Data Storage Architecture in Facetz.DCA
In the “ BigData from A to Z ” series of articles, we looked at one of the most frequently used technology stacks for working with Apache Hadoop big data and gave examples of its use in DCA products. Now we will tell you what the data storage architecture in Facetz.DCA looks like.

Facetz.DCA refers to the components of the programmatic infrastructure, which are called the DMP - Data Management Platform (User Data Processing Platform). The task of DMP - having information about the activity of the user to build his "thematic portrait" - a lot of interests. This process is called segmentation. For example, knowing that a person frequently visits fishing sites, one can conclude that he is an avid angler. The result is user segments that can later be used to display the most relevant advertisements. In a simplified form, the DMP operation scheme looks like this: data about user activity enters the system, it analyzes users and returns multiple segments by id.

Facetz.DCA stores activity data for more than 600 million anonymized users and gives away the user's interests on average in less than 10 ms. The need for such a high speed is dictated by the process of displaying advertising using Real Time Bidding technology - the answer to the request for the display must be given within 50 ms.
')
When building a data storage architecture in DMP, two tasks are solved: storing user information for subsequent analysis and storing analysis results. The solution of the first should provide high bandwidth when accessing data - user activity history. The second task requires minimal delays, the same 10 ms. Both solutions must be well horizontally scalable.
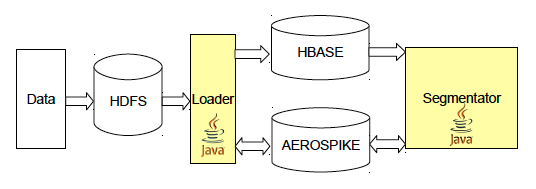
Facetz.DCA receives several terabytes of logs per day; we use the distributed file system HDFS to store them. Data processing takes place using the MapReduce paradigm. Access to raw data is organized through Apache Hive, a library that translates SQL queries into MapReduce tasks. More details about these technologies can be found in our articles - this and this .
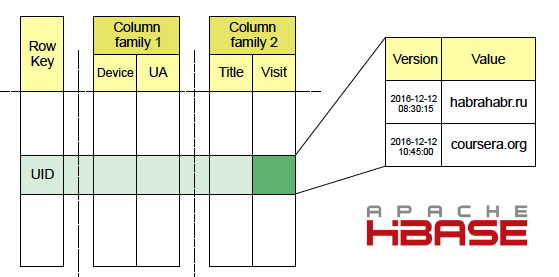
Facetz uses Apache HBase to store user activity data. Information about visited sites gets there through the Map-Reduce Loader service, which reads raw logs from HDFS, as well as streamed through Kafka. In HBase, the data is stored in tables, the key is the user id, the columns are various kinds of facts, for example, the url of the visited page, its name, useragent or ip-address. Columns are combined into families - Column Family, data from one Column Family is stored side by side, which increases the speed of execution of GET queries containing data from several columns within one family. There are many versions for each cell, the event time plays the role of version in our system. You can read more about Apache HBase in this article .
Our project uses both offline and realtime segmentation of users, which causes two different data access patterns in HBase. Offline segmentation occurs once a day, in the process we carry out a full SCAN HBase table. Realtime starts immediately after the new fact about the user enters the database. Thus, it is possible to see changes in the interests of active users with minimal delay. With realtime segmentation, GET requests are used in HBase. To start, we use the trigger mechanism at the database level - coprocessor in HBase terminology . It is triggered when writing new data to HBase through PUT and BulkLoad operations. To ensure the maximum speed of working with data in HBase, we use servers with SSD drives.
