Performance comparison of analytical Exasol and Oracle In-Memory Option DBMS
 I devoted my previous article to how and how much you can accelerate analytical (typical for OLAP / BI systems) queries in Oracle DBMS by connecting the In-Memory option. In continuation of this topic, I want to describe several alternative DBMS for analytics and compare their performance. And I decided to start with in-memory RDBMS Exasol .
I devoted my previous article to how and how much you can accelerate analytical (typical for OLAP / BI systems) queries in Oracle DBMS by connecting the In-Memory option. In continuation of this topic, I want to describe several alternative DBMS for analytics and compare their performance. And I decided to start with in-memory RDBMS Exasol .For the tests, the results of which I publish, the TPC-H Benchmark is selected and, if desired, readers can repeat my tests.
Brief information about Exasol DBMS
Exasol is a relational analytical in-memory database with the following key characteristics:
- In-memory . The database is primarily intended for storing and processing data in RAM. In this case, the data is duplicated on the disk and the entire database does not have to be stored in memory. When executing queries, the missing data in the memory is read from the disk;
- MPP (massive parallel processing). The data is distributed across the cluster nodes for high-performance parallel processing (implemented according to the shared nothing architecture);
- Column-wise data storage. Information in tables is stored in columns in a compressed form, which significantly speeds up analytical queries;
- Supports ANSI SQL 2008 ;
- It integrates well with most BI tools ;
- In-Database Analytics. Support for user-defined functions in LUA, Python, R, Java.
- Java-based interface to Hadoop's HDFS .
More details about the capabilities of Exasol can be found in the excellent article on Habré. I will add only that, despite the low popularity in our area, this is a mature product that has been present in the Gartner Magic Quadrant for Data Warehouse since 2012.
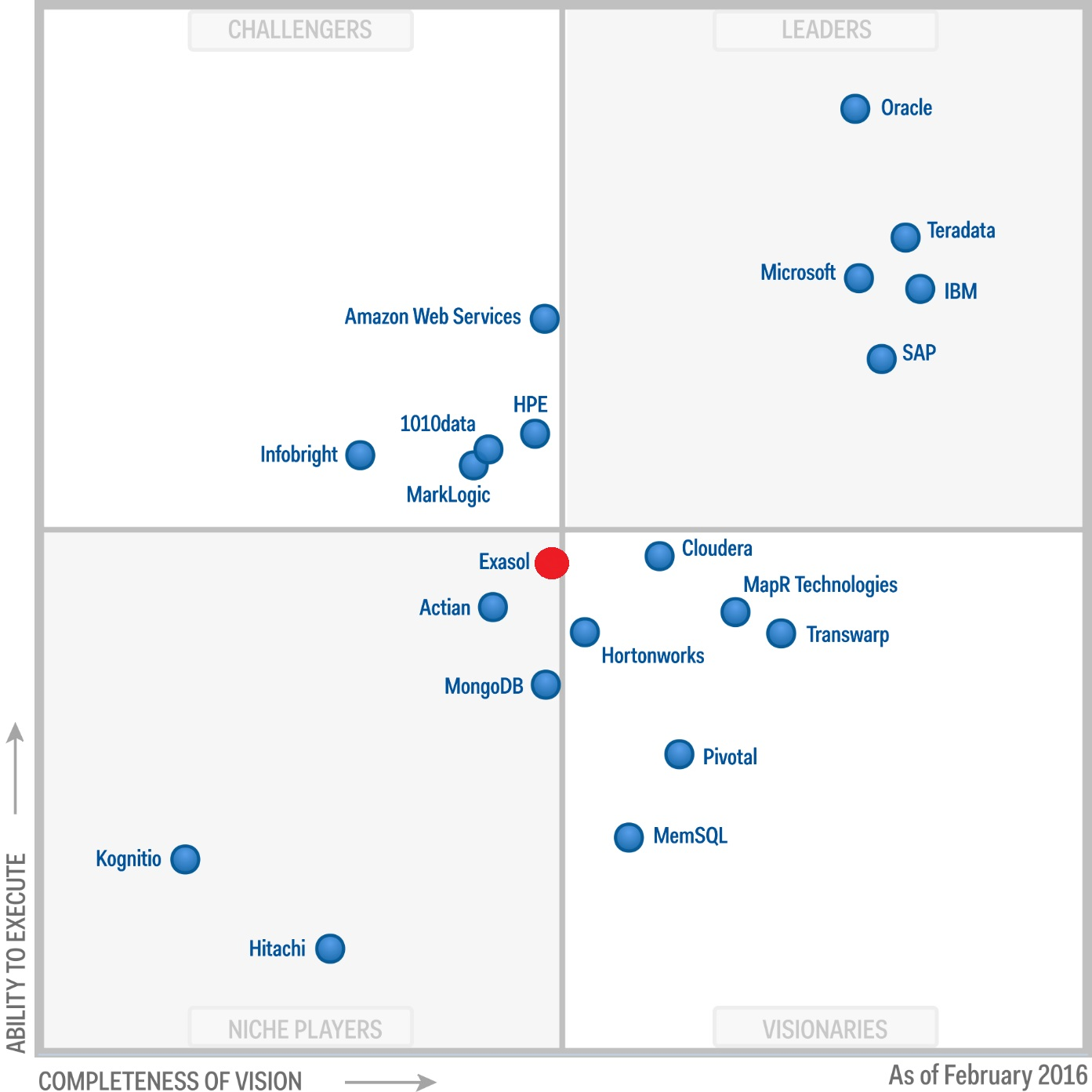
')
TPC-H Benchmark
