Admin Generator
Briefly, the essence of the problem: you needed a lot of admins, wrote the admin generator.

How does it work:
| Content:
|
How did it start
The fact is that I constantly had to impose admins for different services. New project, new server, new admin panel. Sometimes they were written from scratch, sometimes they were copied. Somewhere on the 13th admin I am despondent. I wanted to make a difference. Therefore, a new admin panel for the statistics department was created in the style of 98 Windows. Further, urgently, using the “budding” method, the admin panel of the licensing department was obtained, followed by the admin panel of the new gaming portal.
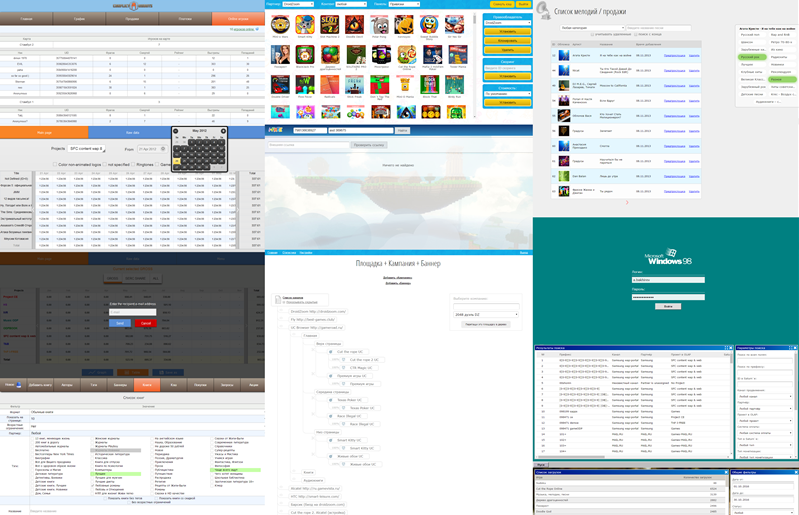
By this point, it became clear that some components are the same in all projects. Yes, and examples of use are also repeated:
- display the list;
- create / edit / delete item;
- assign a one-to-many relationship or many-to-many;
Next, a generator was written that, using templates, created the main code base. It is clear that all the "Wishlist" had to finish manually, but it was already a big step forward. After another three admins, it became clear that you need to generate not only the layout, but, preferably, both the server API and the database schema. This was not necessary in all projects, but in the fleeting “chick chick and production” was the very thing. Since different admin branches received fixes of different bugs, by the end of the summer it became obvious that it would be very good to merge all the fixes into one branch and update the generator qualitatively. This is what I began to do in the evenings and weekends.

Scalable copy / past level of admin of the first version generator

Are there ready admins and admin generators?
Yes , thousands of them . What is wrong with them:
- Clearance for a specific language or framework
For example, if you are using Laravel (PHP framework), you can use SleepingOwl. But if you have a backend on Java, then you can’t tie it without PHP.
- Solidity
Solidity follows from the previous paragraph. On the one hand, there can be a very cool system that dynamically changes the admin area, depending on the database schema. On the other hand, you can not remove this link. If you only need layout, it will hurt. It will also be painful when you want to connect the admin panel to your authorization system (in many large offices there are single authorization systems that control access to all systems of all users from one management point).
') - Clearance for sites
Probably half of the admin generators collect different variations of CMS systems. Some of them are very cool, but they are fundamentally not suitable for content management. If you drive a database of books into them, then it will be very painful to just pick up and throw 100 books into categories.
- Difficulty customization
Well, this is so clear. "You can not make a universal admin panel, each project is individual" (c).
What is very much missing in the admin area:
The ability to create a many-to-many relationship without switching to content editing mode. Example: there is a list of 100 games, you need to quickly tag them. In most admins, you need to open "game editing", put down a tag, return to the "game list".
The ability to batch affixing, deleting or editing. Example: select 15 banners and immediately assign them another promotion channel.
No logging. Example: we look at the content and want to immediately find out who edited it and when, and what specifically changed it.
The ability to duplicate an object and all its records with one click. Example: make a copy of an advertising company with all its banners and sites.
The ability to import / export data to Excel. Example: managers need one-time verification of content and sales in Excel, or send a list of something to partners.
Complex search filters (by group of properties and with an exception). Example: select all books from the “Classic” and “Novels” categories, except for those whose id: 20, 30, 65, and those who are marked with the “Sales hit” tag. In SQL, we will do this on the fly, and for managers in admin, filters, as a rule, will not allow such tricks.
