Articles underlying Facebook's vision for computer vision
Do you know such a company - Facebook? Yes, yes, the one with a website of 1.6 billion users. And if you take all the post-congratulations on your birthday, your shameful children's photos (I have them), that distant relative, like your every status - and here you have a lot of data for analysis.
In terms of image analysis, Facebook has come a long way with convolutional neural networks (Convolutional Neural Network, CNN). In August, Facebook's Artificial Intelligence Unit (Facebook AI Research, abbreviated as FAIR) published a blog post about computer vision algorithms that underlie some of their image segmentation algorithms. In this post, we will summarize and explain the three articles referenced by this blog.
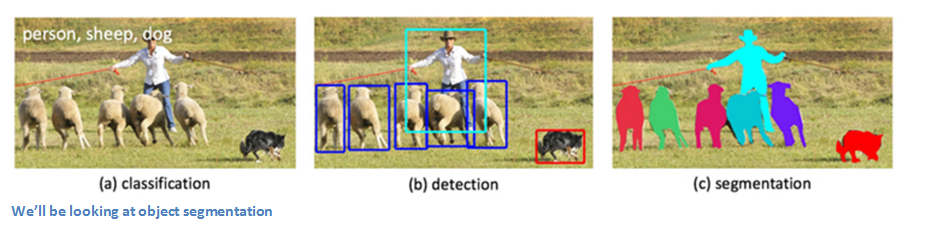
Normally FAIR uses the following sequence of algorithms. Images are fed to the DeepMask segmentation framework. The SharpMask algorithm is used to improve the segments selected in the first stage, then objects are classified using MultiPathNet. Let's take a look at how each of these components works separately.
')
This work, which belongs to Pedro Pinheiro, Roman Collobert, and Peter Dollar, is called “Learning to Segment Object Candidates”. To solve the problem of image segmentation, the authors propose an algorithm that, when receiving a fragment of an image, displays the object mask and the probability that the entire object is in the center of the fragment. This process is applied to the entire image so that a mask is created for each object. The entire process is carried out using just one CNN, since both components use the same network layers.
To begin with we will depict what we expect from the model. We want for the input image to get a set of masks or silhouettes of each object. We can present the original image as a set of fragments. For each input piece at the output, we obtain a binary mask containing the silhouette of the main object on it, as well as an estimate of how likely it is that this fragment contains the object (from -1 to 1).

Each teaching example should contain these three components (note: an example with probability 1 should contain a fragment in the center of which is an object that is contained in the image completely and on the same scale). The algorithm is applied to different parts of the image (the same set of fragments, which we mentioned earlier). The results are then combined to form one final image containing all the masks. Let's see what the algorithm consists of.

* Figure 1 . Above . Model architecture: after a general layer of extraction of characteristics, the model diverges into two branches. The upper branch predicts a segmentation mask for the object in the center, while the lower branch predicts the likelihood that the fragment contains the object.
From below . Examples of training triples: input fragment x, mask m, and label y. Green fragments contain objects that satisfy certain conditions and therefore are marked with y = 1. Note that the masks from the negative examples (red) are not used and are shown for illustration only.
The network was pre-trained in ImageNet image classification (Transfer Learning in action). The image passes through a VGG-like model (without fully connected layers) with eight 3x3 convolutional layers and five maxpool 2x2 layers. Depending on the size of the original image, you will get a certain amount of output (in this case, 512x14x14).
Input : 3 xhxw
Output : 512 xh / 16 xw / 16
Then the network is divided into two components described above. One of them assumes segmentation, while the second determines whether the desired object is in the image.
Now we take the output data, transfer it through the inner layer and the ReLU layer. Now we have a layer of w 'xh' (where w 'and h' are smaller than w and h of the original image) pixel classifiers, which determine whether a given pixel is part of an object in the center of the image (if the image size is 28x28, then the classifiers will be less than 784). Then we take the output values of the classifiers, using the bilinear interpolation method, increase the image resolution to the original one and get a binary mask (1 - if the pixel belongs to the desired object, 0 - if not).
The second component of the network determines whether the image contains an object of the desired scale in the center. By transmitting the output of VGG-like layers through a 2x2 maxpool layer, a dropout module and two fully connected layers, we can get our probability estimate.
Both components of the network are trained in parallel, since the loss function is the sum of the loss of logistic regression (the loss of Objectness Head plus the loss of applying Segmentation Head to each fragment). The error propagation algorithm runs either on an Objectness Head or on a Segmentation Head. To improve the model, we used the technique of extending the training set (Data Augmentation). The model was trained using the stochastic gradient descent method on an Nvidia Tesla K40m GPU for five days.
One convolutional neural network. We did not need an additional step to generate hypotheses of the location of the object (object proposals) or any complex learning process. This model has a certain simplicity, which provides network flexibility, as well as efficiency and speed.