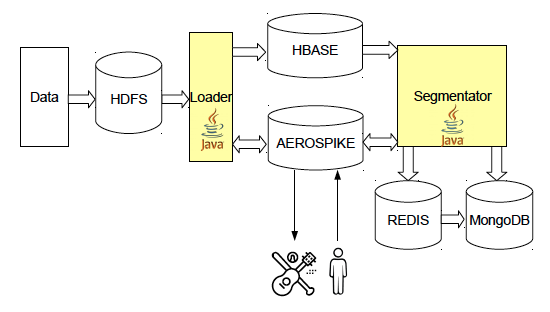
After the user has been analyzed, the results are put in a separate database for later use. The storage should provide high speed of both recording and uploading data, the volumes of which make up several terabytes - this is how much the total volume of all user segments takes. For these purposes, we use Aerospike, a distributed key-value storage designed specifically for SSD disks. This DBMS is in many respects a unique product, and one of its most frequent users is programmatic products. Among other features of Aerospike, it is worth noting support for UDF-functions on the LUA and the ability (with the help of an additional library) to run tasks on top of the Hadoop database.
During the analysis, DMP counts the number of users in each segment. A more difficult task is to determine the size of associations or intersections, for example, the number of pregnant women in Tver can be calculated as the volume of intersection of the “pregnant women” and “live in Tver” segments. And the number of users owning a Niva car and living in Vologda or Ryazan, as the volume of intersection of the segment “owners of the Niva” with the association “live in Vologda” and “live in Ryazan”. One of the main uses of this information is to predict the coverage of an advertising campaign.
To calculate the volume of the segments, we use the HyperLogLog data structure , which is implemented in the key-value Redis repository. HLL is a probabilistic data structure that allows determining the number of unique objects in the set with a small (~ 0.81%) error, while occupying a sufficiently small amount of memory, in our tasks it is a maximum of 16 KB per key. A distinctive feature of HLL is the possibility of counting the number of unique objects in the union of several sets without the appearance of an additional error. Unfortunately, working with intersections of sets in HLL is more difficult: the inclusion-exclusion formula gives a very high error in the case of a large difference between the volumes of sets, MinHash is often used to increase accuracy, but this requires special modifications and still gives a fairly large error. Another problem of HLL is that it is not always convenient to use it in redis-cluster, since without additional data copying, only keys located on the same node can be merged. In addition to HLL, we use Redis to store counters, for example, the number of visits to sites per day. This data allows us to calculate the affinity of advertising sites .
We use MongoDB to store service configurations, statistics, and various meta-information. In Json format, it is convenient to store complex objects, and the lack of a data scheme makes it easy to modify the structure. In fact, we use
only a small part of the capabilities of this database, which in many projects is used as the main repository.
Regarding the storage architecture at the moment, the main plan is to improve the quality of counting volumes of user segments, here we are looking in the direction of ClickHouse and Cloudera Impala. Both of these databases allow you to quickly calculate the approximate number of unique objects in a set.
NoSQL - databases perfectly show themselves as a repository when building projects in online advertising. They are well scaled and at the same time allow for high speed data access. Unfortunately, it is not always possible, using only one technology, to solve all the tasks, in Facetz.DCA we successfully use several NoSQL databases at once.
What is Facetz.DCA?
Facetz.DCA refers to the components of the programmatic infrastructure, which are called the DMP - Data Management Platform (User Data Processing Platform). The task of DMP - having information about the activity of the user to build his "thematic portrait" - a lot of interests. This process is called segmentation. For example, knowing that a person frequently visits fishing sites, one can conclude that he is an avid angler. The result is user segments that can later be used to display the most relevant advertisements. In a simplified form, the DMP operation scheme looks like this: data about user activity enters the system, it analyzes users and returns multiple segments by id.
Facetz.DCA stores activity data for more than 600 million anonymized users and gives away the user's interests on average in less than 10 ms. The need for such a high speed is dictated by the process of displaying advertising using Real Time Bidding technology - the answer to the request for the display must be given within 50 ms.
')
When building a data storage architecture in DMP, two tasks are solved: storing user information for subsequent analysis and storing analysis results. The solution of the first should provide high bandwidth when accessing data - user activity history. The second task requires minimal delays, the same 10 ms. Both solutions must be well horizontally scalable.
Raw data storage
Facetz.DCA receives several terabytes of logs per day; we use the distributed file system HDFS to store them. Data processing takes place using the MapReduce paradigm. Access to raw data is organized through Apache Hive, a library that translates SQL queries into MapReduce tasks. More details about these technologies can be found in our articles - this and this .