I decided to fix these problems. It is clear that in fact, if you raise the question of code generation, then the "hotele" becomes even more. Here we need the output of statistics, which pulls the analysis of the data, and the tools to add a “business logic” to process the influence of data on each other, etc. The topic is very extensive, but in view of the limitations of my motivation and man-hours of development, I cannot implement all the projects. While I would like to finish at least the minimum basic functionality.
What exactly can be done?
Looking ahead, login / password: demodemo / qwerty123456 and set the rights for viewing only (if someone breaks and the demos become useless ahead of time)

Price
Let's start with the simple. Here one guy trades wholesale radio parts. We urgently need to withdraw the price on the site with the search. He doesn't have any 1C-warehouse. Out, brought out: https://goo.gl/OIPQXv
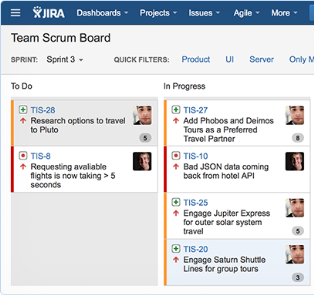
Parody JIRA
By tradition, JavaScript developers TODO sheet is supposed to write. Let's write a todo list of group companies. That there were subsidiaries, divisions, departments. And inside the departments there are already tasks. Tasks are scattered on employees. Each employee has two sheets: current tasks and a queue of tasks for the future. Akhalay-makhalay, ready: https://goo.gl/6UWqRn (demodemo / qwerty123456)
Yes of course. We also need comments on the tasks and so that the files can be attached. This is the minimum set. But this admin panel was generated in the previous version, which has not yet supported this. The new one has already been fixed.

CRM
We want our CRM. There will be companies, their offices, and key individuals scattered around the offices. We can look at the description of the company or the dossier on each key person with whom our manager directly conducts work (such as: client card). Next, you need the ability to create an "event" associated with a key person (for example: a call, a letter, a meeting). Let there be separate lists: what we have to do now, what we expect from the client, a list of jambs in our relationship. Um ... weakly just seven objects. Let's add separate entities with different types of clients (private, legal entities, etc.) and division by profile (carriers, tour operators, hotels, etc.). Chik-chik, hugged: https://goo.gl/OcJU8g (demodemo / qwerty123456)
Probably, we still need all sorts of reports, bills and a warehouse of goods, but on the one hand, I can’t even imagine how bookkeeping and warehouse work, on the other hand, maybe they should make a separate admin panel, since These are other departments with other business processes.
Yes, of course, we also need integration with PBX, advertising platforms, and electronic mail. But this is not a “chik-chik demo” in 30 minutes.
JSON at the entrance - NSI editor at the output
In general, the essence of this - it is the editors of the nomenclature and reference information (NSI). The closer your project is to the NSI editor, the more you get out of the box. Data visualization, analytics and logic will have to be written for now.
But even so, you can sketch a la protodim ERP-system. Actually, the awareness of this very motivated to further action. Further, by searching and viewing different demos, it became clear that:
many ERP systems of the “start-up” level are not much superior in functionality to the “chik-chik demo”. But because of the kodo-generation, the “chik-chik demo” can greatly surpass them.
Many ERP systems are built on the same principle of code-generation and deployment of a heap of configs. For example, there was such a thing “Etalon”, which, judging by the descriptions, was one-on-one like this bike, only under DOS. Again - thousands of them.
Why do you need it?
Suppose you write in Java, and you are constantly tormented by Angulyar. Here you can generate admin panel and do not climb into the front. Well, or another option - you need to create a lot of tables for your architecture (yes, yes, I know that you, Java, you can roll out a scheme from a class and vice versa - generate a class according to the database schema), but suddenly not everyone can. Or the scheme will need to roll the architect who does not write in Java, but only works with the base. Or you generally have a clean front and cannot master relational databases - here, at least, there will be at least some indices (although it is clear that the database schema is locked up with its “denormalization”, but suddenly). Well, or your hands are burning with the desire to nag start-up “rocket sains”, and there is no desire to engage in everyday life to create the project infrastructure.
Well for home projects from three tables come down. We have a little project, a different story.
No :) Because Since the code generation and admin composition are slightly less than completely from the configs, then you can deploy a project of 1000 objects. Another question - why? Usually there are more than 20 entities in one project - pain (there will already be from 40 to 100 tables in the database). Therefore, large projects are divided into microservices, and microservice is already in the region of 100 tables.
Plus, we can set separate settings for connecting to the database, not only for each entity, but also for its logs. Consequently, “out of the box” we can write logs in a separate database and operate with entities from different databases in the same admin panel.
Plus, the authorization was originally made by a separate module, just because the admin panel is collected on the pipeline and there is a separate access control system (hello to fans of ESIA, OIB `Sonat` % , your %_system_access control% ).
