Idiom ranges
Idiom ranges are extremely successful iterator development. It allows you to write high-performance code that does not allocate memory, where it is not necessary, being at an extremely high level of abstraction. In addition, it makes libraries much more versatile and their interfaces flexible. Under the cat a brief description and practical examples of the use of idioms, performance tests, as well as a comparison with popular implementations of iterators in C ++ and C #.
Further in the article, instead of the English “range”, the well-established translation “range” will be used. It cuts a bit of hearing, and this word has many other meanings, but it is still better suited for Russian text.
Some theory
The article is extremely practical, but first we still synchronize the theory. First, an understanding of lazy computations is required. Secondly, structural typing is needed. And if you can read about lazy calculations on the wiki and everything is very clear there, then there are problems with the accuracy of formulations of structural typing. Very little is written on the wiki.
Here, by structural typing, we mean duck typing , but with verification at the compilation stage. This is how the templates work in C ++ and D, the interfaces in Go. That is, the function accepts arguments of all types, such that all the methods and operators used by the function can be called on the object. Unlike the more common nominative typing, where it is necessary to specify a list of implementable interfaces, the structural one does not impose any type declaration requirements. It is enough that with the object you can do what is used inside the function. However, compatibility checking does not occur at runtime during a dynamic invocation, but at compile time. If such a formulation is still not clear - it does not matter, practical application will be much clearer.
')
AB group calculation
Formulation of the problem
Consider one simple task. You need to write a function that calculates which AB group the user belongs to. With AB testing, we need to split all users into several random groups. Traditionally, this is done as follows: we consider the hash of the user id and the test id and take the remainder of the division by the number of groups. Hash gives some randomization, and the use of the id test makes the splitting different for different tests. If we discard all the details of the domain, we need a function that is formally described by the formula:
ab_group(groupId, userId, count) = hash(groupId + userId) % count , where groupId and userId are strings, and count is a positive number. Jenkins_one_at_a_time_hash is used as hash ().
Realization in the forehead
static uint32_t get_ab_group(const string& testId, const string& uid, size_t count) { string concat = testId + uid; uint32_t hashVal = string_hash32(concat.c_str(), concat.size()); return hashVal % count; } static uint32_t string_hash32 (const char *key, size_t len) { uint32_t hash, i; for (hash = i = 0; i < len; ++i) { hash += key[i]; hash += (hash << 10); hash ^= (hash >> 6); } hash += (hash << 3); hash ^= (hash >> 11); hash += (hash << 15); return hash; } The implementation of the hash function was honestly copied from somewhere, and everything else, as you see, requires only 3 lines of code. This implementation solves the problem: the tests pass, the results are the same as previously calculated. There is only one drawback - the speed of work. The choice of C ++ is justified by the need to use the function from the infinidb plugin. We needed to count the group on the fly for the entire user base. It was expected that the function would produce a speed of tens of millions per second, because the hash function worked with such speed.
Optimization
In order to understand what is slowing down, it was not even necessary to run the profiler. At the time of writing, it was clear that this would not work quickly because of one line:
string concat = testId + uid; Here is the creation of a new line with the allocation of memory for it and then copying. At the same time, we release the memory immediately upon exiting the function. That is, in fact, the row object in the heap is not needed. You can of course allocate memory on the stack, but this approach does not pretend to a general solution.
A programmer who was not familiar with the idiom of ranges suggested a completely classical solution. Since only the first part of the hash calculation function depends on the string itself, it can be put into a separate function that returns the intermediate result. It can be called several times for different lines, passing the intermediate result from the call to the call. Well, in the end to call a finalizer, which will give the final hash.
static uint32_t string_hash32_start(uint32_t hash, const char *key, size_t len) { for(uint32_t i = 0; i < len; ++i) { hash += key[i]; hash += (hash << 10); hash ^= (hash >> 6); } return hash; } static uint32_t string_hash32_end(uint32_t hash) { hash += (hash << 3); hash ^= (hash >> 11); hash += (hash << 15); return hash; } static uint32_t get_ab_group(const string& testId, const string& uid, size_t count) { uint32_t hash = 0; hash = string_hash32_start(hash, test_id); hash = string_hash32_start(hash, uid); hash = string_hash32_end(hash); return hashVal % count; } The approach is quite understandable, a lot, where it is done. That's just not very well read, and the original function had to be disassembled. But it is not always possible to do so. Require an algorithm of several passes over the entire line or a passage in the opposite direction, and such an approach would no longer be implementable.
