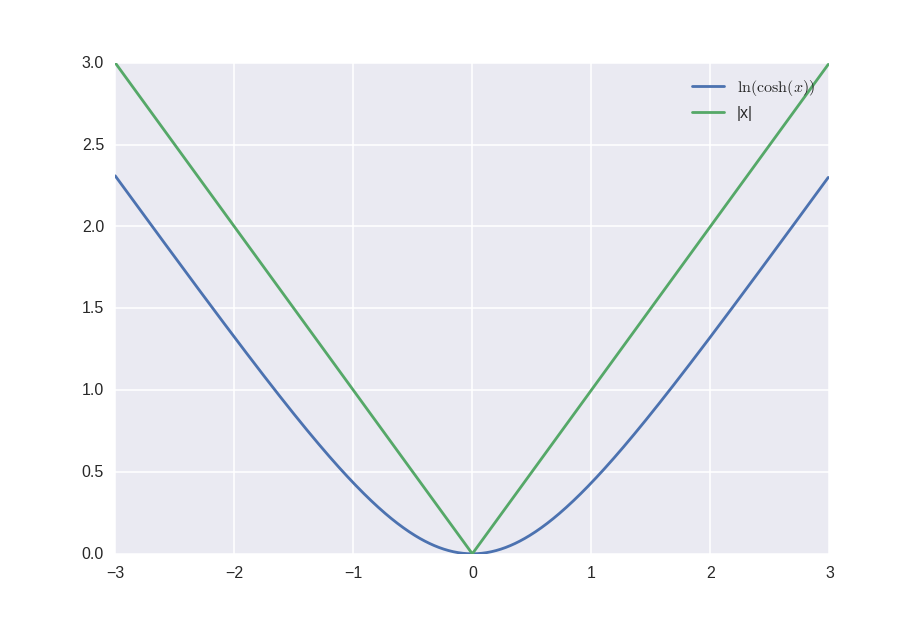
Since MAE is not twice differentiable, it is possible to approximate the module as ln (cosh), which is already twice differentiable, and now it is possible to use not the root-mean-square error for the loss function, but something more interesting. And there was a forum thread on which it was actively discussed.
Idea five
There is an opinion that for algorithms that are based on the decision tree, it is not important how to convert categorical signs into numerical ones. And that in all other algorithms except for one hot encoding nothing can not be used. And that, and another statement from the point of view of business - however, from the point of view of competition and the academic environment - is a blatant lie. There is a difference, but it is small. You can try different encoding and see what works best. For example, for some categorical features, the lexicographic encoding worked a little better, allowing you to reduce the number of splits in each tree.
Idea six
There is an opinion that tree-based algorithms find interactions between features. It is not true. They approximate them. From a business point of view, they are the same thing. In terms of competition - no. Therefore, if you take the top as many of the most important signs from the image above and create new signs that will describe their interactions, then the accuracy of some models increases, which was suggested in one of the scripts . And it allowed someone to reach 1103 with xgboost. (My best score is 1104)
Idea Seven
What about feature engineering? Correct signs in most cases (but not always) will give more than clever numerical methods. In preparing the data, Allstate did a very decent job, and despite the efforts of the participants, it was not possible to de-anonymize anything properly. It seems they understood that one of the signs is the state. And that any signs somehow relate to dates. But as far as I know none of this fished out. Statistical signs, too, no one really use failed. I still added time zones, and statistical signs for the most important categorical ones, but this is more likely to calm my conscience.
Here, for example, the sign diff cont2 vs cont2.