For the performance test, I used the tpc-h benchmark , which is used to compare the performance of analytical systems and data warehouses. This benchmark is used by many manufacturers of both DBMS and server hardware. There are many results available on the tpc-h page , for publication of which it is necessary to fulfill all the requirements of the specification on 136 pages. I did not officially publish my test, so I strictly did not follow all the rules. In the rating of TPC-H - Top Ten Performance Results Results Exasol is the leader in performance (on volumes from 100 GB to 100 TB), which was the reason for my interest in this DBMS.
TPC-H allows you to generate data for 8 tables using the specified scale factor , which determines the approximate amount of data in gigabytes. I limited myself to 2 GB, since I tested Oracle In-Memory on this volume.

The benchmark includes 22 SQL queries of varying complexity. I note that the queries generated by the qgen utility need to be adjusted for the features of a specific DBMS, but in the Exasol case, the changes were minimal: replacing set rowcount with LIMIT clause and replacing keyword value . For the test, 2 types of load were generated:
- 8 virtual users in parallel 3 times in a circle perform all 22 requests
- 2 virtual users in parallel 12 times in a circle perform all 22 requests
As a result, in both cases, the execution time of 528 SQL queries was estimated. Those interested in DDL scripts for tables and SQL queries, write in the comments.
For the purposes of comparing databases or equipment for analytics (including for Big Data), I also recommend paying attention to another more recent benchmark - TPC-DS . It has more tables and significantly more queries - 99.
Test pad
A laptop with the following features:
Intel Core i5-4210 CPU 1.70GHz - 4 virt. processors; DDR3 16 Gb; SSD Disk.
OS:
MS Windows 8.1 x64
VMware Workstation 12 Player
Virtual OS: CentOS 6.8 (Memory: 8 Gb; Processors: 4)
DBMS:
EXASOL V6 Free Small Business Edition rc1 ( single node )
Loading data into Exasol database
I downloaded the data from text files using the EXAplus utility. Download script:
IMPORT INTO TPH.LINEITEM FROM LOCAL CSV FILE 'D:\lineitem.dsv' ENCODING = 'UTF-8' ROW SEPARATOR = 'CRLF' COLUMN SEPARATOR = '|' SKIP = 1 REJECT LIMIT 0; Download time for all files was 3 minutes. 37 sec I also note that a very pleasant impression was left by the documentation with many examples. So, it describes a number of alternative ways to load data: directly from various DBMS, using ETL tools and others.