The previous group of researchers (together with Tsung-Yi Lin) also authored the article entitled “Learning to Refine Object Segments”. As the name implies, this article talks about improving the masks created during the DeepMask stage. The main problem of DeepMask is that this model uses a simple network of direct distribution, which successfully creates “rough” masks, but does not perform segmentation with pixel accuracy. The reason for this is that, if you remember, in DeepMask there is a bilinear interpolation, which serves to fit the size of the original image. Therefore, compliance with real boundaries is very approximate. To solve this problem, the SharpMask model combines the information of low-level characteristics that we get from the first layers of the network with high-level information about the object, which comes from deeper layers. First, the model creates a coarse mask for each input fragment (the work of DeepMask), and then passes through several refinement modules. Consider this stage in more detail.

The SharpMask idea emerged from the following considerations: since in order to find the exact object mask we need object-level information (high-level), we need a downward approach that builds coarse segments first and then combines the important low-level information from the initial layers. As can be seen from the figure above, the original image first passes through DeepMask to obtain coarse segmentation, and then enters the input sequence of the refinement modules for a more accurate increase of the image to the size of the original.
Let us consider in more detail how the specifying module is arranged. The objective of this module is to resist the influence of subsampling layers (pooling layer) at the DeepMask stage (the layers that squeezed the 224x224 image to 14x14), increasing the dimension of the masks obtained taking into account the feature maps created during the ascending passage (we can call DeepMask the ascending passage, and SharpMask - downward). Mathematically speaking, a refinement module is a function that generates an extended mask M, that is, a function from the mask of the previous layer and a map of signs F. The number of refinement modules must be equal to the number of subsample layers used in DeepMask.

But what exactly does the R function do? Glad you asked. A naive approach would be to simply combine M and F, since they have the same height and width. The problem with this approach is creating a color depth channel for each of these components. The number of such channels in feature maps can be much larger than in a mask. Thus, a simple join would add too much F. The solution would be to reduce the number of color depth channels for F using a 3x3 convolutional layer, combining c M, passing through another 3x3 convolutional layer, and finally bilinear interpolation (see network architecture diagram ).
The same training data used for DeepMask can also be applied to SharpMask. First, the layers of DeepMask are trained. Then the weights are frozen, and SharpMask training begins.
This article, based on DeepMask, introduces a new, easy-to-use module. The authors discovered that they can achieve higher segmentation accuracy by simply using the low-level information available in the earlier layers of the DeepMask stage.

DeepMask create coarse mask segments. SharpMask refines the contours of objects. And the task of MultiPathNet is to identify or classify objects in masks. The group consisting of Sergey Zagoruiko, Adam Lerer, Tseng-Yi Lin, Pedro Pinero, Sam Gross, Sumit Chintala and Peter Dollar published an article “Multipath Network for Object Detection”. The goal of this article is to improve object recognition methods by directing attention to more precise localization, as well as to complex images with different scales, a large number of obstacles and unnecessary details. This model uses Fast R-CNN as a starting point (see this article or my previous post ). In essence, this model is a Fast R-CNN implementation with generating hypotheses about the location of an object using DeepMask and SharpMask. The three main changes described in the article are forged areas (forveal regions), skip connections, and integral loss function. But before going deep, let's take a look at the network architecture.

As in Fast R-CNN, we transmit the input image through the VGG network without fully connected layers. The ROI pooling layer is used to extract features from region-based hypotheses (as we remember from the Fast R-CNN article, ROI poling is a method of making an image map of the characteristics of a specific area of an image). For each hypothesis, we crop the image in four different ways to view the object at different scales. These are the “foveal regions”, which were discussed in the introduction. These cropped fragments pass through fully connected layers, the output data is combined, and the network splits into a classification head (regression head) and a regression branch. The authors suggest that these foveal areas will help to more accurately determine the location of the object, because in this way the network will be able to see the object at different scales and in different environments.
Thanks to Fast R-CNN, after the last convolutional VGG layer, the input image 32x32 will be quickly compressed to the size 2x2. The ROI pooling layer will create a 7x7 map, but we still lose a lot of spatial information. To solve this problem, we combine the attributes from the words conv3, conv4 and conv5, and transfer the result to the formal classifier. As stated in the article, this association “gives the classifier access to information about the signs from different areas of the image.”
I do not want to delve into this topic, because I think that all mathematics is much better explained in the article itself, but the whole idea is that the authors derived a loss function that works better with many values of Intersection over Union (IoU).
If you are a Fast R-CNN fan, then you will definitely like this model. It uses the core ideas of VGG Net and ROI pooling, while at the same time creating a new way to more accurately localize and classify using forward areas, skip connections and an integral loss function.
Facebook seems to have mastered all this CNN science perfectly.
If you have something to add, or you can otherwise explain any of the articles, let us know in the comments.