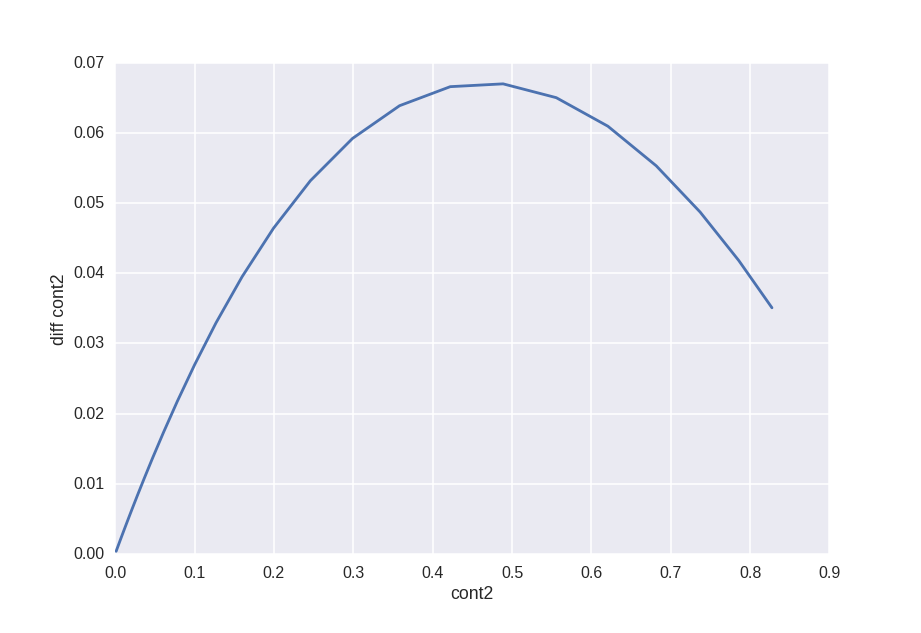
In theory, this should tell us what kind of transformation Allstate applied to the cont2 feature, but no matter how hard I could figure out how to find this transformation.
Idea eight
To get a better result, 1102 needs stacking. This is such a competent technique that is used in every second competition, but as far as I know, it is used extremely rarely in production. She does not give much. But the use of stacking allows you to cleverly cross different models. Actually, before participating in this competition, I did not own this technique, but only heard the edge of my ear, and the main motivation for participation was to sort out and close this question for myself.
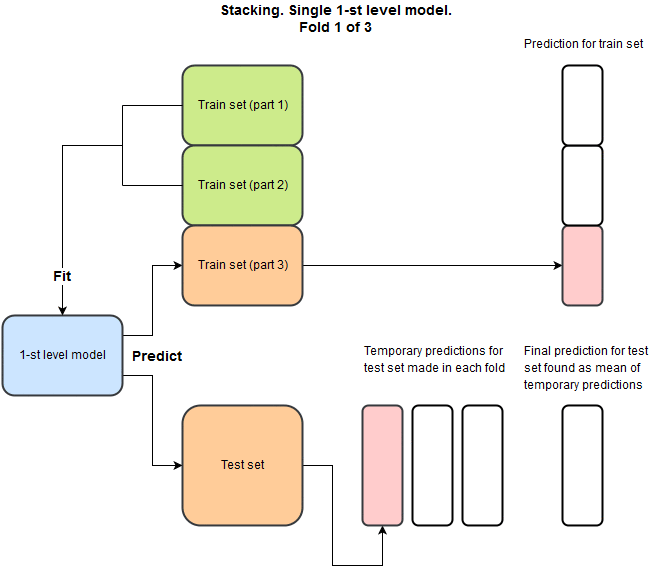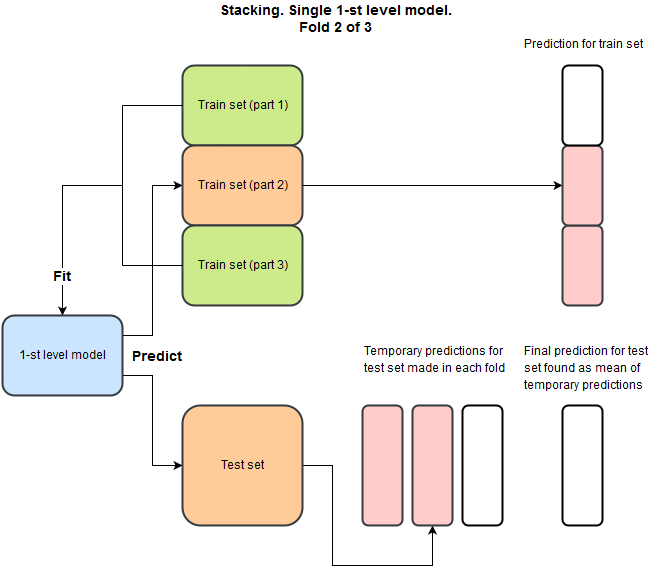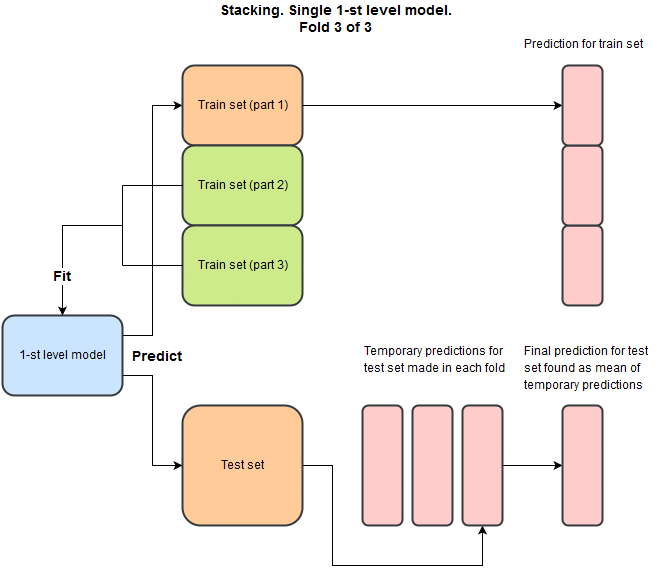
The idea is that for each model we want to make a prediction on the train set and on the test set, while we do not want to predict on the train on the same data that was used for training. Here 's a python example of how to do this.