A little about how it works and how much it weighs
First we need to describe all the entities and their connections in the form of JSON. This is one of the most difficult stages.
{ "objects": [ { "id": "distributionChannel", "name": { "logic": "DistributionChannel", "logicSmall": "distributionChannel", "layout": "distribution_channel" }, "properties": { "create": { "name": { "tag": "input", "type": "string", "min": 1, "max": 50 }, "description": { "tag": "textarea", "type": "string", "min": 1, "max": 500 } }, "update": { "name": { "tag": "input", "type": "string", "min": 1, "max": 50 }, "description": { "tag": "textarea", "type": "string", "min": 1, "max": 500 } }, "search": {} }, "visualization": { "main": { "name": { "type": "string", "min": 0, "max": 50 } }, "history": { "name": { "type": "string", "min": 0, "max": 50 } } } }, ... Next, run the node and create more detailed configs.
node config
{ "objects": [ { "id": "distributionChannel", "name": { "logic": "DistributionChannel", "logicSmall": "distributionChannel", "layout": "distribution_channel" }, "aside": [ { "id": "create", "title": " DistributionChannel", "buttons": [ { "tag":"popup_button", "icon": "menu", "value":"", "id":"distribution_channel_aside_create_button_popup_menu" }, { "tag":"popup_button", "icon": "search", "value":"", "id":"distribution_channel_aside_create_button_popup_search" } ], "content": [ { "tag":"input", "type":"string", "min":1, "max":50, "id":"distribution_channel_aside_create_name" }, { "tag":"textarea", "type":"string", "min":1, "max":500, "id":"distribution_channel_aside_create_description" }, { "tag":"button", "title":"", "id":"distribution_channel_aside_create_button_create" } ] } We can rearrange the fields, add or cut something. Next, we already generate the code (which, for the most part, is also configs files)
node sql node nodejs node admin (function () { "use strict"; function ToggleStyleContentSearchConfig() { return { common: [ { id: "content__search__processing", className: "hidden" }, { id: "content__search__not_found", className: "hidden" }, { id: "content__search__result", className: "hidden" } ], processing: [ { id: "content__search__processing", className: "loading__icon search_status__loading" } ], notFound: [ { id: "content__search__not_found", className: "search_status__message" } ], result: [ { id: "content__search__result", className: "search__container__result" } ] }; } module.exports = ToggleStyleContentSearchConfig; })(); When the files are ready, we execute the generated SQL (to create a schema in the database). Copy the server files to a separate folder. Deploy It remains to collect statics
gulp gulp easy Statics will be collected in one HTML file, which will need to be uploaded to the server. If everything went well, you can try to relieve the static (-40% without or -8% with gzip)
gulp hard Some numbers:
- Database (now PostgreSQL, I plan to add MySQL)
1 entity = (1 table of objects + table of logs) + n * (connection table many to many + table of logs);
1 entity = 5 procedures for an object (creating + editing + deleting + searching + getting one object) + 4 log procedures (creating + deleting + searching + getting one log) + n * procedures for links (creating + deleting + searching) + n * logs for links (create + delete + search);
Total: (2 + n * 2) tables and (9 + (n * 3 * 3)) procedures, where n is the number of many-to-many connections
- Server (now NodeJS, I plan to add PHP)
Only six files, since everything went well with an instance of the same class with configs.
- Client (JS Vanilla)
1 Entity = ~ 10 HTML files + ~ 50 JS + n * files (~ 25 files for many-to-many links)
Total: A model of 12 entities will have approximately 50 tables, 160 procedures, 1000 static files (HTML + CSS + JS). Static after assembly and compression will weigh ~ 1 MB (all in one HTML file). There is also a “miracle plugin” that can be added after the Google compiler to ~ 600kb, and after the gzip arrives at the client ~ 85kb, we replace the gzip with brotli, and we boost it to 79kb . Most of the project files (from 85%) are similar configs for JSON in a wrapper. Therefore, the project can be very flexibly set up after file generation, and very tightly compressed on the assembly , and add copy / past function with search and replace by folder .
The principles that formed the basis of the bike:
Layout is a single HTML file that is not associated with the server. The only thing that binds them is the format of AJAX requests and responses. Want your backend - boldly replace.
The backend does not know the structure of the database, but it knows the names of the stored and the arguments. Want your database schema - write your own.
Anything that can be described by configs should be described by configs. Usually they make up more than 85% of the project files (the more entities, the greater the percentage).
All files and configs should be decomposed so that the new functionality can be added to the copy / past of the desired folder. It is clear that something will still have to fix hands in the code, but the less of these moments - the better.