User Profile Storage
Facetz uses Apache HBase to store user activity data. Information about visited sites gets there through the Map-Reduce Loader service, which reads raw logs from HDFS, as well as streamed through Kafka. In HBase, the data is stored in tables, the key is the user id, the columns are various kinds of facts, for example, the url of the visited page, its name, useragent or ip-address. Columns are combined into families - Column Family, data from one Column Family is stored side by side, which increases the speed of execution of GET queries containing data from several columns within one family. There are many versions for each cell, the event time plays the role of version in our system. You can read more about Apache HBase in this article .
Our project uses both offline and realtime segmentation of users, which causes two different data access patterns in HBase. Offline segmentation occurs once a day, in the process we carry out a full SCAN HBase table. Realtime starts immediately after the new fact about the user enters the database. Thus, it is possible to see changes in the interests of active users with minimal delay. With realtime segmentation, GET requests are used in HBase. To start, we use the trigger mechanism at the database level - coprocessor in HBase terminology . It is triggered when writing new data to HBase through PUT and BulkLoad operations. To ensure the maximum speed of working with data in HBase, we use servers with SSD drives.
Storing user segmentation results
After the user has been analyzed, the results are put in a separate database for later use. The storage should provide high speed of both recording and uploading data, the volumes of which make up several terabytes - this is how much the total volume of all user segments takes. For these purposes, we use Aerospike, a distributed key-value storage designed specifically for SSD disks. This DBMS is in many respects a unique product, and one of its most frequent users is programmatic products. Among other features of Aerospike, it is worth noting support for UDF-functions on the LUA and the ability (with the help of an additional library) to run tasks on top of the Hadoop database.
Counting the number of unique users in a segment
During the analysis, DMP counts the number of users in each segment. A more difficult task is to determine the size of associations or intersections, for example, the number of pregnant women in Tver can be calculated as the volume of intersection of the “pregnant women” and “live in Tver” segments. And the number of users owning a Niva car and living in Vologda or Ryazan, as the volume of intersection of the segment “owners of the Niva” with the association “live in Vologda” and “live in Ryazan”. One of the main uses of this information is to predict the coverage of an advertising campaign.
To calculate the volume of the segments, we use the HyperLogLog data structure , which is implemented in the key-value Redis repository. HLL is a probabilistic data structure that allows determining the number of unique objects in the set with a small (~ 0.81%) error, while occupying a sufficiently small amount of memory, in our tasks it is a maximum of 16 KB per key. A distinctive feature of HLL is the possibility of counting the number of unique objects in the union of several sets without the appearance of an additional error. Unfortunately, working with intersections of sets in HLL is more difficult: the inclusion-exclusion formula gives a very high error in the case of a large difference between the volumes of sets, MinHash is often used to increase accuracy, but this requires special modifications and still gives a fairly large error. Another problem of HLL is that it is not always convenient to use it in redis-cluster, since without additional data copying, only keys located on the same node can be merged. In addition to HLL, we use Redis to store counters, for example, the number of visits to sites per day. This data allows us to calculate the affinity of advertising sites .
Storage of settings and statistics
We use MongoDB to store service configurations, statistics, and various meta-information. In Json format, it is convenient to store complex objects, and the lack of a data scheme makes it easy to modify the structure. In fact, we use
only a small part of the capabilities of this database, which in many projects is used as the main repository.
Future plans
Regarding the storage architecture at the moment, the main plan is to improve the quality of counting volumes of user segments, here we are looking in the direction of ClickHouse and Cloudera Impala. Both of these databases allow you to quickly calculate the approximate number of unique objects in a set.
Summary
NoSQL - databases perfectly show themselves as a repository when building projects in online advertising. They are well scaled and at the same time allow for high speed data access. Unfortunately, it is not always possible, using only one technology, to solve all the tasks, in Facetz.DCA we successfully use several NoSQL databases at once.
Source: https://habr.com/ru/post/318464/
All Articles