And as a result, for each model we will have a prediction on the train, and corresponding to the test. Why is this necessary? We repeat this for different models and combine the predictions into a new train and test set. With signs:
- train: {prediction_xgboost, prediction_NN, prediction_SVM, etc}
- test: {prediction_xgboost, prediction_NN, prediction_SVM, etc}
And now we can forget about the original training and test data and train the second level already on this new data using linear or nonlinear methods.
Moreover, we can repeat this procedure several times using the predictions from the previous step as features for the next. In one of the past competitions the final decision looked like:

Actually such dense decisions and cause rejection of those who think about machine learning solely from the point of view “How much value can I bring to the company?”, Because in practice they are not applicable, although there are companies that are trying to automate this process.
Idea nine
We made a prediction using stacking. Can it be improved? Can. Tree-based algorithms underestimate large values and overestimate small ones, so the final prediction can be calibrated. A popular transformation that some participants used is:
alpha * prediction ^ beta , and someone even did it for different quantiles.
Conclusion
Actually, that's all. Many different models are being trained (xgboost, Neural Networks, Random Forest, Ridge Regression, Extra Trees, SVR, LightGBM) with various hyper-parameters on the data, which are converted by various methods in stacking mode. And then, on predictions from all these models, the Neural Network is trained with a pair of hidden layers in order to get a final result.
Everything is quite simple and straightforward, but at the same time to achieve this, a certain effort was required. Moreover, experienced participants it was easier than inexperienced. Let's hope that in another problem, where similar techniques can be used, the sacred knowledge gained here will somehow help.
Those who have not tried to participate in competitions, I strongly recommend.
If you use machine learning at work, then God himself told you to check how much your knowledge and skills gained at work are applicable in the world of Competitive Machine Learning, and it is possible that something you may learn during the competition and it can it will come in handy at work so that you can “bring value to the company”. For example, I convinced the boss to do a couple of submissions at a recent competition. He flew to the bottom 10 percent of LeaderBoard (he went angry and then thought a lot) because he used different encoding for train and test. After that, his policy at work changed and we began to spend a little more time on testing.
If you are still a student - God himself ordered to participate. If five years ago I had the same data-handling skills, my postgraduate research would have been more effective and I would have published more articles. Plus, good results from competitions in which the workhorse is neural networks can almost certainly be published. And as a piece of diploma can be precisely inserted.
If you are thinking about a gradual transition to Data Science - again, God himself ordered you to participate. Competition alone is not enough for you to be hired, but in combination with education and experience in other areas should help. That year, the guy in DeepMind was invited after one of the competitions, so the cases are different.
Not all tasks are so focused on numerical methods. A recent product prediction competition for various users of Santander Bank in Spain is pure feature engineering. It is a pity that I spent little time with him. Or competitions that are currently being held on Computer Vision, neural networks and other currently fashionable words:
- Pro Fish - $ 150,000 prize
- About satellite maps - $ 100,000 prize
- Pro Cancer - $ 1,000,000 Prize
Interestingly, a lot of knowledge, beautiful pictures, and who are lucky enough and will give money.
And since this is Habr and here they love code - unstructured code, which I wrote for this task .
English translation
Source: https://habr.com/ru/post/318518/
All Articles