Not really. This argument is appropriate, if you store business logic in storage - then yes. But there is no business logic. The whole essence of the store: give, create, or change the record, without any logic. Well, logging is not through triggers, but only upon request by the server of the corresponding procedure. The question arises: “What if we want to change the database? Hranimki will have to be rewritten, and if through ORM it is not. ”Well, personally, I, and none of my friends, have come across the fact that the project changes the database on the fly. And if such a situation arises, then, most likely, “rewriting ten patterns of generation of stored data into another subset of the SQL language” will be the least problem.
Current status of the project:
in September, almost from scratch had to redo everything. But the search became better, there were logs of objects, design, etc.
In November, features and the first two services with a new base began to appear. Left-handed mode, position changes, link log, batch processing, etc.
in December, it was necessary to rewrite the server, the base and put on the front rocking up. I thought that before the end of December I would have time to build a stable version, but I did not have time. Here, communication with the base has become strictly through procedures, search by groups, search with exceptions, the ability to add comments, etc.
Implemented by:
- create / edit / delete entity;
- search with filters, sorting and page output;
- creating / editing a simple connection between two entities;
- the ability to set / change position;
- logging the creation / editing of an entity;
- logging of creation / editing of a simple connection of two entities;
- view logs;
- generation of custom selects (the list of values of which is sewn up and not loaded);
- batch add / delete links (many to many) for entities;
- simlink on the field to skip its creation (for date-binding, an example: one partner field, for all entities in the small panels). referenceElementId;
- generation of independent entity lists;
- the ability to change the size of the working area;
- Search by id list of objects;
- automatic adjustment of the number of lines when searching;
- highlighting a search query in the search results;
- display mode "for left-handers";
- insert search (create / edit) in a random place. For example: comments to taske;
Small bugs:
- search error: filter ref_channel_id. It is necessary to generate LEFT JOIN requests for such searches and filters + ext. fields in the search form;
- repair the output of the names of objects in the search for ref_ links (example lock, column cost);
- displaying server error details;
- file stripping + new project structure. It is necessary to make a cleaner final sorts assembly;
- correct the behavior of batch object allocation;
- fix the calculation of the number of search string for the screen;
- data typing in queries;
- checking the file before overwriting always writes an error to the console (which in fact does not exist). It is annoying, but not critical;
Not implemented functionality:
- position change logging;
- display / edit nested arrays (for example: a list of translations, instead of a name or a list of payments, instead of a payment method);
- determining the order of loading entities;
- definition of related fields (autoswitch all, when changing one. For example: changing partner or promotion channel);
- download files on the fly;
- file download "list";
- upload search results to CSV (export);
- Download results from CSV (import);
- copying is reverse / not reverse;
- add state recovery by logs (when the object state details have been opened);
- batch deletion of entities;
- description and removal of the post-compressor in a separate project;
- convenient generator for config as a separate application;
- correct logging object history. The field is_remove make change_type (0 - created, 1 - edited, 2 - deleted)
- localization;
- adaptation for mobile phones / tablets;
- creating a client window;
- search filters as an array, not a single value (multiple “including” and “excluding” samples);
- the ability to select the display screen (main / aside) for each type of operation;
- subfolders through the parent_id field. There is a field - there is a folder, there is a change in the search filter;
- keyboard control;
- redo the welcome screen. Put on it a graph of the connection of the project entities (as in the banner admin);
- write a seo text;
- connect plugin pagination scrolled;
- consider an authorization system for third-party projects. Modify the authorization module (remove the Draft User);
Not implemented server functionality:
- comments to the tables in the database;
- checking the fields in the "service" object, and not when creating the "REST API";
- generation of documentation on API methods;
- authorization module that is not tied to Sonata;
- DB scheme tied to the access of Partners or with the presence of restrictions for users;
- PHP server generation;
The great advantage is that this is not a “theoretical development”. Each component was already in old projects or is on current ones. Accordingly, the list of "hotelok" and the order of their implementation is dictated by the pain of exploitation (well, the experience of the development of foreign admins generators) .
What are the plans for the next month:
finally build a stable version with proceduresRoll to PHP, because the server on the node in the usual shabashka not deploy. Yes, and maintain easier and cheaper. (Roughly speaking, for 1500 rubles. For a year it is already possible to deploy an admin panel for ~ 20 thousand records.)
add work with files
write a script to install out of the box, but now it takes half an hour to dig in to deploy the project
(and this despite the fact that I know every file in the project).
About UX
Writing the basic functionality is pretty boring. When I get bored, I switch to bugs and features. Here is one of them. There are right-side and left-side interfaces. Those who do localization - collect two options (hello badoo). I have + 2 more options: for left-handers and right-handers. The difference is that the interface is not completely mirrored, but only control panels. It is more convenient for Russian left-handed users to use mirrored control panels, but read the information in the tables from left to right. And left-handed Arab - on the contrary, the European layout of the panels, but the reverse order of the columns in the table.