DeepMask and SharpMask code. MultuiPathNet code .
→ Link to original
→ Sources
In terms of image analysis, Facebook has come a long way with convolutional neural networks (Convolutional Neural Network, CNN). In August, Facebook's Artificial Intelligence Unit (Facebook AI Research, abbreviated as FAIR) published a blog post about computer vision algorithms that underlie some of their image segmentation algorithms. In this post, we will summarize and explain the three articles referenced by this blog.
Normally FAIR uses the following sequence of algorithms. Images are fed to the DeepMask segmentation framework. The SharpMask algorithm is used to improve the segments selected in the first stage, then objects are classified using MultiPathNet. Let's take a look at how each of these components works separately.
')
Deepmask
Introduction
This work, which belongs to Pedro Pinheiro, Roman Collobert, and Peter Dollar, is called “Learning to Segment Object Candidates”. To solve the problem of image segmentation, the authors propose an algorithm that, when receiving a fragment of an image, displays the object mask and the probability that the entire object is in the center of the fragment. This process is applied to the entire image so that a mask is created for each object. The entire process is carried out using just one CNN, since both components use the same network layers.
Input and Output
To begin with we will depict what we expect from the model. We want for the input image to get a set of masks or silhouettes of each object. We can present the original image as a set of fragments. For each input piece at the output, we obtain a binary mask containing the silhouette of the main object on it, as well as an estimate of how likely it is that this fragment contains the object (from -1 to 1).
Each teaching example should contain these three components (note: an example with probability 1 should contain a fragment in the center of which is an object that is contained in the image completely and on the same scale). The algorithm is applied to different parts of the image (the same set of fragments, which we mentioned earlier). The results are then combined to form one final image containing all the masks. Let's see what the algorithm consists of.
* Figure 1 . Above . Model architecture: after a general layer of extraction of characteristics, the model diverges into two branches. The upper branch predicts a segmentation mask for the object in the center, while the lower branch predicts the likelihood that the fragment contains the object.
From below . Examples of training triples: input fragment x, mask m, and label y. Green fragments contain objects that satisfy certain conditions and therefore are marked with y = 1. Note that the masks from the negative examples (red) are not used and are shown for illustration only.
Network architecture
The network was pre-trained in ImageNet image classification (Transfer Learning in action). The image passes through a VGG-like model (without fully connected layers) with eight 3x3 convolutional layers and five maxpool 2x2 layers. Depending on the size of the original image, you will get a certain amount of output (in this case, 512x14x14).
Input : 3 xhxw
Output : 512 xh / 16 xw / 16
Then the network is divided into two components described above. One of them assumes segmentation, while the second determines whether the desired object is in the image.
Segmentation Component (Segmentation Head)
Now we take the output data, transfer it through the inner layer and the ReLU layer. Now we have a layer of w 'xh' (where w 'and h' are smaller than w and h of the original image) pixel classifiers, which determine whether a given pixel is part of an object in the center of the image (if the image size is 28x28, then the classifiers will be less than 784). Then we take the output values of the classifiers, using the bilinear interpolation method, increase the image resolution to the original one and get a binary mask (1 - if the pixel belongs to the desired object, 0 - if not).
Objectness Head
The second component of the network determines whether the image contains an object of the desired scale in the center. By transmitting the output of VGG-like layers through a 2x2 maxpool layer, a dropout module and two fully connected layers, we can get our probability estimate.
Training
Both components of the network are trained in parallel, since the loss function is the sum of the loss of logistic regression (the loss of Objectness Head plus the loss of applying Segmentation Head to each fragment). The error propagation algorithm runs either on an Objectness Head or on a Segmentation Head. To improve the model, we used the technique of extending the training set (Data Augmentation). The model was trained using the stochastic gradient descent method on an Nvidia Tesla K40m GPU for five days.
What is cool this article
One convolutional neural network. We did not need an additional step to generate hypotheses of the location of the object (object proposals) or any complex learning process. This model has a certain simplicity, which provides network flexibility, as well as efficiency and speed.
SharpMask
Introduction
The previous group of researchers (together with Tsung-Yi Lin) also authored the article entitled “Learning to Refine Object Segments”. As the name implies, this article talks about improving the masks created during the DeepMask stage. The main problem of DeepMask is that this model uses a simple network of direct distribution, which successfully creates “rough” masks, but does not perform segmentation with pixel accuracy. The reason for this is that, if you remember, in DeepMask there is a bilinear interpolation, which serves to fit the size of the original image. Therefore, compliance with real boundaries is very approximate. To solve this problem, the SharpMask model combines the information of low-level characteristics that we get from the first layers of the network with high-level information about the object, which comes from deeper layers. First, the model creates a coarse mask for each input fragment (the work of DeepMask), and then passes through several refinement modules. Consider this stage in more detail.