Ranges
In order to make the function truly generic, we need a minimum of changes. We do not touch the algorithm at all, just change the type of the argument from the sishna string to the pattern:
template <typename Range> static uint32_t string_hash32_v3 (Range r) { uint32_t hash = 0; for (const char c : r) { hash += c; hash += (hash << 10); hash ^= (hash >> 6); } hash += (hash << 3); hash ^= (hash >> 11); hash += (hash << 15); return hash; } That is, the function began to accept any object, foreach on which gives char. Any container from std is suitable for this role, with the argument char. A sishnaya zero-terminated string is also easily wrapped in such a container. But, most importantly, you can now pass a lazy generator.
Take the function concat from the ranges-v3 library. This function returns an object that supports the iteration interface on it and gives element-wise the contents of all collections passed to it. First goes through the first, then the second, and so on. That is, it looks like the string a + b, only it does not allocate memory, but simply refers to the original lines. And since it quacks like a duck, we will use it like a duck:
static uint32_t get_ab_group_ranges_v3(const string& testId, const string& uid, size_t count) { auto concat = concat(testId, uid); uint32_t hashVal = string_hash32_v3(concat); return hashVal % count; } It looks the same as the very first non-optimized version, just instead of the + operator, we called the function concat from the ranges-v3 library. But it works significantly faster.
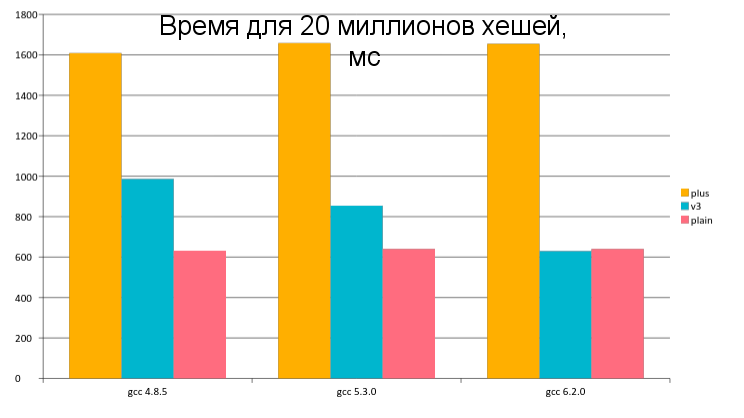
Time for 20 million hashes, ms
| gcc 4.8.5 | gcc 5.3.0 | gcc 6.2.0 | |
| plus | 1609 | 1658 | 1655 |
| v3 | 987 | 855 | 630 |
| plain | 631 | 640 | 640 |
Explanation of the table. plus is the very first implementation using string concatenation. v3 - implementation on ranges. plain is the first optimized version, with a split of hashing into start and end.
Sources
Unfortunately, I am now on vacation and do not have access to the source code of this benchmark. If possible, they will be posted on github. While I can offer only independent experiments, the benefit is that ranges-v3 are header-only and it is not difficult to use it.
We can observe an interesting phenomenon: with GCC6, a generic version with ranges works as fast as an optimized, highly specialized one. Of course, the optimizer did a good job here. You can clearly see the development of optimizations from gcc4 to gcc5 and 6.
All iterators and method calls on them were inline. The extra conditions in the loop are reordered and simplified. As a result, on some compilers, the disassembler of both versions shows the same thing. And on the GCC6, the range version is even slightly faster. I didn’t study this phenomenon, but I’m sure I’m working correctly, so I can only rejoice at the development of technology and advise using the latest versions of compilers.
Sometimes the optimizer works wonders. For example, in the image processing library it can combine successive transformations into one faster one: 2 turns can be assembled into one, any affine transformations can be assembled into one. The translation of the original article was on Habré .
From interesting examples: 4 rotations by 90 degrees, the compiler was thrown out of the code altogether.