Right-handed European

Lefty Arab
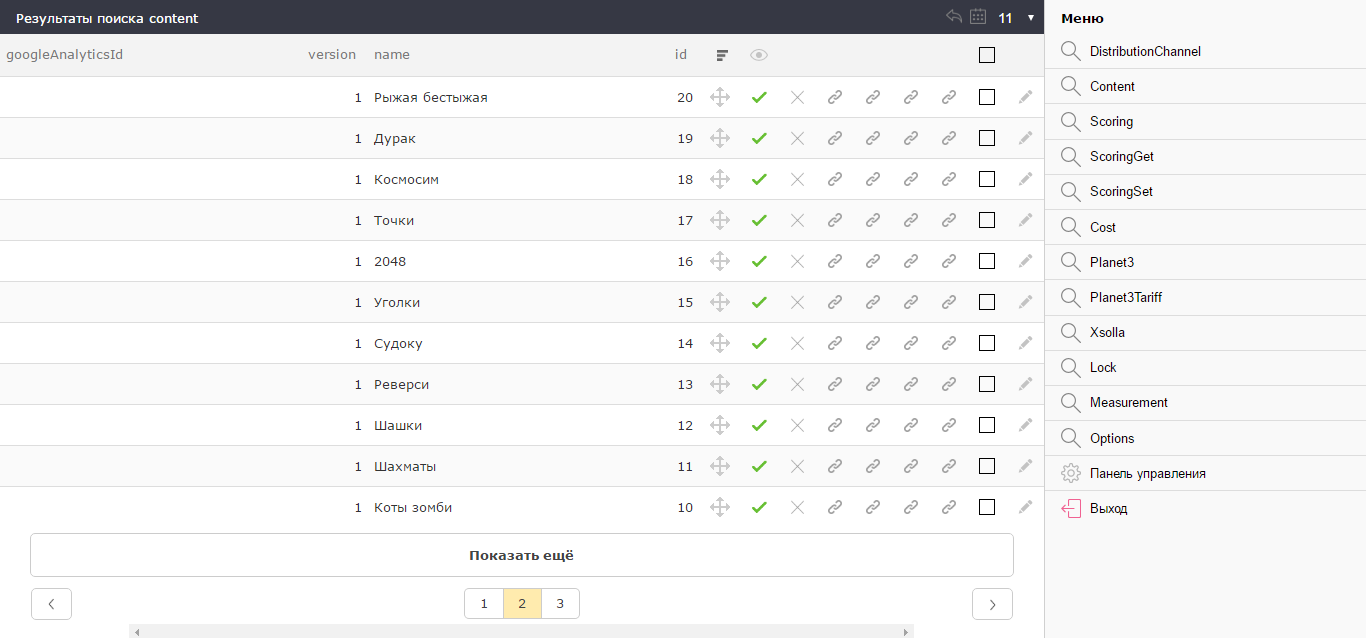
Left-handed european
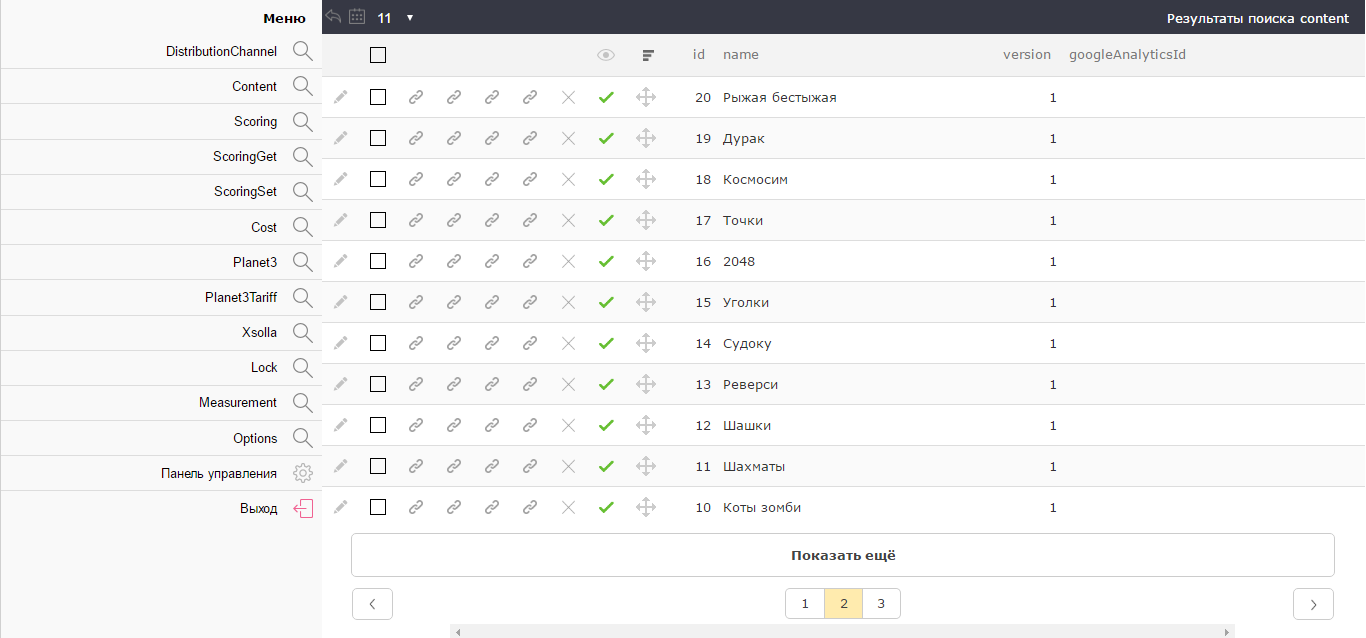
Right handed arab
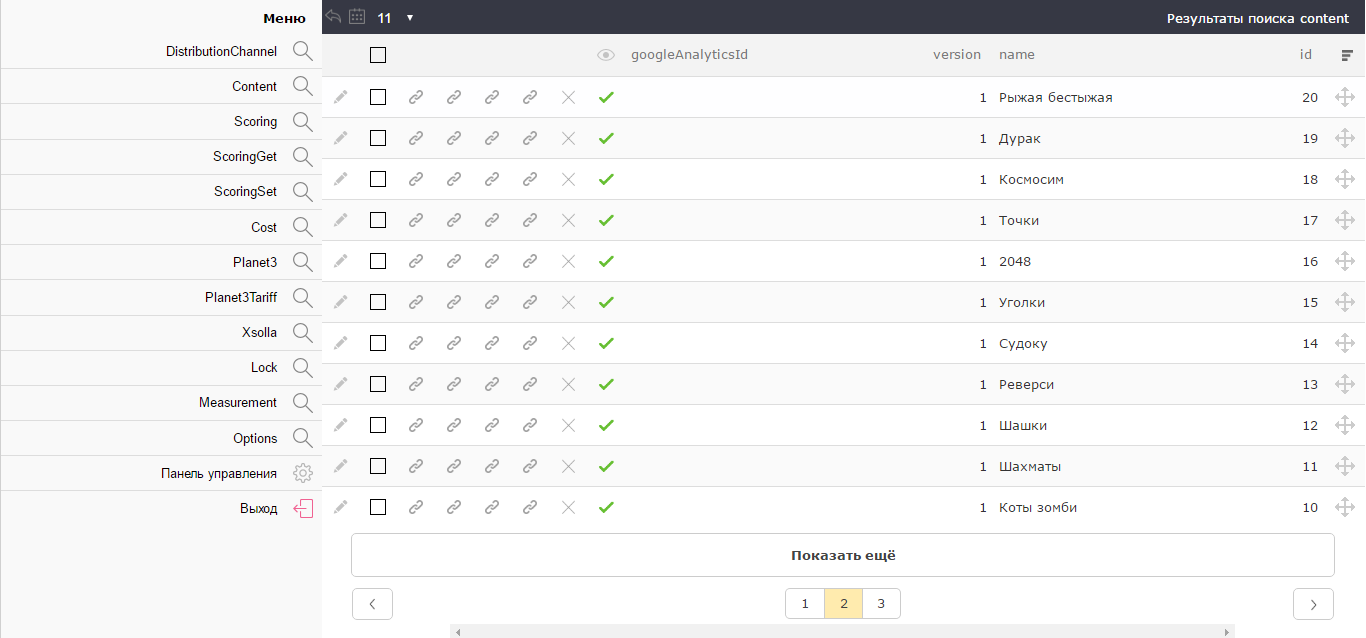
In different projects you need a different ratio of zones "search results" and "element editing". For example, in a book application for editing books there is a rather narrow panel on the right. And in the game application - it is better to change the game in the central part. It also affects the preferences of a particular manager who works with the project. Therefore, in the new version, the ratio of the “search” and “edit” zones can be changed in the settings.