The following table provides information on how the data is organized in Exasol and Oracle In-Memory:
| Exasol | Oracle IM | |||||||
|---|---|---|---|---|---|---|---|---|
| Table | Number of lines | Volume of raw data (Mb) | The amount of tables in memory (MB) | Coefficient compression | Number of indices | The amount of indexes in memory (MB) | The amount of tables in memory (MB) | Coefficient compression |
| LINEITEM | 11,996,782 | 1 562.89 | 432.5 | 3.61 | four | 109.32 | 474.63 | 3.29 |
| ORDERS | 3,000,000 | 307.25 | 97.98 | 3.14 | 2 | 20.15 | 264.38 | 1.16 |
| PARTSUPP | 1,600,000 | 118.06 | 40.46 | 2.92 | 2 | 5.24 | 72.75 | 1.62 |
| Custom | 300,000 | 39.57 | 20.99 | 1.89 | 2 | 1.42 | 32.5 | 1.22 |
| PART | 400,000 | 51.72 | 10.06 | 5.14 | one | 1.48 | 20.5 | 2.52 |
| SUPPLIER | 20,000 | 2.55 | 2.37 | 1.08 | 4.5 | 0.57 | ||
| NATION | 25 | 0 | 0.01 | 0.00 | 1.13 | 0.00 | ||
| REGION | five | 0 | 0.01 | 0.00 | 1.13 | 0.00 | ||
| TOTAL | 17,316,812 | 2,082.04 | 604.38 | 3.44 | eleven | 137.61 | 871.52 | 2.39 |
This information in Exasol can be found in the SYS.EXA_ALL_OBJECT_SIZES and SYS.EXA_ALL_INDICES system tables.
Test results
| Oracle IM | Exasol | |
|---|---|---|
| 8 sessions (1st launch), sec. | 386 | 165 |
| 8 sessions (2nd launch), sec. | ~ 386 | thirty |
| 2 sessions (1st launch), sec. | 787 | 87 |
| 2 sessions (2nd launch), sec. | ~ 787 | 29 |
Thus, we see that this test on Exasol is performed faster relative to Oracle IM at the 1st launch and much faster from the 2nd run. Acceleration of repeated SQL queries in Exasol is provided by automatically creating indexes. 11 indexes occupied about 23% in RAM, relative to the size of the tables themselves, which, in my opinion, is worth such an acceleration. I note that Exasol does not allow managing indexes. Let me give you the translation of the phrase from the documentation on the topic of optimization:
EXASolution deliberately hides complex performance tuning mechanisms for clients, such as, for example, creating various types of indexes, calculating statistics on tables, etc. Requests in EXASolution are analyzed with the help of the optimizer and actions necessary for optimization are performed in a fully automatic mode.
Also, by the results of the execution, it is clear that in my case, Oracle has better parallelized queries (8 sessions versus 2). I have not yet understood the reasons for this.
Exasol in the cloud
For those who want to independently assess the performance of Exasol without the need to install a virtual OS and download data, there is a demo Exasol in the cloud . After registration, I was granted access for 2 weeks to a cluster of 5 servers. There is available TPCH scheme with Scale Factor = 50 (50 Gb, ~ 433 million records). The 2nd launch of my test with 2 sessions on this data took about 2 minutes.
Finally
For myself, I concluded that Exasol DBMS is a great option for building a data warehouse and analytical system on it. Unlike the generic Oracle DB, Exasol is designed for analytics. You can bring an analogy with cars: for fishing trips it is good to have an SUV, and for moving around the city a compact passenger car.
As in the previous article, I urge everyone to draw any serious conclusions only after tests on your specific cases.
That's all for now, next in line is the test for HPE Vertica.
PS: I would be very grateful if the guys from Tinkoff Bank (@Kapustor) share information about their final choice , and Badoo (@wildraid) with the project news.
Source: https://habr.com/ru/post/318416/
All Articles