Search for substrings
As shown in the examples and benchmarks, the ranges are fast. However, their main advantage is that they are comfortable and fast at the same time. Well, or at least show an excellent ratio of ease of writing to speed.
Consider the following task: to find all the occurrences of numbers in a given string. Next, D is used to increase readability, not C ++. For such a function, you can offer two classic interfaces. Convenient:
double[] allNumbersArr(string input); And fast:
Nullable!double findNumber(string input, ref size_t begin); With convenient everything is clear: the input line, the output array of numbers. The disadvantage is that you need to create an array for the result. And create only in a heap.
C fast is harder. At first glance, it is not very clear how to use it. It returns one value and that is not always, sometimes it can return null. It is assumed that the function will be called in a loop to crawl all values and will receive a label from where to start the search.
string test = "123 gfd 44"; size_t begin = 0; Nullable!double iter; while (iter = findNumber(test, begin), !iter.isNull) { double val = iter.get; writeln(val); } Not the most intuitive and readable way. But it does not require arrays and works faster. True, every time you use a function, you will have to write this not the most trivial while, not to forget that you need a begin variable and how to use Nullable. In pure C, by the way, I would have to add a pointer to begin, and in the absence of Nullable, add another flag that they did not find anything. Well, or compare the resulting begin with a long string. In general, fast, but uncomfortable.
Ranges offer to combine convenience with speed. The implementation will look like this:
auto allNumbers(string input) { alias re = ctRegex!`\d+(\.\d+)?`; auto matches = matchAll(input, re); return matches.map!(a => a.hit.to!double); } The function returns a Voldemort type (a type that cannot be named, it does not have a name outside the map implementation). The matchAll function will return a lazy range, which will begin to search when it is first accessed. map is also lazy, so it will not touch matches until asked. That is, at the time the function is called, the search for all entries will not occur and an array will not be created for them. But the result looks like all occurrences of numbers. Examples of using:
auto toWrite = allNumbers("124 ads 85 3.14 43"); foreach (d; toWrite) { writeln(d); } Here writeln will go through all entries and print on the screen.
auto toSum = allNumbers("1 2 3 4 5"); writeln("sum is ", sum(toSum)); sum - standard library algorithm. Accepts a range of any numbers and, obviously, summarizes. Again, you have to go through all, but no arrays, at one time there is one double.
auto toCheck = allNumbers("1qwerty"); writeln("there are some ", !toCheck.empty); And then we generally just checked, and whether there are numbers in the string. In this case, the minimum required. If there are numbers, the search will stop at the first and empty returns false. A full line pass will only occur if there are no numbers. I think many people were pushing for performance problems because arrays were created to check for availability. As the most epic case:
bool exists = sql.query(“SELECT * FROM table”).count() > 0; Raised the entire table in memory only to check if it is not empty. Such code happens. And it is no longer possible to “razvidet”. From the sql query, the ranges, of course, will not save (nothing will help here at all), but in the case of strings or files, there will be no extra work.
It is important to note that the functions of the standard D library, as well as the ranges-v3 for C ++, as well as any good functions for working with ranges, do not indicate specific types. They are generalized to the limit, and you can concatenate regular arrays, lists, and hashes, and most importantly, other ranges. Nothing prevents the argument from passing the result of the algorithm, whether it be filtering, mapping, or another concatenation. In this sense, Range is an iterator development. They also build generalized algorithms like stl, and there is hope that stl2 will take ranges as a basis.
So far we have considered only two algorithms: search and union. In fact, there are a lot of lazy ranges. For D you can look at the list here and here . For C ++, the best source is the Ranges-V3 library.