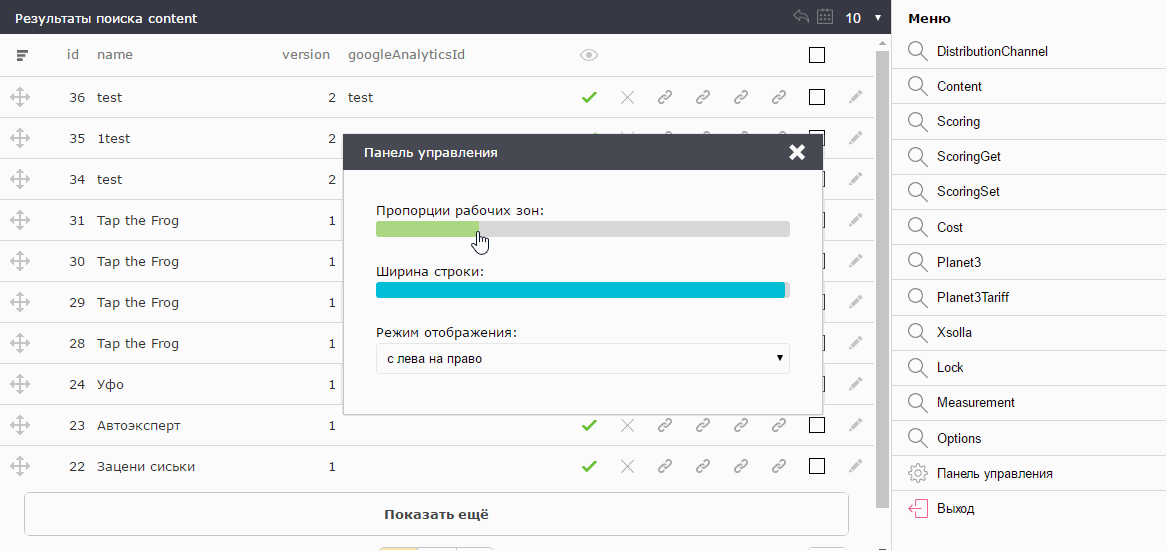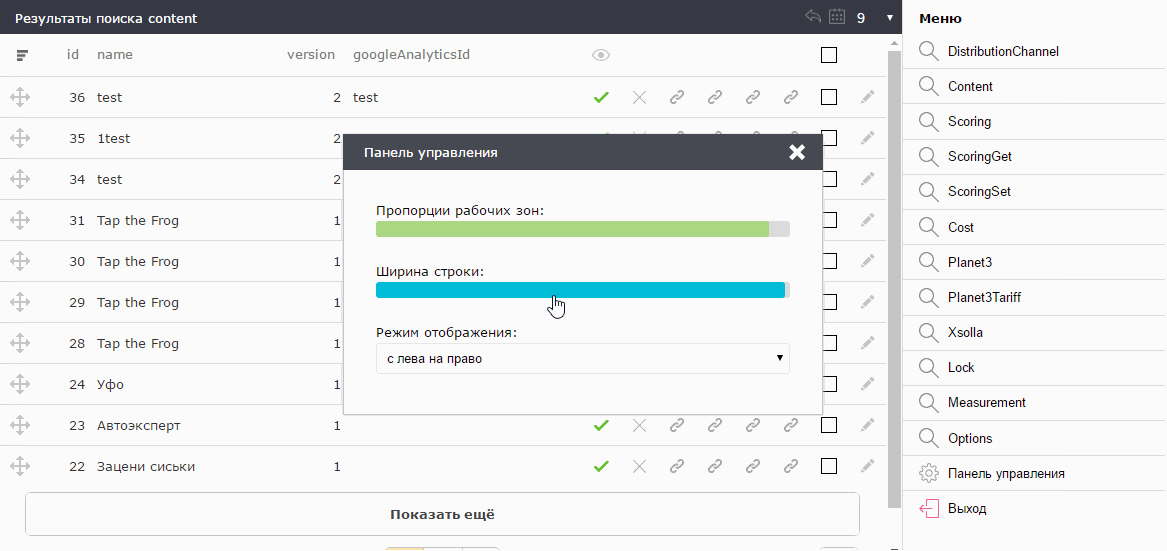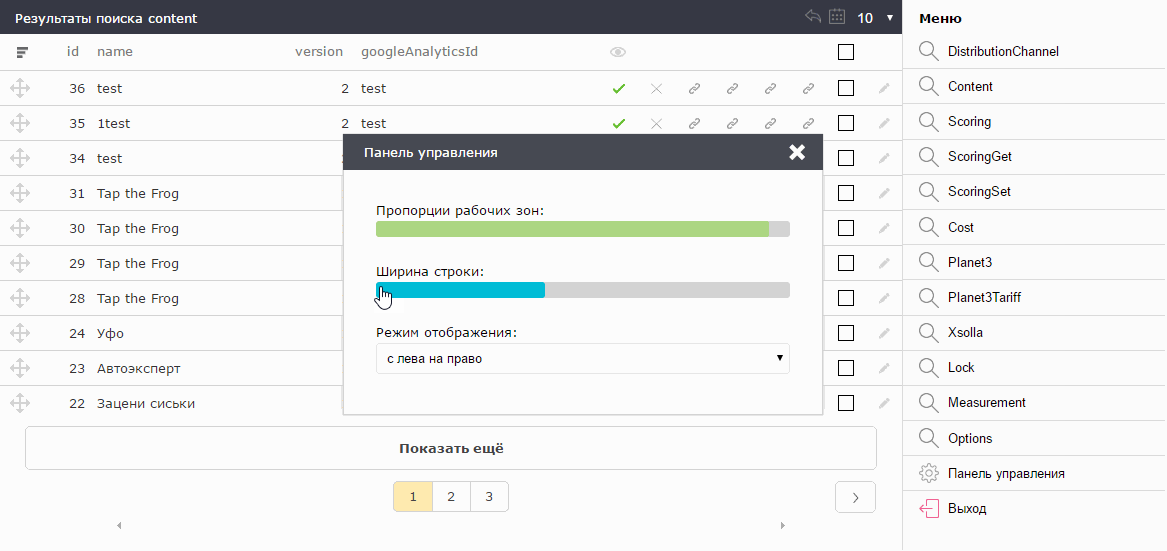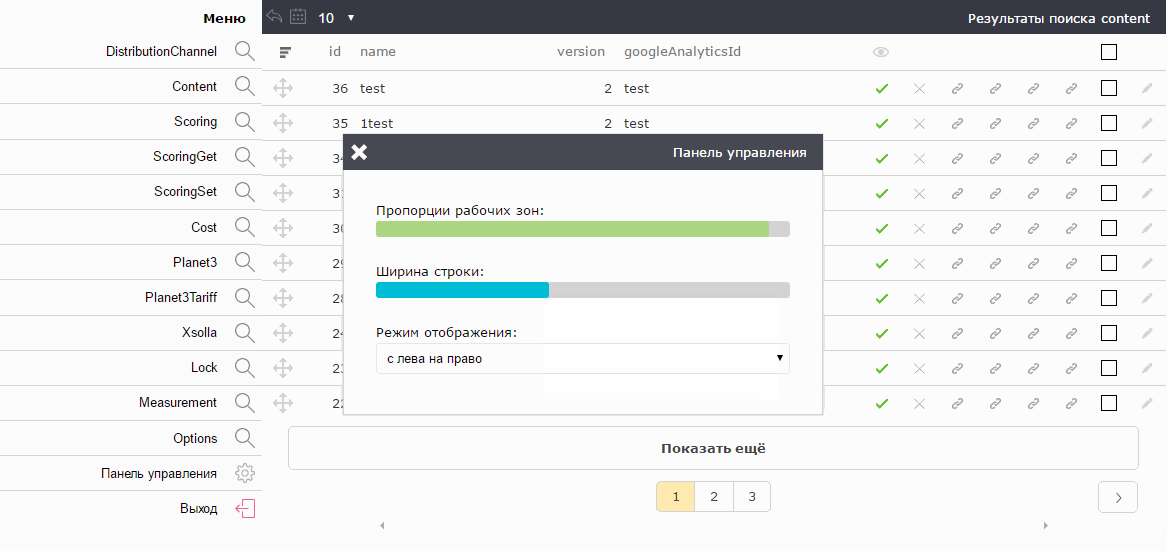
Those who work with statistics, as a rule, spend a lot of time in Excel or similar programs. They are accustomed to strings about 16px high. Those who work with various CMS sites and web snouts on bootstrap, are accustomed to the line height of 32px. Therefore, the line height is also rendered in the settings.
There is an opinion that scrolling is evil. Why it happened - the topic of a separate article. I agree with that. But to specify the exact number of lines that fit on the screen is impossible, because everyone has different monitors. Therefore, the admin panel at startup calculates the optimal number of lines for the current settings with this monitor. They are always exactly as much as the maximum fit on the screen without creating a vertical scroll.
Finally
What do you think, colleagues?
Cataloger books, parts, or any other regulatory information, with a web-muzzle nobody needs?
- it was already in django
- Where is the link to github?
- on a real project does not take off!
- Fu, rewrite for PHP, put a minus !!! 11
- where are the charts? stata on the main - this is the base!
- chop configs! = code-generation
- everything is buggy, the product is raw
- The interface is incomprehensible!
- why not React ʻa?
- it happened before…
- and where to download the installation file?
- no data analysis is needed!
- why not mongodb?
- LIKE is slow!
- and the documentation will be?
- Why is the test coverage zero?
- layout is not flexbox, kill yourself!
- Is there a version for mobile phones?
- article about anything!
- my layout has gone!
Source: https://habr.com/ru/post/318332/
All Articles