Network architecture
The SharpMask idea emerged from the following considerations: since in order to find the exact object mask we need object-level information (high-level), we need a downward approach that builds coarse segments first and then combines the important low-level information from the initial layers. As can be seen from the figure above, the original image first passes through DeepMask to obtain coarse segmentation, and then enters the input sequence of the refinement modules for a more accurate increase of the image to the size of the original.
Refinement module
Let us consider in more detail how the specifying module is arranged. The objective of this module is to resist the influence of subsampling layers (pooling layer) at the DeepMask stage (the layers that squeezed the 224x224 image to 14x14), increasing the dimension of the masks obtained taking into account the feature maps created during the ascending passage (we can call DeepMask the ascending passage, and SharpMask - downward). Mathematically speaking, a refinement module is a function that generates an extended mask M, that is, a function from the mask of the previous layer and a map of signs F. The number of refinement modules must be equal to the number of subsample layers used in DeepMask.
But what exactly does the R function do? Glad you asked. A naive approach would be to simply combine M and F, since they have the same height and width. The problem with this approach is creating a color depth channel for each of these components. The number of such channels in feature maps can be much larger than in a mask. Thus, a simple join would add too much F. The solution would be to reduce the number of color depth channels for F using a 3x3 convolutional layer, combining c M, passing through another 3x3 convolutional layer, and finally bilinear interpolation (see network architecture diagram ).
Training
The same training data used for DeepMask can also be applied to SharpMask. First, the layers of DeepMask are trained. Then the weights are frozen, and SharpMask training begins.
What is cool this article
This article, based on DeepMask, introduces a new, easy-to-use module. The authors discovered that they can achieve higher segmentation accuracy by simply using the low-level information available in the earlier layers of the DeepMask stage.
MultiPathNet
Introduction
DeepMask create coarse mask segments. SharpMask refines the contours of objects. And the task of MultiPathNet is to identify or classify objects in masks. The group consisting of Sergey Zagoruiko, Adam Lerer, Tseng-Yi Lin, Pedro Pinero, Sam Gross, Sumit Chintala and Peter Dollar published an article “Multipath Network for Object Detection”. The goal of this article is to improve object recognition methods by directing attention to more precise localization, as well as to complex images with different scales, a large number of obstacles and unnecessary details. This model uses Fast R-CNN as a starting point (see this article or my previous post ). In essence, this model is a Fast R-CNN implementation with generating hypotheses about the location of an object using DeepMask and SharpMask. The three main changes described in the article are forged areas (forveal regions), skip connections, and integral loss function. But before going deep, let's take a look at the network architecture.
Network architecture / foveal areas
As in Fast R-CNN, we transmit the input image through the VGG network without fully connected layers. The ROI pooling layer is used to extract features from region-based hypotheses (as we remember from the Fast R-CNN article, ROI poling is a method of making an image map of the characteristics of a specific area of an image). For each hypothesis, we crop the image in four different ways to view the object at different scales. These are the “foveal regions”, which were discussed in the introduction. These cropped fragments pass through fully connected layers, the output data is combined, and the network splits into a classification head (regression head) and a regression branch. The authors suggest that these foveal areas will help to more accurately determine the location of the object, because in this way the network will be able to see the object at different scales and in different environments.
Skip connections
Thanks to Fast R-CNN, after the last convolutional VGG layer, the input image 32x32 will be quickly compressed to the size 2x2. The ROI pooling layer will create a 7x7 map, but we still lose a lot of spatial information. To solve this problem, we combine the attributes from the words conv3, conv4 and conv5, and transfer the result to the formal classifier. As stated in the article, this association “gives the classifier access to information about the signs from different areas of the image.”
Integral loss function
I do not want to delve into this topic, because I think that all mathematics is much better explained in the article itself, but the whole idea is that the authors derived a loss function that works better with many values of Intersection over Union (IoU).
What is cool this article
If you are a Fast R-CNN fan, then you will definitely like this model. It uses the core ideas of VGG Net and ROI pooling, while at the same time creating a new way to more accurately localize and classify using forward areas, skip connections and an integral loss function.
Facebook seems to have mastered all this CNN science perfectly.
If you have something to add, or you can otherwise explain any of the articles, let us know in the comments.
DeepMask and SharpMask code. MultuiPathNet code .
→ Link to original
→ Sources
Oh, and come to work with us? :)wunderfund.io is a young foundation that deals with high-frequency algorithmic trading . High-frequency trading is a continuous competition of the best programmers and mathematicians of the whole world. By joining us, you will become part of this fascinating fight.
We offer interesting and challenging data analysis and low latency tasks for enthusiastic researchers and programmers. Flexible schedule and no bureaucracy, decisions are quickly made and implemented.
Join our team: wunderfund.io
Source: https://habr.com/ru/post/317930/
All Articles