A short overview of the most useful algorithms
iota is a generator of a sequence of natural numbers. From 0 to preset. There are versions for setting the step and the initial values.
chunks - split the input range into several others with a fixed length. Allows you to take care of non-multiple length, empty input data and so on. Very handy for working with APIs that limit the size of the input data (Facebook REST with restrictions on all bulk requests)
auto numbers = iota(35); foreach (chunk; numbers.chunks(10)) { writeln(chunk); } Displays
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] [20, 21, 22, 23, 24, 25, 26, 27, 28, 29] [30, 31, 32, 33, 34] enumerate - for the input range, creates a range from the element and its number in the source
zip - collects several ranges into the range, where in the first element a tuple from the first elements of the source, in the second from the second, and so on. Very handy for simultaneously iterating over collections of the same length.
repeat - repeat to infinity the specified value
take - take the specified number of elements
auto infPi = repeat(3.14); writeln(infPi.take(10)); [3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14] Benefits of structural typing
This paragraph is more likely to refer to structural typing in general than to ranges, but it still could not have done without them. Classic OOP "problem": you cannot pass an array of children to a function where an array of ancestors is expected. It is impossible not because the authors of languages are so bad, but because it will lead to logical errors. Suppose it would be possible. Arrays are usually passed by reference. Now we will transfer to the function, expecting an array of animals, an array of cats. And this function will take, but add a dog to the array! And at the exit we have an array of cats in which there is a dog. Const could solve the problem, but only this particular case, and I don’t want to prohibit the insertion of cats.
But you can always iterate and call methods of objects. With ranges on C ++, it would look like this:
class Animal { virtual void walk() {} }; class Cat : public Animal { void walk() override {} }; template <typename Range> void walkThemAll(Range animals) { for (auto animal : animals) { animal->walk(); } } void some() { walkThemAll(new Cat[100]); } Thanks to the Range template, it is typified by cats, and the dog cannot be shoved in there.
How is this different from iterators?
In the abstract, these are iterators. But this is theoretically, and there are many differences from existing implementations. From C ++ iterators ranges are consistent. They themselves know where they end and it’s very difficult to get an invalid range. An iterator in C ++ is rather a pointer, and a range is a reference to std :: vector.
In C #, iterators are more advanced and have no integrity problems. But there are several other fundamental differences. First, iterators in sharpe are just one kind of band - InputRange. It is an entity that is iterated in one direction without the ability to go back or at least copy the current state. In addition to them, there are ForwardRange (with state preservation), BidirectionalRange (ability to iterate in the opposite direction), RandomAccessRange (random access through the operator []), OutputRange (write without reading). All this is not even theoretically covered by a single yield return.
Secondly, performance. The virtual machine will have to create a miracle to make the optimizations available in C ++. And all because of the gap of execution and switching between contexts. And generics, in contrast to templates, do not generate code and cannot optimize particular cases. And as the C ++ example shows, these optimizations speed up the code many times over. My preliminary benchmarks, in which I am not sure, show that an attempt to independently implement concat fails due to speed. Plain concatenation is simply faster. Most likely jit does a good job with working on a solid line, and GC with reuse of memory. But millions of unnecessary switching and function calls to throw no one.
Third, ready-made algorithms. On D or C ++ there is already a mass of lazy algorithms. Sharpe boasts only generators. The presence of agreements allows you to write a code like
array.sort.chunks(10).map(a=>sum(a)).enumerate; The call chain is endless. In C ++, there is no such call through a dot, but there is an operator | overloaded for ranges. Therefore, you can do the same thing, just replacing. on |.
And in go, perl, #my_favorite_lang is also structural typing!
Yes, and it allows you to write something very similar. Not accepted, but you can do. This will not work quickly because it is the same as in C #. The go interfaces, like C # generics, use indirect calls instead of code generation. That is, each iteration will require at least 2 virtual calls. During the virtual call you can do several iterations with inline, so the difference with C ++ will be several times.
That's all, thank you for reading to here.
The material was prepared for the presentation at CrazyPanda and copied here as is. Distribution and copying by the author is not prohibited, but subject to the rules of habrahabr . If the habrasoobschestvo interested in the question, then perhaps continue to follow directly to the habr.
Related Links:
» Ericniebler.com/2013/11/07/input-iterators-vs-input-ranges
» Www.youtube.com/watch?v=mFUXNMfaciE
» Ericniebler.com/2015/02/03/iterators-plus-plus-part-1
» Github.com/ericniebler/range-v3
» Dlang.org/phobos/std_range.html
» Dlang.org/phobos/std_algorithm.html
Source: https://habr.com/ru/post/318266/
All Articles